

Was ist die Hauptursache für verstümmelte Webseiten?
先看段代码:
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>网页编码</title> </head> <body> </body> </html>
HTML代码中的 指定了网页的编码为utf-8。
网页编码涉及的知识点比较多,总的说来它也是一个历史遗留问题。
第一台计算机(ENIAC)于1946年2月诞生于美国,当时美国只考虑自己使用,并在计算机诞生后的几年里制定了一套ASCII码标准(American Standard Code for Information Interchange,美国信息交换标准代码),它是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
ASCII码使用8位二进制数组合来表示256种可能的字符(2的8次方=256),包含了大小写字母,数字0到9,标点符号,以及在美式英语中使用的特殊控制字符。一个字符占1个字节。ASCII码表部分编码如下:
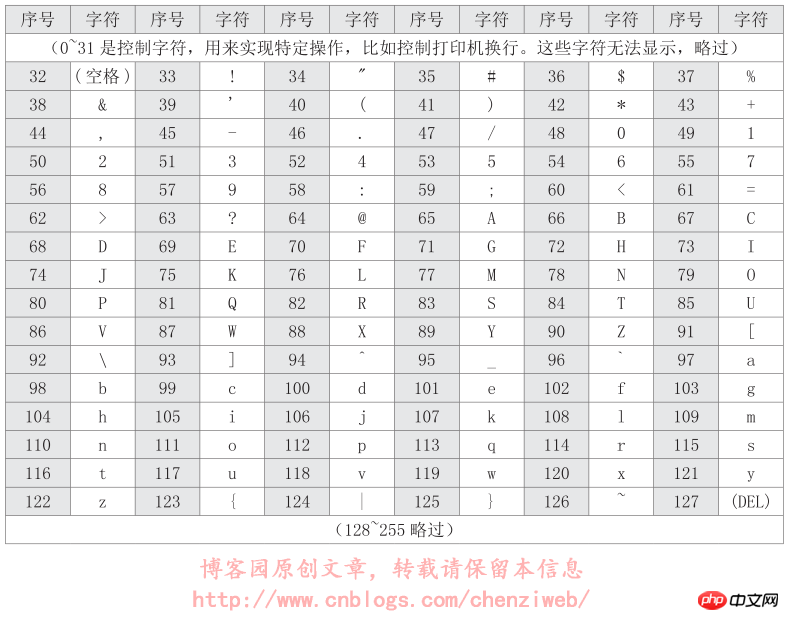
HTML的转义符(字符实体),比如符号“<”的转义符为“<”或“<”,其中的数字编号“60”即是ASCII码表的第60序号。类似的,大写字母“K”也可以转义为“K”。
我们使用转义符做个试验: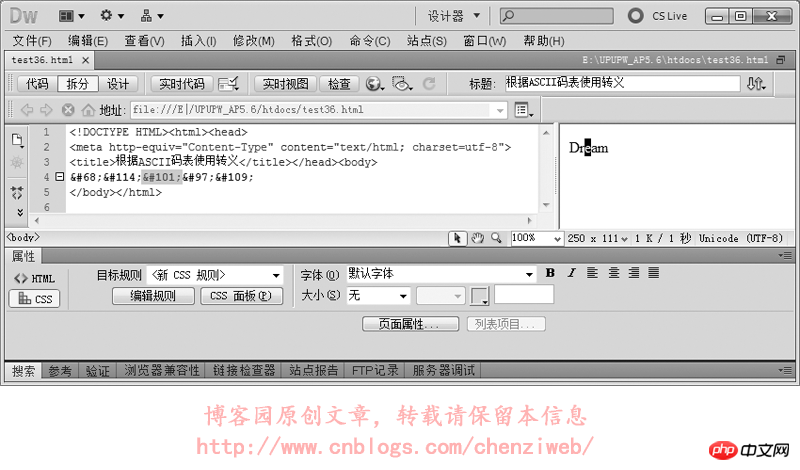
美国制定ASCII码的意思是:ASCII码可以满足在计算机领域所有字符和表示上的需要。不过这只是美国自己的意思,毕竟所有的英文单词都可以拆分来自26个英文字母,ASCII码表能表达256个字符,确实足够美国使用。
后来世界各地也都开始使用计算机,很多国家的语言文字并不是英文,这些国家的文字都没被包含在ASCII码表里。以我们中国为例,汉字近10万个,根本无法排进ASCII码表。于是我们国家对ASCII码表进行拓展并形成自己的的一套标准,在标准中一个汉字占2个字节,新的码表可以表达65536个汉字。但一开始并没有将码表全部填充使用完,只收录了常用的6000多个汉字、英文及其它符号,这套标准称为GB2312(信息交换用汉字编码字符集,GB是“国家标准”的简化词“国标”的拼音首字母缩写,2312是国标序号)。后来又制定了一套收录更多汉字的标准(收录的汉字有2万多个),称为GBK(汉字编码扩展规范,K是“扩”的拼音首字母)。
在GB2312或GBK里,许多标点符号都使用2个字节进行了重新编码,这类占2个字节的标点符号称为“全角”字符(“全角”也称“全形”或“全宽”或“全码”),原来ASCII码表中占1个字节的标点符号则称为“半角”字符(“半角”也称“半形”或“半宽”或“半码”)。全角的逗号、括号、句号等与半角是不一样的:
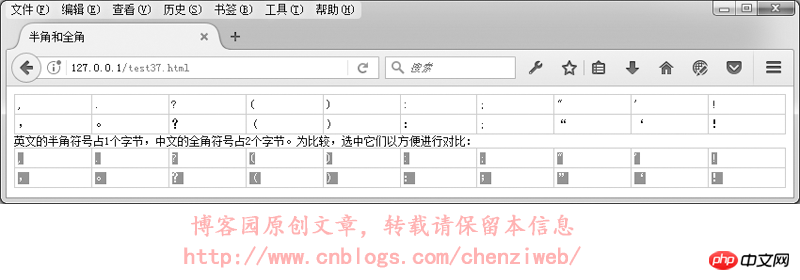
Bei der chinesischen Eingabemethode sind die Standardsatzzeichen Zeichen voller Breite; bei der englischen Eingabemethode sind die Satzzeichen Zeichen halber Breite.
Machen wir mit der Geschichte weiter: Da immer mehr Länder Computer verwenden, formulieren immer mehr Länder ihre eigenen Computercodierungsstandards. Das Ergebnis ist, dass sich die Computercodierung in verschiedenen Ländern nicht gegenseitig unterstützt oder versteht. Wenn Sie beispielsweise chinesische Schriftzeichen auf einem Computer in den USA anzeigen möchten, müssen Sie ein chinesisches Schriftzeichensystem installieren. Andernfalls werden chinesische Dateien beim Öffnen auf einem Computer mit einem amerikanischen System verstümmelt.
