

Beispiel-Tutorial für einen Python-Crawling-Artikel
Dieser Artikel führt Sie hauptsächlich in die relevanten Informationen zur Verwendung von Python zum Crawlen von Artikeln auf Prosa-Websites ein. Die Einführung im Artikel ist sehr detailliert und bietet einen gewissen Referenz- und Lernwert für alle Freunde, die sie benötigen.
Dieser Artikel stellt Ihnen hauptsächlich die relevanten Inhalte zu Python-Crawling-Prosa-Netzwerkartikeln vor. Er wird als Referenz und zum Studium zur Verfügung gestellt:
Das Rendering ist wie folgt:

Konfigurieren Sie Python 2.7
bs4 requests
Installation mit pipsudo pip install bs4
sudo pip install requests
Da es Webseiten crawlt, werde ich es tun Führen Sie find und find_all ein.
Der Unterschied zwischen find und find_all besteht darin, dass das, was zurückgegeben wird, unterschiedlich ist; find gibt das erste übereinstimmende Tag zurück und der Inhalt im Tag
find_all gibt eine Liste zurück
Beispielsweise schreiben wir eine test.html, um den Unterschied zwischen find und find_all zu testen.
Der Inhalt ist:
<html> <head> </head> <body> <p id="one"><a></a></p> <p id="two"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >abc</a></p> <p id="three"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >three a</a></p> <p id="four"><a href="#" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >four<p>four p</p><p>four p</p><p>four p</p> a</a></p> </body> </html>
Dann lautet der Code von test.py:
from bs4 import BeautifulSoup import lxml if __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('p') print s.find_all('p') print "------------------------------" print s.find('p',id='one') print s.find_all('p',id='one') print "------------------------------" print s.find('p',id="two") print s.find_all('p',id="two") print "------------------------------" print s.find('p',id="three") print s.find_all('p',id="three") print "------------------------------" print s.find('p',id="four") print s.find_all('p',id="four") print "------------------------------"
Nach dem Ausführen können wir das Ergebnis sehen. Beim Abrufen einer Gruppe von Tags wird der Unterschied zwischen den beiden angezeigt .
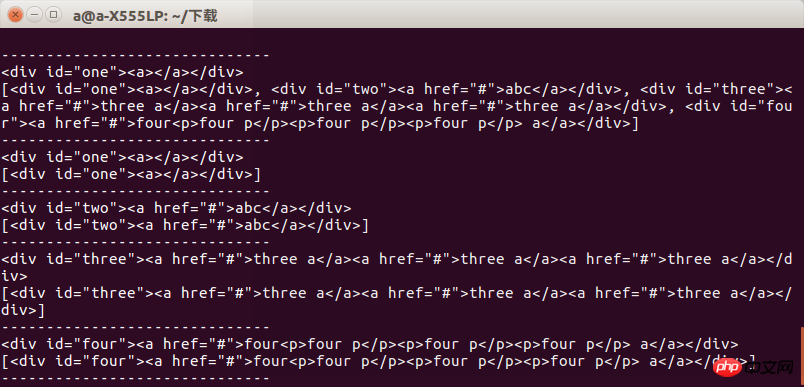
Wir müssen also darauf achten, was wir wollen, wenn wir es verwenden, sonst erscheint ein Fehler
Der nächste Schritt ist es, Webseiteninformationen durch Anfragen zu erhalten. Warum schreibe ich gehörte und andere Dinge? Ich greife direkt auf die Webseite zu und erhalte mehrere klassifizierte sekundäre Webseiten Durch die Methode get und dann einen Gruppentest bestehen, um alle Webseiten zu crawlen
In diesem Teil des Codes habe ich das
def get_html():
url = "https://www.sanwen.net/"
two_html = ['sanwen','shige','zawen','suibi','rizhi','novel']
for doc in two_html:
i=1
if doc=='sanwen':
print "running sanwen -----------------------------"
if doc=='shige':
print "running shige ------------------------------"
if doc=='zawen':
print 'running zawen -------------------------------'
if doc=='suibi':
print 'running suibi -------------------------------'
if doc=='rizhi':
print 'running ruzhi -------------------------------'
if doc=='nove':
print 'running xiaoxiaoshuo -------------------------'
while(i<10):
par = {'p':i}
res = requests.get(url+doc+'/',params=par)
if res.status_code==200:
soup(res.text)
i+=ires.status_codeDer Maximalwert von p ist 10. Ich verstehe das nicht Als ich die Festplatte das letzte Mal gecrawlt habe, waren es 100 Seiten. Vergessen Sie es und analysieren Sie es später. Rufen Sie dann den Inhalt jeder Seite über die get-Methode ab.
