
 Backend-Entwicklung
Python-Tutorial
Ausführliche Erläuterung zur Verwendung von Zeichenkodierung und Funktionen in Python
Backend-Entwicklung
Python-Tutorial
Ausführliche Erläuterung zur Verwendung von Zeichenkodierung und Funktionen in Python
Ausführliche Erläuterung zur Verwendung von Zeichenkodierung und Funktionen in Python

Der folgende Editor bringt Ihnen einen Artikel über die grundlegende Verwendung der Python-Zeichenkodierung und -Funktionen. Der Herausgeber findet es ziemlich gut, deshalb werde ich es jetzt mit Ihnen teilen und es allen als Referenz geben. Folgen wir dem Editor und werfen wir einen Blick darauf.
1. Dekodierungs- und Kodierungsprobleme mit Zeichen in Python2
Wenn Sie derzeit Python2 verwenden Sie sollten wissen, dass es Probleme mit der Zeichenkodierung gibt: Python2 kann Chinesisch natürlich nicht direkt in der Befehlszeile ausgeben. Es wird höchstens ein Haufen verstümmelter Zeichen angezeigt . Wenn wir Chinesisch direkt anzeigen möchten, können wir das Zeichenkodierungsformat im Header der Python2-Datei deklarieren. Wie unten gezeigt,
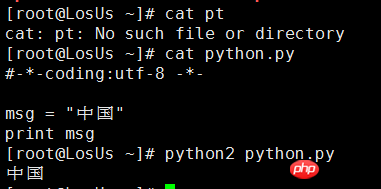
Hier wird #-*-coding:utf-8 -*- verwendet, um anzugeben, für welche Codierung der folgende Code verwendet wird interpretieren;
1.1. Dekodierung und Kodierung in Python2:
In der Welt der Kodierung und Dekodierung müssen wir einen Text finden, den jeder kennt. Man kann es auch so verstehen. Ich bin Chinese und jetzt kommuniziere ich mit einem Japaner. Ich kann definitiv nicht verstehen, was er sagt, und er kann es auch nicht verstehen, aber gibt es keine andere Möglichkeit? Vielleicht brauchen wir eine internationale Sprache – Englisch. Auf diese Weise können Menschen aus verschiedenen Ländern kommunizieren (obwohl ich weiß, dass es dir gut geht, 0-0). Das Gleiche gilt für die Codierung. Weder gbk noch utf-8 wissen, was das Format der anderen Partei bedeutet. Wenn Sie also gbk verwenden möchten, um die Kodierung von utf-8 zu verstehen, müssen Sie utf-8 in Unicode dekodieren, und Unicode kennt gkb. Hier müssen Sie Unicode in gbk kodieren
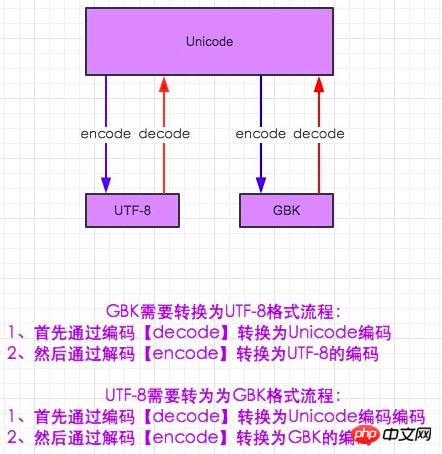
#-*- coding:utf-8 -*- msg = "中国" print msg #解码在编码的过程,encoding是申明用申明这段代码是什么编码 gbk_str = msg.decode(encoding='utf-8').encode(encoding='gbk') print gbk_str #其实两种输出的结果是一样的
In Python2 wird gbk standardmäßig zum Interpretieren des Codes in der IDE verwendet. Daher ist es unmöglich, Chinesisch direkt in die Python-Befehlszeile einzugeben. Daher verwenden wir # -* -coding:utf-8 -*- Um den Header zu deklarieren, welche Sprache müssen wir verwenden, um den folgenden Code zu interpretieren. Aufmerksame Leute müssen ein Problem entdeckt haben, das nur utf-8 verwendet, um die folgenden Wörter zu erklären. Es liegt auf der Hand, dass in der Befehlszeile kein Fehler gemeldet wird Alle, der DOS-Befehl Die Standardunterstützung in der Zeile ist der Zeichencode im GBK-Format? Hier handelt es sich um ein anderes Konzept. Wenn Python den Speicherinterpreter betritt, wird standardmäßig Unicode verwendet. Nachdem die Datei in den Speicher geladen wurde, wird sie automatisch in Unicode dekodiert. Da es sich bei Unicode um einen Fremdcode handelt, kann er natürlich von der UTF-8-Kodierung in die GBK-Kodierung übersetzt werden . Gu kann jetzt Chinesisch anzeigen.