Auf diese Weise wurde in dieser Zeit eine internationale Organisation namens ISO (International Organization for Standardization, Internationale Organisation für Normung) gegründet, um mit der Lösung von Codierungsproblemen in verschiedenen Ländern zu beginnen. ISO hat ein einheitliches Codierungsschema namens UNICODE (Universal Multiple-Octet Coded Character Set, auch UCS genannt) entwickelt, mit dem alle Wörter und Symbole auf der Welt aufgezeichnet werden. UNICODE-Zeichen sind in 17 Gruppen unterteilt, und jede Gruppe wird als Ebene bezeichnet. Jede Ebene verfügt über 65536 Codepunkte und es können insgesamt 1114112 Zeichen aufgezeichnet werden (1,11 Millionen Zeichen, eine ausreichend große Kapazität). Die Unicode-Kodierung vereinheitlicht ein Zeichen und belegt 2 Bytes.
Doch UNICODE konnte lange Zeit nicht gefördert werden, bis die Übertragung und der Austausch von Daten eine Vereinheitlichung der Kodierung zwischen den Ländern erforderlich machten. Frühere Festplatten und Netzwerkverkehr waren jedoch sehr teuer. Jedes Zeichen in der UNICODE-Codierung belegte daher 2 Bytes an Kapazität, um den beim Speichern von Dateien belegten Festplattenspeicher und auch die für die Übertragung von Zeichen erforderliche Zeit zu sparen über das Netzwerk, Um den Netzwerkverkehr zu belegen, wurden viele auf UNICODE basierende übertragungsorientierte Standards formuliert. Diese übertragungsorientierten Standards werden zusammenfassend als UTF (UCS Transfer Format) bezeichnet. UNICODE-Codierung und UTF-Codierung haben keine direkte Eins-zu-eins-Entsprechung, sondern müssen durch einige Algorithmen und Regeln konvertiert werden. Die Beziehung zwischen UNICODE und UTF ist: UNICODE ist die Grundlage, Grundlage und Zweck, während UTF nur ein Mittel, eine Methode und ein Prozess zur Realisierung von UNICODE ist.
