
 Backend-Entwicklung
Python-Tutorial
Detailliertes Beispiel für Python3, das das Anforderungsmodul zum Crawlen von Seiteninhalten verwendet
Backend-Entwicklung
Python-Tutorial
Detailliertes Beispiel für Python3, das das Anforderungsmodul zum Crawlen von Seiteninhalten verwendet
Detailliertes Beispiel für Python3, das das Anforderungsmodul zum Crawlen von Seiteninhalten verwendet
Dieser Artikel stellt hauptsächlich die tatsächliche Verwendung von Python3 zum Crawlen von Seiteninhalten vor. Interessierte können mehr erfahren
1 >
Mein persönliches Desktop-System verwendet Linuxmint standardmäßig nicht, da Pip später zur Installation des Anforderungsmoduls verwendet wird.$ sudo apt install python-pip
$ pip -V
2. Anfragen installieren Modul
Hier habe ich es über pip installiert:$ pip install requests
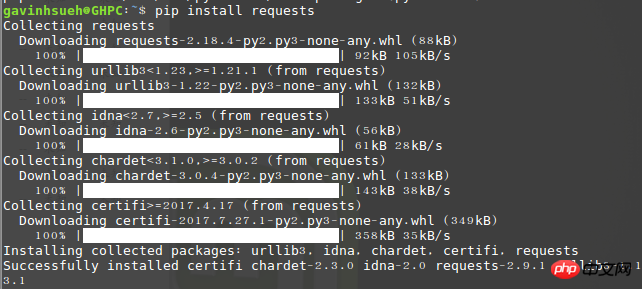

3. Installieren Sie beautifulsoup4
Beautiful Soup ist ein Tool, das das kann kann aus der HTML- oder XML-Python-Bibliothek heruntergeladen werden, um Daten aus Dateien zu extrahieren. Es ermöglicht die übliche Dokumentennavigation und Möglichkeiten zum Suchen und Ändern von Dokumenten über Ihren bevorzugten Konverter. Beautiful Soup erspart Ihnen Stunden oder sogar Tage Arbeit.$ sudo apt-get install python3-bs4
$ sudo pip install beautifulsoup4
4.Eine kurze Analyse des Anfragemoduls
1) Senden Sie eine Anfrage Importieren Sie zunächst natürlich das Modul „Anfragen“:>>> import requests
>>> r = requests.get('http://www.jb51.net/article/124421.htm')
>>> payload = {'newwindow': '1', 'q': 'python爬虫', 'oq': 'python爬虫'}
>>> r = requests.get("https://www.google.com/search", params=payload)>>> import requests
>>> r = requests.get('https://github.com/timeline.json')
>>> r.text>>> r = requests.get('http://www.cnblogs.com/') >>> r.encoding 'utf-8'
>>> r = requests.get('http://www.cnblogs.com/') >>> r.status_code 200
5. Falldemonstration
Das Unternehmen hat kürzlich ein OA-System eingeführt, hier verwende ich das Offizielle Dokumentationsseite Nehmen Sie dies als Beispiel und erfassen Sie nur nützliche Informationen wie Artikeltitel und Inhalt auf der Seite. DemoumgebungBetriebssystem: LinuxmintPython-Version: Python 3.5.2Verwendung von Modulen: Anfragen, beautifulsoup4Code Wie folgt:#!/usr/bin/env python
# -*- coding: utf-8 -*-
_author_ = 'GavinHsueh'
import requests
import bs4
#要抓取的目标页码地址
url = 'http://www.ranzhi.org/book/ranzhi/about-ranzhi-4.html'
#抓取页码内容,返回响应对象
response = requests.get(url)
#查看响应状态码
status_code = response.status_code
#使用BeautifulSoup解析代码,并锁定页码指定标签内容
content = bs4.BeautifulSoup(response.content.decode("utf-8"), "lxml")
element = content.find_all(id='book')
print(status_code)
print(element)
Über das Problem verstümmelter Crawling-Ergebnisse
Tatsächlich habe ich zunächst direkt Python2 verwendet, das standardmäßig mit dem System geliefert wird, aber ich hatte lange Zeit damit zu kämpfen Das Problem der verstümmelten Kodierung des zurückgegebenen Inhalts hat verschiedene Lösungen gegoogelt, aber alle waren wirkungslos. Nachdem ich von Python2 „verrückt“ gemacht wurde, hatte ich keine andere Wahl, als Python3 ehrlich zu verwenden. Bezüglich des Problems verstümmelter Inhalte auf den gecrawlten Seiten von Python2 sind Senioren herzlich eingeladen, ihre Erfahrungen zu teilen, um zukünftigen Generationen wie mir zu helfen, Umwege zu vermeiden.Postscript
