
 Backend-Entwicklung
Python-Tutorial
Python-Crawling-Methode für den Datenaustausch auf Anjuke-Gebrauchtwohnungswebsites
Backend-Entwicklung
Python-Tutorial
Python-Crawling-Methode für den Datenaustausch auf Anjuke-Gebrauchtwohnungswebsites
Python-Crawling-Methode für den Datenaustausch auf Anjuke-Gebrauchtwohnungswebsites

Dieser Artikel enthält hauptsächlich einen Python-Artikel zum Crawlen von Anjuke-Gebrauchtwohnungs-Website-Daten (Erklärung mit Beispielen). Der Herausgeber findet es ziemlich gut, deshalb teile ich es jetzt mit Ihnen und gebe es als Referenz. Folgen wir dem Herausgeber und schauen wir uns das an. Ich hoffe, es kann allen helfen.
Beginnen wir nun mit dem Schreiben des offiziellen Crawlers. Zuerst müssen wir die Struktur der zu crawlenden Website analysieren: Schauen wir uns als Student in Henan die Informationen zu Gebrauchtwohnungen in Zhengzhou an! 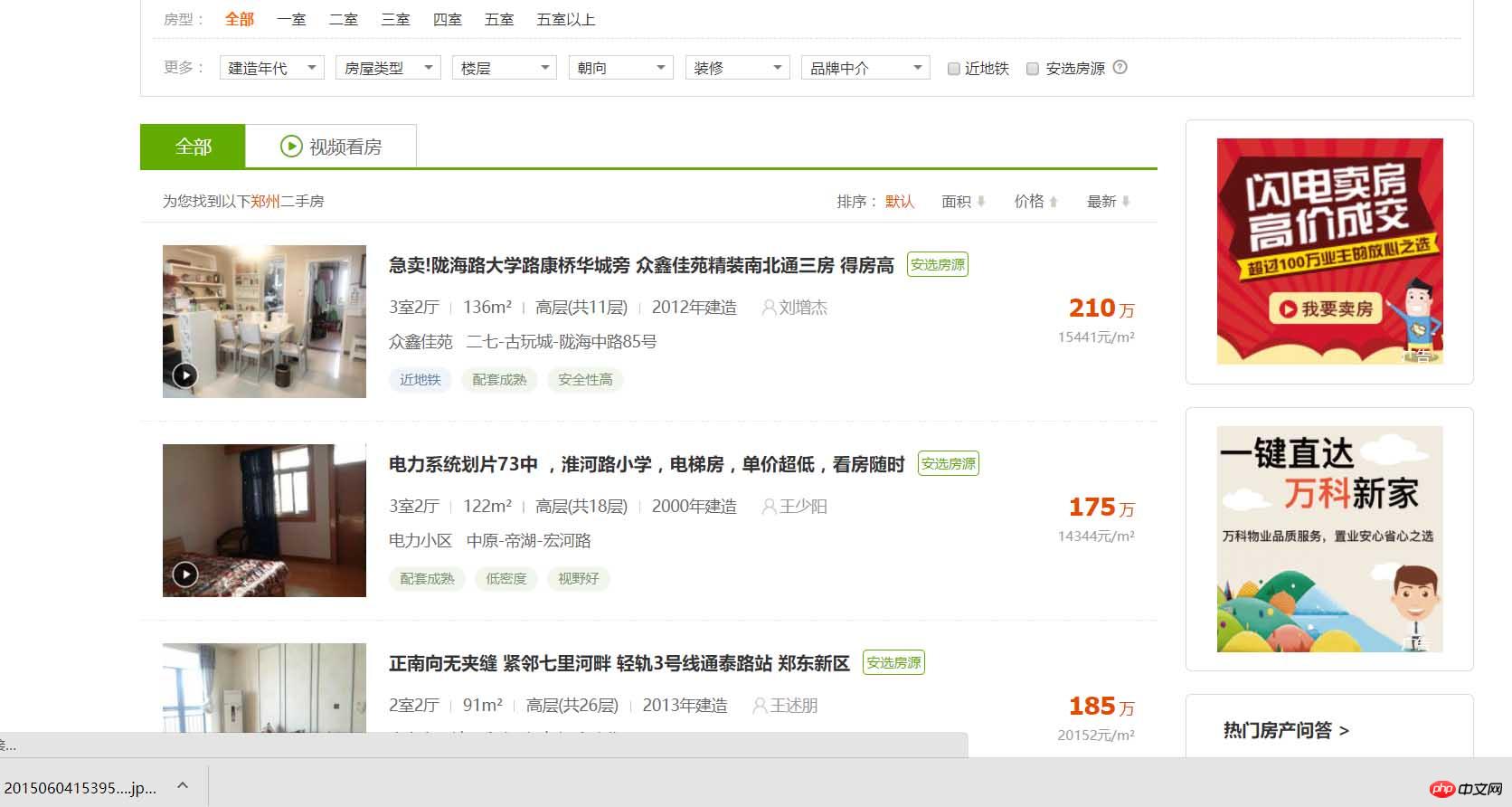
Auf der obigen Seite können wir die Immobilieninformationen einzeln sehen. Von oben können wir die Immobilieninformationen einzeln auf der Webseite sehen finden Sie:
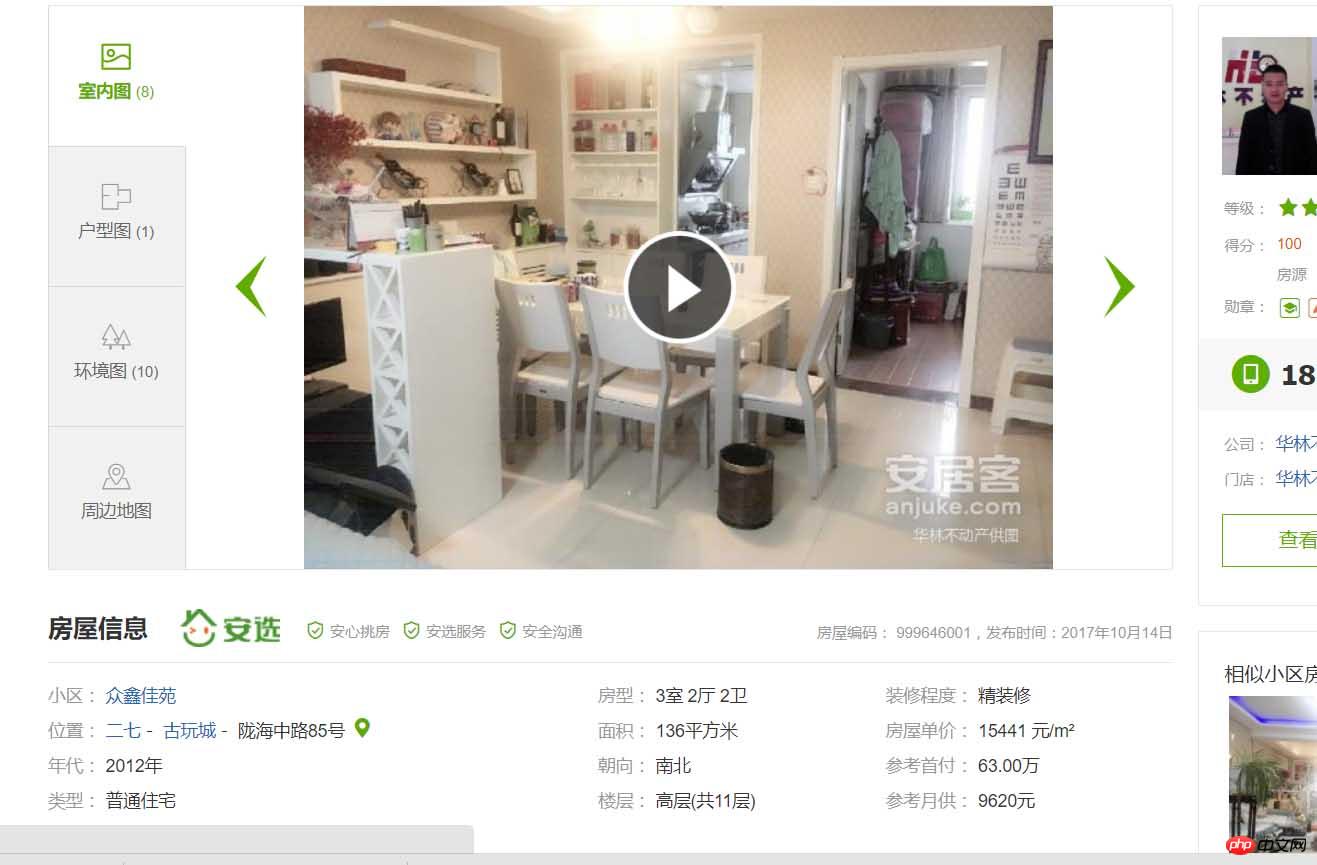
Details zur Immobilie. OK! Was werden wir also tun? Das heißt, alle Informationen zu Gebrauchtwohnungen in Zhengzhou abzurufen und sie in der Datenbank zu speichern. Als Geograph werde ich noch nicht näher darauf eingehen Diesmal. Okay, fangen wir offiziell an. Zuerst verwende ich die Module „Requests“ und „BeautifulSoup“ zum Crawlen der Seite:
