

Der folgende Editor bringt Ihnen einen Artikel über die Implementierung des Java-Webcrawlers in Hadoop (Beispielerklärung). Der Herausgeber findet es ziemlich gut, deshalb teile ich es jetzt mit Ihnen und gebe es als Referenz. Folgen wir dem Herausgeber und werfen wir einen Blick darauf
Die Implementierung dieses Webcrawlers wird sich auf Big Data beziehen. Basierend auf den beiden vorherigen Artikeln über die Implementierung von Webcrawlern in Java und die Implementierung von Webcrawlern in Heritrix müssen wir dieses Mal eine vollständige Datenerfassung, einen Daten-Upload, eine Datenanalyse, das Lesen von Datenergebnissen und eine Datenvisualisierung durchführen.
Sie müssen
Cygwin verwenden: eine UNIX-ähnliche Simulationsumgebung, die auf der Windows-Plattform läuft, direkt online suchen, herunterladen und installieren
Hadoop: Konfigurieren Sie die Hadoop-Umgebung und implementieren Sie ein verteiltes Dateisystem (Hadoop Distributed File System), das als HDFS bezeichnet wird und zum direkten Hochladen und Speichern der gesammelten Daten in HDFS und zur anschließenden Analyse mit MapReduce verwendet wird
Eclipse: Code schreiben, Sie müssen das Hadoop-JAR-Paket importieren, um ein MapReduce-Projekt zu erstellen Jsoup: HTML-Parsing-JAR-Paket, das in Kombination mit regulären Ausdrücken den Quellcode von Webseiten besser analysieren kann; 🎜>----- >
Verzeichnis:
1. Konfigurieren Sie Cygwin2. Konfiguration Hadoop Huang Jing
3. Aufbau der Eclipse-Entwicklungsumgebung
4 )
-------->
1. Installieren und konfigurieren Sie Cygwin Laden Sie die Cygwin-Installationsdatei von der offiziellen Website herunter, Adresse: https://cygwin.com/install.html
Nach dem Herunterladen und Ausführen rufen Sie die Installationsoberfläche auf.
Laden Sie das Erweiterungspaket während der Installation direkt vom Netzwerkspiegel herunter. Sie müssen mindestens das SSH- und SSL-Unterstützungspaket auswählen
Nach der Installation rufen Sie die Cygwin-Konsolenoberfläche auf,
Führen Sie den Befehl „ssh-host-config“ aus und installieren Sie SSH
Eingabe: nein, ja, ntsec, nein, nein
Hinweis: Unter Win7 muss es in „ja, ja, ntsec“ geändert werden , nein, ja, geben Sie das Passwort ein und bestätigen Sie dies. Nach Abschluss der Schritte
wird ein Cygwin-sshd-Dienst im Windows-Betriebssystem konfiguriert und der Dienst kann gestartet werden.
 Konfigurieren Sie dann die passwortfreie SSH-Anmeldung.
Konfigurieren Sie dann die passwortfreie SSH-Anmeldung.
Führen Sie Cygwin erneut aus.
Führen Sie ssh localhost aus und Sie werden aufgefordert, sich mit einem Passwort anzumelden.
Verwenden Sie den Befehl ssh-keygen, um einen SSH-Schlüssel zu generieren, und drücken Sie zum Beenden die Eingabetaste.
Geben Sie nach der Generierung das .ssh-Verzeichnis ein und verwenden Sie den Befehl: cp id_rsa.pubauthorized_keys, um den Schlüssel zu konfigurieren.
Verwenden Sie dann „Exit“, um den Vorgang zu beenden.
Nach dem erneuten Betreten des Systems können Sie das System direkt über ssh localhost betreten, ohne ein Passwort einzugeben.
2. Konfigurieren Sie die Hadoop-Umgebung Ändern Sie die Datei hadoop-env.sh und fügen Sie die Standorteinstellung JAVA_HOME des JDK-Installationsverzeichnisses hinzu.