Python verfügt über viele Crawler-bezogene Module. Zusätzlich zum Anforderungsmodul gibt es auch urllib, pycurl und tornado usw. Im Vergleich dazu finde ich persönlich, dass das Anfragemodul relativ einfach und benutzerfreundlich ist. Durch Text können Sie schnell lernen, das Anforderungsmodul von Python zum Crawlen von Seiteninhalten zu verwenden. Meine Fähigkeiten sind begrenzt. Wenn der Artikel Fehler enthält, können Sie sie mir gerne mitteilen. Wenn Sie Fragen zum Inhalt der von Python gecrawlten Seite haben, können Sie dies auch gerne mit allen besprechen.Das obige ist der detaillierte Inhalt vonDetailliertes Beispiel für Python3, das das Anforderungsmodul zum Crawlen von Seiteninhalten verwendet. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

 Detaillierte Erläuterung der Modusfunktion in C++
Nov 18, 2023 pm 03:08 PM
Detaillierte Erläuterung der Modusfunktion in C++
Nov 18, 2023 pm 03:08 PM
Detaillierte Erläuterung der Modusfunktion in C++ In der Statistik bezieht sich der Modus auf den Wert, der in einem Datensatz am häufigsten vorkommt. In der Sprache C++ können wir den Modus in jedem Datensatz finden, indem wir eine Modusfunktion schreiben. Die Modusfunktion kann auf viele verschiedene Arten implementiert werden. Zwei der häufig verwendeten Methoden werden im Folgenden ausführlich vorgestellt. Die erste Methode besteht darin, eine Hash-Tabelle zu verwenden, um die Häufigkeit des Vorkommens jeder Zahl zu zählen. Zuerst müssen wir eine Hash-Tabelle definieren, in der jede Zahl der Schlüssel und die Häufigkeit des Vorkommens der Wert ist. Dann führen wir für einen bestimmten Datensatz aus
 Ausführliche Erklärung zur Erlangung von Administratorrechten in Win11
Mar 08, 2024 pm 03:06 PM
Ausführliche Erklärung zur Erlangung von Administratorrechten in Win11
Mar 08, 2024 pm 03:06 PM
Das Windows-Betriebssystem ist eines der beliebtesten Betriebssysteme der Welt und seine neue Version Win11 hat viel Aufmerksamkeit erregt. Im Win11-System ist die Erlangung von Administratorrechten ein wichtiger Vorgang. Mit Administratorrechten können Benutzer weitere Vorgänge und Einstellungen auf dem System durchführen. In diesem Artikel wird ausführlich beschrieben, wie Sie Administratorrechte im Win11-System erhalten und wie Sie Berechtigungen effektiv verwalten. Im Win11-System werden Administratorrechte in zwei Typen unterteilt: lokaler Administrator und Domänenadministrator. Ein lokaler Administrator verfügt über vollständige Administratorrechte für den lokalen Computer
 Detaillierte Erläuterung der Divisionsoperation in Oracle SQL
Mar 10, 2024 am 09:51 AM
Detaillierte Erläuterung der Divisionsoperation in Oracle SQL
Mar 10, 2024 am 09:51 AM
Detaillierte Erläuterung der Divisionsoperation in OracleSQL In OracleSQL ist die Divisionsoperation eine häufige und wichtige mathematische Operation, die zur Berechnung des Ergebnisses der Division zweier Zahlen verwendet wird. Division wird häufig in Datenbankabfragen verwendet. Daher ist das Verständnis der Divisionsoperation und ihrer Verwendung in OracleSQL eine der wesentlichen Fähigkeiten für Datenbankentwickler. In diesem Artikel werden die relevanten Kenntnisse über Divisionsoperationen in OracleSQL ausführlich erörtert und spezifische Codebeispiele als Referenz für die Leser bereitgestellt. 1. Divisionsoperation in OracleSQL
 Detaillierte Erläuterung der Restfunktion in C++
Nov 18, 2023 pm 02:41 PM
Detaillierte Erläuterung der Restfunktion in C++
Nov 18, 2023 pm 02:41 PM
Detaillierte Erläuterung der Restfunktion in C++ In C++ wird der Restoperator (%) verwendet, um den Rest der Division zweier Zahlen zu berechnen. Es handelt sich um einen binären Operator, dessen Operanden ein beliebiger Ganzzahltyp (einschließlich char, short, int, long usw.) oder ein Gleitkommazahlentyp (z. B. float, double) sein kann. Der Restoperator gibt ein Ergebnis mit demselben Vorzeichen wie der Dividend zurück. Für die Restoperation von Ganzzahlen können wir beispielsweise den folgenden Code zur Implementierung verwenden: inta=10;intb=3;
