
 Datenbank
MySQL-Tutorial
Detailliertes Beispiel einer vollständigen synchronen MYSQL-Dual-Master-Datenbankreplikation
Datenbank
MySQL-Tutorial
Detailliertes Beispiel einer vollständigen synchronen MYSQL-Dual-Master-Datenbankreplikation
Detailliertes Beispiel einer vollständigen synchronen MYSQL-Dual-Master-Datenbankreplikation

Umgebung:
Der MySQL-5.7.18-Server ist auf den beiden Servern A und B installiert und so konfiguriert, dass er den Master und den Slave des anderen synchronisiert.
Die Linux-Systemversion ist CentOS7
A-Server-IP: 192.168.1.7 Hostname: test1
B-Server-IP: 192.168.1.8 Hostname: test2
(Unter demselben LAN)
1. Vorbereitung
1. Ändern Sie den Hostnamen
Befehl: hostnamectl set-hostname xxx
(Anzeigen Hostname-Befehl:Hostname)
2. Schalten Sie die Firewall aus
1) Überprüfen Sie den Firewall-Status
Befehl: firewall-cmd --state
Ergebnis: läuft
2) Die Firewall läuft, fahren Sie zuerst den Firewall-Dienst herunter
Befehl: systemctl mask firewalld
3) Schalten Sie die Firewall aus
Befehl: systemctl stop firewalld
4) Überprüfen Sie den Firewall-Status
Befehl: firewall-cmd --state
Ergebnis: läuft nicht
3. Selinux-Richtlinie deaktivieren
1) Selinux-Ausführungsstatus prüfen
Befehl: getenforce
Ergebnis: Durchsetzung

2 ) Dauerhaft heruntergefahren (Computer muss neu gestartet werden), Selinux-Datei bearbeiten vi /etc/sysconfig/selinux ändern SELINUX=disabled
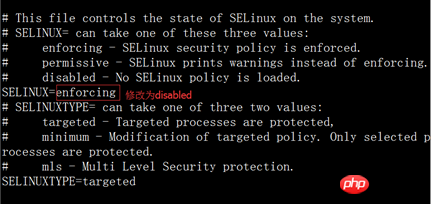
3) ist geschlossen

2. Konfiguration Master-Server (Master) Slave-Server (Slave)
1. Öffnen Sie die my.cnf-Datei vi /etc/my.cnf von Server A und fügen Sie hinzu der folgende Inhalt unter [mysqld] in der Datei
server-id=1 #Muss sich von anderen Servern unterscheiden und ein positiver Ganzzahlwert zwischen 1 und 232 sein
log-bin=mysql-bin log-bin-index=mysql-bin

Fügen Sie in der my.cnf-Datei des B-Servers den obigen Inhalt unter [mysqld] hinzu und ändern Sie nur den Server-ID-Wert.
server-id=2 log-bin=mysql-bin log-bin-index=mysql-bin
2. Erstellen Sie die vollständige Bibliothekssicherungsdatei all.sql unter dem MySQL-Installationspfad auf Server A (der RPM-Installationspfad ist /var/lib/mysql).
Befehl erstellen:
touch /var/lib/mysql/all.sql
Sicherungsbefehl:
[root@test1 mysql]# mysqldump -uroot -p123 --all-databases > /var/lib/mysql/all.sql
Kopieren Sie die all.sql-Datei in einen bestimmten Pfad auf Server B (mit /var/ lib/ MySQL-Pfad als Beispiel) zum Wiederherstellen.
Wiederherstellungsbefehl:
[root@test2 /]# mysql -uroot -p123 < /var/lib/mysql/all.sql
3. Erstellen Sie Benutzer in MySQL der Server A und B für die Synchronisierung.
Benutzer erstellen:
mysql> create user 'tongbu'@'%' identified by 'tongbu';
Autorisierung:
mysql> grant all on *.* to 'tongbu'@'%';
Benutzer löschen:
mysql> drop user '用户名'@'%';
Nachdem die A- und B-Serverbenutzer erstellt wurden , Testen Sie, ob sich Benutzer remote bei MySQL anmelden können.
[root@test1 /]# mysql -utongbu -ptongbu -h192.168.1.8 [root@test2 /]# mysql -utongbu -ptongbu -h192.168.1.7
Starten Sie den MySQL-Dienst auf den Servern A und B nach dem Testen ohne Probleme neu: [root@test /]# service mysqld restart
4. Legen Sie A als Master-Server und B als fest der Slave-Server.
1) Anzeigen des Binärprotokollnamens und des Offsetwerts in Server A mysql
Befehl: mysql> show master statusG
Wie unten gezeigt
>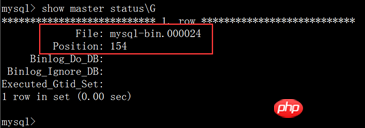
mysql> stop slave; mysql> change master to -> master_host='192.168.1.7', -> master_user='tongbu', -> master_password='tongbu', -> master_log_file='mysql-bin.000024', -> master_log_pos=154; mysql> start slave;

