

Dieser Artikel informiert Sie hauptsächlich über die Prinzipien des Linux-Betriebssystems. Dies ist ein sehr gutes grundlegendes Tutorial zum Linux-System. Wir haben alle relevanten ausgewählten Inhalte zusammengefasst, damit Sie sie gemeinsam lernen können. Ich hoffe, es hilft allen.
1. Die vier Zeitalter der Computer
Die erste Generation:
Vakuumröhrencomputer, Eingabe und Ausgabe: Lochkarten sind auf Computern sehr unpraktisch. Um eine Aufgabe zu erledigen, sind möglicherweise mehr als ein Dutzend Personen erforderlich. Das Jahr ist wahrscheinlich: 1945-1955. Und es verbraucht viel Strom. Wenn Sie zu dieser Zeit einen Computer hatten, wurde die Helligkeit Ihrer Glühbirnen möglicherweise geringer, sobald Sie den Computer einschalteten.
2 🎜>
Transistorcomputer und Stapelverarbeitungssysteme (die im seriellen Modus laufen) entstanden. Es spart viel mehr Strom als das erste. Der typische Vertreter ist Mainframe. Ungefähres Jahr: 1955-1965. Damals wurde die Fortran-Sprache geboren – eine sehr alte Computersprache. 3. Die dritte Generation: Die Entstehung integrierter Schaltkreise und der Entwurf von Mehrkanal-Verarbeitungsprogrammen (die im Parallelmodus laufen). Die typischeren Vertreter sind: Time-Sharing-Systeme (). Aufteilung der CPU-Operationen in Zeiteinheiten). Das Jahr ist wahrscheinlich: etwa 1965-1980. 4. Die vierte Generation: PC erschien, wahrscheinlich um 1980. Ich glaube, die typischen Vertreter dieser Ära: Bill Gates, Steve Jobs. 2. Computer-Arbeitssystem Obwohl sich Computer über vier Zeitalter hinweg weiterentwickelt haben, ist das Computer-Arbeitssystem bis heute immer noch relativ einfach. Im Allgemeinen besteht unser Computer aus fünf Grundteilen. 1.MMU (Speichersteuereinheit, implementiert Speicher-Paging [Speicherseite]) Der Rechenmechanismus ist unabhängig von der CPU (Rechnersteuereinheit). In der CPU befindet sich ein einzigartiger Chip namens MMU. Es wird verwendet, um die Entsprechung zwischen der Thread-Adresse und der physischen Adresse des Prozesses zu berechnen. Es dient auch dem Zugriffsschutz, d. h. wenn ein Prozess zuerst auf eine Speicheradresse zugreift, die ihm nicht gehört, wird ihm dieser verweigert! 2. Speicher (Speicher) 3. Anzeigegerät (VGA-Schnittstelle, Monitor usw.) [gehört zum IO-Gerät] 4. Tastaturgerät) [Gehört zu IO-Geräten] 5. Festplattengerät (Festplattensteuerung, Festplattencontroller oder Adapter) [Gehört zu IO-Geräten] Erweitertes Wissen: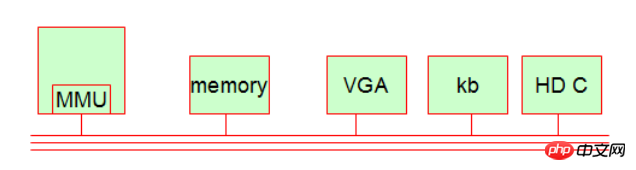
Erweitertes Wissen:
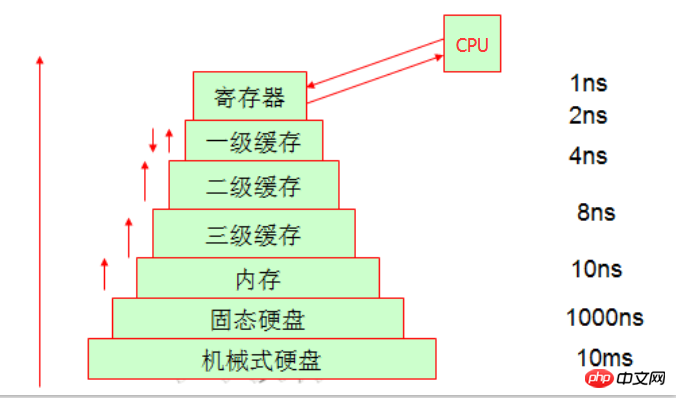
Da der Registerspeicherplatz innerhalb der CPU begrenzt ist, wird Speicher zum Speichern von Daten verwendet. Da die Geschwindigkeit der CPU und die Geschwindigkeit des Speichers jedoch nicht auf dem gleichen Niveau sind überhaupt, also in der Verarbeitung Die meisten von ihnen warten, bis die Daten zurückgegeben werden (die CPU muss ein Datenelement aus dem Speicher abrufen, und es kann in einer Umdrehung der CPU verarbeitet werden, während der Speicher möglicherweise rotieren muss 20 Mal). Um die Effizienz zu verbessern, entstand das Konzept des Caching.
