

PHP generiert textbasierten Morsecode

Kürzlich besteht die Notwendigkeit, Morsecode-Audiodateien basierend auf Eingabetext zu generieren. Nach ein paar erfolglosen Suchen beschloss ich, meinen eigenen Generator zu schreiben. In diesem Artikel werden hauptsächlich relevante Informationen zur Implementierung eines textbasierten Morsecode-Generators in PHP vorgestellt. Freunde in Not können darauf zurückgreifen. Ich hoffe, es hilft allen.
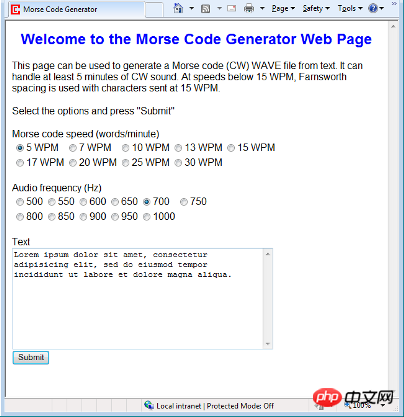
Da ich über das Internet auf meine Morsecode-Audiodateien zugreifen möchte, habe ich mich entschieden, PHP als meine Hauptprogrammiersprache zu verwenden. Der Screenshot oben zeigt eine Webseite, die mit der Generierung von Morsecode beginnt. Die heruntergeladene ZIP-Datei enthält eine Webseite zum Einreichen von Texten und eine PHP-Quelldatei zum Generieren und Anzeigen von Audiodateien. Wenn Sie PHP-Code testen möchten, müssen Sie die Webseite und die zugehörigen PHP-Dateien auf einen PHP-fähigen Server kopieren.
Für viele Menschen ist Morsecode nur eine Folge von „Punkten“ und „Strichen“ oder eine Reihe von Pieptönen, wie sie in einigen alten Filmen gezeigt werden. Offensichtlich reicht dieses Wissen nicht aus, wenn Sie Computercode zum Generieren von Morsecode verwenden möchten. In diesem Artikel werden die Elemente zum Generieren von Morsecode vorgestellt, wie Audiodateien im WAVE-Format generiert werden und wie PHP zum Konvertieren von Morsecode in Audiodateien verwendet wird.
Morsecode
Morsecode ist eine Methode zur Textkodierung. Sein Vorteil besteht darin, dass es leicht zu kodieren und vom menschlichen Ohr leicht zu dekodieren ist. Im Wesentlichen wird Audio (oder Radiofrequenz) ein- und ausgeschaltet, um kurze oder lange Audioimpulse zu erzeugen, die in der Radioterminologie im Allgemeinen als Punkte und Striche oder „Punkte“ und „Striche“ bezeichnet werden. In modernen digitalen Kommunikationsbegriffen ist Morsecode eine Form der Amplitudenumtastung (ASK).
Im Morsecode werden Zeichen (Buchstaben, Zahlen, Satzzeichen und Sonderzeichen) in eine Folge von „Häkchen“ und „Dahs“ kodiert. Um also Text in Morsecode umzuwandeln, müssen wir zunächst bestimmen, wie „tick“ und „dah“ dargestellt werden. Eine offensichtliche Wahl ist die Verwendung von 0 für „tick“ und 1 für „dah“ oder umgekehrt. Leider verwendet der Morsecode ein Codierungsschema mit variabler Länge. Daher müssen wir auch eine Sequenz variabler Länge verwenden oder eine Methode anwenden, um die Daten in ein Format mit fester Bitgröße zu packen, das im Computerspeicher üblich ist. Darüber hinaus ist es wichtig zu beachten, dass der Morsecode nicht zwischen Groß- und Kleinbuchstaben unterscheidet und einige Sonderzeichen nicht kodieren kann. In unserer Implementierung werden undefinierte Zeichen und Symbole ignoriert.
