

Die 10 wichtigsten Algorithmen für maschinelles Lernen, die Sie kennen müssen

Es besteht kein Zweifel, dass die Bereiche maschinelles Lernen und künstliche Intelligenz in den letzten Jahren immer mehr Aufmerksamkeit erhalten haben. Da Big Data zum heißesten Technologietrend in der Branche geworden ist, hat maschinelles Lernen mithilfe von Big Data auch erstaunliche Ergebnisse bei Vorhersagen und Empfehlungen erzielt. Zu den bekannteren Fällen des maschinellen Lernens gehören Netflix, das Benutzern Filme basierend auf ihrem historischen Surfverhalten empfiehlt, und Amazon, das Bücher basierend auf dem historischen Kaufverhalten der Benutzer empfiehlt. In diesem Artikel werden hauptsächlich die zehn wichtigsten Algorithmen vorgestellt, die in einer kurzen Diskussion über maschinelles Lernen verstanden werden müssen. Sie haben einen gewissen Referenzwert und Freunde in Not können sich darauf beziehen.
Wenn Sie also Algorithmen für maschinelles Lernen erlernen möchten, wie fangen Sie dann an? In meinem Fall war mein Einführungskurs ein Kurs über künstliche Intelligenz, den ich während meines Auslandsstudiums in Kopenhagen belegt habe. Der Lehrer ist Vollzeitprofessor für angewandte Mathematik und Informatik an der Technischen Universität Dänemark. Seine Forschungsrichtung ist Logik und künstliche Intelligenz, hauptsächlich Modellierung mit logischen Methoden. Der Kurs besteht aus zwei Teilen: Diskussion der Theorie/Kernkonzepte und praktische Praxis. Das Lehrbuch, das wir verwenden, ist eines der klassischen Bücher über künstliche Intelligenz: „Artificial Intelligence – A Modern Approach“ von Professor Peter Norvig. Der Kurs befasst sich mit intelligenten Agenten, suchbasierter Lösung, kontradiktorischer Suche, Wahrscheinlichkeitstheorie, Multi-Agenten-Systemen usw Sozialisierung, sowie Themen wie Ethik und Zukunft der Künstlichen Intelligenz. Später im Kurs haben wir drei auch gemeinsam ein Programmierprojekt durchgeführt und einen einfachen suchbasierten Algorithmus implementiert, um Transportaufgaben in einer virtuellen Umgebung zu lösen.
Ich habe durch den Kurs viel gelernt und habe vor, mich weiterhin intensiv mit diesem Thema zu befassen. In den letzten Wochen habe ich an mehreren Vorträgen über Deep Learning, neuronale Netze und Datenarchitektur im Raum San Francisco teilgenommen – sowie an einer Konferenz zum Thema maschinelles Lernen mit vielen bekannten Professoren. Am wichtigsten ist, dass ich mich Anfang Juni für den Online-Kurs „Einführung in maschinelles Lernen“ von Udacity angemeldet und die Kursinhalte vor ein paar Tagen abgeschlossen habe. In diesem Artikel möchte ich einige gängige Algorithmen für maschinelles Lernen vorstellen, die ich im Kurs gelernt habe.
Maschinelle Lernalgorithmen können normalerweise in drei Hauptkategorien unterteilt werden: überwachtes Lernen, unüberwachtes Lernen und verstärkendes Lernen. Überwachtes Lernen wird hauptsächlich in Szenarien verwendet, in denen ein Teil des Datensatzes (Trainingsdaten) über eine gewisse Vertrautheit (Beschriftungen) verfügt, die erhalten werden können, die restlichen Stichproben jedoch fehlen und vorhergesagt werden müssen. Unüberwachtes Lernen wird hauptsächlich verwendet, um implizite Beziehungen zwischen unbeschrifteten Datensätzen zu ermitteln. Reinforcement Learning liegt irgendwo dazwischen – jeder Schritt der Vorhersage oder des Verhaltens enthält mehr oder weniger Feedback-Informationen, aber es gibt keine genaue Bezeichnung oder Fehleraufforderung. Da es sich um einen Einführungskurs handelt, wird Reinforcement Learning nicht erwähnt, aber ich hoffe, dass die zehn Algorithmen für überwachtes und unüberwachtes Lernen ausreichen, um Ihren Appetit anzuregen.
