

PHP (die in diesem Artikel erwähnten PHP-Versionen sind alle 7.1.3) ist eine dynamische Skriptsprache. Ihr Ausführungsprozess in der virtuellen Zend-Maschine ist: Lesen Sie das Skriptprogramm Zeichenfolge und Der lexikalische Analysator wandelt sie in Wortsymbole um, dann erkennt der Syntaxanalysator die grammatikalische Struktur und generiert einen abstrakten Syntaxbaum, dann generiert der statische Compiler Opcode und schließlich simuliert der Interpreter Maschinenanweisungen, um jeden Opcode auszuführen.
Im gesamten oben genannten Prozess kann der generierte Opcode Kompilierungsoptimierungstechniken wie das Löschen von totem Code, die bedingte Konstantenweitergabe, das Inlining von Funktionen und andere Optimierungen anwenden, um den Opcode zu rationalisieren und die Ausführungsleistung des Codes zu verbessern.
PHP-Erweiterung Opcache unterstützt Caching-Optimierung für den generierten Opcode basierend auf Shared Memory. Auf dieser Basis wird die statische Kompilierungsoptimierung des Opcodes hinzugefügt. Die hier beschriebene Optimierung wird üblicherweise von einem Optimierer (Optimizer) verwVertieftes Verständnis der Opcode-Optimierung in PHP (Bilder und Text)et. Im Kompilierungsprinzip wird jede Optimierung im Allgemeinen durch einen Optimierungsdurchlauf (Opt-Durchlauf) beschrieben.
Im Allgemeinen gibt es zwei Arten von Optimierungsdurchgängen:
Einer ist der Analysedurchlauf, der Datenfluss- und Kontrollflussanalyseinformationen bereitstellt, um Hilfsinformationen für die bereitzustellen Konvertierungsdurchlauf;
Einer ist der Konvertierungsdurchlauf, der den generierten Code ändert, einschließlich des Hinzufügens und Löschens von Anweisungen, des Änderns von Ersatzanweisungen, des Anpassens der Reihenfolge von Anweisungen usw. Normalerweise werden die Änderungen in Der generierte Code kann vor und nach jedem Durchgang gespeichert werden.
Dieser Artikel basiert auf dem Kompilierungsprinzip, kombiniert mit dem von der Opcache-Erweiterung bereitgestellten Optimierer, und verwendet die Grundeinheit der PHP-Kompilierung op_array und die kleinste Einheit des PHP-Ausführungs-Opcodes als Ausgangspunkt. In diesem Artikel wird die Anwendung der Kompilierungsoptimierungstechnologie in der virtuellen Zend-Maschine vorgestellt und erläutert, wie jeder Optimierungsdurchlauf den Opcode Schritt für Schritt optimiert, um die Codeausführungsleistung zu verbessern. Abschließend werden einige Aussichten basierend auf der Ausführung der virtuellen Maschine der PHP-Sprache gegeben.
Statische Kompilierung, auch Ahead-of-Time-Kompilierung genannt), als AOT bezeichnet. Das heißt, der Quellcode wird in Zielcode kompiliert und läuft bei der Ausführung auf einer Plattform, die den Zielcode unterstützt.
Dynamische Kompilierung bezieht sich im Vergleich zur statischen Kompilierung auf „Kompilieren zur Laufzeit“. Normalerweise wird für die Kompilierung und Ausführung ein Dolmetscher verwendet, was bedeutet, dass die Quellsprache einzeln interpretiert und ausgeführt wird.
JIT-Kompilierung (Just-in-Time-Kompilierung), also Just-in-Time-Kompilierung, bedeutet im engeren Sinne, dass ein bestimmter Codeabschnitt kompiliert wird, wenn er zum ersten Mal ausgeführt werden soll Zeit und wird dann direkt ohne Kompilierung ausgeführt. Es handelt sich um eine Art dynamische Kompilierung.