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
response = requests.get(url, headers=header)
print(response.text)Ausführung Dann erhalten Sie den HTML-Code dieser Website
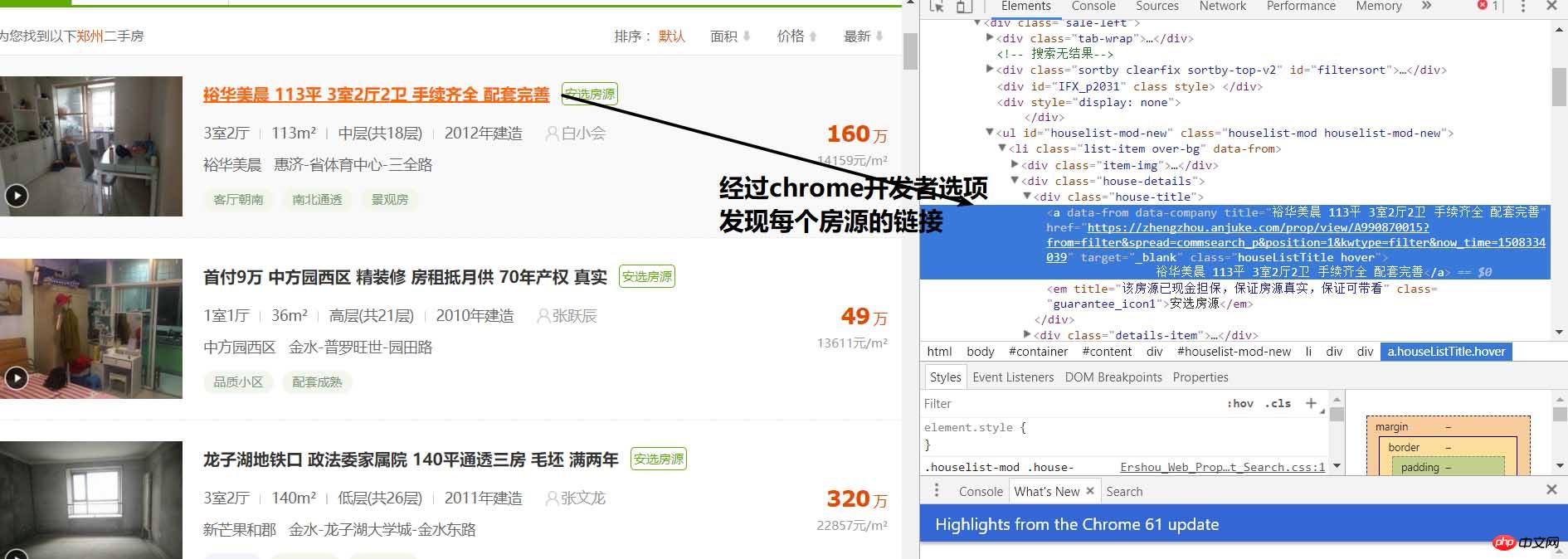
 Durch Analyse können wir feststellen, dass sich jedes Haus im li-Tag von class="list-item" befindet. , dann können wir es gemäß BeautifulSoup verwenden. Durch Extrahieren des Pakets
Durch Analyse können wir feststellen, dass sich jedes Haus im li-Tag von class="list-item" befindet. , dann können wir es gemäß BeautifulSoup verwenden. Durch Extrahieren des Pakets
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
for i in result_li:
print(i)kann die Codemenge durch Drucken weiter reduziert werden. Okay, extrahieren Sie weiter
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
print(result_href.attrs['href'])Auf diese Weise können wir die URLs einzeln sehen 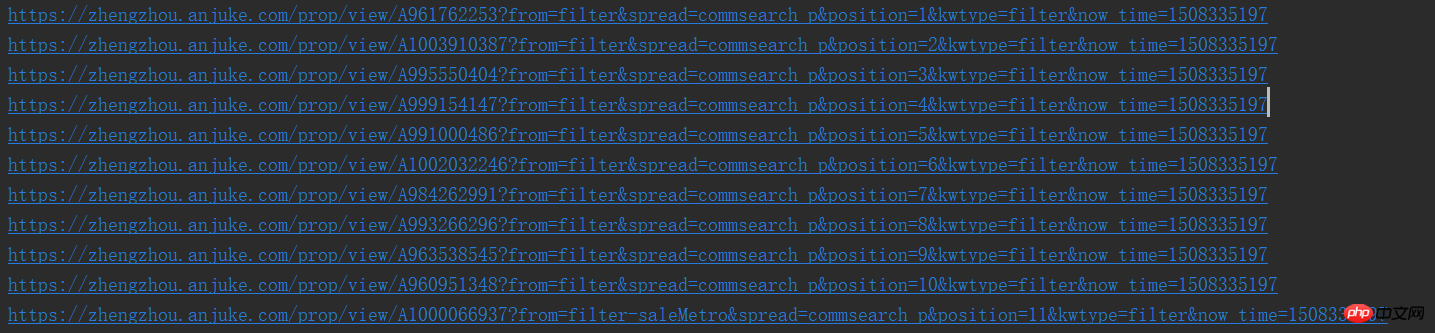
Okay, nach normaler Logik, wir Wir müssen die Seite aufrufen und mit der Analyse der detaillierten Seite beginnen, aber nach dem Crawlen müssen wir zunächst analysieren, ob die Seite eine nächste Seite hat
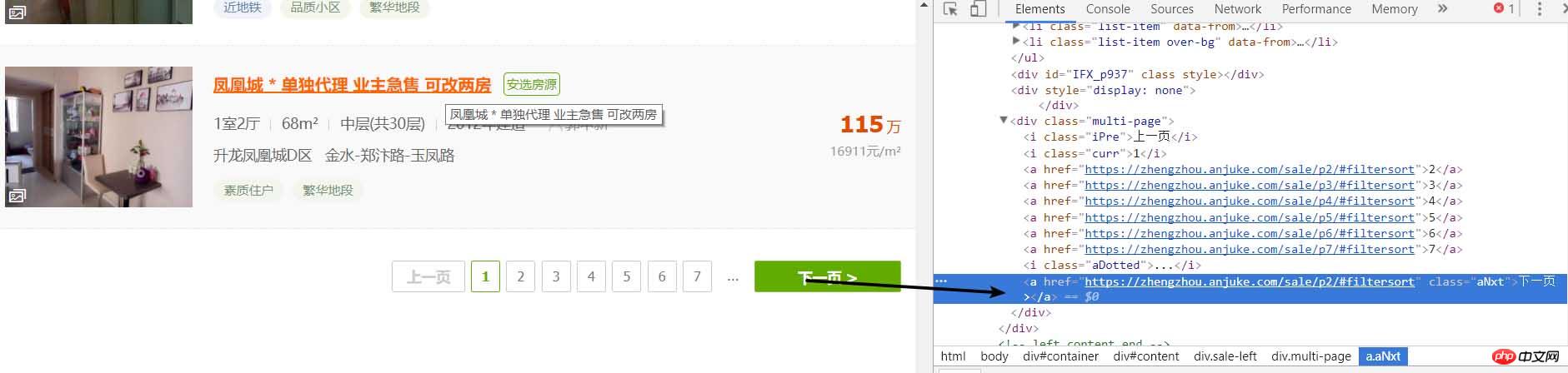
Auf die gleiche Weise können wir feststellen, dass die nächste Seite auch so einfach ist, dass wir mit dem Originalrezept und dem Originalgeschmack fortfahren können
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