Überwachtes Lernen
1. Entscheidungsbaum:
Der Entscheidungsbaum ist ein Entscheidungsunterstützungstool, das ein Baumdiagramm oder Baummodell verwendet, um die Entscheidung darzustellen -Erstellungsprozess und Folgeergebnisse, einschließlich probabilistischer Ereignisergebnisse usw. Bitte beachten Sie das Diagramm unten, um die Struktur des Entscheidungsbaums zu verstehen.
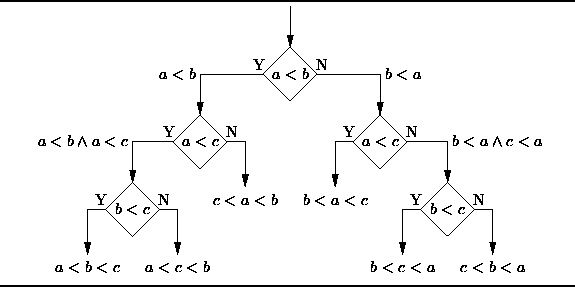
Aus Sicht der Geschäftsentscheidung besteht ein Entscheidungsbaum darin, die Wahrscheinlichkeit einer richtigen Entscheidung anhand möglichst weniger richtiger und falscher Beurteilungsfragen vorherzusagen. Dieser Ansatz kann Ihnen dabei helfen, mit einem strukturierten, systematischen Ansatz vernünftige Schlussfolgerungen zu ziehen.
2. Naive Bayes-Klassifikator:
Der Naive Bayes-Klassifikator ist ein einfacher probabilistischer Klassifikator, der auf der Bayes'schen Theorie basiert. Er geht davon aus, dass Merkmale zuvor unabhängig voneinander waren. Die folgende Abbildung zeigt die Formel: P(A|B) stellt die hintere Wahrscheinlichkeit dar, P(B|A) ist der Wahrscheinlichkeitswert, P(A) ist die frühere Wahrscheinlichkeit der Kategorie und P(B) stellt den Prädiktor dar. Prior-Wahrscheinlichkeit.

Einige Beispiele in realen Szenarien sind:
Spam-E-Mails erkennen
Kategorie von Nachrichten in Kategorien wie Technologie, Politik, Sport usw.
Bestimmen Sie, ob ein Text positive oder negative Emotionen ausdrückt
Wird in Gesichtserkennungssoftware verwendet
3. Regression der kleinsten Quadrate:
Wenn Sie einen Statistikkurs belegt haben, haben Sie vielleicht schon vom Konzept der linearen Regression gehört. Die Regression der kleinsten Quadrate ist eine Methode der linearen Regression. Sie können sich die lineare Regression als das Anpassen einer geraden Linie an mehrere Punkte vorstellen. Es gibt viele Anpassungsmethoden. Die „Kleinste-Quadrate“-Strategie entspricht dem Zeichnen einer geraden Linie, der anschließenden Berechnung des vertikalen Abstands von jedem Punkt zur geraden Linie und der abschließenden Summierung der am besten passenden geraden Linie die kleinste Summe der Entfernungen.
