

Detaillierte Analyse des Node-Timers

JavaScript läuft in einem einzelnen Thread und asynchrone Vorgänge sind besonders wichtig. Dieser Artikel führt Sie hauptsächlich in die relevanten Kenntnisse des Node-Timers ein. Solange Sie andere Funktionen als die Engine verwenden, müssen Sie mit der Außenwelt interagieren, um asynchrone Vorgänge zu bilden. Da es so viele asynchrone Vorgänge gibt, muss JavaScript viel asynchrone Syntax bereitstellen.
Die asynchrone Syntax von Node ist komplizierter als die eines Browsers, da sie mit dem Kernel kommunizieren kann und dafür eine spezielle Bibliothek libuv erstellt werden muss. Diese Bibliothek ist für die Ausführungszeit verschiedener Rückruffunktionen verantwortlich. Schließlich müssen asynchrone Aufgaben schließlich zum Hauptthread zurückkehren und einzeln zur Ausführung in die Warteschlange gestellt werden.

Um asynchrone Aufgaben zu koordinieren, stellt Node tatsächlich vier Timer bereit, sodass Aufgaben zu bestimmten Zeiten ausgeführt werden können.
setTimeout()
setInterval()
setImmediate()
process.nextTick()
Die ersten beiden sind Sprachstandards und die letzten beiden gelten nur für Node. Sie sind auf ähnliche Weise geschrieben und haben ähnliche Funktionen, daher ist es nicht einfach, sie zu unterscheiden.
Können Sie mir das Ergebnis der Ausführung des folgenden Codes mitteilen?
// test.js setTimeout(() => console.log(1)); setImmediate(() => console.log(2)); process.nextTick(() => console.log(3)); Promise.resolve().then(() => console.log(4)); (() => console.log(5))();
Die Laufergebnisse sind wie folgt.
$ node test.js
Wenn Sie es sofort bekommen, müssen Sie möglicherweise nicht mehr lesen. In diesem Artikel wird ausführlich erläutert, wie Node mit verschiedenen Timern umgeht, oder allgemeiner gesagt, wie die libuv-Bibliothek asynchrone Aufgaben anordnet, die im Hauptthread ausgeführt werden sollen.
1. Synchrone Aufgaben und asynchrone Aufgaben
Erstens werden synchrone Aufgaben immer früher ausgeführt als asynchrone Aufgaben.
Im vorherigen Codeteil ist nur die letzte Zeile eine Synchronisierungsaufgabe, daher wird sie am frühesten ausgeführt.
(() => console.log(5))();
2. Aktueller Zyklus und sekundärer Zyklus
Asynchrone Aufgaben können in zwei Typen unterteilt werden.
Asynchrone Aufgaben in diesem Zyklus hinzufügen
Asynchrone Aufgaben im zweiten Zyklus hinzufügen
Die sogenannte „Schleife“ bezieht sich auf die Ereignisschleife. Auf diese Weise verarbeitet die JavaScript-Engine asynchrone Aufgaben, was später ausführlich erläutert wird. Verstehen Sie hier nur, dass dieser Zyklus früher als der zweite Zyklus ausgeführt werden muss.
Knoten legt fest, dass die Rückruffunktionen von process.nextTick und Promise an diesen Zyklus angehängt werden, dh sobald die Synchronisierungsaufgaben abgeschlossen sind, werden sie ausgeführt. Die Rückruffunktionen setTimeout, setInterval und setImmediate werden im zweiten Zyklus hinzugefügt.
Das bedeutet, dass die dritte und vierte Zeile des Codes am Anfang des Artikels früher ausgeführt werden müssen als die erste und zweite Zeile.
// 下面两行,次轮循环执行 setTimeout(() => console.log(1)); setImmediate(() => console.log(2)); // 下面两行,本轮循环执行 process.nextTick(() => console.log(3)); Promise.resolve().then(() => console.log(4));
3. Process.nextTick()
Der Name Process.nextTick ist etwas irreführend und wird in diesem Zyklus ausgeführt und ist der schnellste unter allen asynchronen Aufgaben.