Gängige UTF-Formate sind: UTF-8, UTF-16, UTF-32. Unter diesen ist UTF-8 die am weitesten verbreitete UNICODE-Implementierung im Internet. Sie ist speziell für die Übertragung konzipiert. Gerade weil es sich bei UTF-8 um eine auf UNICODE basierende Übertragungsimplementierungsmethode handelt, ist eine Kodierung ohne Grenzen möglich, und Text aus jedem Land kann in einem Computerbrowser in jedem Land normal angezeigt werden. Eines der größten Merkmale von UTF-8 ist, dass es sich um eine Codierungsmethode mit variabler Länge handelt. Es kann 1 bis 4 Bytes zur Darstellung eines Symbols verwenden Wenn ein Symbol dargestellt wird, wird 1 Byte verwendet, um es darzustellen. Wenn für ein Symbol 2 Bytes erforderlich sind, werden 2 Bytes verwendet, um es darzustellen, und so weiter, bis zu 4 Bytes, wodurch Speicherplatz auf der Festplatte und Netzwerkverkehr gespart werden .
Wenn unsere Website also mit der GB2312- oder GBK-Kodierung entwickelt wurde und Computer in anderen Ländern die Kodierung chinesischer Zeichen nicht unterstützen, werden Sie verstümmelte Codes sehen, die wie folgt angezeigt werden: 口口口口口. Wenn die Website die UTF-8-Kodierung verwendet, wird der Inhalt automatisch in die UNICODE-Kodierung konvertiert, wenn ein Computer in einem beliebigen Land die Website öffnet, und da alle modernen Computer die UNICODE-Kodierung unterstützen, kann jeder Text normal angezeigt werden!
Viele inländische Websites verwenden jedoch immer noch die GB2312- oder GBK-Kodierung. Solche Websites bieten normalerweise nur Dienste für inländische Benutzer an und haben für inländische Benutzer keine Anzeigeprobleme. Betrachtet man solche Websites jedoch mit Besuchern aus anderen Ländern, werden sie beim Öffnen größtenteils verstümmelt erscheinen.
Aus Gründen einer hohen Kompatibilität und Internationalisierung der Website wird empfohlen, dass die Website die UTF-8-Kodierung anstelle der GB2312- oder GBK-Kodierung verwendet.
Die Tags, die Webseiten als UTF-8, GB2312 und GBK angeben, sind:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <meta http-equiv="Content-Type" content="text/html; charset=gbk">
那么有一个问题出现了:网页各种编码的区别,仅仅是在于这一行meta标签的设置差别吗?仅仅是“utf-8”这5个字符换成“gb2312”这6个字符之类的这种“小差别”吗?