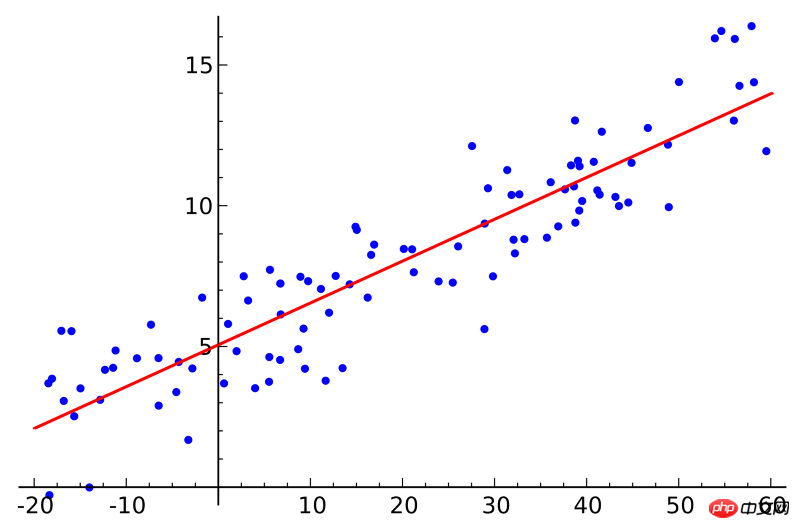
Linear bezieht sich auf das Modell, das zum Anpassen der Daten verwendet wird, während sich die Methode der kleinsten Quadrate auf die zu optimierende Verlustfunktion bezieht.
4. Logistische Regression:
Das logistische Regressionsmodell ist eine leistungsstarke statistische Modellierungsmethode, die eine oder mehrere erklärende Variablen zur Ausgabe binärer Ergebnisse verwendet. Mithilfe der Logistikfunktion wird der Wahrscheinlichkeitswert geschätzt, um die Beziehung zwischen einer kategorialen abhängigen Variablen und einer oder mehreren unabhängigen Variablen zu messen, die zur kumulativen Logistikverteilung gehören.

Im Allgemeinen umfassen Anwendungen logistischer Regressionsmodelle in realen Szenarien:
Kreditbewertung
Vorhersage der Erfolgswahrscheinlichkeit von Geschäftsaktivitäten
Prognostizieren Sie den Umsatz eines bestimmten Produkts
Prognostizieren Sie die Wahrscheinlichkeit eines Erdbebens an einem bestimmten Tag
5. Support-Vektor-Maschine:
Support Vector Machine ist ein binärer Klassifizierungsalgorithmus. Bei zwei Arten von Punkten im N-dimensionalen Raum generiert die Support-Vektor-Maschine eine (N-1)-dimensionale Hyperebene, um diese Punkte in zwei Kategorien zu klassifizieren. Beispielsweise gibt es auf Papier zwei Arten von linear trennbaren Punkten. Die Support-Vektor-Maschine findet eine gerade Linie, die diese beiden Punkttypen trennt und möglichst weit von jedem Punkt entfernt ist.
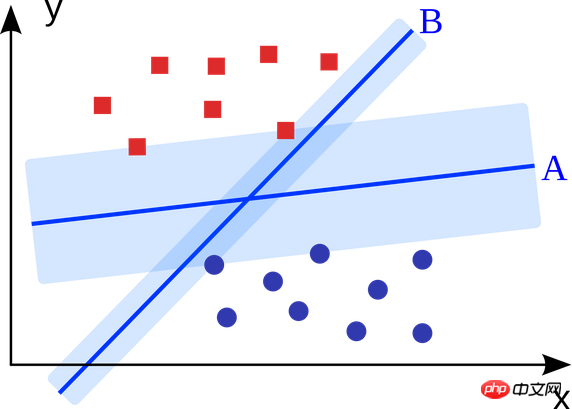
Groß angelegte Probleme, die mithilfe von Support-Vektor-Maschinen (verbessert auf der Grundlage spezifischer Anwendungsszenarien) gelöst werden, umfassen Display-Werbung, Erkennung von Gelenkteilen des menschlichen Körpers, bildbasierte Geschlechtsüberprüfung, große- Skala Bildklassifizierung usw.
6. Integrationsmethode:
Die Integrationsmethode besteht darin, zunächst eine Reihe von Klassifikatoren zu erstellen und dann die gewichtete Abstimmung zu verwenden Jeder Klassifikator soll neue Datenalgorithmen vorhersagen. Die ursprüngliche Ensemble-Methode war die Bayes'sche Mittelung, aber neuere Algorithmen umfassen fehlerkorrigierte Ausgabekodierungs- und Boosting-Algorithmen.

