

Tutorial zum Redis-Clusteraufbau und zur Problemlösung
In diesem Artikel erfahren Sie hauptsächlich, wie Sie einen Redis-Cluster aufbauen und auf welche Probleme Sie dabei achten müssen. Er ist sehr gut und kann jedem empfohlen werden, der ihn benötigt
Erstellen Sie hier einen 6-Knoten-Redis-Pseudocluster auf einer virtuellen Linux-Maschine. Die Idee ist sehr einfach. Öffnen Sie 6 Redis-Instanzen auf einer virtuellen Maschine, und jede Redis-Instanz hat ihren eigenen Port. In diesem Fall entspricht dies der Simulation von 6 Maschinen und dem anschließenden Aufbau eines Redis-Clusters unter Verwendung dieser 6 Instanzen.
Voraussetzung: Redis wurde installiert, das Verzeichnis ist /usr/local/redis-4.0.1. Wenn nicht, können Sie sich auf den Artikel „Redis unter Windows installieren“ beziehen. Redis unter Linux installieren
Der Der Redis-Cluster verwendet ein Ruby-Skript. Zum Ausführen des Skripts ist daher eine Ruby-Umgebung erforderlich. Redis-trib.rb entspricht redis-trib.rb im src-Verzeichnis des Redis-Quellcodes und ist ein von Redis offiziell gestartetes Tool zur Verwaltung von Redis-Clustern. Es basiert auf den von Redis bereitgestellten Cluster-Befehlen und ist in ein einfaches Paket gekapselt , bequemes und praktisches Bedienwerkzeug. also
Ruby-Umgebung installieren:
1.yum install ruby
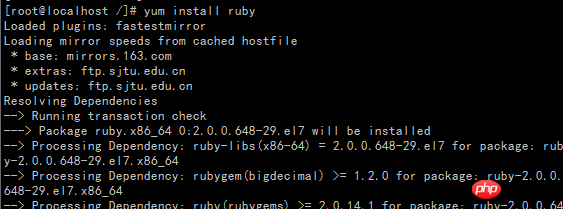
2.yum install rubygems

3.gem install redis

Centos unterstützt Ruby standardmäßig bis 2.0.0 und Redis erfordert mindestens 2.2.2. Die Lösung besteht darin, zuerst rvm zu installieren und dann die Ruby-Version auf 2.3.3 zu aktualisieren.
1.sudo yum install curl
2. Rvm installieren
> 3. curl -L get.rvm.io | bash -s stable
4. Sehen Sie sich die bekannten Ruby-Versionen in der RVM-Bibliothek ansource /usr/local/rvm/scripts/rvm
5. Installieren Sie ein Ruby Version rvm list known
6. Verwenden Sie eine Ruby-Version rvm install 2.3.3
rvm use 2.3.3 9 . Installieren Sie Redis
Redis-Cluster-Konstruktion
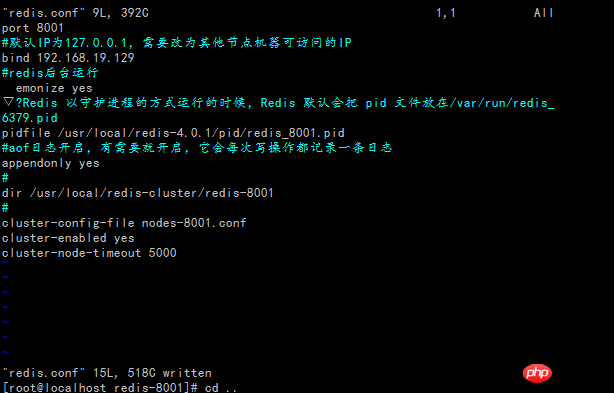
rvm remove 2.0.0 Erstellen Sie das Redis-Cluster-Verzeichnis, erstellen Sie dann die Knotenverzeichnisse Redis-8001, Redis-8002 und Redis-8003 und kopieren Sie dann die Redis -conf jeweils in die Knotenverzeichnisse
ruby --version Ändern Sie die redis-conf-Datei jeweils unter dem Knoten. Da sie sich auf einem Computer befindet (192.16819.129), sollte jede Instanz eine haben unterschiedliche Ports; gleichzeitig wird jede Instanz ihren eigenen Speicherort für Daten haben; schalten Sie den Hintergrundmodus ein; Schalten Sie den Redis-Dienst ein und prüfen Sie, ob er gestartet werden kann. ok, kein Problem.