Nachdem der Knoten alle Synchronisierungsaufgaben ausgeführt hat, führt er die Aufgabenwarteschlange von process.nextTick aus. Die folgende Codezeile ist also die zweite Ausgabe.
process.nextTick(() => console.log(3));
Wenn Sie möchten, dass eine asynchrone Aufgabe so schnell wie möglich ausgeführt wird, verwenden Sie grundsätzlich „process.nextTick“.
4. Mikrotasks
Gemäß den Sprachspezifikationen wird die Rückruffunktion des Promise-Objekts in die „Mikrotask“-Warteschlange der asynchronen Aufgabe aufgenommen.
Die Mikrotask-Warteschlange wird an die Warteschlange „process.nextTick“ angehängt und gehört ebenfalls zu diesem Zyklus. Daher gibt der folgende Code immer zuerst 3 und dann 4 aus.
process.nextTick(() => console.log(3)); Promise.resolve().then(() => console.log(4)); // 3 // 4

Beachten Sie, dass die nächste Warteschlange erst ausgeführt wird, wenn die vorherige Warteschlange vollständig geleert ist.
process.nextTick(() => console.log(1)); Promise.resolve().then(() => console.log(2)); process.nextTick(() => console.log(3)); Promise.resolve().then(() => console.log(4)); // 1 // 3 // 2 // 4
Im obigen Code werden alle Process.nextTick-Rückruffunktionen früher als Promise ausgeführt.
An diesem Punkt ist die Ausführungssequenz dieses Zyklus abgeschlossen.
同步任务 process.nextTick() 微任务
5. Das Konzept der Ereignisschleife
Beginnen wir mit der Ausführungssequenz des zweiten Zyklus, der ein Verständnis dafür erfordert, was eine Ereignisschleife ist.
Zuerst denken einige Leute, dass es zusätzlich zum Hauptthread einen separaten Event-Loop-Thread gibt. Das ist nicht der Fall, es gibt nur einen Hauptthread und die Ereignisschleife wird im Hauptthread abgeschlossen.
Zweitens, wenn Node mit der Ausführung des Skripts beginnt, initialisiert er zuerst die Ereignisschleife, aber die Ereignisschleife hat noch nicht begonnen und die folgenden Dinge werden zuerst abgeschlossen.
Synchronisierungsaufgabe
Eine asynchrone Anfrage stellen
-
Planen Sie den Zeitpunkt, zu dem der Timer wirksam wird
Process.nextTick() usw. ausführen
Nachdem alle oben genannten Dinge erledigt sind, beginnt die Ereignisschleife offiziell.
6. Sechs Phasen der Ereignisschleife
Die Ereignisschleife wird Runde für Runde endlos ausgeführt. Die Ausführung wird erst beendet, wenn die Rückruffunktionswarteschlange der asynchronen Aufgabe gelöscht wird.
Jede Runde der Event-Schleife ist in sechs Phasen unterteilt. Diese Phasen werden nacheinander ausgeführt.
Timer
E/A-Rückrufe
inaktiv, vorbereiten
Abfrage
Prüfung
Rückrufe schließen
Jede Stufe hat eine Premiere -in, First-Out-Warteschlange von Rückruffunktionen. Erst wenn die Rückruffunktionswarteschlange einer Stufe geleert ist und alle auszuführenden Rückruffunktionen ausgeführt wurden, gelangt die Ereignisschleife in die nächste Stufe.
