
 Backend-Entwicklung
Python-Tutorial
Detailliertes Beispiel dafür, wie Python3 das Anforderungsmodul zum Crawlen von Seiteninhalten verwendet
Backend-Entwicklung
Python-Tutorial
Detailliertes Beispiel dafür, wie Python3 das Anforderungsmodul zum Crawlen von Seiteninhalten verwendet
Detailliertes Beispiel dafür, wie Python3 das Anforderungsmodul zum Crawlen von Seiteninhalten verwendet

Dieser Artikel stellt hauptsächlich die tatsächliche Verwendung von Python3 zum Crawlen von Seiteninhalten mithilfe des Anforderungsmoduls vor. Interessierte können mehr erfahren
1 >
Mein persönliches Desktop-System verwendet Linuxmint standardmäßig nicht, da Pip später zur Installation des Anforderungsmoduls verwendet wird.$ sudo apt install python-pip
$ pip -V
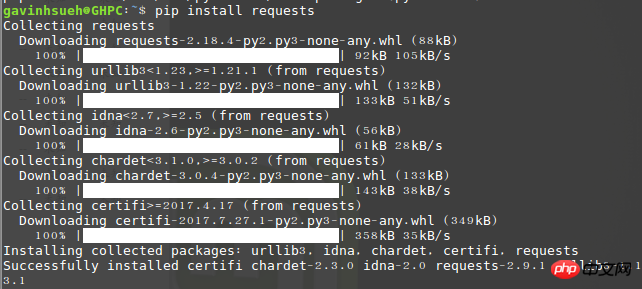
2. Anfragen installieren Modul
Hier habe ich es über pip installiert:$ pip install requests

3. Installieren Sie beautifulsoup4
Beautiful Soup ist ein Tool, das das kann kann aus der HTML- oder XML-Python-Bibliothek heruntergeladen werden, um Daten aus Dateien zu extrahieren. Es ermöglicht die übliche Dokumentennavigation und Möglichkeiten zum Suchen und Ändern von Dokumenten über Ihren bevorzugten Konverter. Beautiful Soup erspart Ihnen Stunden oder sogar Tage Arbeit.$ sudo apt-get install python3-bs4
$ sudo pip install beautifulsoup4
4.Eine kurze Analyse des Anfragemoduls
1) Senden Sie eine Anfrage Importieren Sie zunächst natürlich das Modul „Anfragen“:>>> import requests
>>> r = requests.get('http://www.jb51.net/article/124421.htm')
>>> payload = {'newwindow': '1', 'q': 'python爬虫', 'oq': 'python爬虫'}
>>> r = requests.get("https://www.google.com/search", params=payload)>>> import requests
>>> r = requests.get('https://github.com/timeline.json')
>>> r.text>>> r = requests.get('http://www.cnblogs.com/') >>> r.encoding 'utf-8'
>>> r = requests.get('http://www.cnblogs.com/') >>> r.status_code 200
5. Falldemonstration
Das Unternehmen hat kürzlich ein OA-System eingeführt, hier verwende ich das Offizielle Dokumentationsseite Nehmen Sie dies als Beispiel und erfassen Sie nur nützliche Informationen wie Artikeltitel und Inhalt auf der Seite. DemoumgebungBetriebssystem: LinuxmintPython-Version: Python 3.5.2Verwendung von Modulen: Anfragen, beautifulsoup4Code Wie folgt:#!/usr/bin/env python
# -*- coding: utf-8 -*-
_author_ = 'GavinHsueh'
import requests
import bs4
#要抓取的目标页码地址
url = 'http://www.ranzhi.org/book/ranzhi/about-ranzhi-4.html'
#抓取页码内容,返回响应对象
response = requests.get(url)
#查看响应状态码
status_code = response.status_code
#使用BeautifulSoup解析代码,并锁定页码指定标签内容
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
element = content.find_all(id='book')
print(status_code)
print(element)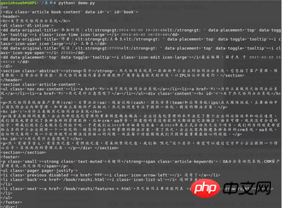
Über das Problem verstümmelter Crawling-Ergebnisse
Tatsächlich habe ich zunächst direkt Python2 verwendet, das standardmäßig mit dem System geliefert wird, aber ich hatte lange Zeit damit zu kämpfen Das Problem der verstümmelten Kodierung des zurückgegebenen Inhalts hat verschiedene Lösungen gegoogelt, aber alle waren wirkungslos. Nachdem ich von Python2 „verrückt“ gemacht wurde, hatte ich keine andere Wahl, als Python3 ehrlich zu verwenden. Bezüglich des Problems verstümmelter Inhalte in gecrawlten Seiten in Python2 sind Senioren herzlich eingeladen, ihre Erfahrungen zu teilen, um zukünftigen Generationen wie mir zu helfen, Umwege zu vermeiden.Das obige ist der detaillierte Inhalt vonDetailliertes Beispiel dafür, wie Python3 das Anforderungsmodul zum Crawlen von Seiteninhalten verwendet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1392
1392
 52
52

![WLAN-Erweiterungsmodul ist gestoppt [Fix]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) WLAN-Erweiterungsmodul ist gestoppt [Fix]
Feb 19, 2024 pm 02:18 PM
