

Dieser Artikel erklärt Ihnen hauptsächlich, wie Sie NodeJS zum Erlernen von Crawlern verwenden, und erklärt die Verwendung und Auswirkungen des Crawlens der Encyclopedia of Embarrassing Things. Es gibt eine NodeJS-Quellcode-Analyse. jaNodeJSWenn Sie interessiert sind, lassen Sie uns gemeinsam lernen.
1. Vorwort-Analyse
Wir verwenden normalerweise die Sprache Python/.NET, um Crawler zu implementieren, aber jetzt natürlich als Front-End-Entwickler Erfordert Kenntnisse in NodeJS. Lassen Sie uns die NodeJS-Sprache verwenden, um einen Crawler für die Encyclopedia of Embarrassing Things zu implementieren. Darüber hinaus haben einige der in diesem Artikel verwendeten Codes die ES6-Syntax.
Die zur Implementierung dieses Crawlers erforderlichen abhängigen Bibliotheken sind wie folgt.
Anfrage: Verwenden Sie die Get- oder Post-Methode, um den Quellcode der Webseite abzurufen. Cheerio: Analysieren Sie den Quellcode der Webseite und erhalten Sie die erforderlichen Daten.
In diesem Artikel werden zunächst die vom Crawler benötigten Abhängigkeitsbibliotheken und deren Verwendung vorgestellt. Anschließend werden diese Abhängigkeitsbibliotheken verwendet, um einen Webcrawler für Encyclopedia of Embarrassing Things zu implementieren.
2. Request-Bibliothek
request ist eine leichte http-Bibliothek, die sehr leistungsstark und einfach zu verwenden ist. Sie können damit HTTP-Anfragen implementieren und unterstützen HTTP-Authentifizierung, benutzerdefinierte Anforderungsheader usw. Nachfolgend finden Sie eine Einführung in einige der Funktionen in der Anforderungsbibliothek.
Installieren Sie das Anforderungsmodul wie folgt:
npm install request
Nachdem die Anforderung installiert wurde, können Sie sie verwenden. wie folgt: Verwenden Sie die Anforderung, um die Webseite von Baidu anzufordern.
const req = require('request');
req('http://www.baidu.com', (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})Wenn der Optionsparameter nicht festgelegt ist, ist die Anforderungsmethode standardmäßig eine Get-Anfrage. Die spezifische Methode, die ich gerne für das Anforderungsobjekt verwende, ist wie folgt:
req.get({
url: 'http://www.baidu.com'
},(err, res, body) => {
if (!err && res.statusCode == 200) {
console.log(body)
}
});Wenn wir jedoch den von einer URL erhaltenen HTML-Quellcode direkt anfordern, können wir oft nicht die benötigten Informationen erhalten. Im Allgemeinen müssen Anforderungsheader und Webseitenkodierung berücksichtigt werden.
Webseiten-Anfrage-Header Webseiten-Codierung
Im Folgenden wird beschrieben, wie man einen Webseiten-Anfrage-Header hinzufügt und bei der Anfrage die richtige Codierung festlegt.
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Host" : "www.zhihu.com",
"Upgrade-Insecure-Requests" : "1"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(!err)
console.log(body);
})Legen Sie den Optionsparameter fest und fügen Sie das Attribut headers hinzu, um das zu implementieren Request-Header-Einstellungen; fügen Sie das Attribut encoding hinzu, um die Kodierung der Webseite festzulegen. Es ist zu beachten, dass bei encoding:null der durch die Get-Anforderung erhaltene Inhalt ein Buffer-Objekt ist, dh der Körper ist ein Pufferobjekt.
Die oben vorgestellten Funktionen reichen aus, um die folgenden Anforderungen zu erfüllen
3. Cheerio-Bibliothek
Cheerio ist ein Server- side Jquery wird von Entwicklern wegen seiner Funktionen wie Leichtigkeit, Schnelligkeit und einfacher Erlernbarkeit geliebt. Es ist sehr einfach, die Cheerio-Bibliothek zu erlernen, wenn man über Grundkenntnisse in Jquery verfügt. Es kann Elemente in Webseiten schnell finden und seine Regeln sind die gleichen wie die Methode von Jquery zum Auffinden von Elementen. Außerdem kann es den Inhalt von Elementen in HTML ändern und ihre Daten in einer sehr praktischen Form abrufen. Im Folgenden wird hauptsächlich Cheerio vorgestellt, um Elemente auf Webseiten schnell zu finden und deren Inhalte abzurufen.
Installieren Sie zuerst die Cheerio-Bibliothek
npm install cheerio
Das Folgende ist zuerst ein Codeteil und wird dann erklärt Der Code Cheerio-Bibliotheksnutzung. Analysieren Sie die Homepage des Blogparks und extrahieren Sie die Titel der Artikel auf jeder Seite.