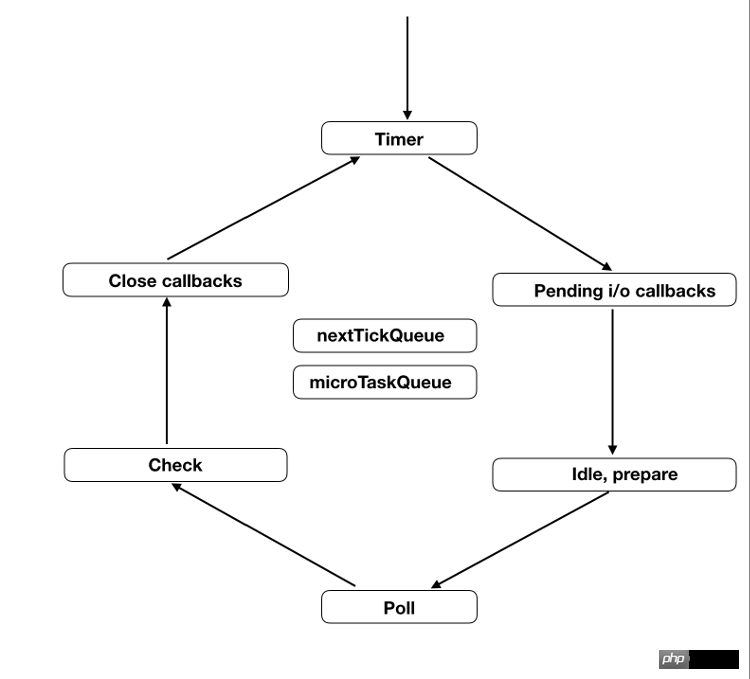
下面简单介绍一下每个阶段的含义,详细介绍可以看官方文档,也可以参考 libuv 的源码解读。
(1)timers
这个是定时器阶段,处理setTimeout()和setInterval()的回调函数。进入这个阶段后,主线程会检查一下当前时间,是否满足定时器的条件。如果满足就执行回调函数,否则就离开这个阶段。
(2)I/O callbacks
除了以下操作的回调函数,其他的回调函数都在这个阶段执行。
setTimeout()和setInterval()的回调函数
setImmediate()的回调函数
用于关闭请求的回调函数,比如socket.on('close', ...)
(3)idle, prepare
该阶段只供 libuv 内部调用,这里可以忽略。
(4)Poll
这个阶段是轮询时间,用于等待还未返回的 I/O 事件,比如服务器的回应、用户移动鼠标等等。
这个阶段的时间会比较长。如果没有其他异步任务要处理(比如到期的定时器),会一直停留在这个阶段,等待 I/O 请求返回结果。
(5)check
该阶段执行setImmediate()的回调函数。
(6)close callbacks
该阶段执行关闭请求的回调函数,比如socket.on('close', ...)。
七、事件循环的示例
下面是来自官方文档的一个示例。
const fs = require('fs');
const timeoutScheduled = Date.now();
// 异步任务一:100ms 后执行的定时器
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms`);
}, 100);
// 异步任务二:至少需要 200ms 的文件读取
fs.readFile('test.js', () => {
const startCallback = Date.now();
while (Date.now() - startCallback < 200) {
// 什么也不做
}
});上面代码有两个异步任务,一个是 100ms 后执行的定时器,一个是至少需要 200ms 的文件读取。请问运行结果是什么?