不是的,差别不仅仅是这几个字符的差别。当网页指定meta标签中的编码为utf-8后,DreamWeaver在保存网页时会自动将网页文件保存为utf-8的编码格式(二进制码使用utf-8的编码格式),meta标签中的utf-8编码是为了告诉浏览器:这个网页用的是utf-8编码,请在显示时使用utf-8编码的格式解析并呈现出来;而如果meta标签中指定编码为gb2312,DreamWeaver在保存网页时会自动将网页文件保存为gb2312的编码格式(二进制码使用gb2312的编码格式),同样,meta标签中的gb2312编码只是为了告诉浏览器:这个网页用的是gb2312编码,请在显示时使用gb2312编码的格式解析并呈现出来。我们做个试验,将一个文本文件分别保存为utf-8格式(打开记事本新建文本文件,输入内容后,选择菜单:文件→另存为,编码选择为UTF-8)和gb2312格式(另存时编码选择为ANSI,ANSI代表当前操作系统的默认编码,在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码,类推),对比其二进制数据。这里使用UltraEdit-32文件编辑器对文本文件进行16进制查看,即使用16进制查看文件的二进制数据: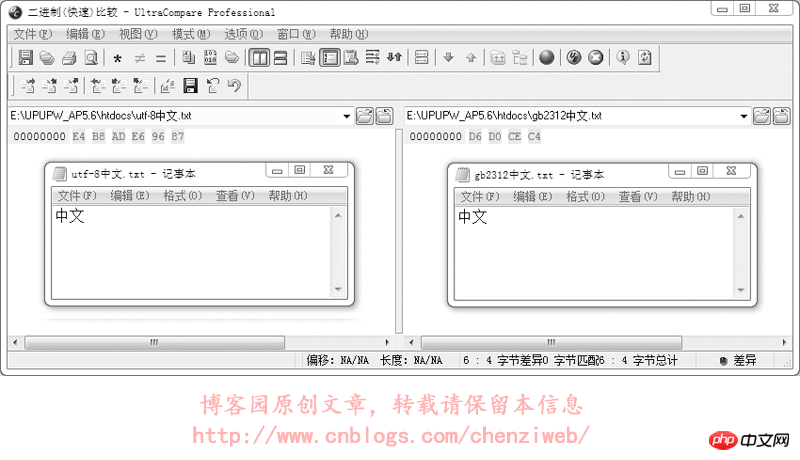
从上图中可以看到,使用utf-8编码和使用gb2312编码保存的文件,其二进制数据是不一样的,即这两个文件的二进制数据内容是不一样的。记事本软件在打开文本文件时,会尝试识别文件的编码并进行解析和显示,即文字保存在记事本里,无论保存成utf-8编码还是gb2312编码,通常情况下记事本都能正常识别和显示,不需要在文件里额外记录数据以告知记事本该文件是什么编码。但很多软件却无法做到智能识别文本文件的编码,这就要求文本文件在保存时,必须附带一些特殊的内容(额外的数据)以告知该文件是什么编码。UNICODE规范中有一个BOM(Byte Order Mark)的概念,就是字节序标记,在文件头部开始位置写入三个字节(EF BB BF)以告知该文件是utf-8编码格式。但这个BOM又带出了新的问题:不是所有的软件或处理程序都支持BOM,即不是所有的软件或处理程序都能识别文件开头的(EF BB BF)这三个字节。当不支持识别时,这三个字节又会被当成文件的实际数据内容。早期的火狐不支持对BOM的识别,当遇到BOM时会对这三个字节显示出特殊的乱码符号;而到目前为止,PHP处理程序仍然不支持BOM,即当一个PHP文件保存为utf-8时,如果附带了BOM,那么PHP处理程序会将BOM解析为PHP文件的实际数据内容而导致出错!在DreamWeaver中,选择软件头部菜单:修改→页面属性(也可以直接按快捷键ctrl+j),在弹出的页面属性面板中点选“标题/编码”,即可看到可供选择的编码。通常在改变网页的编码时,使用这种方式改变。如下图: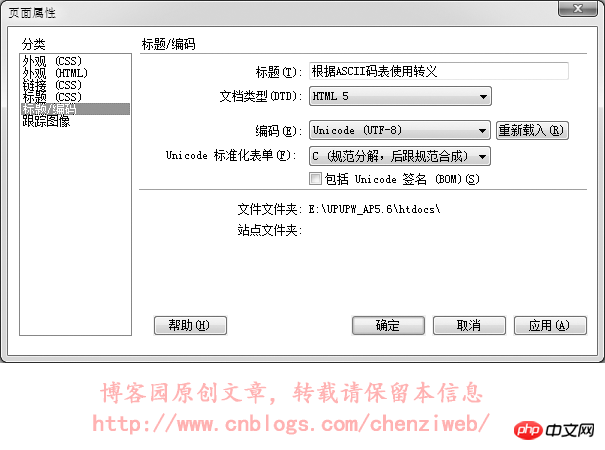
所以:当我们在meta标签中设置为utf-8编码格式时,网页文件就必须要存储为utf-8格式,这样浏览器才能正常显示网页而不是显示乱码。如果在meta标签中设置utf-8编码格式,网页文件却保存为gbk或其它格式,那么在打开网页时浏览器会接到网页meta标签中格式的通知:使用utf-8编码格式来解析和显示网页,而网页的二进制码(数据内容)却为gbk编码或其它格式,显示出来就会是乱码!这好比相亲时,红娘手里的资料有误,错误的告知男方:女方讲英语(meta标签中设置为utf-8编码)。结果女方却不懂英语(文件却不是utf-8编码)。男方开口一句“Hello”就让女方不知所谓了(乱码)。
我们来实验一下,网页指定meta标签中的编码为utf-8,文件却保存为gbk格式:我们先用DreamWeaver编辑一个utf-8格式的网页并保存,然后再用记事本打开该网页,另存为,编码选择为ANSI。
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>中文</title> </head> <body> 本文件使用dreamweaver保存后,再使用记事本打开,并另存为ANSI编码。 </body> </html>
在浏览器中的执行结果如下:
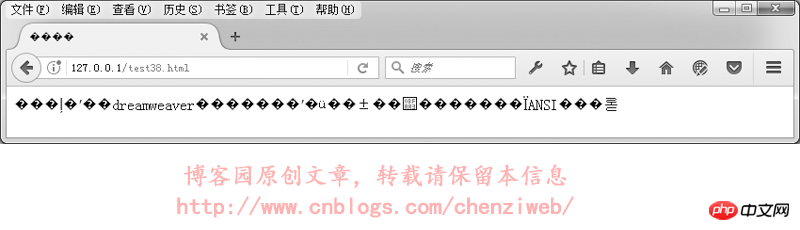
Zusammenfassend: Versuchen Sie beim Entwickeln von Webseiten, das UTF-8-Kodierungsformat zu verwenden, und speichern Sie Dateien beim Speichern mit der UTF-8-Kodierung. (Wenn Dreamweaver Webseitendateien speichert, speichert es automatisch die richtige Kodierung gemäß der durch Entsprechende Kodierung. Wenn Sie jedoch andere Website-Code-Editoren wie Notepad, Editplus usw. verwenden, müssen Sie beim Speichern der Datei auf die Auswahl der richtigen Kodierung achten.
