
 Backend-Entwicklung
Python-Tutorial
So verwenden Sie Haystack mit Django in Python: ein Beispiel für das Volltextsuch-Framework
Backend-Entwicklung
Python-Tutorial
So verwenden Sie Haystack mit Django in Python: ein Beispiel für das Volltextsuch-Framework
So verwenden Sie Haystack mit Django in Python: ein Beispiel für das Volltextsuch-Framework

Der folgende Editor bringt Ihnen einen Artikel über die Verwendung von Haystack mit Python Django: Volltextsuch-Framework (Erklärung mit Beispielen). Der Herausgeber findet es ziemlich gut, deshalb teile ich es jetzt mit Ihnen und gebe es als Referenz. Folgen wir dem Herausgeber, um einen Blick darauf zu werfen
Heuhaufen: ein Framework für die Volltextsuche
whoosh: geschrieben in reiner Python-Volltextsuchmaschine
jieba: ein kostenloses chinesisches Wortsegmentierungspaket
Diese drei Pakete zuerst installieren
pip install django-haystack
pip install whoosh
pip install jieba
1. Ändern Sie die Datei „settings.py“. und installieren Sie die Anwendung Heuhaufen,
2. Konfigurieren Sie die Suchmaschine in der Datei „settings.py“
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'3. blog/“ im Vorlagenverzeichnis „Das Verzeichnis verwendet den Namen der Blog-Anwendung, um eine Datei zu erstellen blog_text.txt
#Geben Sie das Indexattribut an
{{ object.title }}
{{ object.text}}
{{ object .keywords }}
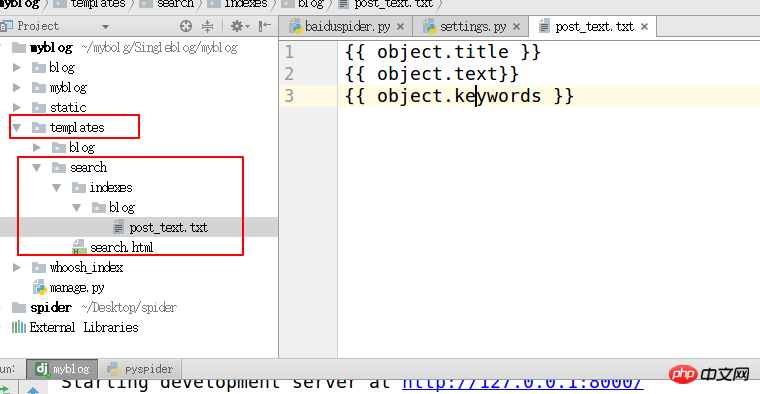
4. Suchindizes erstellen
from haystack import indexes from models import Post #指定对于某个类的某些数据建立索引 class GoodsInfoIndex(indexes.SearchIndex, indexes.Indexable): text = indexes.CharField(document=True, use_template=True) def get_model(self): return Post #搜索的模型类 def index_queryset(self, using=None): return self.get_model().objects.all()
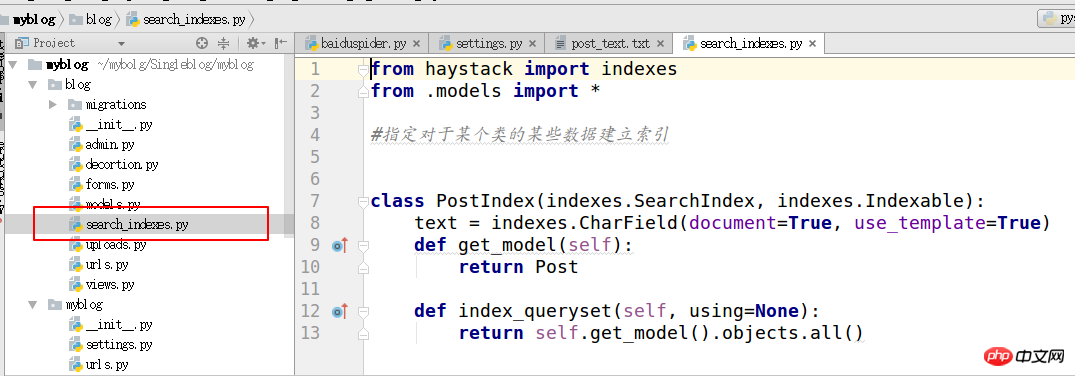 unter der Anwendung, die durchsucht werden muss
unter der Anwendung, die durchsucht werden muss
5.
1. Ändern Sie die Heuhaufendatei
2. Finden Sie den Heuhaufen Verzeichnis unter der virtuellen Umgebung py_django. Dieses Verzeichnis ist je nach verwendeter Python-Umgebung unterschiedlich, auch die Pfade sind unterschiedlich.
3. site-packages/haystack/backends/ Erstellen Sie eine Datei mit dem Namen ChineseAnalyzer.py und schreiben Sie den folgenden Code für die chinesische Wortsegmentierung
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()6.