PS: Hier kommen wir zu einem Schluss: Die Dekodierungsaktion ist in Python2 notwendig, aber die Kodierung ist nicht notwendig, da der Speicher Unicode ist
1.2, Python3 Das Problem mit der Zeichenkodierung:
Nun, was kann man dazu noch sagen? Python3 verwendet standardmäßig utf-8, um Code zu interpretieren. Das heißt, der Zeilenanfang steht mit #-*-coding:utf-8 -*- (GBM), sodass kein Dekodierungsproblem besteht. Aber ich werde es hier erwähnen (tatsächlich habe ich Angst, dass ich es in Zukunft vergessen werde, hehe), wenn wir das UTF-8-Zeichenkodierungsformat in GBK kodieren. Hier werden Dinge im Byteformat ausgegeben.
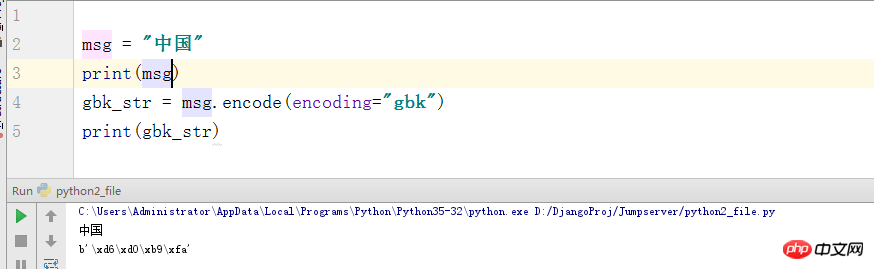
Was genau sind Bytes? Lassen Sie mich hier kurz darauf eingehen. Tatsächlich handelt es sich um die entsprechende Position dieses Zeichens im ASCII-Code. Wenn Sie es nicht glauben, schauen wir uns einen Screenshot des Codes an:
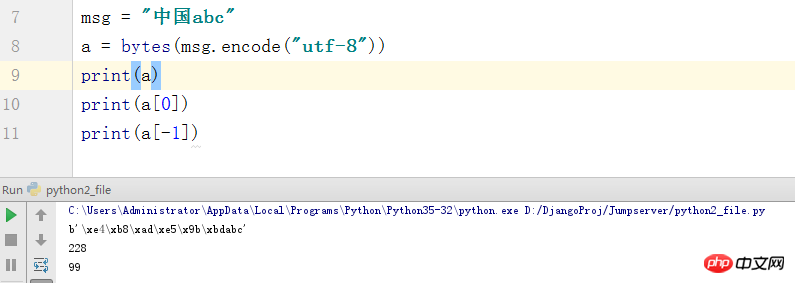
Auf diesem Bild sehen wir, dass China in einen Haufen unverständlicher Vögel zerstreut wurde Schreiben. Es wird aber weiterhin Englisch angezeigt. Durch das Abfangen der Liste können wir jedoch erkennen, dass die Ausgabe des letzten Bits c 99 ist. Tatsächlich ist die Ausgabe hier die Position, die c in ASCII entspricht, und 3 Bytes sind chinesische Zeichen, sodass wir 6 Absätze sehen Hier müssen wir nicht zu viel erklären.