Das obige ist der detaillierte Inhalt vonWas ist die Hauptursache für verstümmelte Webseiten?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Was ist der Grund, warum Screencasting fehlschlägt? „Ein Muss für Neulinge: Wie man das Problem einer erfolglosen drahtlosen Screencasting-Verbindung löst'
Feb 07, 2024 pm 05:03 PM
Was ist der Grund, warum Screencasting fehlschlägt? „Ein Muss für Neulinge: Wie man das Problem einer erfolglosen drahtlosen Screencasting-Verbindung löst'
Feb 07, 2024 pm 05:03 PM
Warum kann beim drahtlosen Screencasting keine Verbindung hergestellt werden? Einige Freunde haben berichtet, dass die Verbindung bei Verwendung der drahtlosen Bildschirmspiegelung fehlschlägt. Was ist los? Was soll ich tun, wenn die drahtlose Bildschirmspiegelungsverbindung fehlschlägt? Bitte bestätigen Sie, ob Ihr Computer, Ihr Fernseher und Ihr Mobiltelefon mit demselben WLAN-Netzwerk verbunden sind. Für die ordnungsgemäße Funktion von Bildschirmspiegelungssoftware müssen sich die Geräte im selben Netzwerk befinden, und Quick Screen Mirroring bildet da keine Ausnahme. Bitte überprüfen Sie daher schnell Ihre Netzwerkeinstellungen. Es ist wichtig festzustellen, ob die Bildschirmspiegelungsfunktion unterstützt wird. Smart-TVs und Mobiltelefone unterstützen in der Regel die DLNA- oder AirPlay-Funktionalität. Wenn die Screencast-Funktion nicht unterstützt wird, ist kein Screencasting möglich. Überprüfen Sie, ob das Gerät richtig verbunden ist: Möglicherweise befinden sich mehrere Geräte im selben WLAN. Stellen Sie sicher, dass Sie eine Verbindung zu dem Gerät herstellen, mit dem Sie den Bildschirm teilen möchten. 4. Stellen Sie sicher, dass das Netzwerk
 So lösen Sie verstümmelte chinesische Zeichen unter Linux
Feb 21, 2024 am 10:48 AM
So lösen Sie verstümmelte chinesische Zeichen unter Linux
Feb 21, 2024 am 10:48 AM
Das verstümmelte Linux-Chinesisch-Problem ist ein häufiges Problem bei der Verwendung chinesischer Zeichensätze und Kodierungen. Verstümmelte Zeichen können durch falsche Dateikodierungseinstellungen, nicht installiertes oder eingestelltes Systemgebietsschema, Konfigurationsfehler bei der Terminalanzeige usw. verursacht werden. In diesem Artikel werden mehrere gängige Problemumgehungen vorgestellt und spezifische Codebeispiele bereitgestellt. 1. Überprüfen Sie die Dateikodierungseinstellung. Verwenden Sie den Dateibefehl im Terminal, um die Kodierung der Datei anzuzeigen: file-ifilename
 Was führt dazu, dass WPS Office einen Druckauftrag nicht starten kann?