Was ist also das Prinzip des integrierten Modells und warum schneidet es besser ab als das unabhängige Modell?
Sie eliminieren den Effekt der Voreingenommenheit: Wenn Sie beispielsweise den Fragebogen der Demokratischen Partei mit dem Fragebogen der Republikanischen Partei mischen, erhalten Sie unscheinbare und neutrale Informationen.
Sie können die Varianz von Vorhersagen verringern: Die Vorhersageergebnisse der Aggregation mehrerer Modelle sind stabiler als die Vorhersageergebnisse eines einzelnen Modells. In der Finanzwelt nennt man das Diversifikation – eine Mischung aus mehreren Aktien bewegt sich immer viel weniger als eine einzelne Aktie. Dies erklärt auch, warum das Modell mit zunehmenden Trainingsdaten besser wird.
Sie sind nicht anfällig für Überanpassung: Wenn ein einzelnes Modell keine Überanpassung durchführt, dann gibt es keinen Grund für eine Überanpassung, wenn man einfach die Vorhersageergebnisse jedes Modells (Mittelwert, gewichteter Durchschnitt, logistische Regression) kombiniert.
Unüberwachtes Lernen
7. Clustering-Algorithmus:
Die Aufgabe des Clustering-Algorithmus besteht darin, eine Gruppe von Objekten in mehrere Gruppen zu gruppieren Objekte derselben Gruppe (Cluster) sind ähnlicher als Objekte in anderen Gruppen.
Jeder Clustering-Algorithmus ist anders, hier sind einige:
Center-basierter Clustering-Algorithmus
Verbindungsbasierter Clustering-Algorithmus
Dichtebasierter Clustering-Algorithmus
Probabilistischer Algorithmus
Dimensionalitätsreduktionsalgorithmus
Neuronales Netzwerk/Deep Learning
8 Analyse:
Die Hauptkomponentenanalyse ist eine statistische Methode, die einen Satz von Variablen, die korrelieren können, in einen Satz linear unkorrelierter Variablen umwandelt. Der umgewandelte Satz von Variablen wird als Hauptkomponente bezeichnet .

Einige praktische Anwendungen der Hauptkomponentenanalyse umfassen Datenkomprimierung, vereinfachte Datendarstellung, Datenvisualisierung usw. Es ist erwähnenswert, dass Domänenkenntnisse erforderlich sind, um zu beurteilen, ob die Verwendung des Hauptkomponentenanalysealgorithmus geeignet ist. Wenn die Daten zu verrauscht sind (dh die Varianz jeder Komponente groß ist), ist die Verwendung des Hauptkomponentenanalysealgorithmus nicht geeignet.
9. Singulärwertzerlegung:
Singulärwertzerlegung ist eine wichtige Matrixzerlegung in der linearen Algebra und eine Verallgemeinerung der normalen Matrix-Unitdiagonalisierung in der Matrixanalyse. Für eine gegebene m*n-Matrix M kann sie in M=UΣV zerlegt werden, wobei U und V einheitliche Matrizen der Ordnung m×m sind und Σ eine positive semidefinite Diagonalmatrix der Ordnung m×n ist.

Die Hauptkomponentenanalyse ist eigentlich ein einfacher Singulärwertzerlegungsalgorithmus. Im Bereich Computer Vision verwendete der erste Gesichtserkennungsalgorithmus die Hauptkomponentenanalyse und die Singularwertzerlegung, um das Gesicht nach Dimensionsreduzierung als lineare Kombination einer Reihe von „Eigengesichtern“ darzustellen, und verwendete dann einfache Methoden, um das Gesicht des Kandidaten abzugleichen. Obwohl moderne Methoden ausgefeilter sind, ähneln sich viele Techniken.