PS: Eines muss sich jeder merken: Str in Python2 ist das Byteformat in Python3, und str in Python2 ist eigentlich Unicode
2. Python3 ergänzt Dateioperationen
2.1. Dateioperationen mit „+“:
Hier sage ich drei, aber tatsächlich diese Dinge sind von geringem Nutzen, aber das ist ein Wissenspunkt
r+: Lesbar, Sie können anhängen
w+: Löschen Sie die Quelldatei und schreiben Sie dann neuen Inhalt
a+: Zum Anhängen können Sie read
f = open('lyrics','r+',encoding='utf-8') #这里的lyrics是文件名字
f.read() #我先读取
f.write("Leon Have Dream") #在后面追加
f.close()r+: Wenn f.read() und dann f.write() verwendet werden, wird es an das Ende der Datei angehängt ist f.directly. write() ersetzt direkt den Inhalt am Anfang der Datei durch den Inhalt in (); den Inhalt und schreibt ihn in write()-Inhalt um, und f.read() meldet keinen Fehler. Ich persönlich empfehle Ihnen, diesen Vorgang auszuführen, wenn Sie Ihren Job aufgeben
f = open('lyricsback','w+',encoding='utf-8')
f.read()
f.write("Leon Have Dream")
f.read()
f.close()
a+: Tatsächlich ist es dasselbe wie r+ und dem Anhängen von Inhalt am Ende sehr ähnlich, lesbarem Inhalt
PS:这里的补充一下,为什么在使用r+的时候先执行f.read()再执行f.write()就会在文件的结尾追加和直接使用f.write()直接就替换文件最前边的内容呢?这是因为Python在读文件的时候自己维护这一个“指针”,如果我们使用f.read()就相当于读完了这个文件,这时候指针也就会在最后面了。下面我在补充“f”这个对象的几个用法来证明Python文件指针。
f = open('lyricsback','r+' ,encoding='utf-8')
print(f.tell()) #this number is 0
f.seek(12) # 将指针向后面移动几个字节,一个汉字是三个字节
print(f.tell()) # this is seek number