In diesem Projekt spielt die Speichernutzung keine besondere Rolle. Daher schlagen wir ein einfaches Codierungsschema vor, das heißt, verwenden Sie „0“, um jedes „Tick“ darzustellen, und „1“, um jedes „Dah“ darzustellen, und fügen Sie sie in ein string-assoziatives Array ein. Der PHP-Code, der die Morsecode-Codierungstabelle definiert, lautet wie folgt:
$CWCODE = array ('A'=>'01','B'=>'1000','C'=>'1010','D'=>'100','E'=>'0', 'F'=>'0010','G'=>'110','H'=>'0000','I'=>'00','J'=>'0111', 'K'=>'101','L'=>'0100','M'=>'11','N'=>'10', 'O'=>'111', 'P'=>'0110','Q'=>'1101','R'=>'010','S'=>'000','T'=>'1', 'U'=>'001','V'=>'0001','W'=>'011','X'=>'1001','Y'=>'1011', 'Z'=>'1100', '0'=>'11111','1'=>'01111','2'=>'00111', '3'=>'00011','4'=>'00001','5'=>'00000','6'=>'10000', '7'=>'11000','8'=>'11100','9'=>'11110','.'=>'010101', ','=>'110011','/'=>'10010','-'=>'10001','~'=>'01010', '?'=>'001100','@'=>'00101');
Es sollte beachtet werden, dass dies für Sie besonders wichtig ist Im Hinblick auf die Speichernutzung kann der obige Code als Bits interpretiert werden. Durch Hinzufügen eines Startbits zu jedem Code kann ein Bitmuster gebildet und jedes Zeichen in einem Byte gespeichert werden. Gleichzeitig werden beim Parsen der endgültigen Codierung die Bits links vom Startbit gelöscht, um eine echte Codierung mit variabler Länge zu erhalten.
Obwohl es vielen Menschen nicht bewusst ist, ist das „Zeitintervall“ tatsächlich der Hauptfaktor, der den Morsecode definiert. Daher ist es wichtig, dies zu verstehen, um Morsecode zu generieren. Daher müssen wir zunächst das Zeitintervall des internen Codes des Morsecodes (dh „tick“ und „dah“) definieren. Der Einfachheit halber definieren wir die Länge eines „Tick“-Tons als Zeiteinheit dt, und das Intervall zwischen „Tick“ und „dah“ ist ebenfalls eine Zeiteinheit dt. Definieren Sie die Länge eines „dah“ als 3 dt, das Zeichen (Der Abstand zwischen Buchstaben) beträgt ebenfalls 3 dt; der Abstand zwischen Definitionswörtern (Wörtern) beträgt 7 dt. Zusammenfassend sieht unsere Zeitintervalltabelle also so aus:

Im Morsecode wird die „Wiedergabegeschwindigkeit“ eines codierten Tons normalerweise in Wörtern/Minute (WPM) ausgedrückt ) zu vertreten. Da englische Wörter unterschiedlich lang sind und Zeichen unterschiedlich viele Klicks und Klicks haben, ist die Konvertierung von WPM in (Audio-)Digital-Samples nicht so einfach, wie es scheint. In einem von internationalen Organisationen übernommenen Schema werden 5 Zeichen als durchschnittliche Wortlänge verwendet, während eine Zahl oder ein Satzzeichen als 2 Zeichen behandelt wird. Auf diese Weise beträgt ein durchschnittliches Wort 50 Zeiteinheiten dt. Wenn Sie also WPM angeben, beträgt unsere Gesamtwiedergabezeit 50 * WPM-Zeiteinheit/Minute und die Länge jedes „Ticks“ (d. h. eine Zeiteinheit dt) entspricht 1,2/WPM-Sekunden. Auf diese Weise kann anhand der Zeitdauer eines „Ticks“ die Zeitdauer anderer Elemente leicht berechnet werden.
你可能已经注意到,在上面显示的网页中,对于低于15WPM的选项,我们使用了“Farnsworth spacing”。那么这个“Farnsworth spacing”又是个什么鬼?