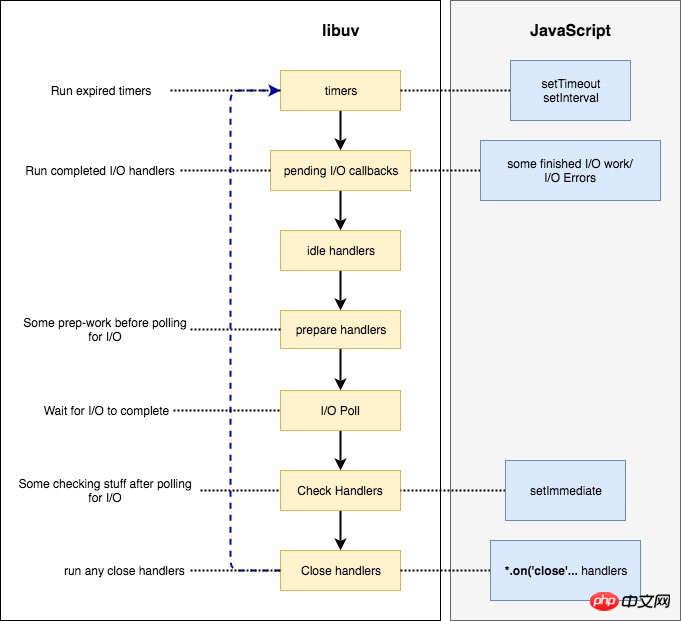
脚本进入第一轮事件循环以后,没有到期的定时器,也没有已经可以执行的 I/O 回调函数,所以会进入 Poll 阶段,等待内核返回文件读取的结果。由于读取小文件一般不会超过 100ms,所以在定时器到期之前,Poll 阶段就会得到结果,因此就会继续往下执行。
第二轮事件循环,依然没有到期的定时器,但是已经有了可以执行的 I/O 回调函数,所以会进入 I/O callbacks 阶段,执行fs.readFile的回调函数。这个回调函数需要 200ms,也就是说,在它执行到一半的时候,100ms 的定时器就会到期。但是,必须等到这个回调函数执行完,才会离开这个阶段。
第三轮事件循环,已经有了到期的定时器,所以会在 timers 阶段执行定时器。最后输出结果大概是200多毫秒。
八、setTimeout 和 setImmediate
由于setTimeout在 timers 阶段执行,而setImmediate在 check 阶段执行。所以,setTimeout会早于setImmediate完成。
setTimeout(() => console.log(1)); setImmediate(() => console.log(2));
上面代码应该先输出1,再输出2,但是实际执行的时候,结果却是不确定,有时还会先输出2,再输出1。
这是因为setTimeout的第二个参数默认为0。但是实际上,Node 做不到0毫秒,最少也需要1毫秒,根据官方文档,第二个参数的取值范围在1毫秒到2147483647毫秒之间。也就是说,setTimeout(f, 0)等同于setTimeout(f, 1)。
实际执行的时候,进入事件循环以后,有可能到了1毫秒,也可能还没到1毫秒,取决于系统当时的状况。如果没到1毫秒,那么 timers 阶段就会跳过,进入 check 阶段,先执行setImmediate的回调函数。
但是,下面的代码一定是先输出2,再输出1。
const fs = require('fs');
fs.readFile('test.js', () => {
setTimeout(() => console.log(1));
setImmediate(() => console.log(2));
});上面代码会先进入 I/O callbacks 阶段,然后是 check 阶段,最后才是 timers 阶段。因此,setImmediate才会早于setTimeout执行。
相关推荐:
Das obige ist der detaillierte Inhalt vonDetaillierte Analyse des Node-Timers. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Ein tiefer Einblick in die Bedeutung und Verwendung des HTTP-Statuscodes 460
Feb 18, 2024 pm 08:29 PM
Ein tiefer Einblick in die Bedeutung und Verwendung des HTTP-Statuscodes 460
Feb 18, 2024 pm 08:29 PM
Eingehende Analyse der Rolle und Anwendungsszenarien des HTTP-Statuscodes 460. Der HTTP-Statuscode ist ein sehr wichtiger Teil der Webentwicklung und wird verwendet, um den Kommunikationsstatus zwischen Client und Server anzuzeigen. Unter diesen ist der HTTP-Statuscode 460 ein relativ spezieller Statuscode. In diesem Artikel werden seine Rolle und Anwendungsszenarien eingehend analysiert. Definition des HTTP-Statuscodes 460 Die spezifische Definition des HTTP-Statuscodes 460 lautet „ClientClosedRequest“, was bedeutet, dass der Client die Anfrage schließt. Dieser Statuscode wird hauptsächlich zur Anzeige verwendet
 iBatis und MyBatis: Vergleich und Vorteilsanalyse
Feb 18, 2024 pm 01:53 PM
iBatis und MyBatis: Vergleich und Vorteilsanalyse
Feb 18, 2024 pm 01:53 PM
iBatis und MyBatis: Analyse der Unterschiede und Vorteile Einführung: In der Java-Entwicklung ist Persistenz eine häufige Anforderung, und iBatis und MyBatis sind zwei weit verbreitete Persistenz-Frameworks. Obwohl sie viele Gemeinsamkeiten aufweisen, gibt es auch einige wesentliche Unterschiede und Vorteile. Dieser Artikel vermittelt den Lesern ein umfassenderes Verständnis durch eine detaillierte Analyse der Funktionen, der Verwendung und des Beispielcodes dieser beiden Frameworks. 1. iBatis-Funktionen: iBatis ist ein älteres Persistenz-Framework, das SQL-Zuordnungsdateien verwendet.