f.write("Love Girl") #这里就从seek到地方替换
print(f.tell()) # tell()用法就是文件的指针位置
f.close()2.2、加b的方式对文件进行操作
rb:将文件以二进制的方式从硬盘中读取出来,这里得记住在open()函数中不要加encoding= 这个参数因为二进制不存在编码上的问题
wb:将文件以二进制的方式写入内容,不过在f.write()中加上encode="utf-8",意思就是申明编码的格式,并且会清楚原来文件内容
ab:只能以二进制方式追加。
三、函数
什么是函数?函数可以简单理解一段命令的集合。为什么需要用函数?这里有一个非常简单的原因,比如说你需要对一段代码反复进行操作,这里你当然可以一直复制再粘贴,但是这样灵活性和日后的维护成本将会变大。
#比方说现在需要写一个报警(调用接口)的程序,这里就用监控做比喻 if cpu > 80%: 连接邮箱服务器 发送消息 关闭连接 if memery > 80%: 连接邮箱服务器 发送消息 关闭连接 if disk > 80% 连接邮箱服务器 发送消息 关闭连接 #通过写这样的一个程序我们发现我们一直在重复调用发送邮箱的这一套接口。这样我们是否能想出一个办法解决这样的重复操作呢?请看下一个版本 发送邮件(): l连接邮箱服务器 发送连接 关闭连接 if cpu > 80% 发送邮件() if memery > 80%: 发送邮件() ....... # 这样以此类推,我们只需要挑用发送邮件的这个接口就可以节省代码的发送邮件了
通过上面的代码我们发现,我们只需要将报警的这一套流程放到一个公共的地方,等下面触发报警的条件的时候调用报警的函数,这样我们就可以省去当每次触发报警的时候我们自己在写报警的步骤了。但是函数是怎么定义呢?又有什么语法和定义呢?请看下面的一段代码,其中代码输出的是“Leon Have A Dream”
def leon(): #leon是函数名字
print("Leon Have A Dream")
leon() #调用函数带参数的函数:
a = 10 b = 5 def calc(a,b): print(a ** b) c = calc(a,b) print(c)
首先上面这些代码执行完会输出两个字符,一个是10000,一个是None,为什么会这样呢?首先c是等于执行了一遍calc这个函数,所以输出10000这个数字是肯定的,但是为什么还会输出一个None呢?原来我们的“c”执行了仪表calc函数,而calc函数中没有任何的返回值,所以c == None 。
PS:函数的返回结果就是return,其中return的含义就是:把函数的执行结果返回给外面,从而让挑用函数的“对象”得到执行结果
下面我们在看与之相似的列子
a = 10 b = 5 def calc(a,b): print(a ** b) return a + b c = calc(a,b) c = calc(10,6) print(c)
首先会输出的有三个值,分别是100000,1000000,16,为什么会是这三个呢,下面用一副图来说一下

PS:
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
Python中的全局变量和局部变量