Da wir nun das Prinzip der Programmlokalität kennen, wissen wir auch, dass die CPU tatsächlich Zeit für den Austausch von Speicherplatz benötigt, um mehr Speicherplatz zu erhalten, der Cache die Daten jedoch direkt von der CPU abrufen kann, was Zeit spart , Caching bedeutet also, Platz für Zeit zu nutzen
3. Auch wenn es sich um ein Speichersystem handelt
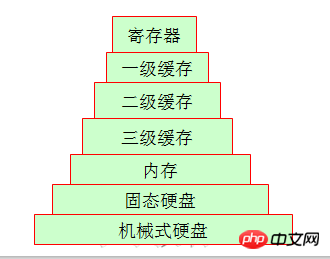
Freunde, die während der Arbeitszeit arbeiten, haben möglicherweise Bandlaufwerke gesehen, Und jetzt verwenden sie im Grunde alle Festplatten, um Bandlaufwerke zu ersetzen. Schauen wir uns also die Struktur des Heimcomputers an, mit der wir am besten vertraut sind. Die Daten sind anders als beim letzten Mal, als sie gespeichert wurden. Wir können ein einfaches Beispiel nennen: Es gibt eine große Lücke zwischen ihren wöchentlichen Lagerzyklen. Besonders auffällig ist die mechanische Festplatte und der Arbeitsspeicher. Die Lücke zwischen beiden ist hinsichtlich des Zugriffs recht groß.
Erweitertes Wissen:
Im Vergleich zu Ihrem eigenen Heim-Desktop oder Notebook haben Sie es möglicherweise selbst zerlegt und über mechanische Festplatten, Solid-State-Laufwerke oder Speicher usw. gesprochen. Aber vielleicht haben Sie den Cache des physischen Geräts nicht gesehen, aber er befindet sich tatsächlich auf der CPU. Daher kann es in unserem Verständnis einige blinde Flecken geben.
Lassen Sie uns zunächst über den First-Level-Cache und den Headset-Cache sprechen. Wenn ihre CPU dort Daten abruft, ist der Zeitraum im Grunde nicht sehr lang, da sowohl der First-Level-Cache als auch der Second-Level-Cache intern sind Ressourcen des CPU-Kerns. (Unter den gleichen Hardwarebedingungen kann der Marktpreis für 128.000 L1-Cache etwa 300 Yuan betragen, der Marktpreis für 256.000 L1-Cache kann etwa 600 Yuan betragen und der Marktpreis für 512.000 L1-Cache kann über vierstellig sein. Sie können darauf verweisen an JD.com für den spezifischen Preis. Dies reicht aus, um zu zeigen, dass die Kosten für den Cache sehr hoch sind!) Zu diesem Zeitpunkt fragen Sie sich vielleicht, was ist mit dem Cache der dritten Ebene? Tatsächlich ist der Cache der dritten Ebene der von mehreren CPUs gemeinsam genutzte Speicherplatz. Natürlich teilen sich auch mehrere CPUs den Speicher.
