
 Web-Frontend
js-Tutorial
Die Quellcodeanalyse von RequireJ zeigt, wie das Laden von Skripten funktioniert
Web-Frontend
js-Tutorial
Die Quellcodeanalyse von RequireJ zeigt, wie das Laden von Skripten funktioniert
Die Quellcodeanalyse von RequireJ zeigt, wie das Laden von Skripten funktioniert
Einleitung
Wie das Sprichwort sagt, sind Programmierer, die nicht gerne Prinzipien studieren, keine guten Programmierer, und Programmierer, die nicht gerne Quellcode lesen, sind keine guten JSER. In den letzten zwei Tagen habe ich Probleme im Zusammenhang mit der Front-End-Modularisierung gesehen und festgestellt, dass die JavaScript-Community wirklich hart für die Front-End-Entwicklung gearbeitet hat. Heute habe ich mich einen Tag lang mit dem Thema Front-End-Modularisierung befasst. Zuerst habe ich kurz die Standardspezifikationen der Modularisierung verstanden, dann etwas über die Syntax und Verwendung von RequireJs gelernt und schließlich das Entwurfsmuster und den Quellcode von RequireJs studiert Ich möchte die relevanten Erfahrungen aufzeichnen und das Prinzip des Modulladens analysieren.
1. RequireJs verstehen
Bevor wir beginnen, müssen wir die Front-End-Modularisierung verstehen Bei Fragen hierzu können Sie auf die Artikelreihe Javascript Modular Programming von Ruan Yifeng verweisen.
Der erste Schritt zur Verwendung von RequireJs: Gehen Sie zur offiziellen Website
Der zweite Schritt: Laden Sie die Datei herunter


Schritt 3: Führen Sie requirejs.js in die Seite ein und legen Sie die Hauptfunktion fest;
1 <script type="text/javascript" src="scripts/require.js?1.1.11" data-main="scripts/main.js?1.1.11"></script>
Modul definieren:
1 //直接定义一个对象 2 define({ 3 color: "black", 4 size: "unisize" 5 }); 6 //通过函数返回一个对象,即可以实现 IIFE 7 define(function () { 8 //Do setup work here 9 10 return {11 color: "black",12 size: "unisize"13 }14 });15 //定义有依赖项的模块16 define(["./cart", "./inventory"], function(cart, inventory) {17 //return an object to define the "my/shirt" module.18 return {19 color: "blue",20 size: "large",21 addToCart: function() {22 inventory.decrement(this);23 cart.add(this);24 }25 }26 }27 );
1 //导入一个模块2 require(['foo'], function(foo) {3 //do something4 });5 //导入多个模块6 require(['foo', 'bar'], function(foo, bar) {7 //do something8 });2. Hauptfunktionseintrag
Eine der Kernideen von requirejs ist die Verwendung eines angegebenen Funktionseintrags, genau wie int main() von C++, public static void main() von Java. , requirejs wird verwendet, indem die Hauptfunktion im Skript-Tag zwischengespeichert wird. Das heißt, die URL der Skriptdatei wird im Skript-Tag zwischengespeichert.
1 <script type="text/javascript" src="scripts/require.js?1.1.11" data-main="scripts/main.js?1.1.11"></script>
1 //Look for a data-main attribute to set main script for the page2 //to load. If it is there, the path to data main becomes the3 //baseUrl, if it is not already set.4 dataMain = script.getAttribute('data-main');3. Dynamisches Ladeskript
Dieser Teil ist der Kern der gesamten Anforderungen. Wir wissen, dass die Art und Weise, Module in Node zu laden. js ist synchron Ja, das liegt daran, dass alle Dateien auf der Serverseite auf der lokalen Festplatte gespeichert sind und die Übertragungsrate schnell und stabil ist. Wenn Sie zum Browser wechseln, ist dies nicht möglich, da das Browser-Ladeskript mit dem Server kommuniziert. Dies ist eine unbekannte Anfrage. Wenn Sie zum Laden eine synchrone Methode verwenden, wird diese möglicherweise weiterhin blockiert. Um zu verhindern, dass der Browser blockiert, müssen wir das Skript asynchron laden. Da es asynchron geladen wird, müssen vom Modul abhängige Vorgänge nach dem Laden des Skripts ausgeführt werden, und hier muss eine Rückruffunktion verwendet werden.