10. Unabhängige Komponentenanalyse:
Die unabhängige Komponentenanalyse ist eine Methode, die statistische Prinzipien verwendet, um Berechnungen durchzuführen, um die verborgenen Faktoren hinter Zufallsvariablen, Messungen oder Signalen aufzudecken . . Der unabhängige Komponentenanalysealgorithmus definiert ein generatives Modell für beobachtete multivariate Daten, normalerweise große Probenmengen. In diesem Modell wird davon ausgegangen, dass die Datenvariablen lineare Mischungen einiger unbekannter latenter Variablen sind, und das Mischungssystem ist ebenfalls unbekannt. Es wird davon ausgegangen, dass die latenten Variablen nicht-gaußsch und unabhängig sind; sie werden als unabhängige Komponenten der beobachteten Daten bezeichnet.
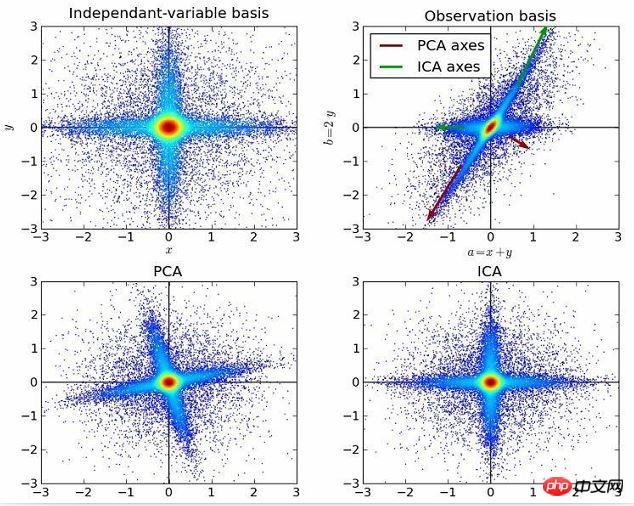
Die unabhängige Komponentenanalyse ähnelt der Hauptkomponentenanalyse, ist jedoch eine leistungsfähigere Technik. Es kann immer noch die zugrunde liegenden Faktoren der Datenquelle finden, wenn diese klassischen Methoden fehlschlagen. Zu den Anwendungen gehören digitale Bilder, Dokumentendatenbanken, Wirtschaftsindikatoren und psychometrische Messungen.
Nun nutzen Sie bitte die Algorithmen, die Sie verstehen, um Anwendungen für maschinelles Lernen zu erstellen und die Lebensqualität von Menschen auf der ganzen Welt zu verbessern.
Verwandte Empfehlungen:
Automatische Kundendienstfunktion des WeChat Mini-Programmroboters
PHP-Entwicklung des WeChat-Zahlungs- und Chat-Roboters
Beispiel-Tutorial der PHP-Bibliothek für maschinelles Lernen php-ml

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1392
1392
 52
52

 Erfahren Sie, wie Sie pip vollständig deinstallieren und Python effizienter nutzen
Jan 16, 2024 am 09:01 AM
Erfahren Sie, wie Sie pip vollständig deinstallieren und Python effizienter nutzen
Jan 16, 2024 am 09:01 AM
Keine Notwendigkeit mehr für Pip? Kommen Sie und lernen Sie, wie Sie Pip effektiv deinstallieren! Einführung: pip ist eines der Paketverwaltungstools von Python, mit dem Python-Pakete einfach installiert, aktualisiert und deinstalliert werden können. Manchmal müssen wir jedoch pip möglicherweise deinstallieren, vielleicht weil wir ein anderes Paketverwaltungstool verwenden möchten oder weil wir die Python-Umgebung vollständig löschen müssen. In diesem Artikel wird erläutert, wie Sie Pip effizient deinstallieren, und es werden spezifische Codebeispiele bereitgestellt. 1. Methoden zum Deinstallieren von Pip Im Folgenden werden zwei gängige Methoden zum Deinstallieren von Pip vorgestellt.