当报务员学习用耳朵来解码莫斯代码的时候,他就会意识到,当播放速度变化的时候,字符出现的节奏也会跟着变化。当播放速度低于10WPM的时候,他能够从容的识别“嘀”和“嗒”,并且知道发送的哪个字符。但是当播放速度超过10WPM的时候,报务员的识别就会出错,他识别出来的字符会多于实际的“嘀”和“嗒”。当一个学习的时候习惯低速莫斯代码的人,在处理高速播放代码的时候,就会出现问题。因为节奏变了,他潜意识的识别就会出错。
为了解决这个问题,“Farnsworth spacing”就被发明出来了。本质上来讲,字母和符号的播放速度依然采取高于15WPM的速度,同时,通过在字符之间插入更多的空格,来使整体的播放速度降低。这样,报务员就能够以一个合理的速度和节奏来识别每个字符,一旦所有的字符都学习完毕,就可以增加速度,而接收员只需要加快识别字符的速度就可以了。本质上来说,“Farnsworth spacing”这个技巧解决了节奏变化这个问题,使接收员能够快速学习。
所以,在整个系统中,对于更低的播放速度,都统一成15WPM。相对应的,一个“嘀”的长度是0.08秒,但是字符之间和单词之间的间隔就不再是3个dit或者7个dit,而是进行的调整以适应整体速度。
生成声音
在PHP代码中,一个字符(即前面数组的索引)代表一组由“嘀”、“嗒”和空白间隔组成的莫斯声音。我们用数字采样来组成音频序列,并且将其写入到文件中,同时加上适当的头信息来将其定义成WAVE格式。
生成声音的代码其实相当简单,你可以在项目中PHP文件中找到它们。我发现定义一个“数字振荡器”相当方便。每调用一次osc(),它就会返回一个从正玄波产生的定时采样。运用声音采样和声频规范,生成WAVE格式的音频已经足够了。在产生的正玄波中的-1到+1之间是被移动和调整过的,这样声音的字节数据可以用0到255来表示,同时128表示零振幅。
同时,在生成声音方面我们还要考虑另外一个问题。一般来讲,我们是通过正玄波的开关来生成莫斯代码。但是你直接这样来做的话,就会发现你生成的信号会占用非常大的带宽。所以,通常无线电设备会对其加以修正,以减少带宽占用。
在我们的项目中,也会做这样的修正,只不过是用数字的方式。既然我们已经知道了一个最小声音样本“嘀”的时间长度,那么,可以证明,最小带宽的声幅发生在长度等于“嘀”的正玄波半周期。事实上,我们使用低通滤波器(low pass filter)来过滤音频信号也能达到同样的效果。不过,既然我们已经知道所有的信号字符,我们直接简单的过滤一下每一个字符信号就可以了。
生成“嘀”、“嗒”和空白信号的PHP代码就像下面这样:
while ($dt < $DitTime) {
$x = Osc();
if ($dt < (0.5*$DitTime)) {
// Generate the rising part of a dit and dah up to half the dit-time
$x = $x*sin((M_PI/2.0)*$dt/(0.5*$DitTime));
$ditstr .= chr(floor(120*$x+128));
$dahstr .= chr(floor(120*$x+128));
}
else if ($dt > (0.5*$DitTime)) {
// For a dah, the second part of the dit-time is constant amplitude
$dahstr .= chr(floor(120*$x+128));
// For a dit, the second half decays with a sine shape
$x = $x*sin((M_PI/2.0)*($DitTime-$dt)/(0.5*$DitTime));
$ditstr .= chr(floor(120*$x+128));
}
else {
$ditstr .= chr(floor(120*$x+128));
$dahstr .= chr(floor(120*$x+128));
}
// a space has an amplitude of 0 shifted to 128
$spcstr .= chr(128);
$dt += $sampleDT;
}
// At this point the dit sound has been generated
// For another dit-time unit the dah sound has a constant amplitude
$dt = 0;
while ($dt < $DitTime) {
$x = Osc();
$dahstr .= chr(floor(120*$x+128));
$dt += $sampleDT;
}
// Finally during the 3rd dit-time, the dah sound must be completed
// and decay during the final half dit-time
$dt = 0;
while ($dt < $DitTime) {
$x = Osc();
if ($dt > (0.5*$DitTime)) {
$x = $x*sin((M_PI/2.0)*($DitTime-$dt)/(0.5*$DitTime));
$dahstr .= chr(floor(120*$x+128));
}
else {
$dahstr .= chr(floor(120*$x+128));
}
$dt += $sampleDT;
}WAVE格式的文件
WAVE是一种通用的音频格式。从最简单的形式来看,WAVE文件通过在头部包含一个整数序列来表示指定采样率的音频振幅。关于WAVE文件的详细信息请查看这里Audio File Format Specifications website。对于产生莫斯代码,我们并不需要用到WAVE格式的所有参数选项,仅仅需要一个8位的单声道就可以了,所以,so easy。需要注意的是,多字节数据需要采用低位优先(little-endian)的字节顺序。WAVE文件使用一种由叫做“块(chunks)”的记录组成的RIFF格式。
WAVE文件由一个ASCII标识符RIFF开始,紧跟着一个4字节的“块”,然后是一个包含ASCII字符WAVE的头信息,最后是定义格式的数据和声音数据。
在我们的程序中,第一个“块”包含了一个格式说明符,它由ASCII字符fmt和一个4倍字节的“块”。在这里,由于我使用的是普通脉冲编码调制(plain vanilla PCM)格式,所以每个“块”都是16字节。然后,我们还需要这些数据:声道数、声音采样/秒、平均字节/秒、一个区块(block)对齐指示器、位(bit)/声音采样。另外,由于我们不需要高质量立体声,我们只采用单声道,我们使用 11050采样/秒(标准的CD质量音频的采样率是 44200采样/秒)的采样率来生成声音,并且用8位(bit)保存。