Wir wissen, dass, wenn die Skriptdatei in HTML definiert ist, die Ausführungsreihenfolge des Skripts synchron ist, wie zum Beispiel:
1 //module1.js2 console.log("module1");1 //module2.js2 console.log("module2");1 //module3.js2 console.log("module3");那么在浏览器端总是会输出:

但是如果是动态加载脚本的话,脚本的执行顺序是异步的,而且不光是异步的,还是无序的:
1 //main.js 2 console.log("main start"); 3 4 var script1 = document.createElement("script"); 5 script1.src = "scripts/module/module1.js?1.1.11"; 6 document.head.appendChild(script1); 7 8 var script2 = document.createElement("script"); 9 script2.src = "scripts/module/module2.js?1.1.11";10 document.head.appendChild(script2);11 12 var script3 = document.createElement("script");13 script3.src = "scripts/module/module3.js?1.1.11";14 document.head.appendChild(script3);15 16 console.log("main end");使用这种方式加载脚本会造成脚本的无序加载,浏览器按照先来先运行的方法执行脚本,如果 module1.js 文件比较大,那么极其有可能会在 module2.js 和 module3.js 后执行,所以说这也是不可控的。要知道一个程序当中最大的 BUG 就是一个不可控的 BUG ,有时候它可能按顺序执行,有时候它可能乱序,这一定不是我们想要的。
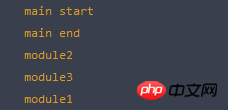
注意这里的还有一个重点是,"module" 的输出永远会在 "main end" 之后。这正是动态加载脚本异步性的特征,因为当前的脚本是一个 task ,而无论其他脚本的加载速度有多快,它都会在 Event Queue 的后面等待调度执行。这里涉及到一个关键的知识 — Event Loop ,如果你还对 JavaScript Event Loop 不了解,那么请先阅读这篇文章 深入理解 JavaScript 事件循环(一)— Event Loop。
四、导入模块原理
在上一小节,我们了解到,使用动态加载脚本的方式会使脚本无序执行,这一定是软件开发的噩梦,想象一下你的模块之间存在上下依赖的关系,而这时候他们的加载顺序是不可控的。动态加载同时也具有异步性,所以在 main.js 脚本文件中根本无法访问到模块文件中的任何变量。那么 requirejs 是如何解决这个问题的呢?我们知道在 requirejs 中,任何文件都是一个模块,一个模块也就是一个文件,包括主模块 main.js,下面我们看一段 requirejs 的源码:
1 /** 2 * Creates the node for the load command. Only used in browser envs. 3 */ 4 req.createNode = function (config, moduleName, url) { 5 var node = config.xhtml ? 6 document.createElementNS('http://www.w3.org/1999/xhtml', 'html:script') : 7 document.createElement('script'); 8 node.type = config.scriptType || 'text/javascript'; 9 node.charset = 'utf-8';10 node.async = true;11 return node;12 };在这段代码中我们可以看出, requirejs 导入模块的方式实际就是创建脚本标签,一切的模块都需要经过这个方法创建。那么 requirejs 又是如何处理异步加载的呢?传说江湖上最高深的医术不是什么灵丹妙药,而是以毒攻毒,requirejs 也深得其精髓,既然动态加载是异步的,那么我也用异步来对付你,使用 onload 事件来处理回调函数:
1 //In the browser so use a script tag 2 node = req.createNode(config, moduleName, url); 3 4 node.setAttribute('data-requirecontext', context.contextName); 5 node.setAttribute('data-requiremodule', moduleName); 6 7 //Set up load listener. Test attachEvent first because IE9 has 8 //a subtle issue in its addEventListener and script onload firings 9 //that do not match the behavior of all other browsers with10 //addEventListener support, which fire the onload event for a11 //script right after the script execution. See:12 //13 //UNFORTUNATELY Opera implements attachEvent but does not follow the script14 //script execution mode.15 if (node.attachEvent &&16 //Check if node.attachEvent is artificially added by custom script or17 //natively supported by browser18 //read 19 //if we can NOT find [native code] then it must NOT natively supported.20 //in IE8, node.attachEvent does not have toString()21 //Note the test for "[native code" with no closing brace, see:22 //23 !