 Ausführliche Erklärung des Oracle-Fehlers 3114: So beheben Sie ihn schnell
Mar 08, 2024 pm 02:42 PM
Ausführliche Erklärung des Oracle-Fehlers 3114: So beheben Sie ihn schnell
Mar 08, 2024 pm 02:42 PM
Ausführliche Erklärung des Oracle-Fehlers 3114: Um ihn schnell zu beheben, sind spezifische Codebeispiele erforderlich. Bei der Entwicklung und Verwaltung von Oracle-Datenbanken stoßen wir häufig auf verschiedene Fehler, unter denen Fehler 3114 ein relativ häufiges Problem ist. Fehler 3114 weist normalerweise auf ein Problem mit der Datenbankverbindung hin, das durch einen Netzwerkfehler, einen Stopp des Datenbankdienstes oder falsche Einstellungen der Verbindungszeichenfolge verursacht werden kann. In diesem Artikel wird die Ursache des Fehlers 3114 ausführlich erläutert und wie dieses Problem schnell gelöst werden kann. Außerdem wird der spezifische Code angehängt
 Analyse der neuen Funktionen von Win11: So überspringen Sie die Anmeldung bei einem Microsoft-Konto
Mar 27, 2024 pm 05:24 PM
Analyse der neuen Funktionen von Win11: So überspringen Sie die Anmeldung bei einem Microsoft-Konto
Mar 27, 2024 pm 05:24 PM
Analyse der neuen Funktionen von Win11: So überspringen Sie die Anmeldung bei einem Microsoft-Konto. Mit der Veröffentlichung von Windows 11 haben viele Benutzer festgestellt, dass es mehr Komfort und neue Funktionen bietet. Einige Benutzer möchten jedoch möglicherweise nicht, dass ihr System an ein Microsoft-Konto gebunden ist, und möchten diesen Schritt überspringen. In diesem Artikel werden einige Methoden vorgestellt, mit denen Benutzer die Anmeldung bei einem Microsoft-Konto in Windows 11 überspringen können, um ein privateres und autonomeres Erlebnis zu erreichen. Lassen Sie uns zunächst verstehen, warum einige Benutzer zögern, sich bei ihrem Microsoft-Konto anzumelden. Einerseits befürchten einige Benutzer, dass sie
 PI -Knotenunterricht: Was ist ein PI -Knoten? Wie installiere und richte ich einen PI -Knoten ein?
Mar 05, 2025 pm 05:57 PM
PI -Knotenunterricht: Was ist ein PI -Knoten? Wie installiere und richte ich einen PI -Knoten ein?