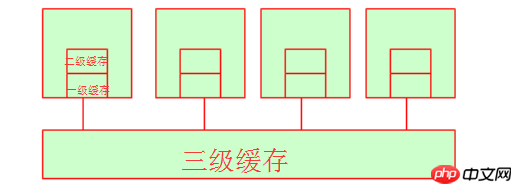
4. Ungleichmäßiger Speicherzugriff (NUMA)
Wir wissen, dass ein Problem auftritt, wenn mehrere CPUs den L3-Cache oder -Speicher teilen der Ressourcenenteignung. Wir wissen, dass Variablen oder Zeichenfolgen Speicheradressen haben, wenn sie im Speicher gespeichert werden. Wie erhalten sie die Speicheradresse? Wir können uns auf das Bild unten beziehen:
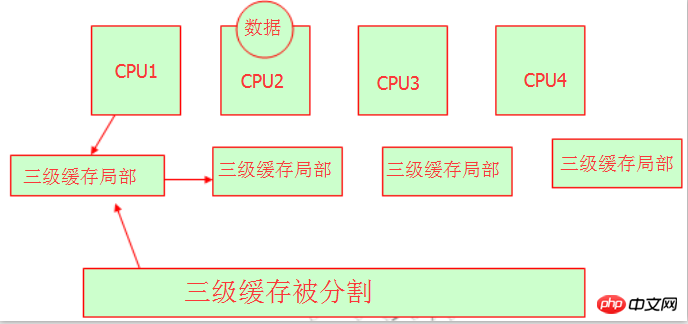
Ja, diese Hardware-Experten teilen den Cache auf drei Ebenen auf und lassen verschiedene CPUs unterschiedliche Speicheradressen belegen. Auf diese Weise ist es so Es ist verständlich, dass sie alle über einen eigenen Level-3-Cache-Bereich verfügen und es kein Problem mit der Ressourcenbeanspruchung geben wird. Es sollte jedoch beachtet werden, dass es sich immer noch um denselben Level-3-Cache handelt. Genau wie Peking die Bezirke Chaoyang, Fengtai, Daxing, Haidian usw. hat, aber sie sind alle Teil von Peking. Wir können hier verstehen. Dies ist NUMA. Seine Merkmale sind: ungleichmäßiger Speicherzugriff, jeder hat seinen eigenen Speicherplatz.
Erweitertes Wissen:
Dann besteht das Problem basierend auf dem Neuladeergebnis darin, dass, wenn der Prozess, der auf cpu1 läuft, angehalten wird, seine Adresse in seiner eigenen Cache-Adresse aufgezeichnet wird, aber wie wird damit umgegangen von CPU2, wenn das Programm erneut ausgeführt wird?
Es bleibt keine andere Wahl, als eine Adresse aus dem Aufrauungsbereich der dritten Ebene von CPU1 zu kopieren oder zur Verarbeitung auf CPU2 zu verschieben. Dies wird eine gewisse Zeit in Anspruch nehmen. Daher führt eine Neuausrichtung zu einer Verringerung der CPU-Leistung. Zu diesem Zeitpunkt können wir dies mithilfe der Prozessbindung erreichen, sodass bei der erneuten Verarbeitung des Prozesses weiterhin die für die Verarbeitung verwendete CPU verwendet wird. Das heißt, die CPU-Affinität des Prozesses.
5. Durchschreib- und Rückschreibmechanismen im Cache.
Der Ort, an dem die CPU Daten verarbeitet, besteht darin, sie im Register zu ändern. Wenn das Register nicht über die gesuchten Daten verfügt, wird es zum ersten Mal verschoben. Wenn sich im Cache der ersten Ebene keine Daten befinden, werden die Daten im Cache der zweiten Ebene gefunden, nacheinander durchsucht, bis sie von der Festplatte gefunden werden, und dann in das Register geladen. Wenn der Cache der dritten Ebene Daten aus dem Speicher abruft und feststellt, dass der Cache der dritten Ebene nicht ausreicht, wird der Speicherplatz im Cache der dritten Ebene automatisch gelöscht.
Wir wissen, dass der letzte Ort, an dem Daten gespeichert werden, die Festplatte ist und dieser Zugriffsprozess vom Betriebssystem durchgeführt wird. Wenn unsere CPU Daten verarbeitet, schreibt sie Daten über zwei Schreibmethoden an verschiedene Orte: Durchschreiben (in den Speicher schreiben) und Zurückschreiben (in den Cache der ersten Ebene schreiben). Offensichtlich ist die Rückschreibleistung gut, aber wenn der Strom ausfällt, wird es peinlich und die Daten gehen verloren, da sie direkt in den Cache der ersten Ebene geschrieben werden, andere CPUs jedoch nicht auf den Cache der ersten Ebene zugreifen können , also aus der Perspektive der Zuverlässigkeit Aus Sicht des Schreibens wird die allgemeine Schreibmethode zuverlässiger sein. Welche Methode Sie verwenden, hängt von Ihren Bedürfnissen ab.
4. IO-Gerät
1. IO-Gerät besteht aus dem Gerätecontroller und dem Gerät selbst.
Gerätecontroller: ein Chip oder eine Reihe von Chips, die auf der Hauptplatine integriert sind. Verantwortlich für den Empfang von Befehlen vom Betriebssystem und den Abschluss der Ausführung der Befehle. Es ist beispielsweise für das Auslesen von Daten aus dem Betriebssystem verantwortlich.
Das Gerät selbst: Es verfügt über eine eigene Schnittstelle, die Schnittstelle des Geräts selbst ist jedoch nicht verfügbar, es handelt sich lediglich um eine physische Schnittstelle. Wie zum Beispiel die IDE-Schnittstelle.