最后,真实的音频数据储存在接下来的“块”中。其中包含ASCII字符data,一个4字节的“块”,最后是由字节序列(因为我们采用的是8位(bit)/采样)组成的真实音频数据。
在程序中,由8位音频振幅序列组成的声音保存在变量$soundstr中。一旦音频数据生成完毕,就可以计算出所有的“块”大小,然后就可以把它们合并在一起写入磁盘文件中。下面的代码展示了如何生成头信息和音频“块”。需要注意的是,$riffstr表示RIFF头,$fmtstr表示“块”格式,$soundstr表示音频数据“块”。
$riffstr = 'RIFF'.$NSizeStr.'WAVE';
$x = SAMPLERATE;
$SampRateStr = '';
for ($i=0; $i<4; $i++) {
$SampRateStr .= chr($x % 256);
$x = floor($x/256);
}
$fmtstr = 'fmt '.chr(16).chr(0).chr(0).chr(0).chr(1).chr(0).chr(1).chr(0)
.$SampRateStr.$SampRateStr.chr(1).chr(0).chr(8).chr(0);
$x = $n;
$NSampStr = '';
for ($i=0; $i<4; $i++) {
$NSampStr .= chr($x % 256);
$x = floor($x/256);
}
$soundstr = 'data'.$NSampStr.$soundstr;总结和评论
我们的文本莫斯代码生成器目前看起来还不错。当然,我们还可以对它做很多的修改和完善,比如使用其他字符集、直接从文件中读取文本、生成压缩音频等等。因为我们这个项目的目的是使其能够在网络上方便的使用,所以我们这个简单的方案,已经达到我们的目的了。
相关推荐:
PHP实现迪菲赫尔曼密钥交换(Diffie–Hellman)算法
Das obige ist der detaillierte Inhalt vonPHP generiert textbasierten Morsecode. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1205
24
52
1205
24

 PHP 8.4 Installations- und Upgrade-Anleitung für Ubuntu und Debian
Dec 24, 2024 pm 04:42 PM
PHP 8.4 Installations- und Upgrade-Anleitung für Ubuntu und Debian
Dec 24, 2024 pm 04:42 PM
PHP 8.4 bringt mehrere neue Funktionen, Sicherheitsverbesserungen und Leistungsverbesserungen mit einer beträchtlichen Menge an veralteten und entfernten Funktionen. In dieser Anleitung wird erklärt, wie Sie PHP 8.4 installieren oder auf PHP 8.4 auf Ubuntu, Debian oder deren Derivaten aktualisieren. Obwohl es möglich ist, PHP aus dem Quellcode zu kompilieren, ist die Installation aus einem APT-Repository wie unten erläutert oft schneller und sicherer, da diese Repositorys in Zukunft die neuesten Fehlerbehebungen und Sicherheitsupdates bereitstellen.
 7 PHP-Funktionen, die ich leider vorher nicht kannte
Nov 13, 2024 am 09:42 AM
7 PHP-Funktionen, die ich leider vorher nicht kannte
Nov 13, 2024 am 09:42 AM
Wenn Sie ein erfahrener PHP-Entwickler sind, haben Sie möglicherweise das Gefühl, dass Sie dort waren und dies bereits getan haben. Sie haben eine beträchtliche Anzahl von Anwendungen entwickelt, Millionen von Codezeilen debuggt und eine Reihe von Skripten optimiert, um op zu erreichen
 So richten Sie Visual Studio-Code (VS-Code) für die PHP-Entwicklung ein
Dec 20, 2024 am 11:31 AM
So richten Sie Visual Studio-Code (VS-Code) für die PHP-Entwicklung ein
Dec 20, 2024 am 11:31 AM
Visual Studio Code, auch bekannt als VS Code, ist ein kostenloser Quellcode-Editor – oder eine integrierte Entwicklungsumgebung (IDE) –, die für alle gängigen Betriebssysteme verfügbar ist. Mit einer großen Sammlung von Erweiterungen für viele Programmiersprachen kann VS Code c
 Erklären Sie JSON Web Tokens (JWT) und ihren Anwendungsfall in PHP -APIs.
Apr 05, 2025 am 12:04 AM
Erklären Sie JSON Web Tokens (JWT) und ihren Anwendungsfall in PHP -APIs.