Die oben genannten drei Arten unterschiedlicher Kompilierungsausführungsprozesse können grob wie folgt beschrieben werden: 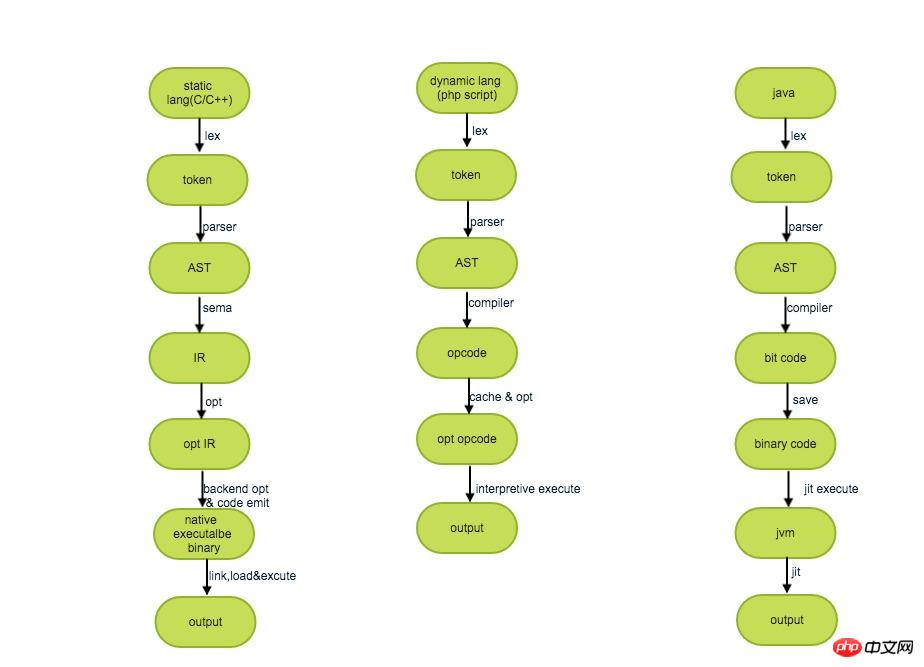
Eine Kompilierungsoptimierung muss erreicht werden Aus dem Programm Genügend Informationen, dies ist die Grundlage aller Kompilierungsoptimierungen.
Das vom Compiler-Frontend generierte Ergebnis kann ein Syntaxbaum oder eine Art Zwischencode auf niedriger Ebene sein. Aber wie auch immer das Ergebnis aussehen mag, es sagt immer noch nicht viel darüber aus, was das Programm tut oder wie es es tut. Der Compiler überlässt der Kontrollflussanalyse die Aufgabe, die Kontrollflusshierarchie innerhalb jeder Prozedur zu ermitteln, und der Datenflussanalyse die Aufgabe, für die Datenverarbeitung relevante globale Informationen zu ermitteln.
Kontrollfluss ist eine formale Analysemethode zum ErhVertieftes Verständnis der Opcode-Optimierung in PHP (Bilder und Text)en von Programmkontrollstrukturinformationen. Sie ist die Grundlage für die Datenflussanalyse und Abhängigkeitsanalyse. Ein grundlegendes Kontrollmodell ist der Control Flow Graph (CFG). Es gibt zwei Möglichkeiten, den Kontrollfluss eines einzelnen Prozesses zu analysieren: die Verwendung notwendiger Knoten zum Auffinden von Schleifen und die Intervallanalyse.
Der Datenfluss sammelt die semantischen Informationen des Programms aus dem Programmcode und bestimmt die Definition und Verwendung von Variablen zur Kompilierungszeit durch algebraische Methoden. Ein grundlegendes Datenmodell ist der Data Flow Graph (DFG). Die übliche Datenflussanalyse ist eine kontrollbaumbasierte Datenflussanalyse, und die Algorithmen sind in Intervallanalyse und Strukturanalyse unterteilt.
ähnelt dem Konzept des Stack-Frames in der C-Sprache, bei dem es sich um die Grundeinheit (ein Frame) eines laufenden Programms handelt, im Allgemeinen eine Eins -time-Funktion Die aufzurufende Basiseinheit. Hier werden eine Funktion oder Methode, die gesamte PHP-Skriptdatei und der an eval übergebene String zur Darstellung des PHP-Codes in ein op_array kompiliert.
In der Implementierung ist op_array eine Struktur, die alle Informationen der Grundeinheit des Programmbetriebs enthält. Natürlich ist das Opcode-Array das wichtigste Feld der Struktur, aber darüber hinaus enthält es auch Variablentypen. Anmerkungsinformationen und Ausnahmeerfassungsinformationen, Sprunginformationen usw.
Der Interpreter-Ausführungsprozess (ZendVM) besteht darin, den minimal optimierten Opcode in einer Basiseinheit op_array auszuführen, die Ausführung der Reihe nach zu durchlaufen, den aktuellen Opcode auszuführen und vorab abzurufen Der nächste Opcode, bis zum letzten RETRUN kehrt dieser spezielle Opcode zum Beenden zurück.