Erweiterte Kenntnisse:
Jeder Controller verfügt über eine kleine Anzahl von Registern für die Kommunikation (von einigen bis zu Dutzenden). Dieses Register ist direkt in den Gerätecontroller integriert. Beispielsweise wird ein minimaler Festplattencontroller auch verwendet, um Register für Festplattenadressen, Sektoranzahlen, Lese- und Schreibrichtungen und andere damit verbundene Betriebsanforderungen anzugeben. Jedes Mal, wenn Sie den Controller aktivieren möchten, empfängt der Gerätetreiber die Betriebsanweisung vom Betriebssystem, wandelt sie dann in die Grundoperation des entsprechenden Geräts um und stellt die Betriebsanforderung in das Register, um die Operation abzuschließen. Jedes Register verhält sich wie ein IO-Port. Alle Registerkombinationen werden als I/O-Adressraum des Geräts bezeichnet, auch I/O-Portraum genannt,
2.Treiber
Der eigentliche Hardwarebetrieb wird durch den Treiberbetrieb vervollständigt. Treiber sollten normalerweise vom Gerätehersteller erstellt werden. Normalerweise befindet sich der Treiber im Kernel, aber nur wenige Leute tun dies, weil es zu ineffizient ist.
3. Ein- und Ausgabe implementieren
Die E/A-Ports des Geräts können nicht im Voraus zugewiesen werden, da die Modelle der einzelnen Motherboards inkonsistent sind, daher müssen wir sie dynamisch zuweisen. Wenn der Computer eingeschaltet ist, muss sich jedes E/A-Gerät registrieren, um den E/A-Port im E/A-Portraum des Busses zu verwenden. Dieser dynamische Port besteht aus allen Registern, die im E/A-Adressraum des Geräts zusammengefasst sind. Es gibt 2^16 Ports, also 65535 Ports.
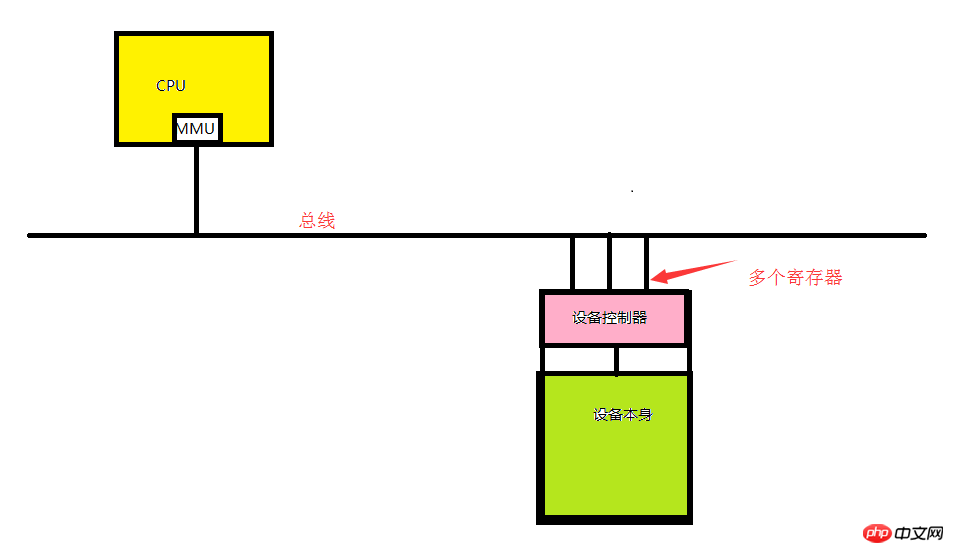
Wie im Bild oben gezeigt, muss unsere CPU, wenn sie mit dem angegebenen Gerät umgehen möchte, den Befehl an den Treiber übergeben, und dieser konvertiert ihn dann CPU-Befehl in etwas, das das Gerät verstehen kann. Das Register (I/O-Port) ist also die Adresse (I/O-Port), über die die CPU mit dem Gerät interagiert der Bus.
