
 Backend-Entwicklung
Python-Tutorial
Beispielanalyse der Erstellung, Zuweisung und Aktualisierungs- und Löschvorgänge von Python-Tupeln
Backend-Entwicklung
Python-Tutorial
Beispielanalyse der Erstellung, Zuweisung und Aktualisierungs- und Löschvorgänge von Python-Tupeln
Beispielanalyse der Erstellung, Zuweisung und Aktualisierungs- und Löschvorgänge von Python-Tupeln

In diesem Artikel werden hauptsächlich die Betriebsmethoden von Python-Tupeln vorgestellt und die Erstellung, Zuweisung, Aktualisierung, Löschung und andere Vorgänge von Tupeln in Python sowie die damit verbundenen Vorsichtsmaßnahmen anhand spezifischer Beispiele analysiert
Die Beispiele in diesem Artikel beschreiben Python-Tupeloperationen. Teilen Sie es als Referenz mit allen. Die Details lauten wie folgt:
#coding=utf8
'''''
元组是跟列表非常相近的另一种容器类型。
元组是一种不可变类型,一旦创建不可以修改其中元素。
由于这种特性,元组能做一个字典的key。
当处理一组对象时,这个组默认是元组类型。
'''
'''''创建元组并赋值'''
#创建并对一个元组赋值
tuple_1=(1,2,3,"ewang","demo")
#创建一个空的元组
tuple_2=()
#使用tuple创建一个元组并给元组赋值
tuple_3=tuple("hello")
#使用tuple创建一个空的元组
tuple_4=tuple()
'''''访问元组中的值'''
#通过索引使用元组中的值
print tuple_1[0], tuple_1[2], tuple_1[4]
#通过切片使用元组中的值
print tuple_3[0:3],tuple_3[0:],tuple_3[:]
#使用如下操作无法输出整个元组值
#最后一个元素无法输出
print tuple_3[:-1]
'''''
元组是不可变类型,不能更新或者改变元组的元素。
通过现有字符串的片段在构造一个新的字符串的方式来等同于更新元组操作。
'''
#通过索引更新
tuple_1=tuple_1[0],tuple_1[2],tuple_1[4]
print tuple_1
#通过切片更新
tuple_1=tuple_1[0:2]
print tuple_1
'''''
删除一个单独的元组元素是不可能的。
当然,把不需要的元素丢弃后,重新组成一个元组是没有问题的。
要显示地删除一整个元组,只要用del语句减少对象引用计数。
当这个引用计数达到0的时候,该对象就会被析构。
大多数时候,不需要显示的用del删除一个对象,
一出它的作用域它就会被析构。
'''
try:
del tuple_1
print tuple_1
except Exception,e:
print "The tuple_1 not exists ",e
'''''
关于元组的其他操作,与列表的大体相似,再测不做赘述。
相关的源码可以查看关于列表的操作说明。
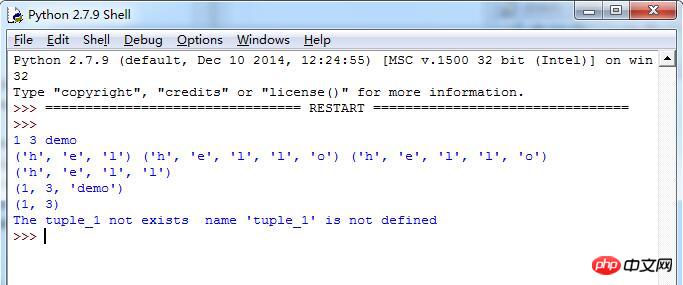
'''Laufergebnisse:
Mehr Python-bezogene Leser, die sich für den Inhalt interessieren, können sich die speziellen Themen auf dieser Website ansehen: „Klassisches Tutorial für den Einstieg in und Fortgeschrittene mit Python“, „Zusammenfassung der String-Operationsfähigkeiten in Python“, „Zusammenfassung der Python-Listenoperation“. Fertigkeiten“, „Zusammenfassung der Python-Codierungsoperationsfähigkeiten“, „Python-Datenstruktur- und Algorithmus-Tutorial“, „Zusammenfassung der Python-Funktionsverwendungsfähigkeiten“ und Zusammenfassung der Python-Datei- und Verzeichnisoperationsfähigkeiten
Das obige ist der detaillierte Inhalt vonBeispielanalyse der Erstellung, Zuweisung und Aktualisierungs- und Löschvorgänge von Python-Tupeln. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Minio-Objektspeicherung: Hochleistungs-Bereitstellung im Rahmen von CentOS System Minio ist ein hochleistungsfähiges, verteiltes Objektspeichersystem, das auf der GO-Sprache entwickelt wurde und mit Amazons3 kompatibel ist. Es unterstützt eine Vielzahl von Kundensprachen, darunter Java, Python, JavaScript und Go. In diesem Artikel wird kurz die Installation und Kompatibilität von Minio zu CentOS -Systemen vorgestellt. CentOS -Versionskompatibilitätsminio wurde in mehreren CentOS -Versionen verifiziert, einschließlich, aber nicht beschränkt auf: CentOS7.9: Bietet einen vollständigen Installationshandbuch für die Clusterkonfiguration, die Umgebungsvorbereitung, die Einstellungen von Konfigurationsdateien, eine Festplattenpartitionierung und Mini
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
 So wählen Sie die Pytorch -Version auf CentOS aus
Apr 14, 2025 pm 06:51 PM
So wählen Sie die Pytorch -Version auf CentOS aus
Apr 14, 2025 pm 06:51 PM
Bei der Installation von PyTorch am CentOS -System müssen Sie die entsprechende Version sorgfältig auswählen und die folgenden Schlüsselfaktoren berücksichtigen: 1. Kompatibilität der Systemumgebung: Betriebssystem: Es wird empfohlen, CentOS7 oder höher zu verwenden. CUDA und CUDNN: Pytorch -Version und CUDA -Version sind eng miteinander verbunden. Beispielsweise erfordert Pytorch1.9.0 CUDA11.1, während Pytorch2.0.1 CUDA11.3 erfordert. Die Cudnn -Version muss auch mit der CUDA -Version übereinstimmen. Bestimmen Sie vor der Auswahl der Pytorch -Version unbedingt, dass kompatible CUDA- und CUDNN -Versionen installiert wurden. Python -Version: Pytorch Official Branch
 So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
Die Installation von CentOS-Installationen erfordert die folgenden Schritte: Installieren von Abhängigkeiten wie Entwicklungstools, PCRE-Devel und OpenSSL-Devel. Laden Sie das Nginx -Quellcode -Paket herunter, entpacken Sie es, kompilieren Sie es und installieren Sie es und geben Sie den Installationspfad als/usr/local/nginx an. Erstellen Sie NGINX -Benutzer und Benutzergruppen und setzen Sie Berechtigungen. Ändern Sie die Konfigurationsdatei nginx.conf und konfigurieren Sie den Hörport und den Domänennamen/die IP -Adresse. Starten Sie den Nginx -Dienst. Häufige Fehler müssen beachtet werden, z. B. Abhängigkeitsprobleme, Portkonflikte und Konfigurationsdateifehler. Die Leistungsoptimierung muss entsprechend der spezifischen Situation angepasst werden, z. B. das Einschalten des Cache und die Anpassung der Anzahl der Arbeitsprozesse.
