

So implementieren Sie das Parsen von CSS-Auswahlfeldern

Basierend auf den oben erlernten Grundkenntnissen der CSS-Syntax implementieren wir nun die Feldanalyse. Analysieren Sie zunächst den Titel. Öffnen Sie die Webentwicklertools und suchen Sie den Quellcode, der dem Titel entspricht. In diesem Artikel werden hauptsächlich relevante Informationen zur CSS-Selektor-Implementierung der Feldanalyse vorgestellt. Ich hoffe, dass er allen helfen kann der Knoten h1 unten, also habe ich die Scrapy-Shell zum Debuggen geöffnet
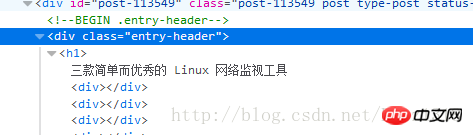
Aber was soll ich tun, wenn ich zu diesem Zeitpunkt kein Tag wie
möchte? Ich muss den Pseudocode in der CSS-Selektorklassenmethode verwenden. Wie unten gezeigt. p class="entry-header"


Verwandte Empfehlungen:
# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/113549/']
def parse(self, response):
# title = response.xpath('//p[@class = "entry-header"]/h1/text()').extract()[0]
# create_date = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
# praise_numbers = response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
# fav_nums = response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
# match_re = re.match(".*?(\d+).*",fav_nums)
# if match_re:
# fav_nums = match_re.group(1)
# comment_nums = response.xpath("//a[@href='#article-comment']/span").extract()[0]
# match_re = re.match(".*?(\d+).*", comment_nums)
# if match_re:
# comment_nums = match_re.group(1)
# content = response.xpath("//p[@class='entry']").extract()[0]
#通过CSS选择器提取字段
title = response.css(".entry-header h1::text").extract()[0]
create_date = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip()
praise_numbers = response.css(".vote-post-up h10::text").extract()[0]
fav_nums = response.css("span.bookmark-btn::text").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
content = response.css("p.entry").extract()[0]
tags = response.css("p.entry-meta-hide-on-mobile a::text").extract()[0]
pass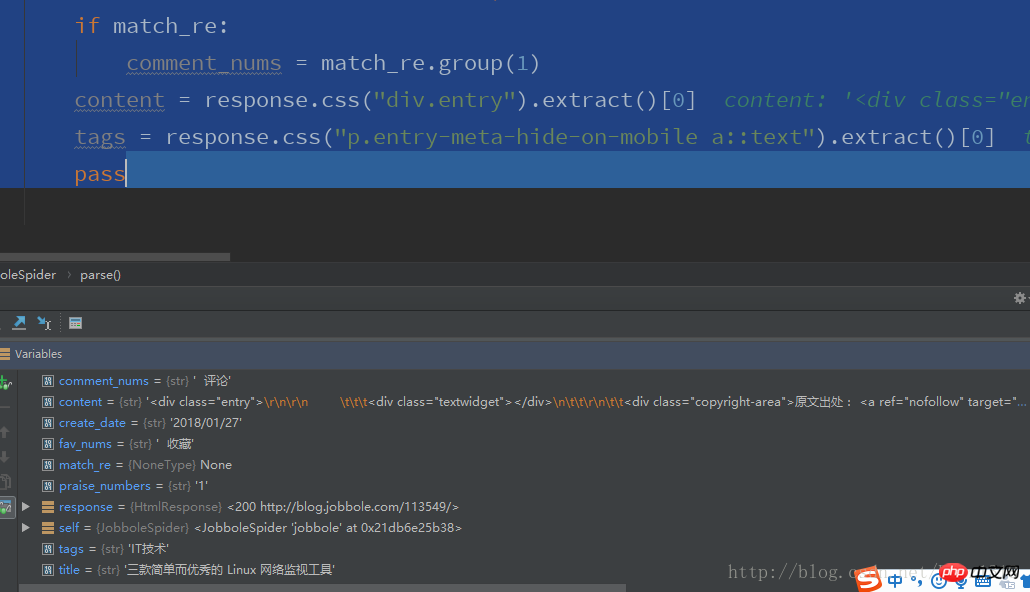 OpenERP-Mitarbeiter ( (Mitarbeiter)-Tabelle Parsen von Feldern, die mit Benutzertabellen verknüpft sind
OpenERP-Mitarbeiter ( (Mitarbeiter)-Tabelle Parsen von Feldern, die mit Benutzertabellen verknüpft sind
Das obige ist der detaillierte Inhalt vonSo implementieren Sie das Parsen von CSS-Auswahlfeldern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 So verwenden Sie Bootstrap in Vue
Apr 07, 2025 pm 11:33 PM
So verwenden Sie Bootstrap in Vue
Apr 07, 2025 pm 11:33 PM
Die Verwendung von Bootstrap in Vue.js ist in fünf Schritte unterteilt: Startstrap installieren. Bootstrap in main.js. Verwenden Sie die Bootstrap -Komponente direkt in der Vorlage. Optional: benutzerdefinierter Stil. Optional: Verwenden Sie Plug-Ins.
 Die Rollen von HTML, CSS und JavaScript: Kernverantwortung
Apr 08, 2025 pm 07:05 PM
Die Rollen von HTML, CSS und JavaScript: Kernverantwortung
Apr 08, 2025 pm 07:05 PM