Erweiterte Kenntnisse:
Drei Möglichkeiten zur Implementierung der Ein- und Ausgabe von E/A-Geräten:
A.. Abfrage:
Bezieht sich normalerweise auf den Benutzer Das Programm initiiert einen Systemaufruf und der Kernel übersetzt ihn in einen Prozeduraufruf für den entsprechenden Treiber des Kernels. Anschließend startet der Gerätetreiber die E/A und überprüft das Gerät in einer Endlosschleife, um festzustellen, ob das Gerät seine Arbeit abgeschlossen hat. Dies ähnelt in gewisser Weise dem „Busy Waiting“ (d. h. die CPU verwendet einen festen Zeitraum, um jedes E/A-Gerät kontinuierlich zu überprüfen, um festzustellen, ob Daten vorhanden sind. Offensichtlich ist diese Effizienz nicht ideal.),
B. .Unterbrechen:
Unterbrechen Sie das von der CPU verarbeitete Programm und unterbrechen Sie den von der CPU ausgeführten Vorgang, wodurch der Kernel benachrichtigt wird, eine Unterbrechungsanforderung zu erhalten. Auf unserem Motherboard befindet sich normalerweise ein einzigartiges Gerät, das als programmierbarer Interrupt-Controller bezeichnet wird. Dieser Interrupt-Controller kann über einen bestimmten Pin direkt mit der CPU kommunizieren und die CPU dazu veranlassen, an einer bestimmten Position abzulenken, wodurch die CPU darüber informiert wird, dass ein bestimmtes Signal angekommen ist. Auf dem Interrupt-Controller gibt es einen Interrupt-Vektor (wenn jedes unserer E/A-Geräte startet, soll der Interrupt-Controller eine Interrupt-Nummer registrieren. Diese Nummer ist normalerweise eindeutig. Normalerweise kann jeder Pin des Interrupt-Vektors mehrere Interrupts identifizieren Nummer), die auch als Interrupt-Nummer bezeichnet werden kann.
Wenn also tatsächlich ein Interrupt auf diesem Gerät auftritt, stellt dieses Gerät keine Daten direkt auf den Bus. Dieses Gerät sendet sofort eine Interrupt-Anfrage an den Interrupt-Controller Der vom Gerät gesendete Interrupt-Vektor wird dann auf irgendeine Weise der CPU mitgeteilt, sodass die CPU weiß, welches Gerät die Interrupt-Anfrage erreicht hat. Zu diesem Zeitpunkt kann die CPU die E/A-Portnummer gemäß der Geräteregistrierung verwenden, sodass die Gerätedaten abgerufen werden können. (Beachten Sie, dass die CPU Daten nicht direkt abrufen kann, da sie nur das Interrupt-Signal empfängt. Sie kann nur den Kernel benachrichtigen, den Kernel auf der CPU selbst laufen lassen und der Kernel erhält die Interrupt-Anforderung.) Beispielsweise empfängt eine Netzwerkkarte Für externe IP-Anfragen verfügt die Netzwerkkarte auch über einen eigenen Cache-Bereich. Die CPU liest ihn zunächst aus und ermittelt, ob es sich um eine eigene IP handelt Paket und erhält schließlich eine Portnummer. Dann findet die CPIU diesen Port in ihrem eigenen Interrupt-Controller und behandelt ihn entsprechend.
Die Kernel-Interrupt-Verarbeitung ist in zwei Schritte unterteilt: die erste Hälfte des Interrupts (sofort verarbeitet) und die zweite Hälfte des Interrupts (nicht unbedingt). Nehmen wir das Beispiel des Empfangs von Daten von der Netzwerkkarte. Wenn die Benutzeranforderung die Netzwerkkarte erreicht, befiehlt die CPU, die Daten im Cache-Bereich der Netzwerkkarte direkt in den Speicher abzurufen nach dem Empfang (die Verarbeitung besteht darin, die Daten von der Netzwerkkarte in den Speicher zu übertragen, um die spätere Verarbeitung zu erleichtern). Der Teil, der die Anfrage tatsächlich bearbeitet, wird als zweite Hälfte bezeichnet.
C.DMA:
Der direkte Speicherzugriff erfolgt über den Bus Welche E/A-Geräte nutzen den Bus zu einem bestimmten Zeitpunkt? Dies wird vom CPU-Controller bestimmt. Der Bus hat drei Funktionen: Adressbus (zur Vervollständigung der Adressierungsfunktion des Geräts), Steuerbus (zur Steuerung der Funktion jeder Geräteadresse über den Bus) und Datenbus (zur Realisierung der Datenübertragung).