print(result_next_page[0].attrs['href'])
else:
print('没有下一页了')Denn wann Es gibt die nächste Seite, es gibt ein a-Tag auf der Webseite. Wenn nicht, wird es zu einem i-Tag, also können wir es verbessern und das Obige in eine Funktion kapseln
import requests
from bs4 import BeautifulSoup
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
def get_page(url):
response = requests.get(url, headers=header)
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 先不做分析,等一会进行详细页面函数完成后进行调用
print(result_href.attrs['href'])
if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)Okay, dann fangen wir an, die detaillierten Seiten zu crawlen
Hey, der Strom wird auf Schritt und Tritt abgeschaltet, was für eine Falle in der Universität, ich‘ Ich hänge zuerst die Ergebnisse an, ich füge weitere hinzu, wenn ich Zeit habe,
import requests
from bs4 import BeautifulSoup
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
def get_page(url):
response = requests.get(url, headers=header)
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup_idex = BeautifulSoup(response.text, 'html.parser')
result_li = soup_idex.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 详细页面的函数调用
get_page_detail(result_href.attrs['href'])
# 进行下一页的爬取
result_next_page = soup_idex.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
# 进行字符串中空格,换行,tab键的替换及删除字符串两边的空格删除
def my_strip(s):
return str(s).replace(" ", "").replace("\n", "").replace("\t", "").strip()