Der Opcode ähnelt hier auch der Zwischendarstellung im statischen Compiler (ähnlich LLVM IR). Er hat normalerweise die Form eines Drei-Adress-Codes, der einen Operator, zwei Operanden und ein Operationsergebnis enthält . Beide Operanden enthVertieftes Verständnis der Opcode-Optimierung in PHP (Bilder und Text)en Typinformationen. Hier gibt es fünf Arten von Typinformationen, nämlich:
Kompilierte Variable (kurz CV). Die Variablen zur Kompilierungszeit sind die im PHP-Skript definierten Variablen.
Interne wiederverwendbare Variablen (VAR), temporäre Variablen, die von ZendVM verwendet werden, können mit anderen Opcodes geteilt werden.
Interne nicht wiederverwendbare Variablen (TMP_VAR), temporäre Variablen, die von ZendVM verwendet werden, können nicht mit anderen Opcodes geteilt werden.
Konstante (CONST), schreibgeschützte Konstante, der Wert kann nicht geändert werden.
Nutzlose Variable (UNUSED). Da Opcode drei Adresscodes verwendet, verfügt nicht jeder Opcode über ein Operandenfeld. Standardmäßig wird diese Variable zum Ausfüllen des Felds verwendet.
Die Typinformationen zusammen mit dem Operator ermöglichen es dem Ausführenden, eine bestimmte kompilierte C-Funktionsbibliotheksvorlage abzugleichen und auszuwählen und die Generierung von Maschinenanweisungen zur Ausführung zu simulieren.
Opcode wird durch die zend_op-Struktur in ZendVM dargestellt und seine Hauptstruktur ist wie folgt: 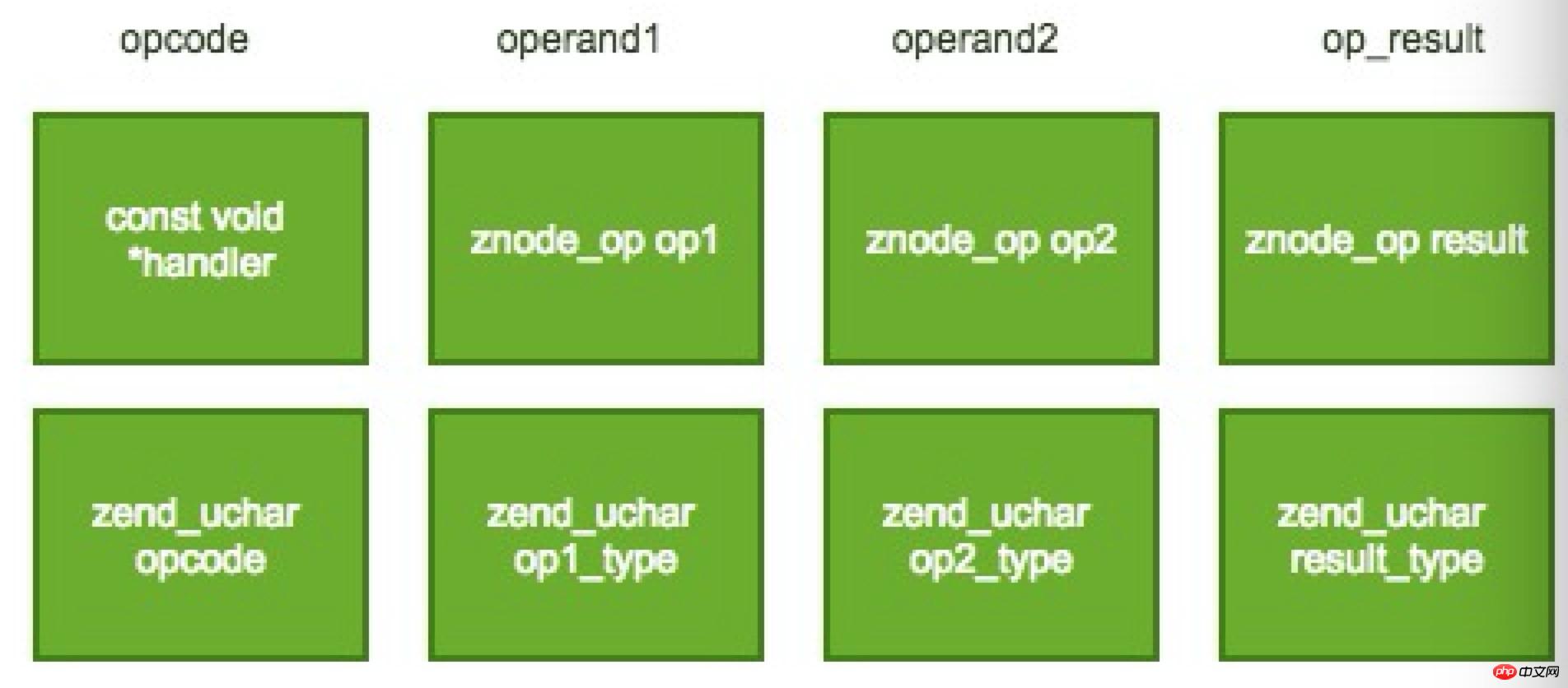
PHP-Skript geht durch lexikalische Analyse und Syntaxanalyse zur Generierung der abstrakten Syntaxbaumstruktur wird der Opcode durch statische Kompilierung generiert. Als gemeinsame Plattform zum Ausführen von Anweisungen an verschiedene virtuelle Maschinen basiert es auf der spezifischen Implementierung verschiedener virtueller Maschinen (bei PHP beziehen sich die meisten jedoch auf ZendVM).