Apr 05, 2025 am 12:04 AM
JWT ist ein offener Standard, der auf JSON basiert und zur sicheren Übertragung von Informationen zwischen Parteien verwendet wird, hauptsächlich für die Identitätsauthentifizierung und den Informationsaustausch. 1. JWT besteht aus drei Teilen: Header, Nutzlast und Signatur. 2. Das Arbeitsprinzip von JWT enthält drei Schritte: Generierung von JWT, Überprüfung von JWT und Parsingnayload. 3. Bei Verwendung von JWT zur Authentifizierung in PHP kann JWT generiert und überprüft werden, und die Funktionen und Berechtigungsinformationen der Benutzer können in die erweiterte Verwendung aufgenommen werden. 4. Häufige Fehler sind Signaturüberprüfungsfehler, Token -Ablauf und übergroße Nutzlast. Zu Debugging -Fähigkeiten gehört die Verwendung von Debugging -Tools und Protokollierung. 5. Leistungsoptimierung und Best Practices umfassen die Verwendung geeigneter Signaturalgorithmen, das Einstellen von Gültigkeitsperioden angemessen.
 Wie analysiert und verarbeitet man HTML/XML in PHP?
Feb 07, 2025 am 11:57 AM
Wie analysiert und verarbeitet man HTML/XML in PHP?
Feb 07, 2025 am 11:57 AM
Dieses Tutorial zeigt, wie XML -Dokumente mit PHP effizient verarbeitet werden. XML (Extensible Markup-Sprache) ist eine vielseitige textbasierte Markup-Sprache, die sowohl für die Lesbarkeit des Menschen als auch für die Analyse von Maschinen entwickelt wurde. Es wird üblicherweise für die Datenspeicherung ein verwendet und wird häufig verwendet
 PHP -Programm zum Zählen von Vokalen in einer Zeichenfolge
Feb 07, 2025 pm 12:12 PM
PHP -Programm zum Zählen von Vokalen in einer Zeichenfolge
Feb 07, 2025 pm 12:12 PM
Eine Zeichenfolge ist eine Folge von Zeichen, einschließlich Buchstaben, Zahlen und Symbolen. In diesem Tutorial wird lernen, wie Sie die Anzahl der Vokale in einer bestimmten Zeichenfolge in PHP unter Verwendung verschiedener Methoden berechnen. Die Vokale auf Englisch sind a, e, i, o, u und sie können Großbuchstaben oder Kleinbuchstaben sein. Was ist ein Vokal? Vokale sind alphabetische Zeichen, die eine spezifische Aussprache darstellen. Es gibt fünf Vokale in Englisch, einschließlich Großbuchstaben und Kleinbuchstaben: a, e, ich, o, u Beispiel 1 Eingabe: String = "TutorialPoint" Ausgabe: 6 erklären Die Vokale in der String "TutorialPoint" sind u, o, i, a, o, ich. Insgesamt gibt es 6 Yuan
 Erklären Sie die späte statische Bindung in PHP (statisch: :).
Apr 03, 2025 am 12:04 AM
Erklären Sie die späte statische Bindung in PHP (statisch: :).
Apr 03, 2025 am 12:04 AM
Statische Bindung (statisch: :) implementiert die späte statische Bindung (LSB) in PHP, sodass das Aufrufen von Klassen in statischen Kontexten anstatt Klassen zu definieren. 1) Der Analyseprozess wird zur Laufzeit durchgeführt.
 Was sind PHP Magic -Methoden (__construct, __Destruct, __call, __get, __set usw.) und geben Sie Anwendungsfälle an?
Apr 03, 2025 am 12:03 AM
Was sind PHP Magic -Methoden (__construct, __Destruct, __call, __get, __set usw.) und geben Sie Anwendungsfälle an?
Apr 03, 2025 am 12:03 AM
Was sind die magischen Methoden von PHP? Zu den magischen Methoden von PHP gehören: 1. \ _ \ _ Konstrukt, verwendet, um Objekte zu initialisieren; 2. \ _ \ _ Destruct, verwendet zur Reinigung von Ressourcen; 3. \ _ \ _ Call, behandeln Sie nicht existierende Methodenaufrufe; 4. \ _ \ _ GET, Implementieren Sie den dynamischen Attributzugriff; 5. \ _ \ _ Setzen Sie dynamische Attributeinstellungen. Diese Methoden werden in bestimmten Situationen automatisch aufgerufen, wodurch die Code -Flexibilität und -Effizienz verbessert werden.
