

Ich lerne kürzlich Python3. Der folgende Artikel stellt Ihnen hauptsächlich die relevanten Informationen zum praktischen Python3-Crawler zum Crawlen von Jingdong-Buchbildern vor . Der Wert des Lernens, Freunde, die es brauchen, schauen Sie sich unten um.
Vorwort
Ich habe vor kurzem das Bedürfnis, Bilder von Büchern auf JD.com herunterzuladen Bücher auf JD.com Alle Bilder der Produktkategorie lokal herunterzuladen, manuell zu kopieren und einzufügen, ist derzeit ein sehr großes Projekt, das mit einem Python-Webcrawler implementiert werden kann. Als nächstes implementieren wir den Crawler.
Analyse implementieren
Öffnen Sie zunächst die erste zu crawlende Webseite. Diese Webseite wird als zu crawlende Startseite verwendet . Wir öffnen JD.com und wählen die Buchkategorie aus. Da es viele Bücher aller Art gibt, wählen wir das Crawlen von Buchbildern aller Programmiersprachen. Die Website lautet: https://list.jd.com/list.html?cat =1713, 3287,3797&page=1&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main
Wie im Bild gezeigt:
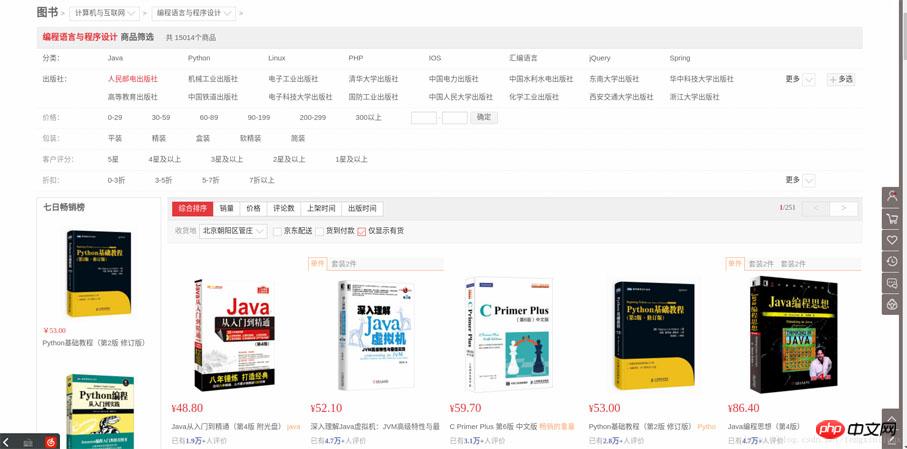
Nach dem Betreten finden wir ein insgesamt 251 Seiten.
Wie können wir also automatisch andere Seiten außer der ersten Seite crawlen?
Sie können auf „Nächste Seite“ klicken, um die Änderungen in der URL zu beobachten. Nachdem ich auf die nächste Seite geklickt hatte, stellte ich fest, dass sich die URL in https://list.jd.com/list.html?cat=1713,3287,3797&page=2&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main geändert hatte.
Wir können feststellen, dass die hier abzurufende Seite durch die URL identifiziert wird, also über GET angefordert wird. In dieser GET-Anfrage gibt es mehrere Felder, eines davon ist Seite, mit dem entsprechenden Wert 2. Daraus können wir die Schlüsselinformationen in der URL abrufen: https://list.jd.com/list.html? cat=1713,3287,3797&page=2. Basierend auf Spekulationen haben wir als Nächstes Seite=2 in Seite=6 geändert und festgestellt, dass wir Seite 6 erfolgreich eingeben konnten.
Daraus können wir uns eine Möglichkeit vorstellen, automatisch mehrere Seiten zu erhalten: Dies kann mithilfe einer for-Schleife implementiert werden. Nach jeder Schleife wird das Seitenfeld in der entsprechenden URL um 1 erhöht bedeutet, dass automatisch zur nächsten Seite gewechselt wird.
Auf jeder Seite müssen wir das entsprechende Bild extrahieren. Wir können reguläre Ausdrücke verwenden, um den Linkteil des Bildes im Quellcode abzugleichen, und dann das entsprechende verknüpfte Bild über urllib.request speichern .urlretrieve() auf lokal.