# The java implementation to use. Required. export JAVA_HOME=/cygdrive/c/Java/jdk1.7.0_67
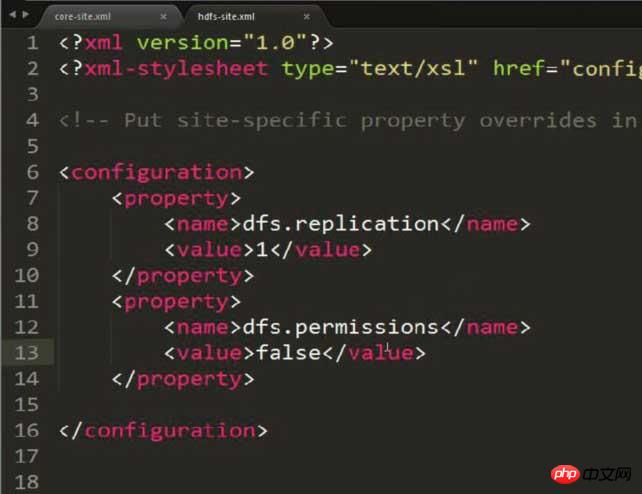
 Ändern Sie hdfs-site.xml und setzen Sie die Speicherkopie auf 1 (da die Konfiguration pseudoverteilt ist)
Ändern Sie hdfs-site.xml und setzen Sie die Speicherkopie auf 1 (da die Konfiguration pseudoverteilt ist)
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
Hinweis: Diesem Bild wurde eine zusätzliche Eigenschaft hinzugefügt, um mögliche Berechtigungsprobleme zu lösen! ! ! HDFS: Hadoop-verteiltes Dateisystem
Sie können Dateien oder Ordner dynamisch über Befehle in HDFS CRUDEN
Beachten Sie, dass möglicherweise Berechtigungen angezeigt werden. Das Problem muss behoben werden Dies kann durch die Konfiguration des folgenden Inhalts in hdfs-site.xml vermieden werden:
<property> <name>dfs.permissions</name> <value>false</value> </property>
 Modify mapred-site, set the Server- und Portnummer, auf der JobTracker ausgeführt wird (da es derzeit auf diesem Computer ausgeführt wird, schreiben Sie einfach localhost direkt, und der Port kann an jeden inaktiven Port gebunden werden)
Modify mapred-site, set the Server- und Portnummer, auf der JobTracker ausgeführt wird (da es derzeit auf diesem Computer ausgeführt wird, schreiben Sie einfach localhost direkt, und der Port kann an jeden inaktiven Port gebunden werden)
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
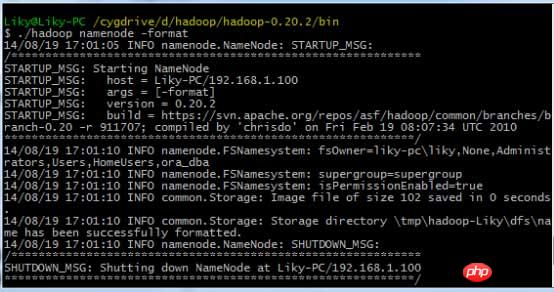
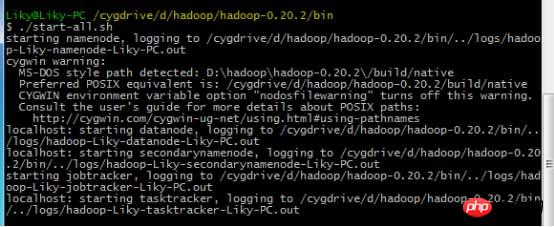
 in Cygwin ein, formatieren Sie das HDFS-Dateisystem im Bin-Verzeichnis (muss vor der ersten Verwendung formatiert werden) und geben Sie dann den Startbefehl ein:
in Cygwin ein, formatieren Sie das HDFS-Dateisystem im Bin-Verzeichnis (muss vor der ersten Verwendung formatiert werden) und geben Sie dann den Startbefehl ein:
3. Einrichtung der Eclipse-Entwicklungsumgebung
Die Die allgemeine Konfigurationsmethode ist in dem Blog beschrieben, den ich über die Bereitstellung von Big Data [2] und das Lesen und Schreiben von Dateien (einschließlich Eclipse-Hadoop-Konfiguration) geschrieben habe. Es muss jedoch zu diesem Zeitpunkt verbessert werden.Kopieren Sie das Hadoop-Eclipse-plugin.jar-Unterstützungspaket in Hadoop in das Plugin-Verzeichnis von Eclipse, um Hadoop-Unterstützung zu Eclipse hinzuzufügen.