Mar 20, 2024 am 09:52 AM
Was führt dazu, dass WPS Office einen Druckauftrag nicht starten kann?
Mar 20, 2024 am 09:52 AM
Beim Anschließen eines Druckers an ein lokales Netzwerk und beim Starten eines Druckauftrags können einige kleinere Probleme auftreten. Beispielsweise tritt gelegentlich das Problem „wpsoffice kann den Druckauftrag nicht starten“ auf, was dazu führt, dass Dateien nicht gedruckt werden können usw ., was unsere Arbeit und unser Studium verzögert und negative Auswirkungen hat. Lassen Sie mich Ihnen sagen, wie Sie das Problem lösen können, dass wpsoffice den Druckauftrag nicht starten kann. Natürlich können Sie die Software oder den Treiber aktualisieren, um das Problem zu lösen, aber das wird lange dauern. Im Folgenden gebe ich Ihnen eine Lösung, die in wenigen Minuten gelöst werden kann. Zunächst ist mir aufgefallen, dass wpsoffice den Druckauftrag nicht starten kann, was dazu führt, dass nicht gedruckt werden kann. Um dieses Problem zu lösen, müssen wir es einzeln untersuchen. Stellen Sie außerdem sicher, dass der Drucker eingeschaltet und angeschlossen ist. Im Allgemeinen führt dies zu einer abnormalen Verbindung
 Umfassender Leitfaden zu PHP 500-Fehlern: Ursachen, Diagnose und Korrekturen
Mar 22, 2024 pm 12:45 PM
Umfassender Leitfaden zu PHP 500-Fehlern: Ursachen, Diagnose und Korrekturen
Mar 22, 2024 pm 12:45 PM
Ein umfassender Leitfaden zu PHP500-Fehlern: Ursachen, Diagnose und Korrekturen Während der PHP-Entwicklung stoßen wir häufig auf Fehler mit dem HTTP-Statuscode 500. Dieser Fehler wird normalerweise „500InternalServerError“ genannt, was bedeutet, dass bei der Verarbeitung der Anfrage auf der Serverseite einige unbekannte Fehler aufgetreten sind. In diesem Artikel untersuchen wir die häufigsten Ursachen von PHP500-Fehlern, wie man sie diagnostiziert und behebt und stellen spezifische Codebeispiele als Referenz bereit. Häufige Ursachen für 1.500 Fehler 1.
 So lösen Sie das Problem verstümmelter chinesischer Zeichen in Windows 10
Jan 16, 2024 pm 02:21 PM
So lösen Sie das Problem verstümmelter chinesischer Zeichen in Windows 10
Jan 16, 2024 pm 02:21 PM
Im Windows 10-System sind verstümmelte Zeichen häufig. Der Grund dafür ist häufig, dass das Betriebssystem einige Zeichensätze nicht standardmäßig unterstützt oder dass ein Fehler in den eingestellten Zeichensatzoptionen vorliegt. Um das richtige Medikament zu verschreiben, analysieren wir im Folgenden die tatsächlichen Betriebsabläufe im Detail. So lösen Sie verstümmelten Windows 10-Code: 1. Öffnen Sie die Einstellungen und suchen Sie nach „Zeit und Sprache“. 2. Suchen Sie dann nach „Sprache“. 3. Suchen Sie nach „Spracheinstellungen verwalten“. 4. Klicken Sie hier auf „Regionale Systemeinstellungen ändern“. 5. Überprüfen Sie, wie gezeigt, und klicken Sie Stellen Sie einfach sicher.
 Warum lädt das Apple-Handy so langsam?
Mar 08, 2024 pm 06:28 PM
Warum lädt das Apple-Handy so langsam?