# 由于频繁进行BeautifulSoup的使用,封装一下,很鸡肋
def my_Beautifulsoup(response):
return BeautifulSoup(str(response), 'html.parser')
# 详细页面的爬取
def get_page_detail(url):
response = requests.get(url, headers=header)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 标题什么的一大堆,哈哈
result_title = soup.find_all('h3', {'class': 'long-title'})[0]
result_price = soup.find_all('span', {'class': 'light info-tag'})[0]
result_house_1 = soup.find_all('p', {'class': 'first-col detail-col'})
result_house_2 = soup.find_all('p', {'class': 'second-col detail-col'})
result_house_3 = soup.find_all('p', {'class': 'third-col detail-col'})
soup_1 = my_Beautifulsoup(result_house_1)
soup_2 = my_Beautifulsoup(result_house_2)
soup_3 = my_Beautifulsoup(result_house_3)
result_house_tar_1 = soup_1.find_all('dd')
result_house_tar_2 = soup_2.find_all('dd')
result_house_tar_3 = soup_3.find_all('dd')
'''
文博公寓,省实验中学,首付只需70万,大三房,诚心卖,价可谈 270万
宇泰文博公寓 金水-花园路-文博东路4号 2010年 普通住宅
3室2厅2卫 140平方米 南北 中层(共32层)
精装修 19285元/m² 81.00万
'''
print(my_strip(result_title.text), my_strip(result_price.text))
print(my_strip(result_house_tar_1[0].text),
my_strip(my_Beautifulsoup(result_house_tar_1[1]).find_all('p')[0].text),
my_strip(result_house_tar_1[2].text), my_strip(result_house_tar_1[3].text))
print(my_strip(result_house_tar_2[0].text), my_strip(result_house_tar_2[1].text),
my_strip(result_house_tar_2[2].text), my_strip(result_house_tar_2[3].text))