Normalerweise handelt es sich um einen intelligenten Steuerchip, der mit dem E/A-Gerät geliefert wird (wir nennen ihn den Direct Memory Access Controller). Wenn die erste Hälfte des Interrupts verarbeitet werden muss, benachrichtigt die CPU den DMA Gerät akzeptiert den Bus, der vom DMA-Gerät verwendet wird, und teilt ihm den Speicherplatz mit, der zum Einlesen der Daten des E/A-Geräts in den Speicherplatz verwendet werden kann. Wenn das DMA-E/A-Gerät das Lesen der Daten abgeschlossen hat, sendet es eine Nachricht, um der CPU mitzuteilen, dass der Lesevorgang abgeschlossen ist. Zu diesem Zeitpunkt benachrichtigt die CPU den Kernel, dass die Daten geladen wurden Die zweite Hälfte des Interrupts wird an den Kernel übergeben. Die meisten Geräte verwenden mittlerweile DMA-Controller, wie z. B. Netzwerkkarten, Festplatten usw.
5. Betriebssystemkonzepte
Durch die obige Studie wissen wir, dass ein Computer aus fünf Grundkomponenten besteht. Das Betriebssystem abstrahiert diese fünf Komponenten hauptsächlich in einer relativ intuitiven Oberfläche, die direkt von Programmierern oder Benutzern der oberen Ebene verwendet wird. Was sind also die Dinge, die im Betriebssystem tatsächlich abstrahiert werden?
1.CPU (Zeitscheibe)
Im Betriebssystem wird die CPU in Zeitscheiben abstrahiert, und dann wird das Programm in einen Prozess abstrahiert und das Programm wird durch Zuweisen von Zeit ausgeführt Scheiben. Die CPU verfügt über eine Adressierungseinheit, die die kollektive Speicheradresse identifiziert, an der die Variable im Speicher gespeichert ist.
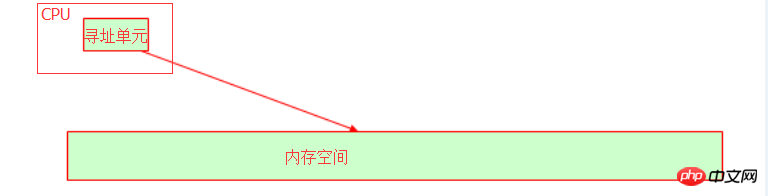
Der interne Bus unseres Hosts hängt von der Bitbreite (auch Wortlänge genannt) der CPU ab. Beispielsweise kann der 32-Bit-Adressbus 2 to darstellen 32. Potenz. Die in Dezimalzahl umgewandelte Speicheradresse ist 4G-Speicherplatz. Zu diesem Zeitpunkt sollten Sie verstehen, warum das 32-Bit-Betriebssystem nur 4G-Speicher erkennen kann, oder? Selbst wenn Ihr physischer Speicher 16 GB groß ist, beträgt der verfügbare Speicher immer noch 4 GB. Wenn Sie also feststellen, dass Ihr Betriebssystem Speicheradressen über 4 GB erkennt, darf Ihr Betriebssystem nicht 32-Bit sein!
2. Speicher
Im Betriebssystem wird Speicher durch einen virtuellen Adressraum implementiert.
3. E/A-Gerät
Im Betriebssystem ist das zentrale E/A-Gerät die Festplatte. Im Kernel ist sie abstrahiert Datei.
4. Prozess
Um es ganz klar auszudrücken: Besteht der Hauptzweck der Existenz eines Computers nicht nur darin, Programme auszuführen? Wenn das Programm ausgeführt wird, nennen wir es einen Prozess (wir müssen uns vorerst nicht um Threads kümmern). Wenn mehrere Prozesse gleichzeitig ausgeführt werden, bedeutet dies, dass diese begrenzten abstrakten Ressourcen (CPU, Speicher usw.) mehreren Prozessen zugewiesen werden. Wir bezeichnen diese abstrakten Ressourcen zusammenfassend als Ressourcensätze.
Der Ressourcensatz umfasst:
1>.CPU-Zeit;
2> 4G Speicherplatz, Der Kernel belegt 1G Speicherplatz und der Prozess verwendet standardmäßig 3G verfügbaren Speicherplatz. Tatsächlich sind möglicherweise nicht 3G Speicherplatz vorhanden, da Ihr Computer möglicherweise über weniger als 4G Speicher verfügt)
3> ;.I/O: Alles ist eine Datei, um mehrere Dateien zu öffnen, öffnen Sie die angegebene Datei über fd (Dateideskriptor). Wir unterteilen Dateien in drei Kategorien: normale Dateien, Gerätedateien und Pipeline-Dateien.
