

Ich dachte immer, dass mein Vue gut sei, und ich dachte immer, dass das Webpack gut sei. Als ich heute Node im MOOC durchstöberte, wurde mir klar, dass ich immer noch weit hinterherhinkte. Wie wir alle wissen, basiert vue-cli auf Webpack und Webpack auf Node. Wenn Sie Node nicht kennen, wie können Sie Webpack verstehen? Deshalb habe ich mir die Frage gestellt, wie man Douban-Daten crawlt, die noch in den Kinderschuhen stecken. Heute werde ich kurz auf die von Douban gecrawlten Daten eingehen und sie auf Ihre eigene Weise auf einer anderen Seite darstellen.
1. Probleme, die gelöst werden müssen
Gebäudedienstleistungen
So bearbeiten Sie die gecrawlte Daten
So öffnen Sie automatisch den Standardbrowser
2. Gebäudedienstleistungen
Es Zum Erstellen von Diensten gibt es mehrere Möglichkeiten. Der Nachteil von http besteht jedoch darin, dass es keine URLs des https-Protokolls analysieren kann. Daher habe ich zum Parsen von URLs des https-Protokolls das Anforderungspaket verwendet. Doubans URL ist https,
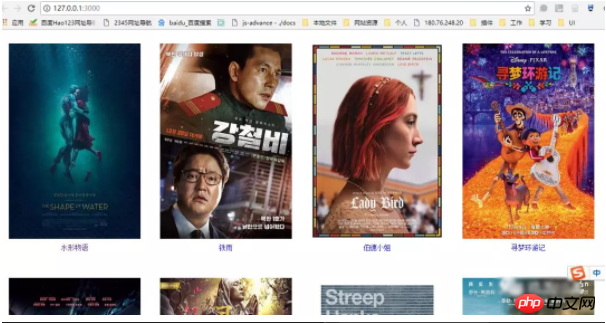
Heute habe ich die URL https://movie.douban.com/chart gecrawlt, wie unten gezeigt, es gibt drei Teile, die ich bekommen möchte, das Bild, den Filmnamen und den Filmlink.
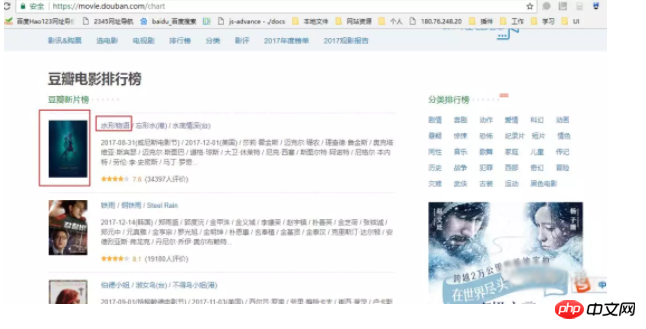

3. So verarbeiten Sie die gecrawlten Daten
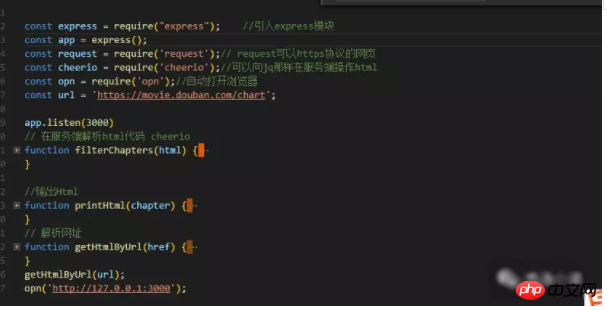
Wie zu verarbeiten die Daten, die wir mit Anfrage gecrawlt haben? Mit dem Cheerio-Paket können wir gecrawlte HTML-Daten wie Jq verarbeiten.
① Zuerst die Daten analysieren und die HTML-Daten der gecrawlten Webseite abrufen.
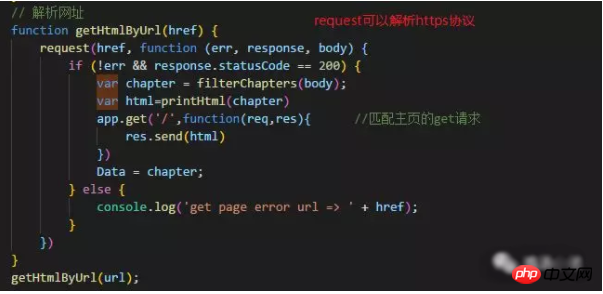
② und erhalten Sie die gewünschten Daten.
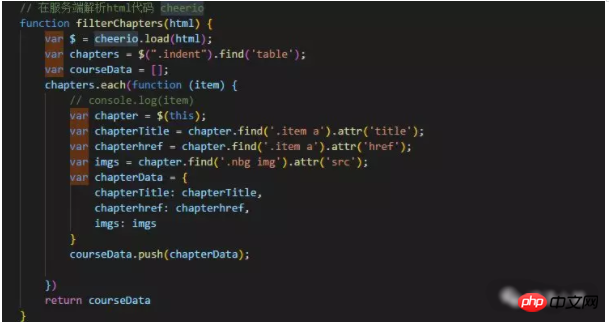
③ Holen Sie sich die Daten, erstellen Sie HTML und geben Sie es auf der Seite aus. Wie im Bild unten gezeigt, ist die von mir verwendete String-Splicing-Methode etwas dumm und ich habe noch keine bessere Methode gefunden.
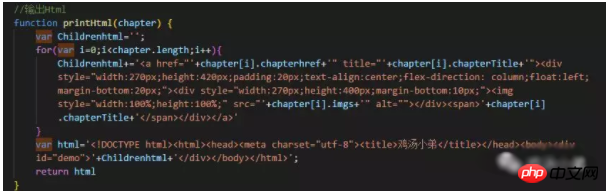
4. So öffnen Sie den Standardbrowser automatisch
Ich weiß nicht, ob Sie sich die Konfiguration von Webpack angesehen haben Öffnen Sie in vue-cli automatisch den Browser und verwenden Sie das opn-Paket für vue-cli.
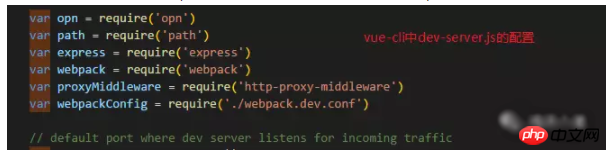
Dieses Paket ist sehr praktisch, um es zu verwenden. URL) direkt;
5. Anzeige
Verwandte Empfehlungen: 🎜>
So crawlen Sie PHP. Holen Sie sich Tmall- und Taobao-Produktdatennodejs implementiert die Funktion zum Crawlen von Website-Bildern_node.jsEmpfohlen Kurse zum Crawlen von Bildern 5 KapitelDas obige ist der detaillierte Inhalt vonBeispiel für die Art und Weise, wie Node.js Douban-Daten crawlt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