Bevor die virtuelle Maschine Opcode ausführt, können Sie Code mit höherer Ausführungseffizienz erhVertieftes Verständnis der Opcode-Optimierung in PHP (Bilder und Text)en. Die Funktion von pass besteht darin, Opcode zu optimieren, Opcode zu verarbeiten, Opcode zu analysieren und zu suchen Optimierungsmöglichkeiten und Ändern des Opcodes, um Code mit höherer Ausführungseffizienz zu erzeugen.
In der Zend Virtual Machine (ZendVM) ist der statische Code-Optimierer von Opcache die Zend-Opcode-Optimierung.
Um den Optimierungseffekt zu beobachten und das Debuggen zu erleichtern, bietet es auch Optimierungs- und Debugging-Optionen:
OptimierungEbene (opcache.optimizationEbene =0xFFFFFFFF ) Optimierungsstufe, die meisten Optimierungsdurchgänge sind standardmäßig aktiviert, und Benutzer können das AusschVertieftes Verständnis der Opcode-Optimierung in PHP (Bilder und Text)en auch steuern, indem sie Befehlszeilenparameter
optdebuglevel übergeben (opcache.opt debuglevel=-1) Debug-Level, nicht standardmäßig aktiviert, sondern stellt den Transformationsprozess des Opcodes vor und nach jeder Optimierung bereit
Die Die für die statische Optimierung erforderlichen Skriptkontextinformationen sind in der Struktur zend_script gekapselt und lauten wie folgt:
typedef struct _zend_script {
zend_string *filename; //文件名
zend_op_array main_op_array; //栈帧
HashTable function_table; //函数单位符号表信息
HashTable class_table; //类单位符号表信息
} zend_script;Die oben genannten drei InhVertieftes Verständnis der Opcode-Optimierung in PHP (Bilder und Text)sinformationen werden als Eingabeparameter zur Analyse und Optimierung an den Optimierer übergeben. Natürlich bildet es, ähnlich wie die übliche PHP-Erweiterung, zusammen mit dem Opcode-Cache-Modul (zend_accel) die Opcache-Erweiterung. Es bettet drei interne APIs in den Cache-Beschleuniger ein:
zendOptimizerStartup-Startup-Optimizer
zendoptimize Skriptoptimierer implementiert die Hauptlogik der Optimierung
zendOptimiererBeenden Sie die vom Optimierer generierte Ressourcenbereinigung
In Bezug auf das Opcode-Caching handelt es sich auch um eine sehr wichtige Optimierung des Opcodes. Das grundlegende Anwendungsprinzip lautet ungefähr wie folgt:
Obwohl PHP eine dynamische Skriptsprache ist, ruft es weder direkt einen vollständigen Satz von Compiler-Toolketten wie GCC/LLVM auf, noch ruft es ein reines Frontend auf Compiler wie Javac. Aber jedes Mal, wenn die Ausführung eines PHP-Skripts angefordert wird, durchläuft es den gesamten Lebenszyklus von Lexikon, Syntax, Kompilierung zum Opcode und VM-Ausführung.
Die ersten drei Schritte außer der Ausführung stellen im Grunde den gesamten Prozess eines Front-End-Compilers dar. Dieser Kompilierungsprozess ist jedoch nicht schnell. Wenn dasselbe Skript wiederholt ausgeführt wird, schränkt die Kompilierungszeit der ersten drei Schritte die Betriebseffizienz erheblich ein, der bei jeder Kompilierung generierte Opcode ändert sich jedoch nicht. Daher kann der Opcode beim ersten Kompilieren an einem bestimmten Ort zwischengespeichert werden (Java speichert ihn beim nächsten Mal direkt aus dem gemeinsam genutzten Speicher). Das Skript wird ausgeführt. Dies spart Kompilierungszeit.