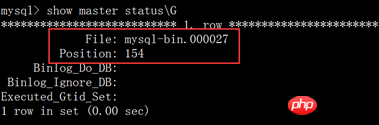
mysql> stop slave; mysql> change master to -> master_host='192.168.1.8', -> master_user='tongbu', -> master_password='tongbu', -> master_log_file='mysql-bin.000027', -> master_log_pos=154; mysql> start slave; mysql> show slave status\G 查看Slave_IO_Running和Slave_SQL_Running的值是否为Yes
Fehlerbehebung:
1. Slave_IO_Running-Statusfehler
Bei der Überprüfung von MySQL> wird der Slave_IO_Running-Status als Verbindungsfehler angezeigt. Es gibt drei Hauptgründe: Muss Überprüfen Sie die Konfiguration:
1) Das Netzwerk ist blockiert
2) Die Konfiguration der Kontoberechtigungen ist falsch, z. B. falsches Passwort, falsches Konto, falsche Adresse
3) Die Der Speicherort der Binärdatei ist falsch
2. Anomalien aufgrund von Konflikten oder Unterschieden zwischen Primär- und Sicherungsdaten
主键冲突、表已存在等错误代码如1062,1032,1060等,可以在mysql配置文件指定略过此类异常并继续下条sql同步,这样可以避免很多主从同步的异常中断。打开/etc/ mysql下的my.cnf文件,在[mysqld]后添加如下代码:
slave-skip-errors = 1062,1032,1060
3. 跳过异常恢复同步
mysql >slave stop; mysql >SET GLOBAL sql_slave_skip_counter = 1; mysql >slave start;
Das obige ist der detaillierte Inhalt vonDetailliertes Beispiel einer vollständigen synchronen MYSQL-Dual-Master-Datenbankreplikation. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 PHPs Fähigkeiten zur Verarbeitung von Big-Data-Strukturen
May 08, 2024 am 10:24 AM
PHPs Fähigkeiten zur Verarbeitung von Big-Data-Strukturen
May 08, 2024 am 10:24 AM
Fähigkeiten zur Verarbeitung von Big-Data-Strukturen: Chunking: Teilen Sie den Datensatz auf und verarbeiten Sie ihn in Blöcken, um den Speicherverbrauch zu reduzieren. Generator: Generieren Sie Datenelemente einzeln, ohne den gesamten Datensatz zu laden, geeignet für unbegrenzte Datensätze. Streaming: Lesen Sie Dateien oder fragen Sie Ergebnisse Zeile für Zeile ab, geeignet für große Dateien oder Remote-Daten. Externer Speicher: Speichern Sie die Daten bei sehr großen Datensätzen in einer Datenbank oder NoSQL.
 Wie optimiert man die MySQL-Abfrageleistung in PHP?
Jun 03, 2024 pm 08:11 PM
Wie optimiert man die MySQL-Abfrageleistung in PHP?
Jun 03, 2024 pm 08:11 PM
Die MySQL-Abfrageleistung kann durch die Erstellung von Indizes optimiert werden, die die Suchzeit von linearer Komplexität auf logarithmische Komplexität reduzieren. Verwenden Sie PreparedStatements, um SQL-Injection zu verhindern und die Abfrageleistung zu verbessern. Begrenzen Sie die Abfrageergebnisse und reduzieren Sie die vom Server verarbeitete Datenmenge. Optimieren Sie Join-Abfragen, einschließlich der Verwendung geeigneter Join-Typen, der Erstellung von Indizes und der Berücksichtigung der Verwendung von Unterabfragen. Analysieren Sie Abfragen, um Engpässe zu identifizieren. Verwenden Sie Caching, um die Datenbanklast zu reduzieren. Optimieren Sie den PHP-Code, um den Overhead zu minimieren.
 Wie verwende ich MySQL-Backup und -Wiederherstellung in PHP?
Jun 03, 2024 pm 12:19 PM
Wie verwende ich MySQL-Backup und -Wiederherstellung in PHP?
Jun 03, 2024 pm 12:19 PM