Aber hier gibt es ein Problem. Die Bilder auf dieser Webseite enthalten nicht nur die Bilder der Produkte in der Liste, sondern auch einige irrelevante Bilder daneben, sodass wir eine Information durchführen können Zuerst filtern. Die erste Informationsfilterung. Belassen Sie die Daten in der Produktliste in der Mitte und filtern Sie die Daten in anderen Teilen heraus. Sie können mit der rechten Maustaste klicken und den Quellcode der Webseite anzeigen, wie in der Abbildung gezeigt:
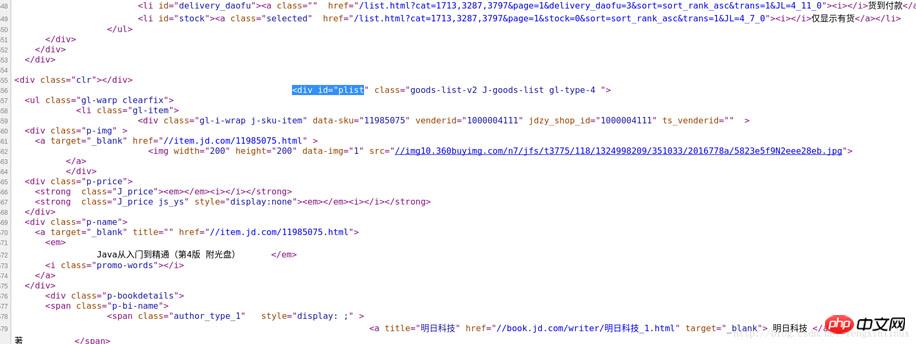
Sie können schnell durch das erste Produkt in der Produktliste mit dem Namen „ Suchen Sie die entsprechende Position im Quellcode und beobachten Sie dann das spezielle Logo im Produktlistenteil. Sie können sehen, dass sich darüber ein „
In ähnlicher Weise geben wir das letzte Buch in der Produktliste auf dieser Seite im Quellcode ein, suchen schnell den Speicherort des Quellcodes und analysieren ihn Ein solcher Code als Bezeichner, wie im Bild gezeigt:
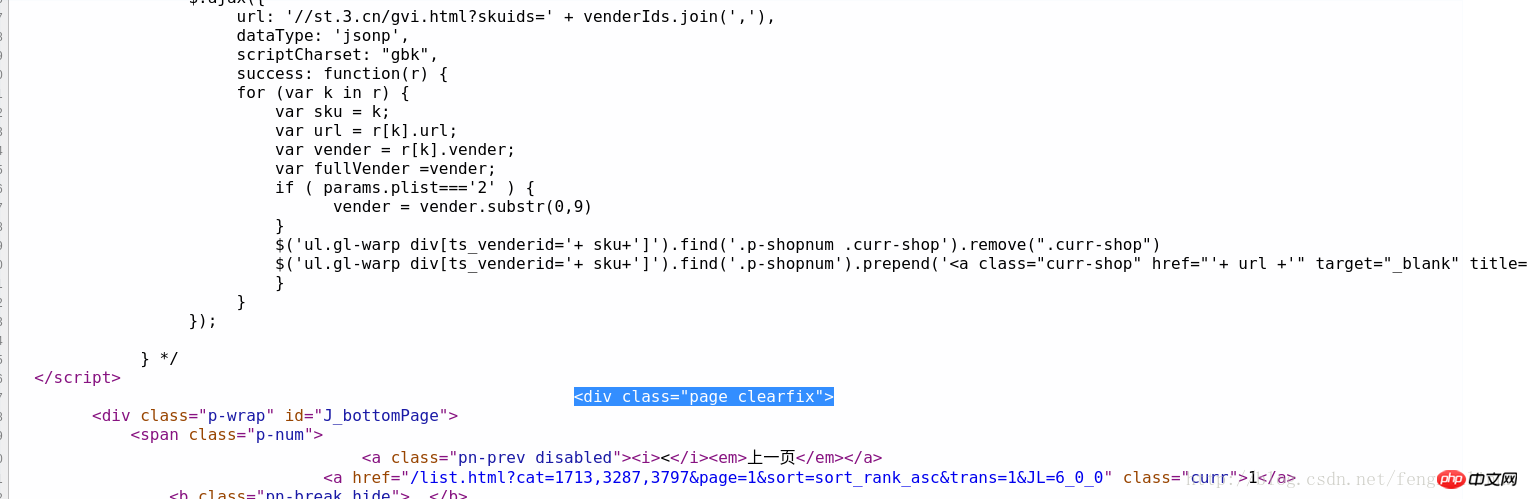
Nach der ersten Informationsfilterung sind die verbleibenden Bildlinks Dies ist das Bild, das wir crawlen möchten. Der nächste Schritt besteht darin, die Bildlinkinformationen basierend auf der ersten Filterung herauszufiltern .