Der Opcode-Caching-Prozess der Opcache-Erweiterung ist ungefähr wie folgt: 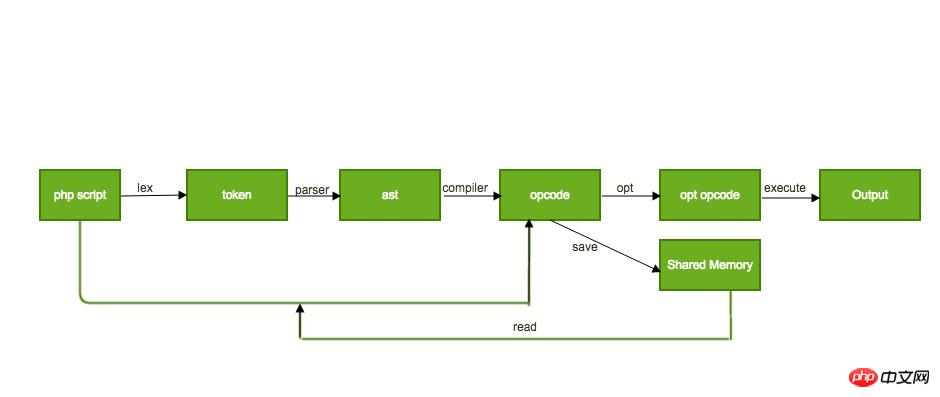 Da sich dieser Artikel hauptsächlich auf statische Optimierungsdurchgänge konzentriert, wird die spezifische Implementierung der Cache-Optimierung hier nicht erläutert.
Da sich dieser Artikel hauptsächlich auf statische Optimierungsdurchgänge konzentriert, wird die spezifische Implementierung der Cache-Optimierung hier nicht erläutert.
Gemäß dem „Whale Book“ („Advanced Compiler Design and Implementation“) ist eine sinnvollere Optimierungsdurchlaufsequenz für einen optimierenden Compiler wie folgt: 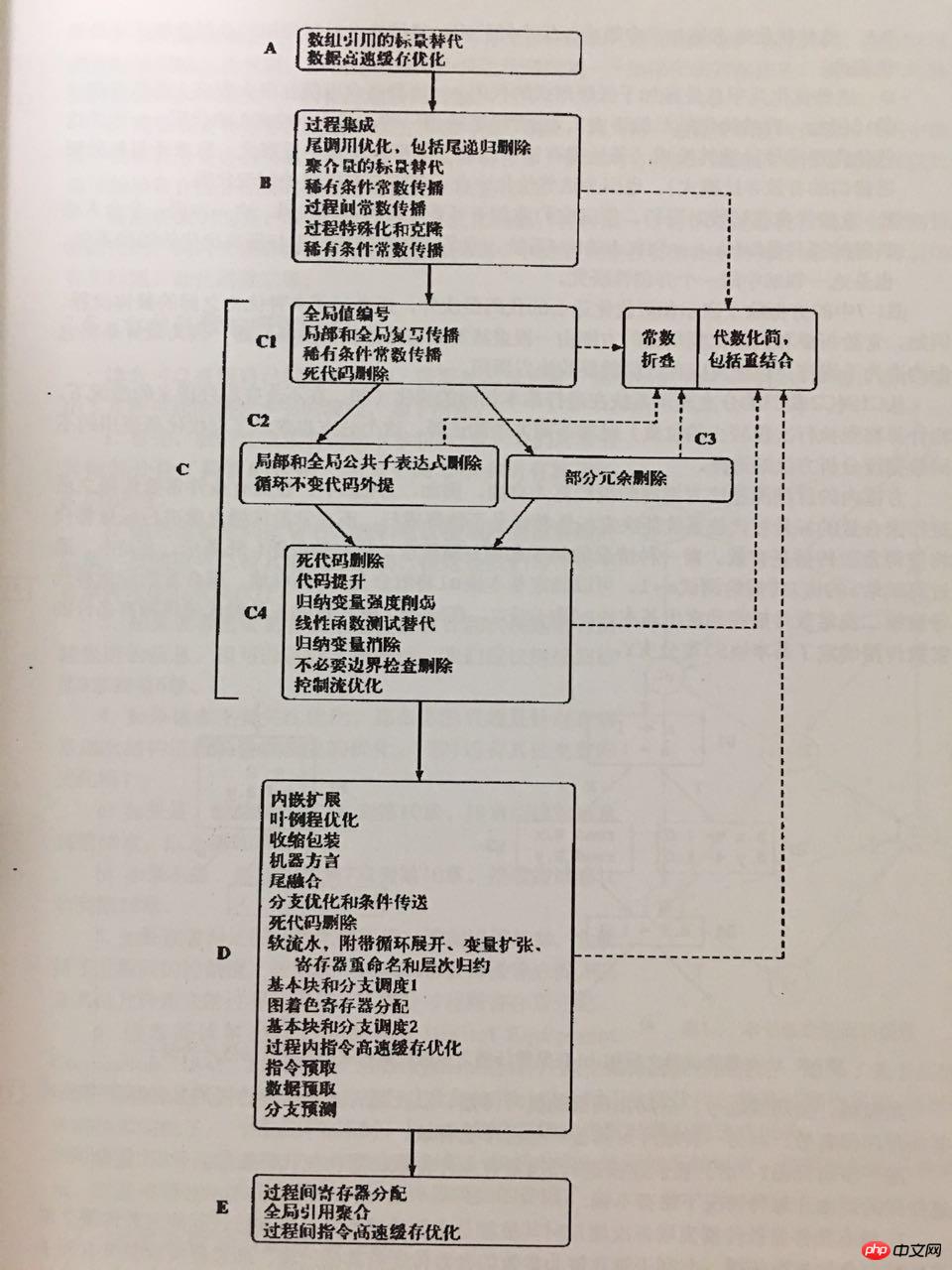
Die Optimierungen in der obigen Abbildung reichen von einfachen Konstanten und totem Code bis hin zu Schleifen und Verzweigungssprüngen, von Funktionsaufrufen bis zur Optimierung zwischen Prozeduren, von Prefetching und Caching bis hin zu Soft-Pipelining und Registerzuweisung und umfassen natürlich auch Daten Fluss, Kontrollflussanalyse.
Natürlich implementiert der aktuelle Opcode-Optimierer nicht alle oben genannten Optimierungsdurchgänge, und es besteht keine Notwendigkeit, maschinenbezogene Zwischendarstellungsoptimierungen auf niedriger Ebene wie die Registerzuweisung zu implementieren.
Nachdem der Opcache-Optimierer die oben genannten Skriptparameterinformationen erhVertieftes Verständnis der Opcode-Optimierung in PHP (Bilder und Text)en hat, findet er die minimale Kompilierungseinheit. Auf dieser Grundlage kann gemäß dem Optimierungsdurchlaufmakro und dem entsprechenden Optimierungsstufenmakro die Registrierungssteuerung eines bestimmten Durchlaufs realisiert werden.
Unter den registrierten Optimierungen ist jede Optimierung seriell in einer bestimmten Reihenfolge organisiert, einschließlich konstanter Optimierung, redundanter NoP-Löschung, Funktionsaufrufoptimierungs-Konvertierungsdurchlauf und Analysedurchgängen wie Datenflussanalyse, Kontrollflussanalyse usw Anrufbeziehungsanalyse. Das
