

Einführung in den grundlegenden Python3-Crawler
Erfahrung beim Einstieg in den Python3-Basic-Crawler
Es ist das erste Mal, dass ich einen Blog schreibe, daher bin ich etwas nervös. Kommentieren Sie also nicht, wenn Sie es nicht tun Es gefällt mir nicht.
Wenn es Mängel gibt, hoffe ich, dass die Leser darauf hinweisen und ich sie korrigieren werde.
学习爬虫之前你需要了解(个人建议,铁头娃可以无视): - **少许网页制作知识,起码要明白什么标签...** - **相关语言基础知识。比如用java做爬虫起码会用Java语言,用python做爬虫起码要会用python语言...** - **一些网络相关知识。比如TCP/IP、cookie之类的知识,明白网页打开的原理。** - **国家法律。知道哪些能爬,哪些不能爬,别瞎爬。**
Wie der Titel schon sagt, verwenden alle Codes in diesem Artikel python3.6.X.
Zuerst müssen Sie das
Requests-Modul
BeautifulSoup-Modul installieren (pip3 install xxxx und es wird in Ordnung sein). (oder lxml-Modul)
Diese beiden Bibliotheken sind sehr leistungsstarke Anfragen und werden zum Senden von Webseitenanfragen und zum Öffnen von Webseiten verwendet, während beautifulsoup und lxml zum Parsen von Inhalten und zum Extrahieren Ihrer Inhalte verwendet werden wollen. BeautifulSoup bevorzugt reguläre Ausdrücke, lxml bevorzugt XPath. Da ich eher daran gewöhnt bin, die Beautifulsoup-Bibliothek zu verwenden, wird in diesem Artikel hauptsächlich die Beautifulsoup-Bibliothek verwendet, ohne zu sehr auf lxml einzugehen. (Es wird empfohlen, vor der Verwendung die Dokumentation zu lesen.)
Die Hauptstruktur des Crawlers:
Manager: Verwalten Sie die Adressen, die Sie crawlen möchten.
Downloader: Webseiteninformationen herunterladen.
Filter: Filtern Sie den benötigten Inhalt aus den heruntergeladenen Webseiteninformationen heraus.
Speicherung: Speichern Sie die heruntergeladenen Dinge dort, wo Sie sie speichern möchten. (Abhängig von der tatsächlichen Situation ist dies optional.)
Grundsätzlich können alle Webcrawler, mit denen ich in Kontakt gekommen bin, dieser Struktur nicht entkommen, von Sracpy bis Urllib. Solange Sie diese Struktur kennen, müssen Sie sie sich nicht merken. Der Vorteil dieser Kenntnis besteht darin, dass Sie beim Schreiben zumindest wissen, was Sie schreiben, und wissen, wo Sie Fehler beheben müssen.
