

Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell

1. Einführung
Wenn wir Crawler-Programme zum Crawlen von Webseiten verwenden, ist das Crawlen statischer Seiten im Allgemeinen relativ einfach, und wir haben bereits viele Fälle geschrieben. Aber wie kann man mit js dynamisch geladene Seiten crawlen?
Es gibt mehrere Crawling-Methoden für dynamische JS-Seiten:
Erreicht durch Selenium+PhantomJS.
Phantomjs ist ein Headless-Browser, Selenium ist ein automatisiertes Testframework. Fordern Sie die Seite über den Headless-Browser an, warten Sie, bis js geladen ist, und erhalten Sie die Daten dann durch automatisierte Tests Selen. Da Headless-Browser viele Ressourcen verbrauchen, mangelt es ihnen an Leistung.
Scrapy-Splash-Framework:
Splash ist als JS-Rendering-Dienst leichtgewichtig und basiert auf Twisted und QT-Browser-Engine und bietet direkte http-API. Die schnellen und leichten Funktionen erleichtern die verteilte Entwicklung.
Die Crawler-Frameworks Splash und Scrapy sind miteinander kompatibel und weisen eine bessere Crawling-Effizienz auf.
2. Aufbau der Splash-Umgebung
Der Splash-Dienst basiert auf dem Docker-Container, daher müssen wir zuerst den Docker-Container installieren.
2.1 Docker-Installation (Windows 10 Home-Version)
Wenn es sich um eine Win 10 Professional-Version oder andere Betriebssysteme handelt, ist die Installation von Docker in der Windows 10 Home-Version einfacher Zur Verwendung der Toolbox müssen die neuesten Tools installiert werden.
Informationen zur Installation von Docker finden Sie in der Dokumentation: Docker unter WIN10 installieren
2.2 Splash-Installation
docker pull scrapinghub/splash
2.3 Starten des Splash-Dienstes
docker run -p 8050:8050 scrapinghub/splash
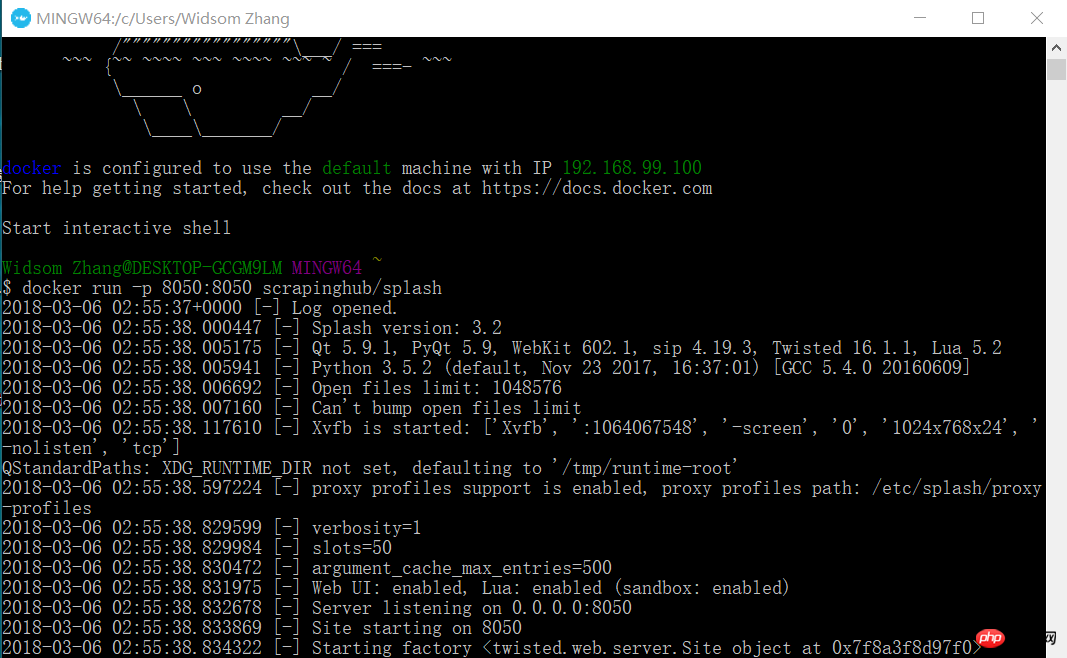
Öffnen Sie jetzt Ihren Browser und geben Sie 192.168.99.100:8050 ein. Sie sehen eine Schnittstelle wie diese.