print(my_strip(result_house_tar_3[0].text), my_strip(result_house_tar_3[1].text),
my_strip(result_house_tar_3[2].text))
if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)Da ich beim Bloggen Code geschrieben habe, habe ich einige Änderungen an der get_page vorgenommen Funktion, das heißt, der rekursive Aufruf für die nächste Seite muss nach der Funktion platziert und gekapselt werden. Die beiden Funktionen werden nicht eingeführt,
und die Daten werden nicht in MySQL geschrieben, daher werde ich weiterverfolgen Später danke!!!
Verwandte Empfehlungen:
Beispiel-Tutorial für Python-Crawling-Artikel
10 empfohlene Artikel über Python Crawling
Teilen eines Python-Crawlings So machen Sie beliebte Kommentare zu NetEase Cloud Music
Das obige ist der detaillierte Inhalt vonPython-Crawling-Methode für den Datenaustausch auf Anjuke-Gebrauchtwohnungswebsites. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Effizientes Training von Pytorch -Modellen auf CentOS -Systemen erfordert Schritte, und dieser Artikel bietet detaillierte Anleitungen. 1.. Es wird empfohlen, YUM oder DNF zu verwenden, um Python 3 und Upgrade PIP zu installieren: Sudoyumupdatepython3 (oder sudodnfupdatepython3), PIP3Install-upgradepip. CUDA und CUDNN (GPU -Beschleunigung): Wenn Sie Nvidiagpu verwenden, müssen Sie Cudatool installieren
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