WLAN-Erweiterungsmodul ist gestoppt [Fix]
Feb 19, 2024 pm 02:18 PM
Wenn es ein Problem mit dem WLAN-Erweiterungsmodul Ihres Windows-Computers gibt, kann dies dazu führen, dass Sie nicht mehr mit dem Internet verbunden sind. Diese Situation ist oft frustrierend, aber glücklicherweise enthält dieser Artikel einige einfache Vorschläge, die Ihnen helfen können, dieses Problem zu lösen und Ihre drahtlose Verbindung wieder ordnungsgemäß funktionieren zu lassen. Behebung, dass das WLAN-Erweiterbarkeitsmodul nicht mehr funktioniert Wenn das WLAN-Erweiterbarkeitsmodul auf Ihrem Windows-Computer nicht mehr funktioniert, befolgen Sie diese Vorschläge, um das Problem zu beheben: Führen Sie die Netzwerk- und Internet-Fehlerbehebung aus, um drahtlose Netzwerkverbindungen zu deaktivieren und wieder zu aktivieren. Starten Sie den WLAN-Autokonfigurationsdienst neu. Ändern Sie die Energieoptionen. Ändern Erweiterte Energieeinstellungen Netzwerkadaptertreiber neu installieren Einige Netzwerkbefehle ausführen Schauen wir uns das nun im Detail an
 Das WLAN-Erweiterungsmodul kann nicht gestartet werden
Feb 19, 2024 pm 05:09 PM
Das WLAN-Erweiterungsmodul kann nicht gestartet werden
Feb 19, 2024 pm 05:09 PM
In diesem Artikel werden Methoden zur Behebung des Ereignisses ID10000 beschrieben, das darauf hinweist, dass das WLAN-Erweiterungsmodul nicht gestartet werden kann. Dieser Fehler kann im Ereignisprotokoll des Windows 11/10-PCs erscheinen. Das WLAN-Erweiterbarkeitsmodul ist eine Komponente von Windows, die es unabhängigen Hardwareanbietern (IHVs) und unabhängigen Softwareanbietern (ISVs) ermöglicht, Benutzern angepasste Features und Funktionen für drahtlose Netzwerke bereitzustellen. Es erweitert die Funktionalität nativer Windows-Netzwerkkomponenten durch Hinzufügen von Windows-Standardfunktionen. Das WLAN-Erweiterungsmodul wird im Rahmen der Initialisierung gestartet, wenn das Betriebssystem Netzwerkkomponenten lädt. Wenn beim WLAN-Erweiterungsmodul ein Problem auftritt und es nicht gestartet werden kann, wird möglicherweise eine Fehlermeldung im Protokoll der Ereignisanzeige angezeigt.
 So realisieren Sie die gegenseitige Konvertierung zwischen CURL- und Python-Anfragen in Python
May 03, 2023 pm 12:49 PM
So realisieren Sie die gegenseitige Konvertierung zwischen CURL- und Python-Anfragen in Python
May 03, 2023 pm 12:49 PM
Sowohl Curl als auch Pythonrequests sind leistungsstarke Tools zum Senden von HTTP-Anfragen. Während Curl ein Befehlszeilentool ist, mit dem Sie Anfragen direkt vom Terminal aus senden können, bietet die Requests-Bibliothek von Python eine eher programmatische Möglichkeit, Anfragen aus Python-Code zu senden. Die grundlegende Syntax zum Konvertieren des Curl-Befehls in den Pythonrequestscurl-Befehl lautet wie folgt: curl[OPTIONS]URL Beim Konvertieren des Curl-Befehls in eine Python-Anfrage müssen wir die Optionen und die URL in Python-Code konvertieren. Hier ist ein Beispiel für einen CurlPOST-Befehl: curl-XPOST https://example.com/api
 So verwenden Sie die Python-Crawler-Requests-Bibliothek
May 16, 2023 am 11:46 AM
So verwenden Sie die Python-Crawler-Requests-Bibliothek
May 16, 2023 am 11:46 AM
1. Installieren Sie die Anforderungsbibliothek. Python muss vorab installiert werden. Sie können die installierte Python-Version überprüfen, indem Sie den Befehl python --version ausführen um Python 3.X oder höher zu installieren. Nach der Installation von Python können Sie die Anforderungsbibliothek über den folgenden Befehl direkt installieren. pipinstallrequestsPs: Sie können zu inländischen Pip-Quellen wie Alibaba und Douban wechseln, die schnell sind. Um die Funktion zu demonstrieren, habe ich Nginx verwendet, um eine einfache Website zu simulieren. Führen Sie nach dem Herunterladen einfach das Programm nginx.exe im Stammverzeichnis aus.