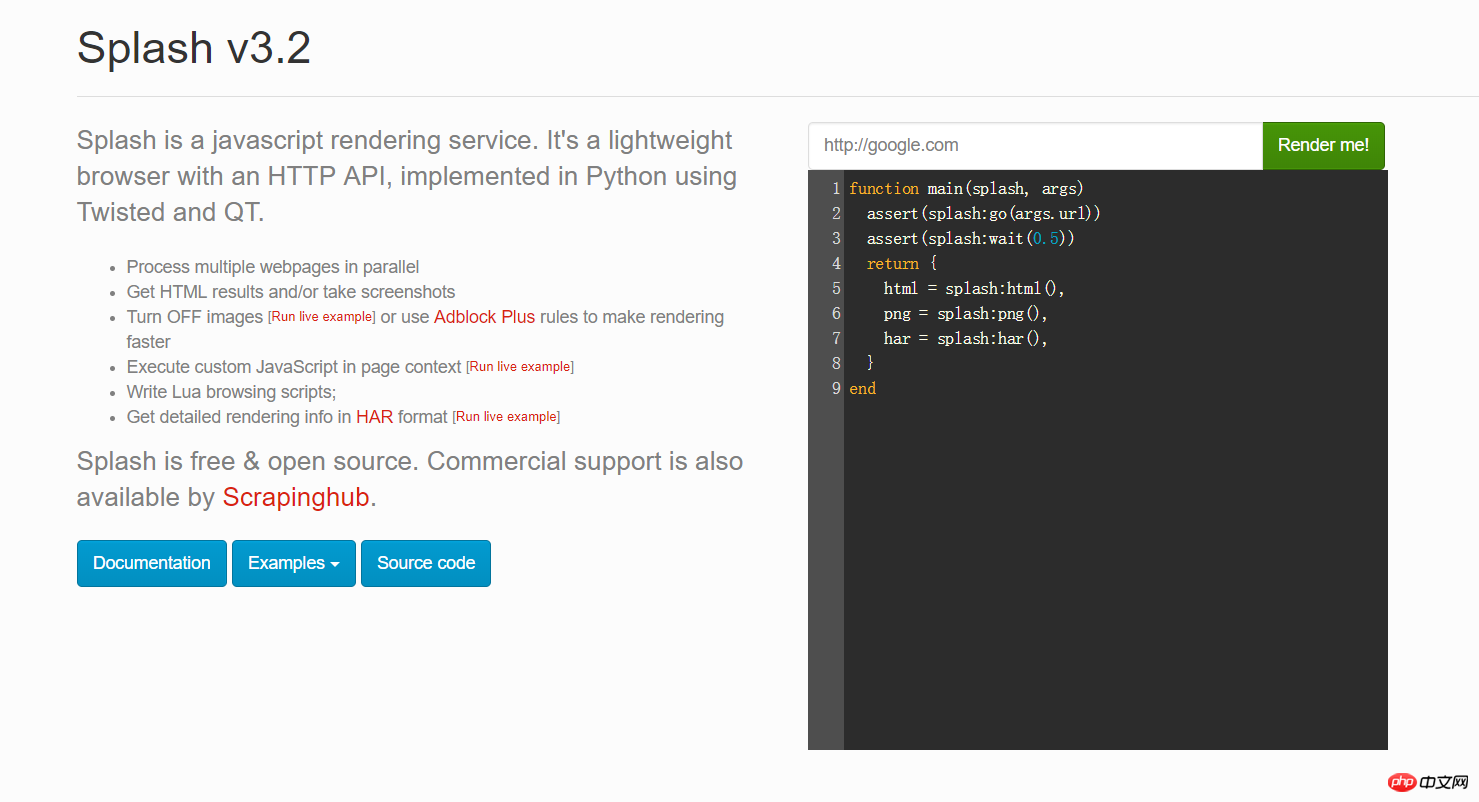
Sie können eine beliebige URL in das rote Feld im Bild oben eingeben und auf „Rendern“ klicken, um zu sehen, wie sie nach dem Rendern aussehen wird