 Detaillierte Erläuterung der Verwendung der Vue.nextTick-Funktion und ihrer Anwendung bei asynchronen Updates
Jul 26, 2023 am 08:57 AM
Detaillierte Erläuterung der Verwendung der Vue.nextTick-Funktion und ihrer Anwendung bei asynchronen Updates
Jul 26, 2023 am 08:57 AM
Detaillierte Erläuterung der Verwendung der Vue.nextTick-Funktion und ihrer Anwendung bei asynchronen Aktualisierungen. Bei der Vue-Entwicklung treten häufig Situationen auf, in denen Daten asynchron aktualisiert werden müssen. Beispielsweise müssen Daten sofort nach einer Änderung des DOM oder verwandter Vorgänge aktualisiert werden unmittelbar nach der Aktualisierung der Daten durchzuführen. Die von Vue bereitgestellte Funktion .nextTick wurde entwickelt, um diese Art von Problem zu lösen. In diesem Artikel wird die Verwendung der Vue.nextTick-Funktion im Detail vorgestellt und mit Codebeispielen kombiniert, um ihre Anwendung bei asynchronen Updates zu veranschaulichen. 1. Vue.nex
 Detaillierte Erläuterung der Rolle und Verwendung des PHP-Modulo-Operators
Mar 19, 2024 pm 04:33 PM
Detaillierte Erläuterung der Rolle und Verwendung des PHP-Modulo-Operators
Mar 19, 2024 pm 04:33 PM
Der Modulo-Operator (%) in PHP wird verwendet, um den Rest der Division zweier Zahlen zu ermitteln. In diesem Artikel werden wir die Rolle und Verwendung des Modulo-Operators im Detail besprechen und spezifische Codebeispiele bereitstellen, um den Lesern ein besseres Verständnis zu erleichtern. 1. Die Rolle des Modulo-Operators Wenn wir in der Mathematik eine ganze Zahl durch eine andere ganze Zahl dividieren, erhalten wir einen Quotienten und einen Rest. Wenn wir beispielsweise 10 durch 3 dividieren, ist der Quotient 3 und der Rest ist 1. Um diesen Rest zu ermitteln, wird der Modulo-Operator verwendet. 2. Verwendung des Modulo-Operators In PHP verwenden Sie das %-Symbol, um den Modul darzustellen
 Detaillierte Erläuterung der Funktion system() des Linux-Systemaufrufs
Feb 22, 2024 pm 08:21 PM
Detaillierte Erläuterung der Funktion system() des Linux-Systemaufrufs
Feb 22, 2024 pm 08:21 PM
Detaillierte Erläuterung der Funktion system() des Linux-Systems Der Systemaufruf ist ein sehr wichtiger Teil des Linux-Betriebssystems. Er bietet eine Möglichkeit, mit dem Systemkernel zu interagieren. Unter diesen ist die Funktion system() eine der am häufigsten verwendeten Systemaufruffunktionen. In diesem Artikel wird die Verwendung der Funktion system() ausführlich vorgestellt und entsprechende Codebeispiele bereitgestellt. Grundlegende Konzepte von Systemaufrufen Systemaufrufe sind eine Möglichkeit für Benutzerprogramme, mit dem Betriebssystemkernel zu interagieren. Benutzerprogramme fordern das Betriebssystem an, indem sie Systemaufruffunktionen aufrufen
 Detaillierte Erläuterung des Linux-Befehls „curl'.
Feb 21, 2024 pm 10:33 PM
Detaillierte Erläuterung des Linux-Befehls „curl'.
Feb 21, 2024 pm 10:33 PM
Detaillierte Erläuterung des Linux-Befehls „curl“ Zusammenfassung: Curl ist ein leistungsstarkes Befehlszeilentool für die Datenkommunikation mit dem Server. In diesem Artikel wird die grundlegende Verwendung des Curl-Befehls vorgestellt und tatsächliche Codebeispiele bereitgestellt, um den Lesern zu helfen, den Befehl besser zu verstehen und anzuwenden. 1. Was ist Locken? Curl ist ein Befehlszeilentool zum Senden und Empfangen verschiedener Netzwerkanfragen. Es unterstützt mehrere Protokolle wie HTTP, FTP, TELNET usw. und bietet umfangreiche Funktionen wie Datei-Upload, Datei-Download, Datenübertragung und Proxy