zendoptimizeSkript und der eigentliche Optimierungsregistrierungsprozess zend_optimize lauten wie folgt:
zend_optimize_script(zend_script *script,
zend_long optimization_level, zend_long debug_level)
|zend_optimize_op_array(&script->main_op_array, &ctx);
遍历二元操作符的常量操作数,由运行时转化为编译时(反向pass2)
实际优化pass,zend_optimize
遍历二元操作符的常量操作数,由编译时转化为运行时(pass2)
|遍历op_array内函数zend_optimize_op_array(op_array, &ctx);
|遍历类内非用户函数zend_optimize_op_array(op_array, &ctx);
(用户函数设static_variables)
|若使用DFA pass & 调用图pass & 构建调用图成功
遍历二元操作符的常量操作数,由运行时转化为编译时(反向pass2)
设置函数返回值信息,供SSA数据流分析使用
遍历调用图的op_array,做DFA分析zend_dfa_analyze_op_array
遍历调用图的op_array,做DFA优化zend_dfa_optimize_op_array
若开调试,遍历dump调用图的每一个op_array(优化变换后)
若开栈矫正优化,矫正栈大小adjust_fcall_stack_size_graph
再次遍历调用图内的的所有op_array,
针对DFA pass变换后新产生的常量场景,常量优化pass2再跑一遍
调用图op_array资源清理
|若开栈矫正优化
矫正栈大小main_op_array
遍历矫正栈大小op_array
|清理资源该部分主要调用了SSA/DFA/CFG这几类用于opcode分析pass,涉及的pass有BB块、CFG、DFA(CFG、DOMINATORS、LIVENESS、PHI-NODE、SSA)。
用于opcode转换的pass则集中在函数zend_optimize内,如下:
zend_optimize |op_array类型为ZEND_EVAL_CODE,不做优化 |开debug, 可dump优化前内容 |优化pass1, 常量替换、编译时常量操作变换、简单操作转换 |优化pass2 常量操作转换、条件跳转指令优化 |优化pass3 跳转指令优化、自增转换 |优化pass4 函数调用优化(主要为函数调用优化) |优化pass5 控制流图(CFG)优化 |构建流图 |计算数据依赖 |划分BB块(basic block,简称BB,数据流分析基本单位) |BB块内基于数据流分析优化 |BB块间跳转优化 |不可到达BB块删除 |BB块合并 |BB块外变量检查 |重新构建优化后的op_array(基于CFG) |析构CFG |优化pass6/7 数据流分析优化 |数据流分析(基于静态单赋值SSA) |构建SSA |构建CFG 需要找到对应BB块序号、管理BB块数组、计算BB块后继BB、标记可到达BB块、计算BB块前驱BB |计算Dominator树 |标识循环是否可简化(主要依赖于循环回边) |基于phi节点构建完SSA def集、phi节点位置、SSA构造重命名 |计算use-def链 |寻找不当依赖、后继、类型及值范围值推断 |数据流优化 基于SSA信息,一系列BB块内opcode优化 |析构SSA |优化pass9 临时变量优化 |优化pass10 冗余nop指令删除 |优化pass11 压缩常量表优化
还有其他一些优化遍如下:
优化pass12 矫正栈大小 优化pass15 收集常量信息 优化pass16 函数调用优化,主要是函数内联优化
除此之外,pass 8/13/14可能为预留pass id。由此可看出当前提供给用户选项控制的opcode转换pass有13个。但是这并不计入其依赖的数据流/控制流的分析pass。
通常在函数调用过程中,由于需要进行不同栈帧间切换,因此会有开辟栈空间、保存返回地址、跳转、返回到调用函数、返回值、回收栈空间等一系列函数调用开销。因此对于函数体适当大小情况下,把整个函数体嵌入到调用者(Caller)内部,从而不实际调用被调用者(Callee)是一个提升性能的利器。