Das Sichern und Wiederherstellen einer MySQL-Datenbank in PHP kann durch Befolgen dieser Schritte erreicht werden: Sichern Sie die Datenbank: Verwenden Sie den Befehl mysqldump, um die Datenbank in eine SQL-Datei zu sichern. Datenbank wiederherstellen: Verwenden Sie den Befehl mysql, um die Datenbank aus SQL-Dateien wiederherzustellen.
 Wie füge ich mit PHP Daten in eine MySQL-Tabelle ein?
Jun 02, 2024 pm 02:26 PM
Wie füge ich mit PHP Daten in eine MySQL-Tabelle ein?
Jun 02, 2024 pm 02:26 PM
Wie füge ich Daten in eine MySQL-Tabelle ein? Mit der Datenbank verbinden: Stellen Sie mit mysqli eine Verbindung zur Datenbank her. Bereiten Sie die SQL-Abfrage vor: Schreiben Sie eine INSERT-Anweisung, um die einzufügenden Spalten und Werte anzugeben. Abfrage ausführen: Verwenden Sie die Methode query(), um die Einfügungsabfrage auszuführen. Bei Erfolg wird eine Bestätigungsmeldung ausgegeben.
 So beheben Sie den Fehler „mysql_native_password nicht geladen' unter MySQL 8.4
Dec 09, 2024 am 11:42 AM
So beheben Sie den Fehler „mysql_native_password nicht geladen' unter MySQL 8.4
Dec 09, 2024 am 11:42 AM
Eine der wichtigsten Änderungen, die in MySQL 8.4 (der neuesten LTS-Version von 2024) eingeführt wurden, besteht darin, dass das Plugin „MySQL Native Password“ nicht mehr standardmäßig aktiviert ist. Darüber hinaus entfernt MySQL 9.0 dieses Plugin vollständig. Diese Änderung betrifft PHP und andere Apps
 Wie verwende ich gespeicherte MySQL-Prozeduren in PHP?
Jun 02, 2024 pm 02:13 PM
Wie verwende ich gespeicherte MySQL-Prozeduren in PHP?
Jun 02, 2024 pm 02:13 PM
So verwenden Sie gespeicherte MySQL-Prozeduren in PHP: Verwenden Sie PDO oder die MySQLi-Erweiterung, um eine Verbindung zu einer MySQL-Datenbank herzustellen. Bereiten Sie die Anweisung zum Aufrufen der gespeicherten Prozedur vor. Führen Sie die gespeicherte Prozedur aus. Verarbeiten Sie die Ergebnismenge (wenn die gespeicherte Prozedur Ergebnisse zurückgibt). Schließen Sie die Datenbankverbindung.
 Wie erstelle ich eine MySQL-Tabelle mit PHP?
Jun 04, 2024 pm 01:57 PM
Wie erstelle ich eine MySQL-Tabelle mit PHP?
Jun 04, 2024 pm 01:57 PM
Das Erstellen einer MySQL-Tabelle mit PHP erfordert die folgenden Schritte: Stellen Sie eine Verbindung zur Datenbank her. Erstellen Sie die Datenbank, falls sie nicht vorhanden ist. Wählen Sie eine Datenbank aus. Tabelle erstellen. Führen Sie die Abfrage aus. Schließen Sie die Verbindung.
 Der Unterschied zwischen Oracle-Datenbank und MySQL
May 10, 2024 am 01:54 AM
Der Unterschied zwischen Oracle-Datenbank und MySQL
May 10, 2024 am 01:54 AM
Oracle-Datenbank und MySQL sind beide Datenbanken, die auf dem relationalen Modell basieren, aber Oracle ist in Bezug auf Kompatibilität, Skalierbarkeit, Datentypen und Sicherheit überlegen, während MySQL auf Geschwindigkeit und Flexibilität setzt und eher für kleine bis mittlere Datensätze geeignet ist. ① Oracle bietet eine breite Palette von Datentypen, ② bietet erweiterte Sicherheitsfunktionen, ③ ist für Anwendungen auf Unternehmensebene geeignet; ① MySQL unterstützt NoSQL-Datentypen, ② verfügt über weniger Sicherheitsmaßnahmen und ③ ist für kleine bis mittlere Anwendungen geeignet.