Nachdem Sie den Inhalt jeder Seite erhalten haben, analysieren Sie den Autor und den Titel. Der Code sieht so aus:
Es gibt einen Ich möchte euch fragen, warum ihr nicht nur einen, sondern auch zwei Schrägstriche in den Dateinamen einfügt, als ich die Datei später schrieb. Also habe ich einen regulären Ausdruck geschrieben und werde ihn Ihnen geben. Ändern Sie Ihre Karriere.
def soup(html_text): s = BeautifulSoup(html_text,'lxml') link = s.find('p',class_='categorylist').find_all('li') for i in link: if i!=s.find('li',class_='page'): title = i.find_all('a')[1] author = i.find_all('a')[2].text url = title.attrs['href'] sign = re.compile(r'(//)|/') match = sign.search(title.text) file_name = title.text if match: file_name = sign.sub('a',str(title.text))
Der letzte Schritt besteht darin, den Prosainhalt zu erhalten, indem wir die Artikeladresse analysieren und dann den Inhalt erhalten, den ich ursprünglich einzeln erhalten wollte die Webadresse, was Ärger erspart.
Schreiben Sie abschließend die Datei und speichern Sie sie in Ordnung
def get_content(url): res = requests.get('https://www.sanwen.net'+url) if res.status_code==200: soup = BeautifulSoup(res.text,'lxml') contents = soup.find('p',class_='content').find_all('p') content = '' for i in contents: content+=i.text+'\n' return content
Drei Funktionen, um die zu erhalten Prosa-Netzwerk Prosa, aber es gibt ein Problem, dass ich nicht weiß, warum einige Artikel verloren gehen. Dies unterscheidet sich stark von den Artikeln auf Prose.com Seite für Seite. Ich hoffe, jemand kann mir bei diesem Problem helfen. Vielleicht sollten wir die Webseite unzugänglich machen. Natürlich denke ich, dass es etwas mit dem kaputten Netzwerk in meinem Wohnheim zu tun hat
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
Ich hätte das Rendering fast vergessen
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
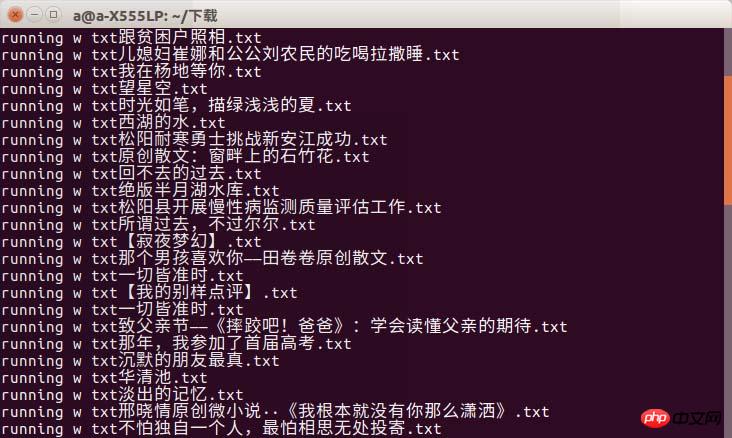 Es kann zu einem Timeout-Phänomen kommen. Ich kann nur sagen, dass Sie eine gute Internetverbindung wählen müssen, wenn Sie zur Uni gehen!
Es kann zu einem Timeout-Phänomen kommen. Ich kann nur sagen, dass Sie eine gute Internetverbindung wählen müssen, wenn Sie zur Uni gehen!
Das obige ist der detaillierte Inhalt vonBeispiel-Tutorial für einen Python-Crawling-Artikel. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 Was ist der Grund, warum PS immer wieder Laden zeigt?
Apr 06, 2025 pm 06:39 PM
Was ist der Grund, warum PS immer wieder Laden zeigt?
Apr 06, 2025 pm 06:39 PM
PS "Laden" Probleme werden durch Probleme mit Ressourcenzugriff oder Verarbeitungsproblemen verursacht: Die Lesegeschwindigkeit von Festplatten ist langsam oder schlecht: Verwenden Sie Crystaldiskinfo, um die Gesundheit der Festplatte zu überprüfen und die problematische Festplatte zu ersetzen. Unzureichender Speicher: Upgrade-Speicher, um die Anforderungen von PS nach hochauflösenden Bildern und komplexen Schichtverarbeitung zu erfüllen. Grafikkartentreiber sind veraltet oder beschädigt: Aktualisieren Sie die Treiber, um die Kommunikation zwischen PS und der Grafikkarte zu optimieren. Dateipfade sind zu lang oder Dateinamen haben Sonderzeichen: Verwenden Sie kurze Pfade und vermeiden Sie Sonderzeichen. Das eigene Problem von PS: Installieren oder reparieren Sie das PS -Installateur neu.