Nachdem Sie Eclipse gestartet haben, wechseln Sie zur MapReduce-Oberfläche.
在windows工具选项选择showviews的others里面查找map/reduce locations。
在Map/Reduce Locations窗口中建立一个Hadoop Location,以便与Hadoop进行关联。

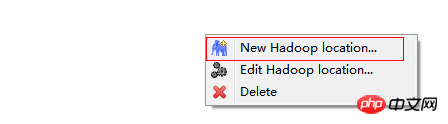
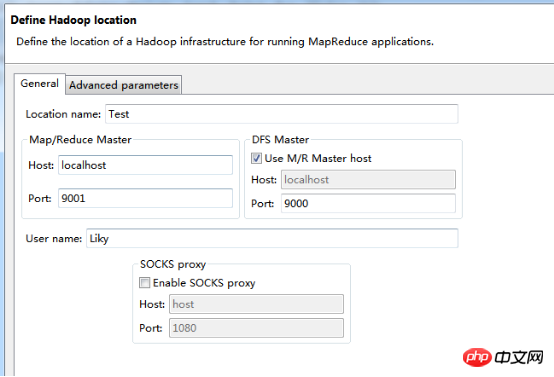
注意:此处的两个端口应为你配置hadoop的时候设置的端口!!!
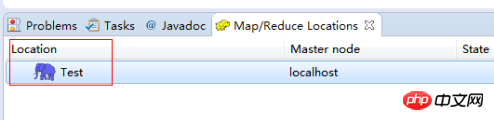
完成后会建立好一个Hadoop Location
在左侧的DFS Location中,还可以看到HDFS中的各个目录
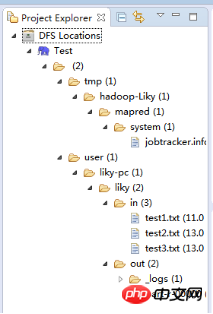
并且你可以在其目录下自由创建文件夹来存取数据。
下面你就可以创建mapreduce项目了,方法同正常创建一样。
4、网络数据爬取
现在我们通过编写一段程序,来将爬取的新闻内容的有效信息保存到HDFS中。
此时就有了两种网络爬虫的方法:
其一就是利用heritrix工具获取的数据;
其一就是java代码结合jsoup编写的网络爬虫。
方法一的信息保存到HDFS:
直接读取生成的本地文件,用jsoup解析html,此时需要将jsoup的jar包导入到项目中。
package org.liky.sina.save;
//这里用到了JSoup开发包,该包可以很简单的提取到HTML中的有效信息
import java.io.File;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class SinaNewsData {
private static Configuration conf = new Configuration();
private static FileSystem fs;
private static Path path;
private static int count = 0;
public static void main(String[] args) {
parseAllFile(new File(
"E:/heritrix-1.12.1/jobs/sina_news_job_02-20170814013255352/mirror/"));
}
public static void parseAllFile(File file) {
// 判断类型
if (file.isDirectory()) {
// 文件夹
File[] allFile = file.listFiles();
if (allFile != null) {
for (File f : allFile) {
parseAllFile(f);
}
}
} else {
// 文件
if (file.getName().endsWith(".html")
|| file.getName().endsWith(".shtml")) {
parseContent(file.getAbsolutePath());
}
}
}
public static void parseContent(String filePath) {
try {
//用jsoup的方法读取文件路径
Document doc = Jsoup.parse(new File(filePath), "utf-8");
//读取标题
String title = doc.title();
Elements descElem = doc.getElementsByAttributeValue("name",
"description");
Element descE = descElem.first();
// 读取内容
String content = descE.attr("content");
if (title != null && content != null) {
//通过Path来保存数据到HDFS中
path = new Path("hdfs://localhost:9000/input/"
+ System.currentTimeMillis() + ".txt");
fs = path.getFileSystem(conf);
// 建立输出流对象
FSDataOutputStream os = fs.create(path);
// 使用os完成输出
os.writeChars(title + "\r\n" + content);
os.close();
count++;
System.out.println("已经完成" + count + " 个!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}Das obige ist der detaillierte Inhalt vonEinführung in die Implementierungsmethode des Java-Webcrawlers in Hadoop. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