Da ist vorne viel Unsinn... Der Text lautet wie folgt:
Dieser Artikel verwendet Crawling https://baike.baidu.com/item/Python (das Baidu Eintrag von Python als Beispiel):
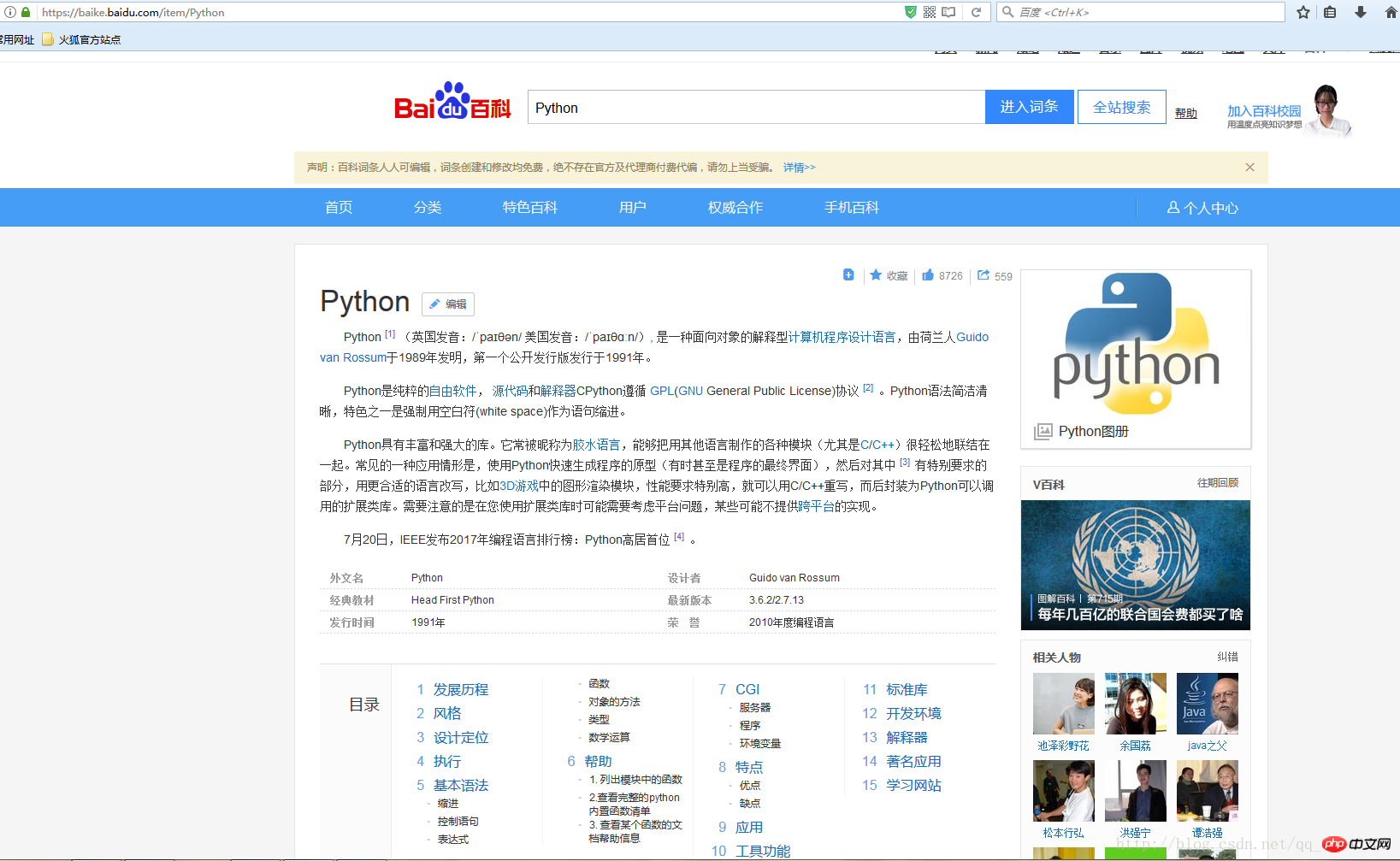
(Weil Screenshots zu mühsam sind. Dies wird das einzige Bild in diesem Artikel sein)
Wenn Sie möchten Um den Inhalt des Python-Eintrags zu crawlen, müssen Sie zunächst die URL kennen, die Sie crawlen möchten:
url = 'https://baike.baidu.com/item/Python'
Da Sie nur diese Seite crawlen müssen, ist der Manager in Ordnung.
html = request.urlopen(url)
Rufen Sie die Funktion urlopen() auf, der Downloader ist in Ordnung
Soup = BeautifulSoup(html,"html.parser")
baike = Soup.find_all("p",class_='lemma-summary')Verwenden Sie die Funktion „Beautifulsoup“ und die Funktion „find_all“ in der Bibliothek „Beautifulsoup“, der Parser ist in Ordnung
Sagen Sie etwas Hier ist der Rückgabewert der Funktion find_all eine Liste. Daher muss die Ausgabe in einer Schleife gedruckt werden.
Da dieses Beispiel nicht gespeichert werden muss, kann es direkt gedruckt werden, also:
for content in baike: print (content.get_text())
Die Funktion von get_text() besteht darin, den Text im Etikett zu extrahieren.
Ordnen Sie den obigen Code an:
import requestsfrom bs4 import BeautifulSoupfrom urllib import requestimport reif __name__ == '__main__':
url = 'https://baike.baidu.com/item/Python'
html = request.urlopen(url)
Soup = BeautifulSoup(html,"html.parser")
baike = Soup.find_all("p",class_='lemma-summary') for content in baike: print (content.get_text())Der Eintrag in der Baidu-Enzyklopädie wird angezeigt.
Ähnliche Methoden können auch einige Romane, Bilder, Schlagzeilen usw. crawlen und sind keineswegs auf Einträge beschränkt.
Wenn Sie dieses Programm nach Abschluss dieses Artikels schreiben können, herzlichen Glückwunsch, Sie fangen gleich an. Denken Sie daran, den Code niemals auswendig zu lernen.
Die Schritte werden weggelassen...Der ganze Prozess ist etwas holprig...Tut mir leid...es ist verrutscht ( ̄ー ̄)...