(node.attachEvent.toString && node.attachEvent.toString().indexOf('[native code') < 0) &&24 !isOpera) {25 //Probably IE. IE (at least 6-8) do not fire26 //script onload right after executing the script, so27 //we cannot tie the anonymous define call to a name.28 //However, IE reports the script as being in 'interactive'29 //readyState at the time of the define call.30 useInteractive = true;31 32 node.attachEvent('onreadystatechange', context.onScriptLoad);33 //It would be great to add an error handler here to catch34 //404s in IE9+. However, onreadystatechange will fire before35 //the error handler, so that does not help. If addEventListener36 //is used, then IE will fire error before load, but we cannot37 //use that pathway given the connect.microsoft.com issue38 //mentioned above about not doing the 'script execute,39 //then fire the script load event listener before execute40 //next script' that other browsers do.41 //Best hope: IE10 fixes the issues,42 //and then destroys all installs of IE 6-9.43 //node.attachEvent('onerror', context.onScriptError);44 } else {45 node.addEventListener('load', context.onScriptLoad, false);46 node.addEventListener('error', context.onScriptError, false);47 }48 node.src = url;注意在这段源码当中的监听事件,既然动态加载脚本是异步的的,那么干脆使用 onload 事件来处理回调函数,这样就保证了在我们的程序执行前依赖的模块一定会提前加载完成。因为在事件队列里, onload 事件是在脚本加载完成之后触发的,也就是在事件队列里面永远处在依赖模块的后面,例如我们执行:
1 require(["module"], function (module) {2 //do something3 });那么在事件队列里面的相对顺序会是这样:

相信细心的同学可能会注意到了,在源码当中不光光有 onload 事件,同时还添加了一个 onerror 事件,我们在使用 requirejs 的时候也可以定义一个模块加载失败的处理函数,这个函数在底层也就对应了 onerror 事件。同理,其和 onload 事件一样是一个异步的事件,同时也永远发生在模块加载之后。
谈到这里 requirejs 的核心模块思想也就一目了然了,不过其中的过程还远不直这些,博主只是将模块加载的实现思想抛了出来,但 requirejs 的具体实现还要复杂的多,比如我们定义模块的时候可以导入依赖模块,导入模块的时候还可以导入多个依赖,具体的实现方法我就没有深究过了, requirejs 虽然不大,但是源码也是有两千多行的... ...但是只要理解了动态加载脚本的原理过后,其思想也就不难理解了,比如我现在就可以想到一个简单的实现多个模块依赖的方法,使用计数的方式检查模块是否加载完全:
1 function myRequire(deps, callback){ 2 //记录模块加载数量 3 var ready = 0; 4 //创建脚本标签 5 function load (url) { 6 var script = document.createElement("script"); 7 script.type = 'text/javascript'; 8 script.async = true; 9 script.src = url;10 return script;11 }12 var nodes = [];13 for (var i = deps.length - 1; i >= 0; i--) {14 nodes.push(load(deps[i]));15 }16 //加载脚本17 for (var i = nodes.length - 1; i >= 0; i--) {18 nodes[i].addEventListener("load", function(event){19 ready++;20 //如果所有依赖脚本加载完成,则执行回调函数;21 if(ready === nodes.length){22 callback()23 }24 }, false);25 document.head.appendChild(nodes[i]);26 }27 }实验一下是否能够工作:
1 myRequire(["module/module1.js?1.1.11", "module/module2.js?1.1.11", "module/module3.js?1.1.11"], function(){2 console.log("ready!");3 }); 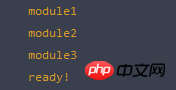
Ja, es ist Arbeit!
Zusammenfassung
Die Kernidee des Requirejs-Lademoduls besteht darin, die asynchrone Natur dynamisch geladener Skripte und das Onload-Ereignis zu nutzen, um Viren mit Gift zu bekämpfen. Wir müssen auf folgende Punkte achten:
Die Einführung des

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos
AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.