2.4 Installieren Python Das Scrapy-Splash-Paket
pip install scrapy-splash
3. Der Scrapy-Crawler lädt den js-Projekttest am Beispiel von Google News.
Aus geschäftlichen Gründen crawlen wir einige ausländische Nachrichten-Websites, wie zum Beispiel Google News. Aber ich fand heraus, dass es sich tatsächlich um JS-Code handelte. Also begann ich, das Scrapy-Splash-Framework zu verwenden und mit dem js-Rendering-Dienst von Splash zusammenzuarbeiten, um Daten zu erhalten. Schauen Sie sich insbesondere den folgenden Code an:
3.1 Settings.py-Konfigurationsinformationen
# 渲染服务的urlSPLASH_URL = 'http://192.168.99.100:8050'# 去重过滤器DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'# 使用Splash的Http缓存HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}#下载器中间件DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}# 请求头DEFAULT_REQUEST_HEADERS = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
}# 管道ITEM_PIPELINES = { 'news.pipelines.NewsPipeline': 300,
}3.2 Elementfelddefinition
class NewsItem(scrapy.Item): # 标题
title = scrapy.Field() # 图片的url链接
Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell_url = scrapy.Field() # 新闻来源
source = scrapy.Field() # 点击的url
action_url = scrapy.Field()3.3 Spider-Code
Erstellen Sie im Spider-Verzeichnis eine Datei new_spider.py mit folgendem Inhalt:
from scrapy import Spiderfrom scrapy_splash import SplashRequestfrom news.items import NewsItemclass GoolgeNewsSpider(Spider):
name = "google_news"
start_urls = ["https://news.google.com/news/headlines?ned=cn&gl=CN&hl=zh-CN"] def start_requests(self):
for url in self.start_urls: # 通过SplashRequest请求等待1秒
yield SplashRequest(url, self.parse, args={'wait': 1}) def parse(self, response):
for element in response.xpath('//p[@class="qx0yFc"]'):
actionUrl = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/@href').extract_first()
title = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/text()').extract_first()
source = element.xpath('.//span[@class="IH8C7b Pc0Wt"]/text()').extract_first()
Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnellUrl = element.xpath('.//img[@class="lmFAjc"]/@src').extract_first()
item = NewsItem()
item['title'] = title
item['Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell_url'] = Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnellUrl
item['action_url'] = actionUrl
item['source'] = source yield item3.4 Pipelines.py-Code
Speichern Sie die Artikeldaten in der MySQL-Datenbank.
db_news-Datenbank erstellen
CREATE DATABASE db_news
tb_news-Tabelle erstellen
CREATE TABLE tb_google_news(
id INT AUTO_INCREMENT,
title VARCHAR(50),
Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell_url VARCHAR(200),
action_url VARCHAR(200),
source VARCHAR(30), PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8;NewsPipeline-Klasse
class NewsPipeline(object):
def __init__(self):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='root', db='db_news',charset='utf8')
self.cursor = self.conn.cursor() def process_item(self, item, spider):
sql = '''insert into tb_google_news (title,Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell_url,action_url,source) values(%s,%s,%s,%s)'''
self.cursor.execute(sql, (item["title"], item["Das Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell_url"], item["action_url"], item["source"]))