由于函数调用与目标机的应用二进制接口(ABI)强相关,静态编译器如GCC/LLVM的函数内联优化基本是在指令生成之前完成。
ZendVM的内联则发生在opcode生成后的FCALL指令的替换优化,pass id为16,其原理大致如下:
| 遍历op_array中的opcode,找到DO_XCALL四个opcode之一
| opcode ZEND_INIT_FCALL
| opcode ZEND_INIT_FCALL_BY_NAMEZ
| 新建opcode,操作码置为ZEND_INIT_FCALL,计算栈大小,
更新缓存槽位,析构常量池字面量,替换当前opline的opcode
| opcode ZEND_INIT_NS_FCALL_BY_NAME
| 新建opcode,操作码置为ZEND_INIT_FCALL,计算栈大小,
更新缓存槽位,析构常量池字面量,替换当前opline的opcode
| 尝试函数内联
| 优化条件过滤 (每个优化pass通常有较多限制条件,某些场景下
由于缺乏足够信息不能优化或出于代价考虑而排除)
| 方法调用ZEND_INIT_METHOD_CALL,直接返回不内联
| 引用传参,直接返回不内联
| 缺省参数为命名常量,直接返回不内联
| 被调用函数有返回值,添加一条ZEND_QM_ASSIGN赋值opcode
| 被调用函数无返回值,插入一条ZEND_NOP空opcode
| 删除调用被内联函数的call opcode(即当前online的前一条opcode)如下示例代码,当调用fname()时,使用字符串变量名fname来动态调用函数foo,而没有使用直接调用的方式。此时可通过VLD扩展查看其生成的opcode,或打开opcache调试选项(opcache.optdebuglevel=0xFFFFFFFF)亦可查看。
function foo() { }
$fname = 'foo';开启debug后dump可看出,发生函数调用优化前opcode序列(仅截取片段)为:
ASSIGN CV0($fname) string("foo")
INIT_FCALL_BY_NAME 0 CV0($fname)
DO_FCALL_BY_NAMEINIT_FCALL_BY_NAME这条opcode执行逻辑较为复杂,当开启激进内联优化后,可将上述指令序列直接合并成一条DO_FCALL string("foo")指令,省去间接调用的开销。这样也恰好与直接调用生成的opcode一致。
根据以上描述,可见向当前优化器加入一个pass并不会太难,大体步骤如下:
先向zend_optimize优化器注册一个pass宏(例如添加pass17),并决定其优化级别。
在优化管理器某个优化pass前后调用加入的pass(例如添加一个尾递归优化pass),建议在DFA/SSA分析pass之后添加,因为此时获得的优化信息更多。
实现新加入的pass,进行定制代码转换(例如zendoptimizefunc_calls实现一个尾递归优化)。针对当前已有pass,主要添加转换pass,这里一般也可利用SSA/DFA的信息。不同于静态编译优化一般是在贴近于机器相关的低层中间表示优化,这里主要是在opcode层的opcode/operand相应的一些转换。
实现pass前,与函数内联类似,通常首先收集优化所需信息,然后排除掉不适用该优化的一些场景(如非真正的尾不递归调用、参数问题无法做优化等)。实现优化后,可dump优化前后生成opcode结构的变化是否优化正确、是否符合预期(如尾递归优化最终的效果是变换函数调用为forloop的形式)。
以下是对基于动态的PHP脚本程序执行的一些看法,仅供参考。
由于LLVM从前端到后端,从静态编译到jit整个工具链框架的支持,使得许多语言虚拟机都尝试整合。当前PHP7时代的ZendVM官方还没采用,原因之一虚拟机opcode承载着相当复杂的分析工作。相比于静态编译器的机器码每一条指令通常只干一件事情(通常是CPU指令时钟周期),opcode的操作数(operand)由于类型不固定,需要在运行期间做大量的类型检查、转换才能进行运算,这极度影响了执行效率。即使运行时采用jit,以byte code为单位编译,编译出的字节码也会与现有解释器一条一条opcode处理类似,类型需要处理、也不能把zval值直接存在寄存器。
以函数调用为例,比较现有的opcode执行与静态编译成机器码执行的区别,如下图:
在不改变现有opcode设计的前提下,加强类型推断能力,进而为opcode的执行提供更多的类型信息,是提高执行性能的可选方法之一。