<p id="plist".+? <p class="page clearfix">
Bild 1:
Bild 2:
<img width="200" height="200" data-img="1" src="//img13.360buyimg.com/n7/jfs/t6130/167/771989293/235186/608d0264/592bf167Naf49f7f6.jpg">
Vergleich der beiden Bei den Bildcodes haben wir festgestellt, dass das Grundformat dasselbe ist, aber die Link-URL des Bildes unterschiedlich ist. Daher erstellen wir zu diesem Zeitpunkt das extrahierte Bild basierend auf dieser Regel. Regulärer Ausdruck für Links:
<img width="200" height="200" data-img="1" src="//img10.360buyimg.com/n7/g14/M03/0E/0D/rBEhV1Im1n8IAAAAAAcHltD_3_8AAC0FgC-1WoABweu831.jpg">
<img width="200" height="200" data-img="1" src="//(.+?\.jpg)">
刚开始到这里,我以为就结束了,后来在爬取的过程中我发现每一页都少爬取了很多图片,再次查看源码发现,每页后面的几十张图片又是另一种格式:
<img width="200" height="200" data-img="1" src-img="//img10.360buyimg.com/n7/jfs/t3226/230/618950227/110172/7749a8bc/57bb23ebNfe011bfe.jpg">
所以,完整的正则表达式应该是这两种格式的或:
<img width="200" height="200" data-img="1" src="//(.+?\.jpg)">|
到这里,我们根据该正则表达式,就可以提取出一个页面中所有想要爬取的图片链接。
所以,根据上面的分析,我们可以得到该爬虫的编写思路与过程,具体如下:
建立一个爬取图片的自定义函数,该函数负责爬取一个页面下的我们想爬取的图片,爬取过程为:首先通过urllib.request.utlopen(url).read()读取对应网页的全部源代码,然后根据上面的第一个正则表达式进行第一次信息过滤,过滤完成之后,在第一次过滤结果的基础上,根据上面的第二个正则表达式进行第二次信息过滤,提取出该网页上所有的目标图片的链接,并将这些链接地址存储的一个列表中,随后遍历该列表,分别将对应链接通过urllib.request.urlretrieve(imageurl,filename=imagename)存储到本地,为了避免程序中途异常崩溃,我们可以建立异常处理。
通过for循环将该分类下的所有网页都爬取一遍,链接可以构造为url='https://list.jd.com/list.html?cat=1713,3287,3797&page=' + str(i)
完整的代码如下:
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import re import urllib.request import urllib.error import urllib.parse sum = 0 def craw(url,page): html1=urllib.request.urlopen(url).read() html1=str(html1) pat1=r'<p id="plist".+? <p class="page clearfix">' result1=re.compile(pat1).findall(html1) result1=result1[0] pat2=r'<img width="200" height="200" data-img="1" src="//(.