PS:函数内部是可以修改列表,字典,集合,实例(class),我们通过下面一个图来说明
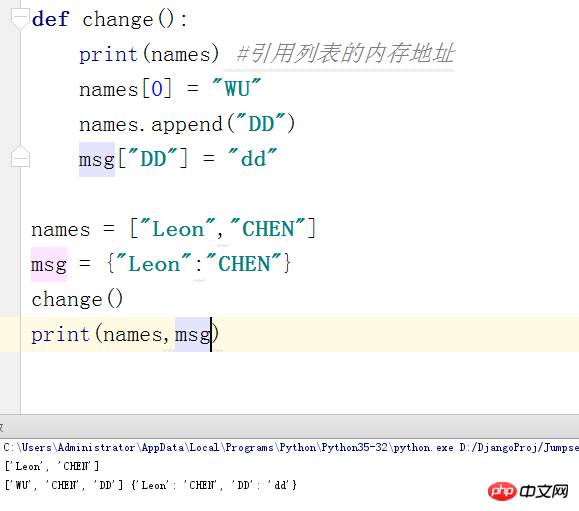
为什么列表和字典等会被添加和修改呢,原来函数内部知识引用了字典和列表的内存地址,而内存地址无法修改(可以重新开辟一块内存地址),而每个字典和列表中的每一个值都有对应的内存地址,但是记住我们函数是引用的列表或者字典本身的内存地址,所以这样打印到出来的也就会跟着改变了。
全局与局部变量
在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。
全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时:
在定义局部变量的子程序内,局部变量起作用;在其它地方全局变量起作用。
位置参数:
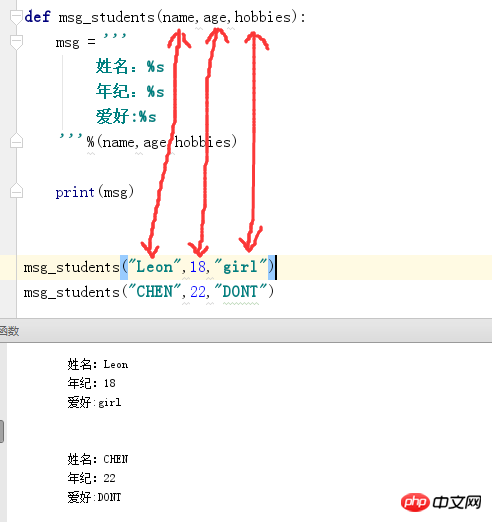
像上面这样实参和形参一一对应的上就是就是位置参数
默认参数:
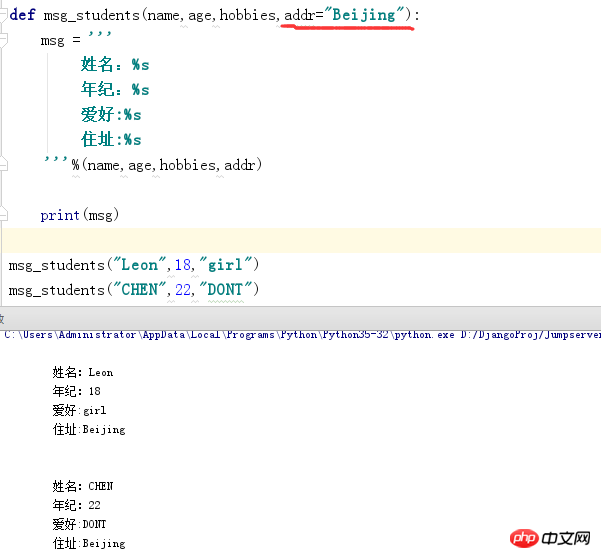
在函数将一个位置参数设置成一个默认的值的那一个变量就是默认参数,记住默认参数得在位置参数得后面
关键参数:
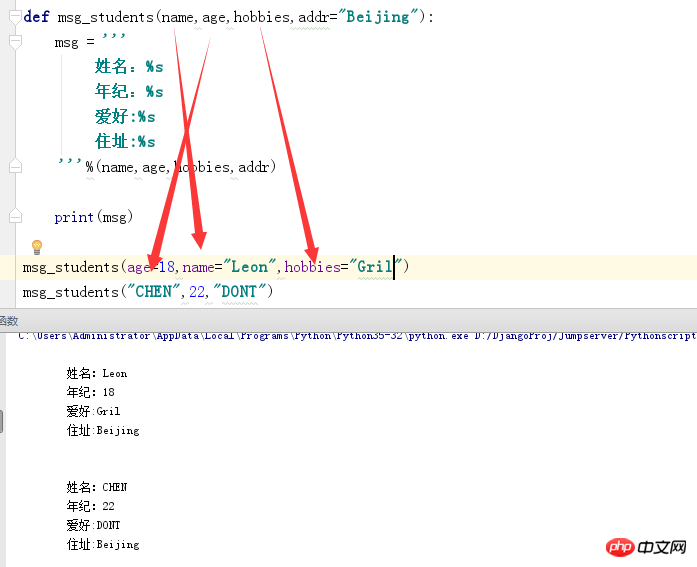
像上面这样实参和形参不一一对应,并且在调用函数的时候给参数赋值的叫做关键参数
非固定函数:
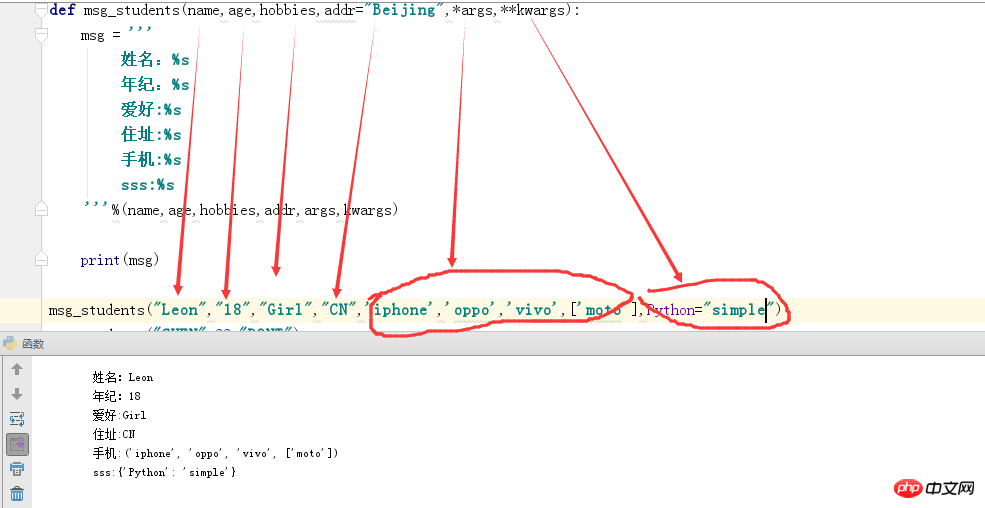
通过输出结果我们发现*args是接收多余的字符串类型的参数,而想Python="simple"(字典)类型的会传入给**kwargs,这就是非固定参数;当你不知道这个参数需要多少个参数时可以使用该函数类型
递归函数——二分查找
a = [1,2,3,4,5,7,9,10,11,12,14,15,16,17,19,21]
def calc(num,find_num):
print(num)
mid = int(len(num) / 2)
if mid == 0:
if num[mid] == find_num:
print("find it %s"%find_num)
else:
print("cannt find num")
if num[mid] == find_num:
print("find_num %s"%find_num)
elif num[mid] > find_num:
calc(num[0:mid],find_num)
elif num[mid] < find_num:
calc(num[mid+1:],find_num)
calc(a,12)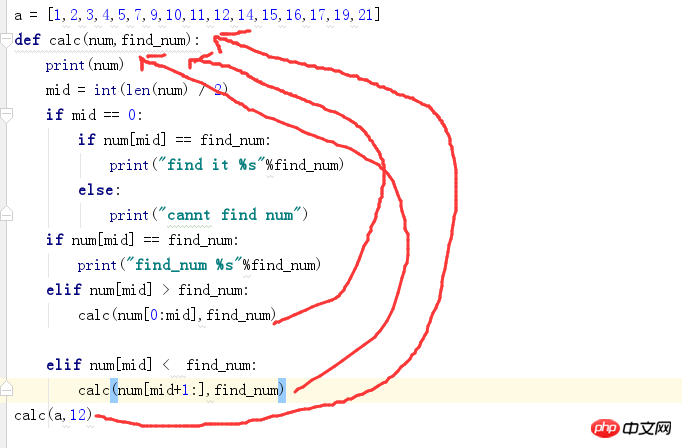
递归的特性
函数必须有明确的结束(判断)条件,也就是上图一开始的mid[0] 不能等于0,因为这样就会没有意义了
每次进入更深一层递归时,问题规模相比上次递归都应有所减少
递归函数每次向下递归一次,上次的函数占用的内存地址不会被释放,而是一直会被阻塞主,等待函数全部执行完毕后释放,所以也可以说递归是相当消耗内存空间的,对此Python有递归的深度,如果超过该深度函数将会被推出(栈溢出)
匿名函数:
calc = lambda x:x+2 # x是形参,冒号后的内容是该匿名函数执行的动作 print(calc(5)) #匿名函数意识需要通过调用来执行的 calc = lambda x,y,z:x*y*z #匿名函数可以传入多个形参,各个参数之间用逗号隔开 print(calc(2,4,6)) c = map(lambda x:x*2,[2,5,4,6]) #map方法需要 传入两个参数一个是function(函数),itrables(可迭代)的数据类型 for i in c: print(i) #三元运算 for i in map(lambda x:x**2 if x >5 else x - 1,[1,2,3,5,7,8,9]): #lambda最多支持三元运算,map是直接调用匿名函数,但是如果想打印map的内容,需要循环 print(i)
高阶函数:
def calc(x,y,f): print(f(x) + f(y)) calc(10,-10,abs)
高阶函数的特性
把一个函数的内存地址传给另外一个函数,当做参数
一个函数把另外一个函数的当做返回值返回
满足上面的这个两个特性中的一个就可以称为高阶函数,这里因为偷懒,就是直接调用了Python中的内置函数
Das obige ist der detaillierte Inhalt vonAusführliche Erläuterung zur Verwendung von Zeichenkodierung und Funktionen in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP ist hauptsächlich prozedurale Programmierung, unterstützt aber auch die objektorientierte Programmierung (OOP). Python unterstützt eine Vielzahl von Paradigmen, einschließlich OOP, funktionaler und prozeduraler Programmierung. PHP ist für die Webentwicklung geeignet, und Python eignet sich für eine Vielzahl von Anwendungen wie Datenanalyse und maschinelles Lernen.
 Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
PHP eignet sich für Webentwicklung und schnelles Prototyping, und Python eignet sich für Datenwissenschaft und maschinelles Lernen. 1.PHP wird für die dynamische Webentwicklung verwendet, mit einfacher Syntax und für schnelle Entwicklung geeignet. 2. Python hat eine kurze Syntax, ist für mehrere Felder geeignet und ein starkes Bibliotheksökosystem.
 Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python eignet sich besser für Anfänger mit einer reibungslosen Lernkurve und einer kurzen Syntax. JavaScript ist für die Front-End-Entwicklung mit einer steilen Lernkurve und einer flexiblen Syntax geeignet. 1. Python-Syntax ist intuitiv und für die Entwicklung von Datenwissenschaften und Back-End-Entwicklung geeignet. 2. JavaScript ist flexibel und in Front-End- und serverseitiger Programmierung weit verbreitet.
 Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
VS -Code -Erweiterungen stellen böswillige Risiken dar, wie das Verstecken von böswilligem Code, das Ausbeutetieren von Schwachstellen und das Masturbieren als legitime Erweiterungen. Zu den Methoden zur Identifizierung böswilliger Erweiterungen gehören: Überprüfung von Verlegern, Lesen von Kommentaren, Überprüfung von Code und Installation mit Vorsicht. Zu den Sicherheitsmaßnahmen gehören auch: Sicherheitsbewusstsein, gute Gewohnheiten, regelmäßige Updates und Antivirensoftware.
 Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
VS -Code kann zum Schreiben von Python verwendet werden und bietet viele Funktionen, die es zu einem idealen Werkzeug für die Entwicklung von Python -Anwendungen machen. Sie ermöglichen es Benutzern: Installation von Python -Erweiterungen, um Funktionen wie Code -Abschluss, Syntax -Hervorhebung und Debugging zu erhalten. Verwenden Sie den Debugger, um Code Schritt für Schritt zu verfolgen, Fehler zu finden und zu beheben. Integrieren Sie Git für die Versionskontrolle. Verwenden Sie Tools für die Codeformatierung, um die Codekonsistenz aufrechtzuerhalten. Verwenden Sie das Lining -Tool, um potenzielle Probleme im Voraus zu erkennen.
 Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
VS -Code kann unter Windows 8 ausgeführt werden, aber die Erfahrung ist möglicherweise nicht großartig. Stellen Sie zunächst sicher, dass das System auf den neuesten Patch aktualisiert wurde, und laden Sie dann das VS -Code -Installationspaket herunter, das der Systemarchitektur entspricht und sie wie aufgefordert installiert. Beachten Sie nach der Installation, dass einige Erweiterungen möglicherweise mit Windows 8 nicht kompatibel sind und nach alternativen Erweiterungen suchen oder neuere Windows -Systeme in einer virtuellen Maschine verwenden müssen. Installieren Sie die erforderlichen Erweiterungen, um zu überprüfen, ob sie ordnungsgemäß funktionieren. Obwohl VS -Code unter Windows 8 möglich ist, wird empfohlen, auf ein neueres Windows -System zu upgraden, um eine bessere Entwicklungserfahrung und Sicherheit zu erzielen.
 So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
Im VS -Code können Sie das Programm im Terminal in den folgenden Schritten ausführen: Erstellen Sie den Code und öffnen Sie das integrierte Terminal, um sicherzustellen, dass das Codeverzeichnis mit dem Terminal Working -Verzeichnis übereinstimmt. Wählen Sie den Befehl aus, den Befehl ausführen, gemäß der Programmiersprache (z. B. Pythons Python your_file_name.py), um zu überprüfen, ob er erfolgreich ausgeführt wird, und Fehler auflösen. Verwenden Sie den Debugger, um die Debugging -Effizienz zu verbessern.
 PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP entstand 1994 und wurde von Rasmuslerdorf entwickelt. Es wurde ursprünglich verwendet, um Website-Besucher zu verfolgen und sich nach und nach zu einer serverseitigen Skriptsprache entwickelt und in der Webentwicklung häufig verwendet. Python wurde Ende der 1980er Jahre von Guidovan Rossum entwickelt und erstmals 1991 veröffentlicht. Es betont die Lesbarkeit und Einfachheit der Code und ist für wissenschaftliche Computer, Datenanalysen und andere Bereiche geeignet.