既然opcode承担如此复杂的分析工作,能否将其分解成多层的opcode归一化中间表示( intermediate representation, IR)。各优化可选择应用哪一层中间表示,传统编译器的中间表示依据所携带信息量、从抽象的高级语言到贴近机器码,分成高级中间表示(HIR) 、中级中间表示(MIR)、低级中间表示(LIR)。
In Bezug auf das optimierte Pass-Management von Opcode, wie im vorherigen Artikel erwähnt, sollte es Raum für Verbesserungen geben. Obwohl die aktuelle Analyse auf der Datenfluss-/Kontrollflussanalyse basiert, mangelt es immer noch an Analysen und Optimierungen, z. B. hinsichtlich der Laufreihenfolge, der Anzahl der Durchläufe, der RegistrierungsverwVertieftes Verständnis der Opcode-Optimierung in PHP (Bilder und Text)ung, der Informationsauslagerung bei der Analyse komplexer Durchgänge usw Im Vergleich zu ausgereiften Frameworks wie llvm fehlt noch eine große Lücke.
ZendVM implementiert eine große Anzahl von ZVAL-Werten, Typkonvertierungen und anderen Vorgängen, die mit Hilfe von LLVM zur Laufzeit in Maschinencode kompiliert werden können, allerdings auf Kosten einer extrem schnellen Geschwindigkeit Erweiterung der Kompilierungszeit. Natürlich kann auch libjit verwendet werden.
Das obige ist der detaillierte Inhalt vonVertieftes Verständnis der Opcode-Optimierung in PHP (Bilder und Text). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So öffnen Sie eine PHP-Datei
So öffnen Sie eine PHP-Datei
 So entfernen Sie die ersten paar Elemente eines Arrays in PHP
So entfernen Sie die ersten paar Elemente eines Arrays in PHP
 Was tun, wenn die PHP-Deserialisierung fehlschlägt?
Was tun, wenn die PHP-Deserialisierung fehlschlägt?
 So verbinden Sie PHP mit der MSSQL-Datenbank
So verbinden Sie PHP mit der MSSQL-Datenbank
 So verbinden Sie PHP mit der MSSQL-Datenbank
So verbinden Sie PHP mit der MSSQL-Datenbank
 So laden Sie HTML hoch
So laden Sie HTML hoch
 So lösen Sie verstümmelte Zeichen in PHP
So lösen Sie verstümmelte Zeichen in PHP
 So öffnen Sie PHP-Dateien auf einem Mobiltelefon
So öffnen Sie PHP-Dateien auf einem Mobiltelefon








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