 Ein tiefer Einblick in die Farbkarte von Matplotlib
Jan 09, 2024 pm 03:51 PM
Ein tiefer Einblick in die Farbkarte von Matplotlib
Jan 09, 2024 pm 03:51 PM
Um mehr über die Matplotlib-Farbtabelle zu erfahren, benötigen Sie spezifische Codebeispiele. 1. Einführung Matplotlib ist eine leistungsstarke Python-Zeichenbibliothek. Sie bietet einen umfangreichen Satz an Zeichenfunktionen und -werkzeugen, mit denen verschiedene Arten von Diagrammen erstellt werden können. Die Farbkarte (Colormap) ist ein wichtiges Konzept in Matplotlib, das das Farbschema des Diagramms bestimmt. Eine eingehende Untersuchung der Matplotlib-Farbtabelle wird uns helfen, die Zeichenfunktionen von Matplotlib besser zu beherrschen und das Zeichnen komfortabler zu gestalten.
 Die Attraktivität der C-Sprache enthüllen: Das Potenzial von Programmierern aufdecken
Feb 24, 2024 pm 11:21 PM
Die Attraktivität der C-Sprache enthüllen: Das Potenzial von Programmierern aufdecken
Feb 24, 2024 pm 11:21 PM
Der Reiz des Erlernens der C-Sprache: Das Potenzial von Programmierern freisetzen Mit der kontinuierlichen Weiterentwicklung der Technologie ist die Computerprogrammierung zu einem Bereich geworden, der viel Aufmerksamkeit erregt hat. Unter vielen Programmiersprachen war die Sprache C schon immer bei Programmierern beliebt. Seine Einfachheit, Effizienz und breite Anwendung machen das Erlernen der C-Sprache für viele Menschen zum ersten Schritt, um in den Bereich der Programmierung einzusteigen. In diesem Artikel geht es um den Reiz des Erlernens der C-Sprache und darum, wie man das Potenzial von Programmierern durch das Erlernen der C-Sprache freisetzt. Der Reiz des Erlernens der C-Sprache liegt zunächst einmal in ihrer Einfachheit. Im Vergleich zu anderen Programmiersprachen C-Sprache
 Erste Schritte mit Pygame: Umfassendes Installations- und Konfigurations-Tutorial
Feb 19, 2024 pm 10:10 PM
Erste Schritte mit Pygame: Umfassendes Installations- und Konfigurations-Tutorial
Feb 19, 2024 pm 10:10 PM
Lernen Sie Pygame von Grund auf: Komplettes Installations- und Konfigurations-Tutorial, spezifische Codebeispiele erforderlich. Einführung: Pygame ist eine Open-Source-Spieleentwicklungsbibliothek, die mit der Programmiersprache Python entwickelt wurde. Sie bietet eine Fülle von Funktionen und Tools, mit denen Entwickler problemlos eine Vielzahl von Typen erstellen können des Spiels. Dieser Artikel hilft Ihnen, Pygame von Grund auf zu erlernen und bietet ein vollständiges Installations- und Konfigurations-Tutorial sowie spezifische Codebeispiele, um Ihnen einen schnellen Einstieg zu erleichtern. Teil eins: Python und Pygame installieren Stellen Sie zunächst sicher, dass Sie dies getan haben
 Lassen Sie uns gemeinsam lernen, wie Sie die Stammzahl in Word eingeben
Mar 19, 2024 pm 08:52 PM
Lassen Sie uns gemeinsam lernen, wie Sie die Stammzahl in Word eingeben
Mar 19, 2024 pm 08:52 PM
Beim Bearbeiten von Textinhalten in Word müssen Sie manchmal Formelsymbole eingeben. Manche Leute wissen nicht, wie man die Stammzahl in Word eingibt, also habe ich den Redakteur gebeten, mit meinen Freunden ein Tutorial zur Eingabe der Stammzahl in Word zu teilen. Ich hoffe, es hilft meinen Freunden. Öffnen Sie zunächst die Word-Software auf Ihrem Computer, öffnen Sie dann die Datei, die Sie bearbeiten möchten, und bewegen Sie den Cursor an die Stelle, an der Sie das Stammzeichen einfügen müssen, siehe Beispielbild unten. 2. Wählen Sie [Einfügen] und dann im Symbol [Formel]. Wie im roten Kreis im Bild unten gezeigt: 3. Wählen Sie dann unten [Neue Formel einfügen]. Wie im roten Kreis im Bild unten gezeigt: 4. Wählen Sie [Radikal] und dann das entsprechende Radikal. Wie im roten Kreis im Bild unten gezeigt:
 Welche Konfiguration ist erforderlich, um CAD reibungslos auszuführen?