Das obige ist der detaillierte Inhalt vonEinführung in den grundlegenden Python3-Crawler. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Mar 18, 2024 am 09:10 AM
Mar 18, 2024 am 09:10 AM
Object-Relational Mapping (ORM)-Frameworks spielen eine wichtige Rolle in der Python-Entwicklung. Sie vereinfachen den Datenzugriff und die Datenverwaltung, indem sie eine Brücke zwischen Objekt- und relationalen Datenbanken schlagen. Um die Leistung verschiedener ORM-Frameworks zu bewerten, wird in diesem Artikel ein Vergleich mit den folgenden gängigen Frameworks durchgeführt: sqlAlchemyPeeweeDjangoORMPonyORMTortoiseORM Testmethode Der Benchmark verwendet eine SQLite-Datenbank mit 1 Million Datensätzen. Der Test führte die folgenden Vorgänge in der Datenbank durch: Einfügen: 10.000 neue Datensätze in die Tabelle einfügen. Lesen: Alle Datensätze in der Tabelle lesen. Aktualisieren: Ein einzelnes Feld für alle Datensätze in der Tabelle aktualisieren. Löschen: Alle Datensätze in der Tabelle löschen. Jeder Vorgang
 Einführung in das Yii-Framework: Verstehen Sie die Kernkonzepte von Yii
Jun 21, 2023 am 09:39 AM
Einführung in das Yii-Framework: Verstehen Sie die Kernkonzepte von Yii
Jun 21, 2023 am 09:39 AM
Das Yii-Framework ist ein leistungsstarkes, hoch skalierbares und äußerst wartbares PHP-Entwicklungsframework, das bei der Entwicklung von Webanwendungen äußerst effizient und zuverlässig ist. Der Hauptvorteil des Yii-Frameworks sind seine einzigartigen Features und Entwicklungsmethoden sowie die Integration vieler praktischer Tools und Funktionen. Das Kernkonzept des Yii-Frameworks, das MVC-Muster, übernimmt Yii das MVC-Muster (Model-View-Controller), ein Muster, das die Anwendung in drei unabhängige Teile unterteilt, nämlich das Geschäftslogik-Verarbeitungsmodell und das Präsentationsmodell der Benutzeroberfläche .
 PHP-Grundlagen-Tutorial: Vom Anfänger zum Meister
Jun 18, 2023 am 09:43 AM
PHP-Grundlagen-Tutorial: Vom Anfänger zum Meister
Jun 18, 2023 am 09:43 AM
PHP ist eine weit verbreitete serverseitige Open-Source-Skriptsprache, die alle Aufgaben in der Webentwicklung bewältigen kann. PHP wird in der Webentwicklung häufig verwendet, insbesondere wegen seiner hervorragenden Leistung bei der dynamischen Datenverarbeitung, weshalb es von vielen Entwicklern geliebt und verwendet wird. In diesem Artikel erklären wir Ihnen Schritt für Schritt die Grundlagen von PHP, um Anfängern den Einstieg bis zum Erlernen von PHP-Kenntnissen zu erleichtern. 1. Grundlegende Syntax PHP ist eine interpretierte Sprache, deren Code HTML, CSS und JavaScript ähnelt. Jede PHP-Anweisung endet mit einem Semikolon
 Mar 18, 2024 am 09:19 AM
Mar 18, 2024 am 09:19 AM
Object-Relational Mapping (ORM) ist eine Programmiertechnologie, die es Entwicklern ermöglicht, Objektprogrammiersprachen zum Bearbeiten von Datenbanken zu verwenden, ohne SQL-Abfragen direkt schreiben zu müssen. ORM-Tools in Python (wie SQLAlchemy, Peewee und DjangoORM) vereinfachen die Datenbankinteraktion für Big-Data-Projekte. Vorteile Einfachheit des Codes: ORM macht das Schreiben langwieriger SQL-Abfragen überflüssig, was die Einfachheit und Lesbarkeit des Codes verbessert. Datenabstraktion: ORM bietet eine Abstraktionsschicht, die Anwendungscode von Datenbankimplementierungsdetails isoliert und so die Flexibilität verbessert. Leistungsoptimierung: ORMs nutzen häufig Caching- und Batch-Vorgänge, um Datenbankabfragen zu optimieren und dadurch die Leistung zu verbessern. Portabilität: ORM ermöglicht Entwicklern
 Erhalten Sie ein umfassendes Verständnis von 7 häufig verwendeten Java-Designmustern
Dec 23, 2023 pm 01:01 PM
Erhalten Sie ein umfassendes Verständnis von 7 häufig verwendeten Java-Designmustern
Dec 23, 2023 pm 01:01 PM