Mar 05, 2025 pm 05:57 PM
Detaillierte Erläuterungs- und Installationshandbuch für Pinetwork -Knoten In diesem Artikel wird das Pinetwork -Ökosystem im Detail vorgestellt - PI -Knoten, eine Schlüsselrolle im Pinetwork -Ökosystem und vollständige Schritte für die Installation und Konfiguration. Nach dem Start des Pinetwork -Blockchain -Testnetzes sind PI -Knoten zu einem wichtigen Bestandteil vieler Pioniere geworden, die aktiv an den Tests teilnehmen und sich auf die bevorstehende Hauptnetzwerkveröffentlichung vorbereiten. Wenn Sie Pinetwork noch nicht kennen, wenden Sie sich bitte an was Picoin ist? Was ist der Preis für die Auflistung? PI -Nutzung, Bergbau und Sicherheitsanalyse. Was ist Pinetwork? Das Pinetwork -Projekt begann 2019 und besitzt seine exklusive Kryptowährung PI -Münze. Das Projekt zielt darauf ab, eine zu erstellen, an der jeder teilnehmen kann
 Analyse der Bedeutung und Verwendung von Midpoint in PHP
Mar 27, 2024 pm 08:57 PM
Analyse der Bedeutung und Verwendung von Midpoint in PHP
Mar 27, 2024 pm 08:57 PM
[Analyse der Bedeutung und Verwendung von Mittelpunkt in PHP] In PHP ist Mittelpunkt (.) ein häufig verwendeter Operator, der zum Verbinden zweier Zeichenfolgen oder Eigenschaften oder Methoden von Objekten verwendet wird. In diesem Artikel befassen wir uns eingehend mit der Bedeutung und Verwendung von Mittelpunkten in PHP und veranschaulichen sie anhand konkreter Codebeispiele. 1. String-Mittelpunkt-Operator verbinden Die häufigste Verwendung in PHP ist das Verbinden zweier Strings. Indem Sie . zwischen zwei Saiten platzieren, können Sie diese zu einer neuen Saite zusammenfügen. $string1=&qu
 Apache2 kann PHP-Dateien nicht korrekt analysieren
Mar 08, 2024 am 11:09 AM
Apache2 kann PHP-Dateien nicht korrekt analysieren
Mar 08, 2024 am 11:09 AM
Aus Platzgründen folgt hier ein kurzer Artikel: Apache2 ist eine häufig verwendete Webserver-Software und PHP ist eine weit verbreitete serverseitige Skriptsprache. Beim Erstellen einer Website stößt man manchmal auf das Problem, dass Apache2 die PHP-Datei nicht korrekt analysieren kann, was dazu führt, dass der PHP-Code nicht ausgeführt werden kann. Dieses Problem wird normalerweise dadurch verursacht, dass Apache2 das PHP-Modul nicht richtig konfiguriert oder das PHP-Modul nicht mit der Version von Apache2 kompatibel ist. Im Allgemeinen gibt es zwei Möglichkeiten, dieses Problem zu lösen: Die eine ist
 Parsing Wormhole NTT: ein offenes Framework für jedes Token
Mar 05, 2024 pm 12:46 PM
Parsing Wormhole NTT: ein offenes Framework für jedes Token
Mar 05, 2024 pm 12:46 PM
Wormhole ist führend in der Blockchain-Interoperabilität und konzentriert sich auf die Schaffung robuster, zukunftssicherer dezentraler Systeme, bei denen Eigentum, Kontrolle und erlaubnislose Innovation im Vordergrund stehen. Die Grundlage dieser Vision ist das Bekenntnis zu technischem Fachwissen, ethischen Grundsätzen und Community-Ausrichtung, um die Interoperabilitätslandschaft mit Einfachheit, Klarheit und einer breiten Palette von Multi-Chain-Lösungen neu zu definieren. Mit dem Aufkommen wissensfreier Nachweise, Skalierungslösungen und funktionsreicher Token-Standards werden Blockchains immer leistungsfähiger und Interoperabilität wird immer wichtiger. In dieser innovativen Anwendungsumgebung eröffnen neuartige Governance-Systeme und praktische Funktionen beispiellose Möglichkeiten für Assets im gesamten Netzwerk. Protokollentwickler setzen sich nun mit der Frage auseinander, wie sie in dieser aufstrebenden Multi-Chain agieren sollen