1. Kopieren Sie die Datei whoosh_backend.py und ändern Sie sie in den folgenden Namen
whoosh_cn_backend.py
Importieren Sie das chinesische Wortsegmentierungsmodul in die kopierte Datei Datei
aus .ChineseAnalyzer import ChineseAnalyzer
2. Ändern Sie die Wortanalyseklasse in Chinesisch
Suchen Sie nach „analysator=StemmingAnalyzer()“ und ändern Sie sie in „analysator=ChineseAnalyzer()“ 🎜>
7. Der letzte Schritt besteht darin, erste Indexdaten zu erstellenpython manage.py rebuild_index8. Suchvorlage in Vorlagen/Indizes erstellen/Suchvorlage erstellen Suchergebnisse Für Paging lautet der von der Ansicht an die Vorlage übergebene Kontext wie folgt Abfrage: Suchbegriffeclass GoodsSearchView(SearchView): def get_context_data(self, *args, **kwargs): context = super().get_context_data(*args, **kwargs) context['iscart']=1 context['qwjs']=2 return context
Das obige ist der detaillierte Inhalt vonSo verwenden Sie Haystack mit Django in Python: ein Beispiel für das Volltextsuch-Framework. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Wie kann man Node.js oder Python -Dienste in Lampenarchitektur effizient integrieren?
Apr 01, 2025 pm 02:48 PM
Wie kann man Node.js oder Python -Dienste in Lampenarchitektur effizient integrieren?
Apr 01, 2025 pm 02:48 PM
Viele Website -Entwickler stehen vor dem Problem der Integration von Node.js oder Python Services unter der Lampenarchitektur: Die vorhandene Lampe (Linux Apache MySQL PHP) Architekturwebsite benötigt ...
 Was ist der Grund, warum Pipeline persistente Speicherdateien bei der Verwendung von Scapy Crawler nicht geschrieben werden kann?
Apr 01, 2025 pm 04:03 PM
Was ist der Grund, warum Pipeline persistente Speicherdateien bei der Verwendung von Scapy Crawler nicht geschrieben werden kann?
Apr 01, 2025 pm 04:03 PM
Bei der Verwendung von Scapy Crawler kann der Grund, warum Pipeline persistente Speicherdateien nicht geschrieben werden kann? Diskussion beim Lernen, Scapy Crawler für Data Crawler zu verwenden, begegnen Sie häufig auf eine ...
 Python Hourglass Graph Drawing: Wie vermeiden Sie variable undefinierte Fehler?
Apr 01, 2025 pm 06:27 PM
Python Hourglass Graph Drawing: Wie vermeiden Sie variable undefinierte Fehler?
Apr 01, 2025 pm 06:27 PM
Erste Schritte mit Python: Hourglas -Grafikzeichnung und Eingabeüberprüfung In diesem Artikel wird das Problem der Variablendefinition gelöst, das von einem Python -Anfänger im Hourglass -Grafikzeichnungsprogramm auftritt. Code...
 Was ist der Grund, warum der Python -Prozesspool gleichzeitige TCP -Anfragen behandelt und den Kunden dazu bringt, stecken zu bleiben?
Apr 01, 2025 pm 04:09 PM
Was ist der Grund, warum der Python -Prozesspool gleichzeitige TCP -Anfragen behandelt und den Kunden dazu bringt, stecken zu bleiben?
Apr 01, 2025 pm 04:09 PM
Python Process Pool verarbeitet gleichzeitige TCP -Anfragen, die dazu führen, dass der Client stecken bleibt. Bei der Verwendung von Python für die Netzwerkprogrammierung ist es entscheidend, gleichzeitige TCP -Anforderungen effizient zu verarbeiten. ...
 Wie kann ich die ursprünglichen Funktionen betrachten, die von Python Functools.Partial Object in intern eingekapselt sind?
Apr 01, 2025 pm 04:15 PM
Wie kann ich die ursprünglichen Funktionen betrachten, die von Python Functools.Partial Object in intern eingekapselt sind?
Apr 01, 2025 pm 04:15 PM
Erforschen Sie tief die Betrachtungsmethode von Python Functools.Partialial Object in functools.Partial mit Python ...
 Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Wie löste ich das Problem der Berechtigungen beim Betrachten der Python -Version in Linux Terminal?
Apr 01, 2025 pm 05:09 PM
Lösung für Erlaubnisprobleme beim Betrachten der Python -Version in Linux Terminal Wenn Sie versuchen, die Python -Version in Linux Terminal anzuzeigen, geben Sie Python ein ...
 Python Cross-Platform Desktop-Anwendungsentwicklung: Welche GUI-Bibliothek ist die beste für Sie?
Apr 01, 2025 pm 05:24 PM
Python Cross-Platform Desktop-Anwendungsentwicklung: Welche GUI-Bibliothek ist die beste für Sie?
Apr 01, 2025 pm 05:24 PM
Auswahl der Python-plattformübergreifenden Desktop-Anwendungsentwicklungsbibliothek Viele Python-Entwickler möchten Desktop-Anwendungen entwickeln, die sowohl auf Windows- als auch auf Linux-Systemen ausgeführt werden können ...
 Wie löst ich das Problem der Dateinamen -Codierung bei der Verbindung zu FTP -Server in Python?
Apr 01, 2025 pm 06:21 PM
Wie löst ich das Problem der Dateinamen -Codierung bei der Verbindung zu FTP -Server in Python?
Apr 01, 2025 pm 06:21 PM
Wenn Sie Python verwenden, um eine Verbindung zu einem FTP -Server herzustellen, können Sie auf Codierungsprobleme stoßen, wenn Sie Dateien im angegebenen Verzeichnis erhalten und herunterladen, insbesondere Text auf dem FTP -Server ...