 Wie löst ich das Problem des Ladens beim Starten von PS?
Apr 06, 2025 pm 06:36 PM
Wie löst ich das Problem des Ladens beim Starten von PS?
Apr 06, 2025 pm 06:36 PM
Ein PS, der beim Booten auf "Laden" steckt, kann durch verschiedene Gründe verursacht werden: Deaktivieren Sie korrupte oder widersprüchliche Plugins. Eine beschädigte Konfigurationsdatei löschen oder umbenennen. Schließen Sie unnötige Programme oder aktualisieren Sie den Speicher, um einen unzureichenden Speicher zu vermeiden. Upgrade auf ein Solid-State-Laufwerk, um die Festplatte zu beschleunigen. PS neu installieren, um beschädigte Systemdateien oder ein Installationspaketprobleme zu reparieren. Fehlerinformationen während des Startprozesses der Fehlerprotokollanalyse anzeigen.
 Wie löste ich das Problem des Ladens, wenn die PS die Datei öffnet?
Apr 06, 2025 pm 06:33 PM
Wie löste ich das Problem des Ladens, wenn die PS die Datei öffnet?
Apr 06, 2025 pm 06:33 PM
Das Laden von Stottern tritt beim Öffnen einer Datei auf PS auf. Zu den Gründen gehören: zu große oder beschädigte Datei, unzureichender Speicher, langsame Festplattengeschwindigkeit, Probleme mit dem Grafikkarten-Treiber, PS-Version oder Plug-in-Konflikte. Die Lösungen sind: Überprüfen Sie die Dateigröße und -integrität, erhöhen Sie den Speicher, aktualisieren Sie die Festplatte, aktualisieren Sie den Grafikkartentreiber, deinstallieren oder deaktivieren Sie verdächtige Plug-Ins und installieren Sie PS. Dieses Problem kann effektiv gelöst werden, indem die PS -Leistungseinstellungen allmählich überprüft und genutzt wird und gute Dateimanagementgewohnheiten entwickelt werden.
 Wie kann man das Problem des Ladens lösen, wenn PS immer zeigt, dass es geladen wird?
Apr 06, 2025 pm 06:30 PM
Wie kann man das Problem des Ladens lösen, wenn PS immer zeigt, dass es geladen wird?
Apr 06, 2025 pm 06:30 PM
PS -Karte ist "Laden"? Zu den Lösungen gehören: Überprüfung der Computerkonfiguration (Speicher, Festplatte, Prozessor), Reinigen der Festplattenfragmentierung, Aktualisierung des Grafikkartentreibers, Anpassung der PS -Einstellungen, der Neuinstallation von PS und der Entwicklung guter Programmiergewohnheiten.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Wie kontrolliert PS -Federn die Weichheit des Übergangs?
Apr 06, 2025 pm 07:33 PM
Wie kontrolliert PS -Federn die Weichheit des Übergangs?
Apr 06, 2025 pm 07:33 PM
Der Schlüssel zur Federkontrolle liegt darin, seine allmähliche Natur zu verstehen. PS selbst bietet nicht die Möglichkeit, die Gradientenkurve direkt zu steuern, aber Sie können den Radius und die Gradientenweichheit flexius durch mehrere Federn, Matching -Masken und feine Selektionen anpassen, um einen natürlichen Übergangseffekt zu erzielen.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
 Was soll ich tun, wenn sich die PS -Karte in der Ladeschnittstelle befindet?
Apr 06, 2025 pm 06:54 PM
Was soll ich tun, wenn sich die PS -Karte in der Ladeschnittstelle befindet?
Apr 06, 2025 pm 06:54 PM
Die Ladeschnittstelle der PS-Karte kann durch die Software selbst (Dateibeschäftigung oder Plug-in-Konflikt), die Systemumgebung (ordnungsgemäße Treiber- oder Systemdateienbeschäftigung) oder Hardware (Hartscheibenbeschäftigung oder Speicherstickfehler) verursacht werden. Überprüfen Sie zunächst, ob die Computerressourcen ausreichend sind. Schließen Sie das Hintergrundprogramm und geben Sie den Speicher und die CPU -Ressourcen frei. Beheben Sie die PS-Installation oder prüfen Sie, ob Kompatibilitätsprobleme für Plug-Ins geführt werden. Aktualisieren oder Fallback die PS -Version. Überprüfen Sie den Grafikkartentreiber und aktualisieren Sie ihn und führen Sie die Systemdateiprüfung aus. Wenn Sie die oben genannten Probleme beheben, können Sie die Erkennung von Festplatten und Speichertests ausprobieren.