Java-Entwurfsmuster verstehen: Eine Einführung in 7 häufig verwendete Entwurfsmuster. Es sind spezifische Codebeispiele erforderlich. Java-Entwurfsmuster sind eine universelle Lösung für Software-Entwurfsprobleme. Sie bieten eine Reihe allgemein akzeptierter Entwurfsideen und Verhaltenskodizes. Entwurfsmuster helfen uns, die Codestruktur besser zu organisieren und zu planen, wodurch der Code wartbarer, lesbarer und skalierbarer wird. In diesem Artikel stellen wir sieben häufig verwendete Entwurfsmuster in Java vor und stellen entsprechende Codebeispiele bereit. Singleton Patte
 Mar 18, 2024 am 09:25 AM
Mar 18, 2024 am 09:25 AM
Object-Relational Mapping (ORM) ist eine Technologie, die es ermöglicht, eine Brücke zwischen objektorientierten Programmiersprachen und relationalen Datenbanken zu schlagen. Die Verwendung von PythonORM kann Datenpersistenzvorgänge erheblich vereinfachen und dadurch die Effizienz und Wartbarkeit der Anwendungsentwicklung verbessern. Vorteile Die Verwendung von PythonORM bietet die folgenden Vorteile: Reduzierung des Boilerplate-Codes: ORM generiert automatisch SQL-Abfragen und vermeidet so das Schreiben einer großen Menge Boilerplate-Code. Vereinfachen Sie die Datenbankinteraktion: ORM bietet eine einheitliche Schnittstelle für die Interaktion mit der Datenbank und vereinfacht so Datenoperationen. Sicherheit verbessern: ORM verwendet parametrisierte Abfragen, die Sicherheitslücken wie SQL-Injection verhindern können. Datenkonsistenz fördern: ORM gewährleistet die Synchronisierung zwischen Objekten und Datenbanken und sorgt für die Datenkonsistenz. Wählen Sie ORM aus
 Verleihen Sie Ihren Projekten mit Python Tkinter GUI-Charme
Mar 24, 2024 am 09:46 AM
Verleihen Sie Ihren Projekten mit Python Tkinter GUI-Charme
Mar 24, 2024 am 09:46 AM
Tkinter ist eine leistungsstarke Bibliothek zum Erstellen grafischer Benutzeroberflächen (GUIs) in Python. Es ist bekannt für seine Einfachheit, plattformübergreifende Kompatibilität und nahtlose Integration in das Python-Ökosystem. Durch die Verwendung von Tkinter können Sie Ihrem Projekt eine benutzerfreundliche Oberfläche hinzufügen, die Benutzererfahrung verbessern und die Interaktion mit Ihrer Anwendung vereinfachen. Erstellen einer Tkinter-GUI-Anwendung Um eine GUI-Anwendung mit Tkinter zu erstellen, führen Sie die folgenden Schritte aus: Importieren Sie die Tkinter-Bibliothek: importtkinterask Erstellen Sie das Tkinter-Hauptfenster: root=tk.Tk() Konfigurieren Sie das Hauptfenster: Legen Sie Fenstertitel, Größe und Position fest usw. GUI-Elemente hinzufügen: Mit Tki
 Vom Anfänger zum Meister: Ein Crashkurs in Java Git
Mar 27, 2024 pm 10:41 PM
Vom Anfänger zum Meister: Ein Crashkurs in Java Git
Mar 27, 2024 pm 10:41 PM
Git ist ein verteiltes Versionskontrollsystem, das Teams bei der Zusammenarbeit bei der Softwareentwicklung unterstützt. Für Java-Entwickler ist das Verständnis von Git von entscheidender Bedeutung, da es eine Plattform zum Verwalten von Codeänderungen, zum Verfolgen des Codeverlaufs und zur Zusammenarbeit mit anderen bietet. Installieren Sie Git für Neulinge (verstehen Sie die Grundlagen): Installieren Sie die Git-Software und legen Sie Umgebungsvariablen fest. Repository erstellen: Verwenden Sie gitinit, um ein lokales Repository zu erstellen. Dateien hinzufügen: Verwenden Sie gitadd, um Dateien zum Staging-Bereich hinzuzufügen. Änderungen festschreiben: Verwenden Sie gitcommit, um Änderungen im Staging-Bereich im lokalen Repository festzuschreiben. Fortgeschrittenes Klonen eines Repositorys (Zusammenarbeit und Versionskontrolle): Verwenden Sie gitclone, um eine lokale Kopie aus einem Remote-Repository zu klonen. Verzweigung und Zusammenführung: Verwenden Sie Verzweigungen, um isolierte Kopien Ihres Codes zu erstellen