Mar 08, 2024 pm 06:28 PM
Bei einigen Benutzern kann es bei der Verwendung von Apple-Telefonen zu langsamen Ladegeschwindigkeiten kommen. Es gibt viele Gründe für dieses Problem. Es kann durch eine geringe Leistung des Ladegeräts, einen Geräteausfall, Probleme mit der USB-Schnittstelle des Mobiltelefons oder sogar durch Alterung des Akkus und andere Faktoren verursacht werden. Warum lädt das Apple-Handy sehr langsam? Antwort: Problem mit der Ladeausrüstung, Problem mit der Hardware des Mobiltelefons, Problem mit dem Mobiltelefonsystem. 1. Wenn Benutzer Ladegeräte mit relativ geringer Leistung verwenden, ist die Ladegeschwindigkeit des Mobiltelefons sehr langsam. 2. Auch die Verwendung minderwertiger Ladegeräte oder Ladekabel von Drittanbietern führt zu langsamem Laden. 3. Es wird empfohlen, dass Benutzer das offizielle Original-Ladegerät verwenden oder es durch ein normales zertifiziertes Hochleistungsladegerät ersetzen. 4. Es liegt ein Problem mit der Mobiltelefon-Hardware des Benutzers vor. Beispielsweise kann die USB-Schnittstelle des Mobiltelefons nicht kontaktiert werden.
 Aufdecken der Hauptursachen für den Win11-Bluescreen
Jan 04, 2024 pm 05:32 PM
Aufdecken der Hauptursachen für den Win11-Bluescreen
Jan 04, 2024 pm 05:32 PM
Ich glaube, viele Freunde sind auf das Problem des System-Bluescreens gestoßen, aber ich weiß nicht, was die Ursache des Win11-Bluescreens ist. Tatsächlich gibt es viele Gründe für den System-Bluescreen, und wir können sie der Reihe nach untersuchen und lösen. Gründe für den Win11-Bluescreen: 1. Unzureichender Speicher 1. Dies kann auftreten, wenn zu viel Software ausgeführt wird oder das Spiel zu viel Speicher verbraucht. 2. Insbesondere jetzt gibt es in Win11 einen Speicherüberlauffehler, daher ist es sehr wahrscheinlich, dass er auftritt. 3. Zu diesem Zeitpunkt können Sie versuchen, den virtuellen Speicher einzurichten, um das Problem zu lösen. Der beste Weg ist jedoch, das Speichermodul zu aktualisieren. 2. CPU-Übertaktung und Überhitzung 1. Die Ursachen von CPU-Problemen ähneln tatsächlich denen des Speichers. 2. Es tritt normalerweise auf, wenn Nachbearbeitungs-, Modellierungs- und andere Software verwendet wird oder wenn umfangreiche Spiele gespielt werden. 3. Wenn der CPU-Verbrauch zu hoch ist, erscheint ein Bluescreen.
 Bearbeitungsmethode zur Lösung des Problems verstümmelter Zeichen beim Öffnen von DLL-Dateien
Jan 06, 2024 pm 07:53 PM
Bearbeitungsmethode zur Lösung des Problems verstümmelter Zeichen beim Öffnen von DLL-Dateien
Jan 06, 2024 pm 07:53 PM
Wenn viele Benutzer Computer verwenden, werden sie feststellen, dass es viele Dateien mit der Endung dll gibt, aber viele Benutzer wissen nicht, wie man solche Dateien öffnet. Wer es wissen möchte, schaut sich bitte die folgenden Details an So öffnen und bearbeiten Sie DLL-Dateien: 1. Laden Sie eine Software namens „Exescope“ herunter, laden Sie sie herunter und installieren Sie sie. 2. Klicken Sie dann mit der rechten Maustaste auf die DLL-Datei und wählen Sie „Ressourcen mit Exescope bearbeiten“. 3. Klicken Sie dann im Popup-Fehlerfeld auf „OK“. 4. Klicken Sie dann im rechten Bereich auf das „+“-Zeichen vor jeder Gruppe, um den darin enthaltenen Inhalt anzuzeigen. 5. Klicken Sie auf die DLL-Datei, die Sie anzeigen möchten, klicken Sie dann auf „Datei“ und wählen Sie „Exportieren“. 6. Dann können Sie