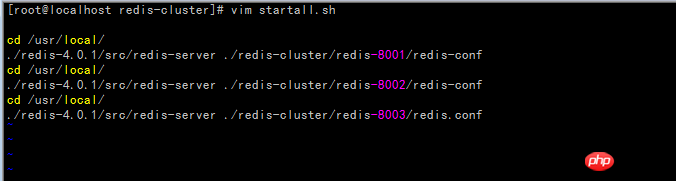
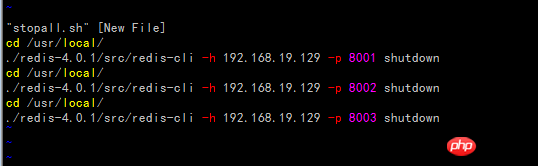
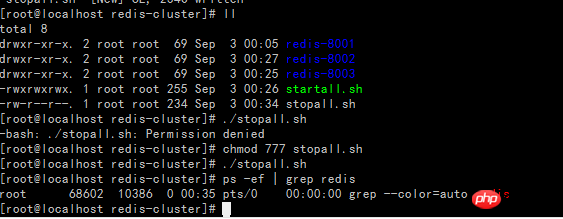
gem install redis Erstellen Sie das Skript startall.sh (die Eingabeaufforderung „Berechtigung verweigert“ weist auf unzureichende Berechtigungen hin, führen Sie den Befehl chmod 777 startall.sh aus, um die Berechtigungen zu ändern)
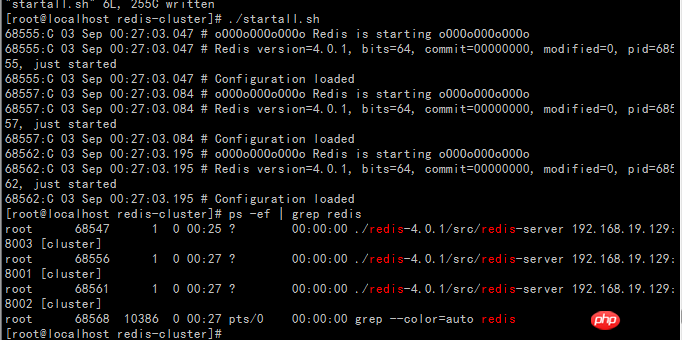
Starten Sie das startall.sh-Skript

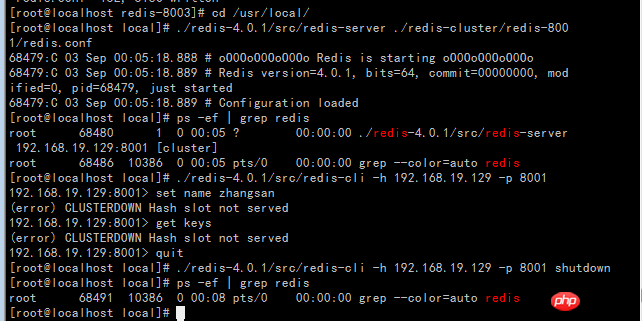 Cluster erstellen
Cluster erstellen
create: Erstellen Sie einen Cluster
Info: Cluster-Informationen anzeigen
Behebung: Reparieren Sie den Cluster
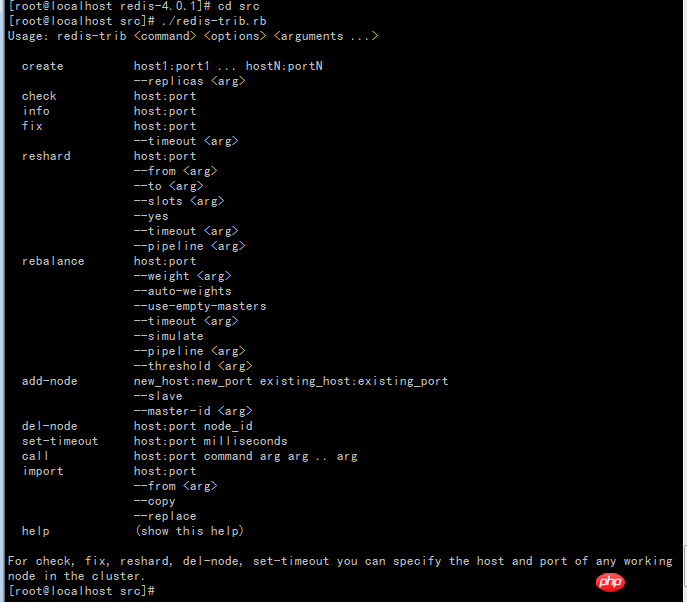
- Rebalancing: Anzahl der Clusterknoten-Slots ausgleichen
- Hinzufügen- node: Neue Knoten zum Cluster hinzufügen
- del-node: Knoten aus dem Cluster löschen
- set-timeout: Legen Sie das Timeout für fest die Heartbeat-Verbindung zwischen Cluster-Knoten
- Aufruf: Führen Sie den Befehl auf allen Knoten im Cluster aus
- import: Importieren Sie externe Redis-Daten in den Cluster
redis-trib.rb hat hauptsächlich zwei Klassen: ClusterNode und RedisTrib . ClusterNode speichert die Informationen jedes Knotens, RedisTrib ist die Implementierung jeder Funktion von redis-trib.rb

Hinweis: fordert mindestens 3 Master-Clusterknoten auf, Zuvor wurde gesagt, dass 6 erstellt wurden, aber im tatsächlichen Betrieb habe ich nur 3 Knoten erstellt. Daraus kann geschlossen werden, dass wir beim Erstellen eines Redis-Clusters mindestens drei Master-Knoten benötigen, und es sollte eine ungerade Zahl sein, also nicht Seien Sie nicht faul und erstellen Sie drei weitere.