Jeder Prozess hat seine eigene Aufgabenadressstruktur, nämlich: Aufgabenstruktur. Es handelt sich um eine Datenstruktur, die vom Kernel für jeden Prozess verwaltet wird (eine Datenstruktur wird zum Speichern von Daten verwendet). Um es ganz klar auszudrücken: Es handelt sich um den Speicherplatz, der den Ressourcensatz aufzeichnet, der dem Prozess gehört, und natürlich seinem übergeordneten Prozess. Dadurch wird die Szene gespeichert [Wird zur Prozessumschaltung verwendet], Speicherzuordnung warten). Die Aufgabenstruktur simuliert lineare Adressen und ermöglicht dem Prozess die Verwendung dieser linearen Adressen, zeichnet jedoch die Zuordnungsbeziehung zwischen linearen Adressen und physischen Speicheradressen auf.
5. Speicherzuordnung – Seitenrahmen
Solange es sich nicht um den vom Kernel verwendeten physischen Speicherplatz handelt, nennen wir ihn Benutzerbereich. Der Kernel schneidet den physischen Speicher des Benutzerbereichs in einen Seitenrahmen mit fester Größe (d. h. Seitenrahmen) ein, es handelt sich um eine Speichereinheit mit fester Größe, die kleiner ist als die Standard-Einzelspeichereinheit (der Standardwert ist). Ein Byte, also 8 Bit, sollte normalerweise eine Speichereinheit pro 4 KB groß sein. Jeder Seitenrahmen ist nach außen hin als eigenständige Einheit zugeordnet und jeder Seitenrahmen ist zusätzlich nummeriert. [Beispiel: Angenommen, 4G-Speicherplatz ist verfügbar, jeder Seitenrahmen ist 4 KB groß und es gibt insgesamt 1 Mio. Seitenrahmen. 】Diese Seitenrahmen sind verschiedenen Prozessen zugeordnet.
Wir gehen davon aus, dass Sie über 4 GB Arbeitsspeicher verfügen, das Betriebssystem 1 GB belegt und die verbleibenden 3 GB physischen Speicher dem Benutzerbereich zugewiesen sind. Nachdem jeder Prozess gestartet wurde, geht er davon aus, dass 3G-Speicherplatz verfügbar ist, tatsächlich kann er 3G jedoch überhaupt nicht nutzen. Der vom Prozess geschriebene Speicher wird diskret gespeichert. Greifen Sie überall dort zu, wo freier Speicher vorhanden ist. Fragen Sie mich nicht nach dem spezifischen Zugriffsalgorithmus, ich habe ihn auch nicht studiert.
Prozessraumstruktur:
1>. Reservierter Speicherplatz
2>
4>.Heap (öffnen Sie eine Datei, in der der Datenstrom in der Datei gespeichert wird)5>.Datensegment (globaler statischer Variablenspeicher)6>.Code Der Die Speicherbeziehung zwischen dem Segment Prozess und dem Speicher lautet wie folgt: Jeder Prozessraum verfügt über reservierten Speicherplatz. Wenn ein Prozess feststellt, dass die von ihm geöffneten Daten vorhanden sind Es reicht nicht aus, es muss eine neue Datei geöffnet werden (das Öffnen einer neuen Datei erfordert das Speichern von Daten im Adressraum des Prozesses). Offensichtlich ist der Prozessadressraum im obigen Bild linear und nicht im eigentlichen Sinne. Wenn ein Prozess tatsächlich einen Speicher beantragt, muss er einen Systemaufruf an den Kernel initiieren. Der Kernel findet einen physischen Platz im physischen Speicher und teilt dem Prozess die Speicheradresse mit, die verwendet werden kann. Wenn ein Prozess beispielsweise eine Datei auf dem Heap öffnen möchte, muss er Speicherplatz vom Betriebssystem (Kernel) beantragen und innerhalb des durch den physischen Speicher zulässigen Bereichs liegen (d. h. der angeforderte Speicher muss kleiner sein als Der freie physische Speicher wird vom Kernel der Prozessspeicheradresse zugewiesen. 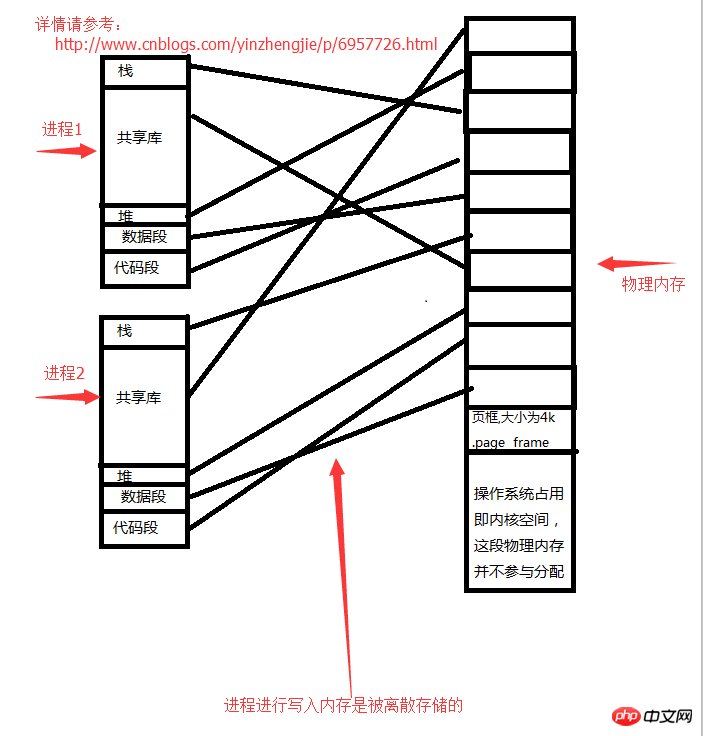