Undress AI Tool
Ausziehbilder kostenlos
Clothoff.io
KI-Kleiderentferner
AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
R.E.P.O. Energiekristalle erklärten und was sie tun (gelber Kristall)3 Wochen vor By 尊渡假赌尊渡假赌尊渡假赌R.E.P.O. Beste grafische Einstellungen3 Wochen vor By 尊渡假赌尊渡假赌尊渡假赌Assassin's Creed Shadows: Seashell Riddle -Lösung2 Wochen vor By DDDR.E.P.O. So reparieren Sie Audio, wenn Sie niemanden hören können3 Wochen vor By 尊渡假赌尊渡假赌尊渡假赌WWE 2K25: Wie man alles in Myrise freischaltet3 Wochen vor By 尊渡假赌尊渡假赌尊渡假赌
Heiße Werkzeuge
Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor
SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen
Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung
Dreamweaver CS6
Visuelle Webentwicklungstools
SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
CakePHP-Tutorial 1376
1376
 52
52











![Fehler beim Laden des Plugins in Illustrator [Behoben]](https://img.php.cn/upload/article/000/465/014/170831522770626.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) Fehler beim Laden des Plugins in Illustrator [Behoben]
Feb 19, 2024 pm 12:00 PM
Fehler beim Laden des Plugins in Illustrator [Behoben]
Feb 19, 2024 pm 12:00 PM
Erscheint beim Starten von Adobe Illustrator eine Meldung über einen Fehler beim Laden des Plug-Ins? Bei einigen Illustrator-Benutzern ist dieser Fehler beim Öffnen der Anwendung aufgetreten. Der Meldung folgt eine Liste problematischer Plugins. Diese Fehlermeldung weist darauf hin, dass ein Problem mit dem installierten Plug-In vorliegt, es kann jedoch auch andere Gründe haben, beispielsweise eine beschädigte Visual C++-DLL-Datei oder eine beschädigte Einstellungsdatei. Wenn dieser Fehler auftritt, werden wir Sie in diesem Artikel bei der Behebung des Problems unterstützen. Lesen Sie daher weiter unten weiter. Fehler beim Laden des Plug-Ins in Illustrator Wenn Sie beim Versuch, Adobe Illustrator zu starten, die Fehlermeldung „Fehler beim Laden des Plug-Ins“ erhalten, können Sie Folgendes verwenden: Als Administrator
 So implementieren Sie ein Online-Spracherkennungssystem mit WebSocket und JavaScript
Dec 17, 2023 pm 02:54 PM
So implementieren Sie ein Online-Spracherkennungssystem mit WebSocket und JavaScript
Dec 17, 2023 pm 02:54 PM
So implementieren Sie mit WebSocket und JavaScript ein Online-Spracherkennungssystem. Einführung: Mit der kontinuierlichen Weiterentwicklung der Technologie ist die Spracherkennungstechnologie zu einem wichtigen Bestandteil des Bereichs der künstlichen Intelligenz geworden. Das auf WebSocket und JavaScript basierende Online-Spracherkennungssystem zeichnet sich durch geringe Latenz, Echtzeit und plattformübergreifende Eigenschaften aus und hat sich zu einer weit verbreiteten Lösung entwickelt. In diesem Artikel wird erläutert, wie Sie mit WebSocket und JavaScript ein Online-Spracherkennungssystem implementieren.
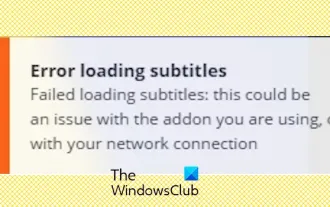 Stremio-Untertitel funktionieren nicht; Fehler beim Laden der Untertitel
Feb 24, 2024 am 09:50 AM
Stremio-Untertitel funktionieren nicht; Fehler beim Laden der Untertitel
Feb 24, 2024 am 09:50 AM
Untertitel funktionieren bei Stremio auf Ihrem Windows-PC nicht? Einige Stremio-Benutzer berichteten, dass in den Videos keine Untertitel angezeigt wurden. Viele Benutzer berichteten, dass ihnen die Fehlermeldung „Fehler beim Laden der Untertitel“ angezeigt wurde. Hier ist die vollständige Fehlermeldung, die bei diesem Fehler angezeigt wird: Beim Laden der Untertitel ist ein Fehler aufgetreten. Untertitel konnten nicht geladen werden: Dies könnte ein Problem mit dem von Ihnen verwendeten Plugin oder Ihrem Netzwerk sein. Wie in der Fehlermeldung angegeben, könnte es Ihre Internetverbindung sein, die den Fehler verursacht. Überprüfen Sie daher bitte Ihre Netzwerkverbindung und stellen Sie sicher, dass Ihr Internet ordnungsgemäß funktioniert. Abgesehen davon könnte es auch andere Gründe für diesen Fehler geben, darunter ein widersprüchliches Untertitel-Add-on, nicht unterstützte Untertitel für bestimmte Videoinhalte und eine veraltete Stremio-App. wie
 WebSocket und JavaScript: Schlüsseltechnologien zur Implementierung von Echtzeitüberwachungssystemen
Dec 17, 2023 pm 05:30 PM