Besonderer Hinweis: Der Schlüssel hier ist der optionale Replikas-Parameter --replicas 2 bedeutet, jedem Master 2 Slaves zuzuweisen. Es kann erfolgreich erstellt werden, ohne diesen Parameter auszufüllen, daher gibt es drei Master. Wir werden den Replicas-Parameter später vorstellen
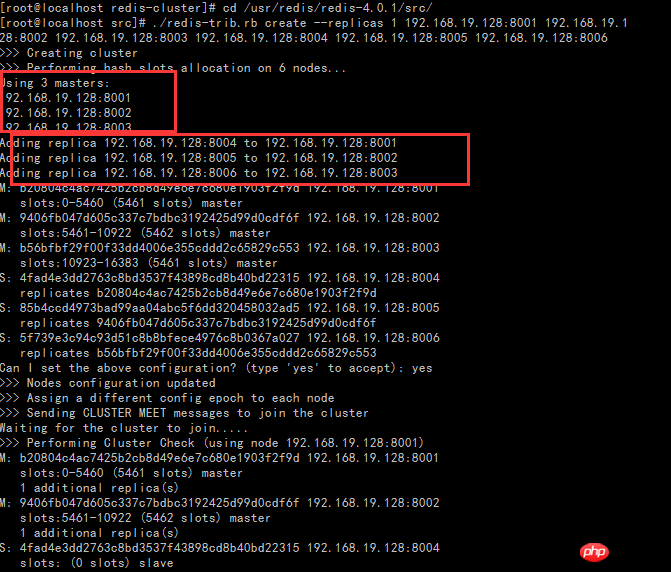
Zuallererst stellt --replicas 1 1 tatsächlich ein Verhältnis dar, das die Anzahl von angibt Master-Knoten/ Der Anteil der Slave-Knoten. Denken Sie also darüber nach, welche Knoten beim Erstellen eines Clusters die Masterknoten sind. Welche Knoten sind Slave-Knoten? Die Antwort ist, dass die Reihenfolge von IP:PORT im Befehl befolgt wird, zuerst 3 Master-Knoten, dann 3 Slave-Knoten.
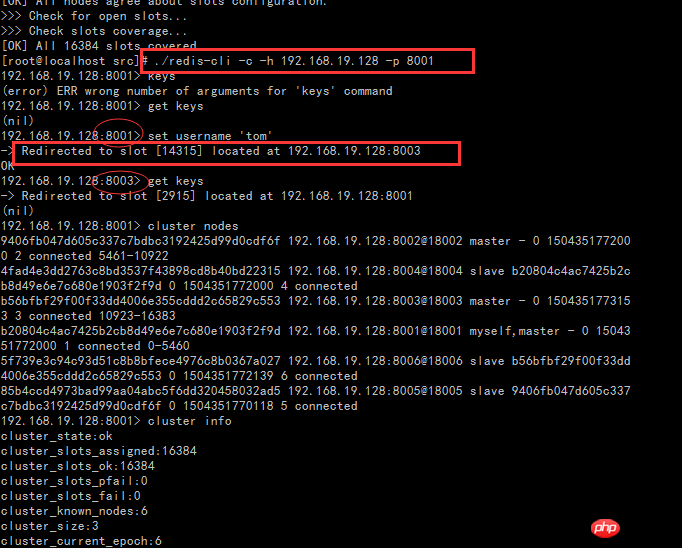
Zweitens achten Sie auf das Konzept des Slots im Bild. Für Redis-Cluster ist der Slot ein Ort zum Speichern von Daten, ein Slot. Für jeden Master gibt es einen Steckplatzbereich, für den Slave jedoch nicht. Im Redis-Cluster kann der Master weiterhin lesen und schreiben, während der Slave nur lesen kann. Das Schreiben von Daten wird tatsächlich in Slots verteilt und gespeichert, was sich vom vorherigen Master-Slave-Modus von 1.X unterscheidet (die Master/Slave-Datenspeicherung im Master-Slave-Modus ist vollständig konsistent), weil 3 Die Datenspeicherung jedes Masters ist anders. Dies wird in nachfolgenden Aufsätzen überprüft.