Wenn eine Anwendung die Funktion des Kernels anstelle der Funktion des Benutzerprogramms aufrufen muss, stellt die Anwendung fest, dass sie einen privilegierten Vorgang ausführen muss, und die Anwendung selbst verfügt nicht über diese Fähigkeit. Die Anwendung sendet eine Anwendung an den Kernel senden und den Kernel bei der Durchführung privilegierter Vorgänge unterstützen lassen. Der Kernel stellt fest, dass die Anwendung berechtigt ist, privilegierte Anweisungen zu verwenden. Der Kernel führt diese privilegierten Anweisungen aus und gibt die Ausführungsergebnisse an die Anwendung zurück. Anschließend fährt die Anwendung mit dem nachfolgenden Code fort, nachdem sie die Ausführungsergebnisse der privilegierten Anweisungen erhalten hat. Das ist ein Paradigmenwechsel.
Wenn ein Programmierer Ihr Programm produktiv machen möchte, sollte er daher versuchen, Ihren Code im Benutzerbereich auszuführen. Wenn der größte Teil Ihres Codes im Kernelbereich ausgeführt wird, wird Ihre Anwendung voraussichtlich nicht erfolgreich sein Bringt Ihnen nicht viel Produktivität. Weil wir wissen, dass der Kernel-Speicherplatz nicht für die Produktivität verantwortlich ist.
Erweitertes Wissen:
Wir wissen, dass die Bedienung eines Computers durch die Bedienung spezifiziert wird. Die Anweisungen werden außerdem in privilegierte und nicht privilegierte Befehlsebenen unterteilt. Freunde, die sich mit Computern auskennen, wissen vielleicht, dass die CPU-Architektur von X86 grob in vier Ebenen unterteilt ist. Es gibt vier Ringe von innen nach außen, die als Ring 0, Ring 1, Ring 2 und Ring 3 bezeichnet werden. Wir wissen, dass die Anweisungen in Ring 0 privilegierte Anweisungen und die Anweisungen in Ring 3 Benutzeranweisungen sind. Im Allgemeinen bezieht sich die privilegierte Befehlsebene auf die Bedienung der Hardware, die Steuerung des Busses usw.
Die Ausführung eines Programms erfordert die Koordination des Kernels, und es ist möglich, zwischen Benutzermodus und Kernelmodus zu wechseln. Daher muss die Ausführung eines Programms vom Kernel zur Ausführung geplant werden. Einige Anwendungen werden während des Betriebs des Betriebssystems ausgeführt, um grundlegende Funktionen auszuführen. Dies wird als Daemon-Prozess bezeichnet. Einige Programme werden jedoch nur ausgeführt, wenn der Benutzer sie benötigt. Wie benachrichtigen wir den Kernel, damit er die von uns benötigten Anwendungen ausführen kann? Zu diesem Zeitpunkt benötigen Sie einen Interpreter, der mit dem Betriebssystem umgehen und die Ausführung von Anweisungen veranlassen kann. Vereinfacht ausgedrückt bedeutet dies, dass die Ausführungsanforderung des Benutzers an den Kernel gesendet werden kann und der Kernel dann die für seinen Betrieb erforderlichen Grundbedingungen öffnen kann. Anschließend wird das Programm ausgeführt.
Verwandte Empfehlungen:
Verständnis von Threads im Betriebssystemwissen
CPU-Interrupts unter dem Linux-Betriebssystem
Ein Beispiel-Tutorial zur Sicherheitshärtung des Linux-Betriebssystems
Das obige ist der detaillierte Inhalt vonGrundprinzipien des Linux-Betriebssystems. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