 Python verwendet häufig Standardbibliotheken und Bibliotheken von Drittanbietern im 2-SYS-Modul
Apr 10, 2023 pm 02:56 PM
Python verwendet häufig Standardbibliotheken und Bibliotheken von Drittanbietern im 2-SYS-Modul
Apr 10, 2023 pm 02:56 PM
1. Einführung in das SYS-Modul Das zuvor vorgestellte OS-Modul ist hauptsächlich für das Betriebssystem gedacht, während das SYS-Modul in diesem Artikel hauptsächlich für den Python-Interpreter gedacht ist. Das sys-Modul ist ein Modul, das mit Python geliefert wird. Es ist eine Schnittstelle für die Interaktion mit dem Python-Interpreter. Das sys-Modul bietet viele Funktionen und Variablen für den Umgang mit verschiedenen Teilen der Python-Laufzeitumgebung. 2. Häufig verwendete Methoden des sys-Moduls Sie können mithilfe der dir()-Methode überprüfen, welche Methoden im sys-Modul enthalten sind: import sys print(dir(sys))1.sys.argv – Rufen Sie die Befehlszeilenparameter sys ab. argv wird verwendet, um den Befehl von außerhalb des Programms zu implementieren. Dem Programm werden Parameter übergeben und es kann die Befehlszeilenparameterspalte abrufen
 Python-Programmierung: Detaillierte Erläuterung der wichtigsten Punkte bei der Verwendung benannter Tupel
Apr 11, 2023 pm 09:22 PM
Python-Programmierung: Detaillierte Erläuterung der wichtigsten Punkte bei der Verwendung benannter Tupel
Apr 11, 2023 pm 09:22 PM
Vorwort In diesem Artikel wird weiterhin das Python-Sammlungsmodul vorgestellt. Dieses Mal werden hauptsächlich die darin enthaltenen benannten Tupel vorgestellt, dh die Verwendung von benannten Tupeln. Fangen wir ohne Umschweife an – denken Sie daran, „Gefällt mir“, „Folgen“ und „Weiterleiten“ zu markieren. Sie können überall dort verwendet werden, wo reguläre Tupel verwendet werden, und bieten die Möglichkeit, auf Felder über den Namen statt über den Positionsindex zuzugreifen. Es stammt aus den in Python integrierten Modulsammlungen. Die verwendete allgemeine Syntax lautet: Sammlungen importieren XxNamedT
 Wie Python Requests zum Anfordern von Webseiten verwendet
Apr 25, 2023 am 09:29 AM
Wie Python Requests zum Anfordern von Webseiten verwendet
Apr 25, 2023 am 09:29 AM
Requests erbt alle Funktionen von urllib2. Requests unterstützt HTTP-Verbindungspersistenz und Verbindungspooling, unterstützt die Verwendung von Cookies zur Aufrechterhaltung von Sitzungen, unterstützt das Hochladen von Dateien, unterstützt die automatische Bestimmung der Kodierung von Antwortinhalten und unterstützt internationalisierte URLs und die automatische Kodierung von POST-Daten. Die Installationsmethode verwendet pip, um $pipinstallrequests zu installieren. Grundlegende GET-Anforderungen (Header- und Parmas-Parameter) anfordern. 1. Die grundlegendste GET-Anfrage kann direkt mit der Get-Methode „response=requests.get(“http://www.baidu.com/“ verwendet werden. "
 Wie funktioniert der Import von Python?
May 15, 2023 pm 08:13 PM
Wie funktioniert der Import von Python?
May 15, 2023 pm 08:13 PM
Hallo, mein Name ist somenzz, du kannst mich Bruder Zheng nennen. Der Import von Python ist sehr intuitiv, aber manchmal werden Sie feststellen, dass trotz des Vorhandenseins des Pakets immer noch ModuleNotFoundError auftritt. Der relative Pfad ist offensichtlich sehr korrekt, aber der Fehler ImportError:attemptedrelativeimportwithnoknownparentpackage importiert ein Modul im selben Verzeichnis ein anderes. Die Module des Verzeichnisses sind völlig unterschiedlich. Dieser Artikel hilft Ihnen, den Import zu vereinfachen, indem er einige Probleme analysiert, die bei der Verwendung des Imports auftreten. Auf dieser Grundlage können Sie problemlos Attribute erstellen.