Bei der Auswahl einer Pytorch -Version unter CentOS müssen die folgenden Schlüsselfaktoren berücksichtigt werden: 1. Cuda -Version Kompatibilität GPU -Unterstützung: Wenn Sie NVIDIA -GPU haben und die GPU -Beschleunigung verwenden möchten, müssen Sie Pytorch auswählen, der die entsprechende CUDA -Version unterstützt. Sie können die CUDA-Version anzeigen, die unterstützt wird, indem Sie den Befehl nvidia-smi ausführen. CPU -Version: Wenn Sie keine GPU haben oder keine GPU verwenden möchten, können Sie eine CPU -Version von Pytorch auswählen. 2. Python Version Pytorch
 So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
Die Installation von CentOS-Installationen erfordert die folgenden Schritte: Installieren von Abhängigkeiten wie Entwicklungstools, PCRE-Devel und OpenSSL-Devel. Laden Sie das Nginx -Quellcode -Paket herunter, entpacken Sie es, kompilieren Sie es und installieren Sie es und geben Sie den Installationspfad als/usr/local/nginx an. Erstellen Sie NGINX -Benutzer und Benutzergruppen und setzen Sie Berechtigungen. Ändern Sie die Konfigurationsdatei nginx.conf und konfigurieren Sie den Hörport und den Domänennamen/die IP -Adresse. Starten Sie den Nginx -Dienst. Häufige Fehler müssen beachtet werden, z. B. Abhängigkeitsprobleme, Portkonflikte und Konfigurationsdateifehler. Die Leistungsoptimierung muss entsprechend der spezifischen Situation angepasst werden, z. B. das Einschalten des Cache und die Anpassung der Anzahl der Arbeitsprozesse.
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