WebSocket und JavaScript: Schlüsseltechnologien zur Implementierung von Echtzeitüberwachungssystemen
Dec 17, 2023 pm 05:30 PM
WebSocket und JavaScript: Schlüsseltechnologien zur Realisierung von Echtzeit-Überwachungssystemen Einführung: Mit der rasanten Entwicklung der Internet-Technologie wurden Echtzeit-Überwachungssysteme in verschiedenen Bereichen weit verbreitet eingesetzt. Eine der Schlüsseltechnologien zur Erzielung einer Echtzeitüberwachung ist die Kombination von WebSocket und JavaScript. In diesem Artikel wird die Anwendung von WebSocket und JavaScript in Echtzeitüberwachungssystemen vorgestellt, Codebeispiele gegeben und deren Implementierungsprinzipien ausführlich erläutert. 1. WebSocket-Technologie
 So implementieren Sie ein Online-Reservierungssystem mit WebSocket und JavaScript
Dec 17, 2023 am 09:39 AM
So implementieren Sie ein Online-Reservierungssystem mit WebSocket und JavaScript
Dec 17, 2023 am 09:39 AM
So implementieren Sie ein Online-Reservierungssystem mit WebSocket und JavaScript. Im heutigen digitalen Zeitalter müssen immer mehr Unternehmen und Dienste Online-Reservierungsfunktionen bereitstellen. Es ist von entscheidender Bedeutung, ein effizientes Online-Reservierungssystem in Echtzeit zu implementieren. In diesem Artikel wird erläutert, wie Sie mit WebSocket und JavaScript ein Online-Reservierungssystem implementieren, und es werden spezifische Codebeispiele bereitgestellt. 1. Was ist WebSocket? WebSocket ist eine Vollduplex-Methode für eine einzelne TCP-Verbindung.
 Verwendung von JavaScript und WebSocket zur Implementierung eines Echtzeit-Online-Bestellsystems
Dec 17, 2023 pm 12:09 PM
Verwendung von JavaScript und WebSocket zur Implementierung eines Echtzeit-Online-Bestellsystems
Dec 17, 2023 pm 12:09 PM
Einführung in die Verwendung von JavaScript und WebSocket zur Implementierung eines Online-Bestellsystems in Echtzeit: Mit der Popularität des Internets und dem Fortschritt der Technologie haben immer mehr Restaurants damit begonnen, Online-Bestelldienste anzubieten. Um ein Echtzeit-Online-Bestellsystem zu implementieren, können wir JavaScript und WebSocket-Technologie verwenden. WebSocket ist ein Vollduplex-Kommunikationsprotokoll, das auf dem TCP-Protokoll basiert und eine bidirektionale Kommunikation zwischen Client und Server in Echtzeit realisieren kann. Im Echtzeit-Online-Bestellsystem, wenn der Benutzer Gerichte auswählt und eine Bestellung aufgibt
 Outlook friert beim Einfügen eines Hyperlinks ein
Feb 19, 2024 pm 03:00 PM
Outlook friert beim Einfügen eines Hyperlinks ein
Feb 19, 2024 pm 03:00 PM
Wenn beim Einfügen von Hyperlinks in Outlook Probleme beim Einfrieren auftreten, kann dies an instabilen Netzwerkverbindungen, alten Outlook-Versionen, Störungen durch Antivirensoftware oder Add-In-Konflikten liegen. Diese Faktoren können dazu führen, dass Outlook Hyperlink-Vorgänge nicht ordnungsgemäß verarbeitet. Beheben, dass Outlook beim Einfügen von Hyperlinks einfriert. Verwenden Sie die folgenden Korrekturen, um das Einfrieren von Outlook beim Einfügen von Hyperlinks zu beheben: Überprüfen Sie installierte Add-Ins. Aktualisieren Sie Outlook. Deaktivieren Sie vorübergehend Ihre Antivirensoftware und versuchen Sie dann, ein neues Benutzerprofil zu erstellen. Office-Apps reparieren. Programm deinstallieren und neu installieren. Los geht's. 1] Überprüfen Sie die installierten Add-Ins. Möglicherweise verursacht ein in Outlook installiertes Add-In das Problem.
 JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems
Dec 17, 2023 pm 05:13 PM
JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems
Dec 17, 2023 pm 05:13 PM
JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems Einführung: Heutzutage ist die Genauigkeit von Wettervorhersagen für das tägliche Leben und die Entscheidungsfindung von großer Bedeutung. Mit der Weiterentwicklung der Technologie können wir genauere und zuverlässigere Wettervorhersagen liefern, indem wir Wetterdaten in Echtzeit erhalten. In diesem Artikel erfahren Sie, wie Sie mit JavaScript und WebSocket-Technologie ein effizientes Echtzeit-Wettervorhersagesystem aufbauen. In diesem Artikel wird der Implementierungsprozess anhand spezifischer Codebeispiele demonstriert. Wir