Jan 01, 2024 pm 07:17 PM
Welche Konfiguration ist erforderlich, um CAD reibungslos auszuführen?
Jan 01, 2024 pm 07:17 PM
Welche Konfigurationen sind erforderlich, um CAD reibungslos nutzen zu können? Um CAD-Software reibungslos nutzen zu können, müssen Sie die folgenden Konfigurationsvoraussetzungen erfüllen: Prozessoranforderungen: Um „Word Play Flowers“ reibungslos laufen zu lassen, müssen Sie mit mindestens einem Intel Corei5 oder ausgestattet sein AMD Ryzen5 oder höher Prozessor. Wenn Sie sich für einen leistungsstärkeren Prozessor entscheiden, können Sie natürlich schnellere Verarbeitungsgeschwindigkeiten und eine bessere Leistung erzielen. Der Speicher ist eine sehr wichtige Komponente im Computer. Er hat einen direkten Einfluss auf die Leistung und das Benutzererlebnis des Computers. Im Allgemeinen empfehlen wir mindestens 8 GB Arbeitsspeicher, der den Anforderungen der meisten täglichen Nutzung gerecht wird. Für eine bessere Leistung und ein reibungsloseres Nutzungserlebnis wird jedoch empfohlen, eine Speicherkonfiguration von 16 GB oder mehr zu wählen. Dadurch wird sichergestellt, dass die
 Lernen Sie die Hauptfunktion der Go-Sprache von Grund auf kennen
Mar 27, 2024 pm 05:03 PM
Lernen Sie die Hauptfunktion der Go-Sprache von Grund auf kennen
Mar 27, 2024 pm 05:03 PM
Titel: Lernen Sie die Hauptfunktionen der Go-Sprache von Grund auf. Als einfache und effiziente Programmiersprache wird die Go-Sprache von Entwicklern bevorzugt. In der Go-Sprache ist die Hauptfunktion eine Einstiegsfunktion, und jedes Go-Programm muss die Hauptfunktion als Einstiegspunkt des Programms enthalten. In diesem Artikel wird erläutert, wie Sie die Hauptfunktion der Go-Sprache von Grund auf erlernen, und es werden spezifische Codebeispiele bereitgestellt. 1. Zuerst müssen wir die Go-Sprachentwicklungsumgebung installieren. Sie können zur offiziellen Website (https://golang.org) gehen
 Erlernen Sie schnell die Rohrinstallation und erlernen Sie die Fähigkeiten von Grund auf
Jan 16, 2024 am 10:30 AM
Erlernen Sie schnell die Rohrinstallation und erlernen Sie die Fähigkeiten von Grund auf
Jan 16, 2024 am 10:30 AM
Erlernen Sie die Pip-Installation von Grund auf und beherrschen Sie schnell spezifische Codebeispiele. Übersicht: Pip ist ein Python-Paketverwaltungstool, mit dem Python-Pakete einfach installiert, aktualisiert und verwaltet werden können. Für Python-Entwickler ist es sehr wichtig, die Fähigkeiten im Umgang mit Pip zu beherrschen. In diesem Artikel wird die Installationsmethode von Pip von Grund auf vorgestellt und einige praktische Tipps und spezifische Codebeispiele gegeben, damit der Leser die Verwendung von Pip schnell erlernen kann. 1. Pip installieren Bevor Sie Pip verwenden können, müssen Sie zunächst Pip installieren. Pip