Analysieren Sie zunächst die Homepage des Blogparks. Wie unten gezeigt:
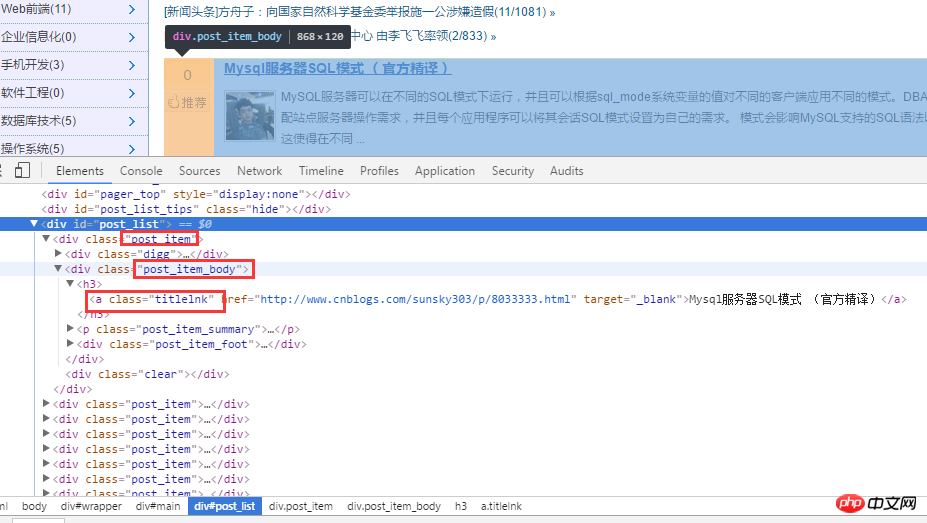
Erhalten Sie nach der Analyse des HTML-Quellcodes zunächst alle Titel über .post_item und analysieren Sie dann jeden .post_item mit a.titlelnk, der mit dem übereinstimmt ein Tag für jeden Titel. Das Folgende wird durch Code implementiert.
const req = require('request');
const cheerio = require('cheerio');
req.get({
url: 'https://www.cnblogs.com/'
}, (err, res, body) => {
if (!err && res.statusCode == 200) {
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
$('.post_item').each((index, ele) => {
let title = $(ele).find('a.titlelnk');
let titleText = title.text();
let titletUrl = title.attr('href');
console.log(titleText, titletUrl);
});
}
});Natürlich unterstützt die Cheerio-Bibliothek auch Kettenanrufe und die oben genannten Code auch Es kann wie folgt umgeschrieben werden:
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
let titles = $('.post_item').find('a.titlelnk');
titles.each((index, ele) => {
let titleText = $(ele).text();
let titletUrl = $(ele).attr('href');
console.log(titleText, titletUrl);Der obige Code ist sehr einfach und wird nicht erneut verwendet. Im Folgenden fasse ich einige Punkte zusammen, die ich für wichtiger halte.
使用 find() 方法获取的节点集合 A,若再次以 A 集合中的元素为根节点定位它的子节点以及获取子元素的内容与属性,需对 A 集合中的子元素进行 $(A[i]) 包装,如上面的$(ele) 一样。在上面代码中使用 $(ele) ,其实还可以使用 $(this) 但是由于我使用的是 es6 的箭头函数,因此改变了 each 方法中回调函数的 this 指针,因此,我使用 $(ele); cheerio 库也支持链式调用,如上面的 $('.post_item').find('a.titlelnk') ,需要注意的是,cheerio 对象 A 调用方法 find(),如果 A 是一个集合,那么 A 集合中的每一个子元素都调用 find() 方法,并放回一个结果结合。如果 A 调用 text() ,那么 A 集合中的每一个子元素都调用 text() 并返回一个字符串,该字符串是所有子元素内容的合并(直接合并,没有分隔符)。
最后在总结一些我比较常用的方法。
first() last() children([selector]): 该方法和 find 类似,只不过该方法只搜索子节点,而 find 搜索整个后代节点。
4. 糗事百科爬虫
通过上面对 request 和 cheerio 类库的介绍,下面利用这两个类库对糗事百科的页面进行爬取。
1、在项目目录中,新建 httpHelper.js 文件,通过 url 获取糗事百科的网页源码,代码如下:
//爬虫
const req = require('request');
function getHtml(url){
return new Promise((resolve, reject) => {
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Referer" : "https://www.qiushibaike.com/"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(err) reject(err);
else resolve(body);
})
});
}
exports.getHtml = getHtml;2、在项目目录中,新建一个 Splider.js 文件,分析糗事百科的网页代码,提取自己需要的信息,并且建立一个逻辑通过更改 url 的 id 来爬取不同页面的数据。
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('p');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);在获取糗事百科网页信息的时候,首先在浏览器中对源码进行分析,定位到自己所需要标签,然后提取标签的文本或者属性值,这样就完成了网页的解析。
Splider.js 文件入口是 splider 方法,首先根据传入该方法的 index 索引,构造糗事百科的 url,接着获取该 url 的网页源码,最后将获取的源码传入 getQBJok 方法,进行解析,本文只解析每条文本笑话的作者、内容以及喜欢个数。
直接运行 Splider.js 文件,即可爬取第一页的笑话信息。然后可以更改 splider 方法的参数,实现抓取不同页面的信息。
在上面已有代码的基础上,使用 koa 和 vue2.0 搭建一个浏览文本的页面,效果如下:

源码已上传到 github 上。下载地址:https://github.com/StartAction/SpliderQB ;
项目运行依赖 node v7.6.0 以上, 首先从 Github 上面克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆之后,进入项目目录,运行下面命令即可。
node app.js
5. 总结
通过实现一个完整的爬虫功能,加深自己对 Node 的理解,且实现的部分语言都是使用 es6 的语法,让自己加快对 es6 语法的学习进度。另外,在这次实现中,遇到了 Node 的异步控制的知识,本文是采用的是 async 和 await 关键字,也是我最喜欢的一种,然而在 Node 中,实现异步控制有好几种方式。关于具体的方式以及原理,有时间再进行总结。
相关推荐:
Das obige ist der detaillierte Inhalt vonNodeJS-Crawler-Beispiel-Enzyklopädie der peinlichen Dinge_node.js. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