Das obige ist der detaillierte Inhalt vonTutorial zum Redis-Clusteraufbau und zur Problemlösung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
So erstellen Sie den Redis -Clustermodus
Apr 10, 2025 pm 10:15 PM
Der Redis -Cluster -Modus bietet Redis -Instanzen durch Sharding, die Skalierbarkeit und Verfügbarkeit verbessert. Die Bauschritte sind wie folgt: Erstellen Sie ungerade Redis -Instanzen mit verschiedenen Ports; Erstellen Sie 3 Sentinel -Instanzen, Monitor -Redis -Instanzen und Failover; Konfigurieren von Sentinel -Konfigurationsdateien, Informationen zur Überwachung von Redis -Instanzinformationen und Failover -Einstellungen hinzufügen. Konfigurieren von Redis -Instanzkonfigurationsdateien, aktivieren Sie den Cluster -Modus und geben Sie den Cluster -Informationsdateipfad an. Erstellen Sie die Datei nodes.conf, die Informationen zu jeder Redis -Instanz enthält. Starten Sie den Cluster, führen Sie den Befehl erstellen aus, um einen Cluster zu erstellen und die Anzahl der Replikate anzugeben. Melden Sie sich im Cluster an, um den Befehl cluster info auszuführen, um den Clusterstatus zu überprüfen. machen
 So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten
Apr 10, 2025 pm 10:06 PM
So löschen Sie Redis -Daten: Verwenden Sie den Befehl Flushall, um alle Schlüsselwerte zu löschen. Verwenden Sie den Befehl flushdb, um den Schlüsselwert der aktuell ausgewählten Datenbank zu löschen. Verwenden Sie SELECT, um Datenbanken zu wechseln, und löschen Sie dann FlushDB, um mehrere Datenbanken zu löschen. Verwenden Sie den Befehl del, um einen bestimmten Schlüssel zu löschen. Verwenden Sie das Redis-Cli-Tool, um die Daten zu löschen.
 So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
So verwenden Sie den Befehl Redis
Apr 10, 2025 pm 08:45 PM
Die Verwendung der REDIS -Anweisung erfordert die folgenden Schritte: Öffnen Sie den Redis -Client. Geben Sie den Befehl ein (Verbschlüsselwert). Bietet die erforderlichen Parameter (variiert von der Anweisung bis zur Anweisung). Drücken Sie die Eingabetaste, um den Befehl auszuführen. Redis gibt eine Antwort zurück, die das Ergebnis der Operation anzeigt (normalerweise in Ordnung oder -err).
 So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
So verwenden Sie Redis Lock
Apr 10, 2025 pm 08:39 PM
Um die Operationen zu sperren, muss die Sperre durch den Befehl setNX erfasst werden und dann den Befehl Ablauf verwenden, um die Ablaufzeit festzulegen. Die spezifischen Schritte sind: (1) Verwenden Sie den Befehl setNX, um zu versuchen, ein Schlüsselwertpaar festzulegen; (2) Verwenden Sie den Befehl Ablauf, um die Ablaufzeit für die Sperre festzulegen. (3) Verwenden Sie den Befehl Del, um die Sperre zu löschen, wenn die Sperre nicht mehr benötigt wird.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
So implementieren Sie die zugrunde liegenden Redis
Apr 10, 2025 pm 07:21 PM
Redis verwendet Hash -Tabellen, um Daten zu speichern und unterstützt Datenstrukturen wie Zeichenfolgen, Listen, Hash -Tabellen, Sammlungen und geordnete Sammlungen. Ernähren sich weiterhin über Daten über Snapshots (RDB) und appendiert Mechanismen nur Schreibmechanismen. Redis verwendet die Master-Slave-Replikation, um die Datenverfügbarkeit zu verbessern. Redis verwendet eine Ereignisschleife mit einer Thread, um Verbindungen und Befehle zu verarbeiten, um die Datenatomizität und Konsistenz zu gewährleisten. Redis legt die Ablaufzeit für den Schlüssel fest und verwendet den faulen Löschmechanismus, um den Ablaufschlüssel zu löschen.
 So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
So lesen Sie den Quellcode von Redis
Apr 10, 2025 pm 08:27 PM
Der beste Weg, um Redis -Quellcode zu verstehen, besteht darin, Schritt für Schritt zu gehen: Machen Sie sich mit den Grundlagen von Redis vertraut. Wählen Sie ein bestimmtes Modul oder eine bestimmte Funktion als Ausgangspunkt. Beginnen Sie mit dem Einstiegspunkt des Moduls oder der Funktion und sehen Sie sich die Codezeile nach Zeile an. Zeigen Sie den Code über die Funktionsaufrufkette an. Kennen Sie die von Redis verwendeten Datenstrukturen. Identifizieren Sie den von Redis verwendeten Algorithmus.