HTML definiert die Webstruktur, CSS ist für Stil und Layout verantwortlich, und JavaScript ergibt eine dynamische Interaktion. Die drei erfüllen ihre Aufgaben in der Webentwicklung und erstellen gemeinsam eine farbenfrohe Website.
 So schreiben Sie geteilte Zeilen auf Bootstrap
Apr 07, 2025 pm 03:12 PM
So schreiben Sie geteilte Zeilen auf Bootstrap
Apr 07, 2025 pm 03:12 PM
Es gibt zwei Möglichkeiten, eine Bootstrap -Split -Zeile zu erstellen: Verwenden des Tags, das eine horizontale Split -Linie erstellt. Verwenden Sie die CSS -Border -Eigenschaft, um benutzerdefinierte Style Split -Linien zu erstellen.
 So fügen Sie Bilder auf Bootstrap ein
Apr 07, 2025 pm 03:30 PM
So fügen Sie Bilder auf Bootstrap ein
Apr 07, 2025 pm 03:30 PM
Es gibt verschiedene Möglichkeiten, Bilder in Bootstrap einzufügen: Bilder direkt mit dem HTML -IMG -Tag einfügen. Mit der Bootstrap -Bildkomponente können Sie reaktionsschnelle Bilder und weitere Stile bereitstellen. Legen Sie die Bildgröße fest und verwenden Sie die IMG-Fluid-Klasse, um das Bild anpassungsfähig zu machen. Stellen Sie den Rand mit der img-beliebten Klasse ein. Stellen Sie die abgerundeten Ecken ein und verwenden Sie die IMG-Rund-Klasse. Setzen Sie den Schatten, verwenden Sie die Schattenklasse. Größen Sie die Größe und positionieren Sie das Bild im CSS -Stil. Verwenden Sie mit dem Hintergrundbild die CSS-Eigenschaft im Hintergrund.
 So ändern Sie Bootstrap
Apr 07, 2025 pm 03:18 PM
So ändern Sie Bootstrap
Apr 07, 2025 pm 03:18 PM
Um die Größe der Elemente in Bootstrap anzupassen, können Sie die Dimensionsklasse verwenden, einschließlich: Einstellbreite:.
 So richten Sie das Framework für Bootstrap ein
Apr 07, 2025 pm 03:27 PM
So richten Sie das Framework für Bootstrap ein
Apr 07, 2025 pm 03:27 PM
Um das Bootstrap -Framework einzurichten, müssen Sie die folgenden Schritte befolgen: 1. Verweisen Sie die Bootstrap -Datei über CDN; 2. Laden Sie die Datei auf Ihrem eigenen Server herunter und hosten Sie sie. 3.. Fügen Sie die Bootstrap -Datei in HTML hinzu; 4. Kompilieren Sie Sass/weniger bei Bedarf; 5. Importieren Sie eine benutzerdefinierte Datei (optional). Sobald die Einrichtung abgeschlossen ist, können Sie die Grid -Systeme, -Komponenten und -stile von Bootstrap verwenden, um reaktionsschnelle Websites und Anwendungen zu erstellen.
 So verwenden Sie die Bootstrap -Taste
Apr 07, 2025 pm 03:09 PM
So verwenden Sie die Bootstrap -Taste
Apr 07, 2025 pm 03:09 PM
Wie benutze ich die Bootstrap -Taste? Führen Sie Bootstrap -CSS ein, um Schaltflächenelemente zu erstellen, und fügen Sie die Schaltfläche "Bootstrap" hinzu, um Schaltflächentext hinzuzufügen
 So sehen Sie das Datum der Bootstrap
Apr 07, 2025 pm 03:03 PM
So sehen Sie das Datum der Bootstrap
Apr 07, 2025 pm 03:03 PM
ANTWORT: Sie können die Datumsauswahlkomponente von Bootstrap verwenden, um Daten auf der Seite anzuzeigen. Schritte: Stellen Sie das Bootstrap -Framework ein. Erstellen Sie ein Eingangsfeld für Datumsauswahl in HTML. Bootstrap fügt dem Selektor automatisch Stile hinzu. Verwenden Sie JavaScript, um das ausgewählte Datum zu erhalten.