+?\.jpg)">|' imagelist=re.compile(pat2).findall(result1) x=1 global sum for imageurl in imagelist: imagename='./books/'+str(page)+':'+str(x)+'.jpg' if imageurl[0]!='': imageurl='http://'+imageurl[0] else: imageurl='http://'+imageurl[1] print('开始爬取第%d页第%d张图片'%(page,x)) try: urllib.request.urlretrieve(imageurl,filename=imagename) except urllib.error.URLError as e: if hasattr(e,'code') or hasattr(e,'reason'): x+=1 print('成功保存第%d页第%d张图片'%(page,x)) x+=1 sum+=1 for i in range(1,251): url='https://list.jd.com/list.html?cat=1713,3287,3797&page='+str(i) craw(url,i) print('爬取图片结束,成功保存%d张图'%sum)
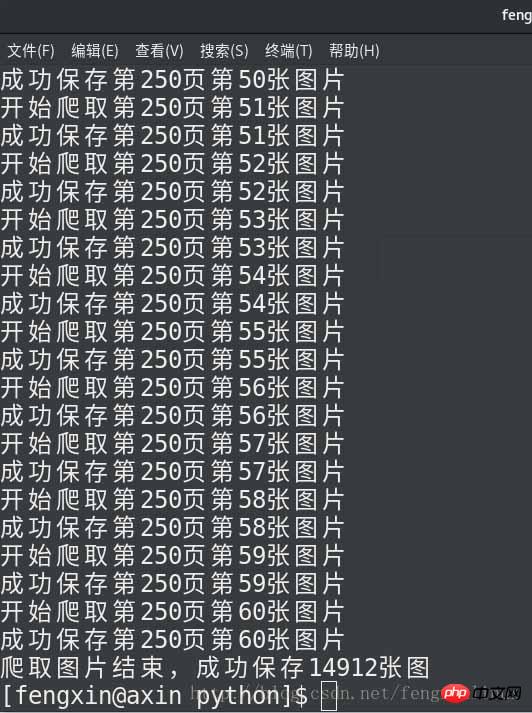
运行结果如下:
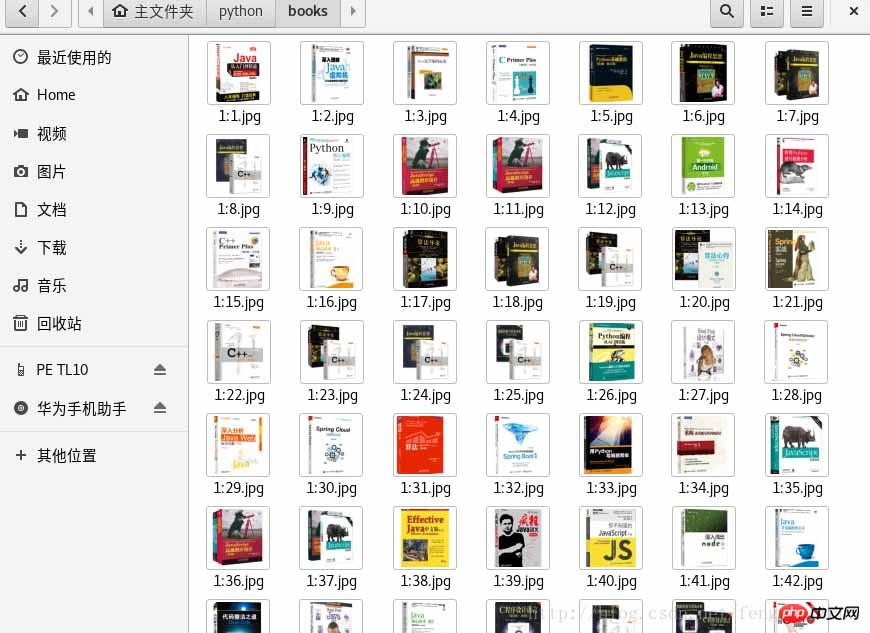
总结
Das obige ist der detaillierte Inhalt vonDetaillierte Grafik- und Texterklärung des praktischen Python3-Crawlers zum Crawlen von Jingdong-Büchern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So öffnen Sie die Win11-Systemsteuerung
So öffnen Sie die Win11-Systemsteuerung
 Der Unterschied zwischen Pascal-Sprache und C-Sprache
Der Unterschied zwischen Pascal-Sprache und C-Sprache
 Fil-Währungspreis Echtzeitpreis
Fil-Währungspreis Echtzeitpreis
 Mehrere Möglichkeiten zur Datenerfassung
Mehrere Möglichkeiten zur Datenerfassung
 Verwendung von Versprechen
Verwendung von Versprechen
 Welche virtuellen Währungen könnten im Jahr 2024 stark ansteigen?
Welche virtuellen Währungen könnten im Jahr 2024 stark ansteigen?
 Der Unterschied zwischen MS Office und WPS Office
Der Unterschied zwischen MS Office und WPS Office
 Was ist Python-Programmierung?
Was ist Python-Programmierung?
 Handelsplattform für virtuelle Währungen
Handelsplattform für virtuelle Währungen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