self.conn.commit() return item def close_spider(self):
self.cursor.close()
self.conn.close()3.5 Scrapy-Crawler ausführen
Auf der Konsole ausgeführt:
scrapy crawl google_news
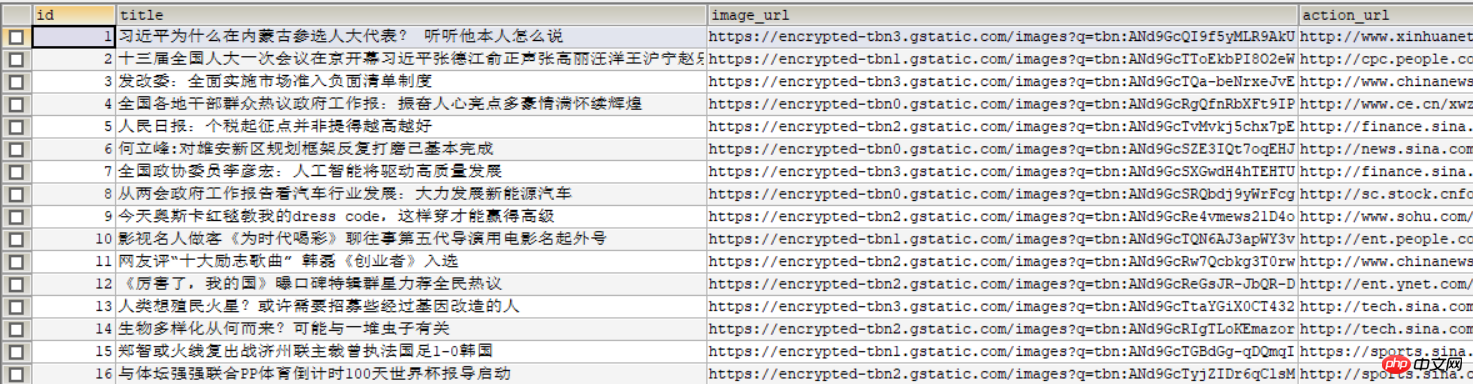
Das folgende Bild wird in der Datenbank angezeigt:
Verwandte Empfehlungen:
Grundlegende Einführung in Scrapy-Befehle
Einführung in das Scrapy-Crawler-Framework
Das obige ist der detaillierte Inhalt vonDas Scrapy- und Scrapy-Splash-Framework lädt JS-Seiten schnell. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So implementieren Sie ein Online-Spracherkennungssystem mit WebSocket und JavaScript
Dec 17, 2023 pm 02:54 PM
So implementieren Sie ein Online-Spracherkennungssystem mit WebSocket und JavaScript
Dec 17, 2023 pm 02:54 PM
So implementieren Sie mit WebSocket und JavaScript ein Online-Spracherkennungssystem. Einführung: Mit der kontinuierlichen Weiterentwicklung der Technologie ist die Spracherkennungstechnologie zu einem wichtigen Bestandteil des Bereichs der künstlichen Intelligenz geworden. Das auf WebSocket und JavaScript basierende Online-Spracherkennungssystem zeichnet sich durch geringe Latenz, Echtzeit und plattformübergreifende Eigenschaften aus und hat sich zu einer weit verbreiteten Lösung entwickelt. In diesem Artikel wird erläutert, wie Sie mit WebSocket und JavaScript ein Online-Spracherkennungssystem implementieren.
 WebSocket und JavaScript: Schlüsseltechnologien zur Implementierung von Echtzeitüberwachungssystemen
Dec 17, 2023 pm 05:30 PM
WebSocket und JavaScript: Schlüsseltechnologien zur Implementierung von Echtzeitüberwachungssystemen
Dec 17, 2023 pm 05:30 PM
WebSocket und JavaScript: Schlüsseltechnologien zur Realisierung von Echtzeit-Überwachungssystemen Einführung: Mit der rasanten Entwicklung der Internet-Technologie wurden Echtzeit-Überwachungssysteme in verschiedenen Bereichen weit verbreitet eingesetzt. Eine der Schlüsseltechnologien zur Erzielung einer Echtzeitüberwachung ist die Kombination von WebSocket und JavaScript. In diesem Artikel wird die Anwendung von WebSocket und JavaScript in Echtzeitüberwachungssystemen vorgestellt, Codebeispiele gegeben und deren Implementierungsprinzipien ausführlich erläutert. 1. WebSocket-Technologie
 Verwendung von JavaScript und WebSocket zur Implementierung eines Echtzeit-Online-Bestellsystems
Dec 17, 2023 pm 12:09 PM
Verwendung von JavaScript und WebSocket zur Implementierung eines Echtzeit-Online-Bestellsystems
Dec 17, 2023 pm 12:09 PM
Einführung in die Verwendung von JavaScript und WebSocket zur Implementierung eines Online-Bestellsystems in Echtzeit: Mit der Popularität des Internets und dem Fortschritt der Technologie haben immer mehr Restaurants damit begonnen, Online-Bestelldienste anzubieten. Um ein Echtzeit-Online-Bestellsystem zu implementieren, können wir JavaScript und WebSocket-Technologie verwenden. WebSocket ist ein Vollduplex-Kommunikationsprotokoll, das auf dem TCP-Protokoll basiert und eine bidirektionale Kommunikation zwischen Client und Server in Echtzeit realisieren kann. Im Echtzeit-Online-Bestellsystem, wenn der Benutzer Gerichte auswählt und eine Bestellung aufgibt
 So implementieren Sie ein Online-Reservierungssystem mit WebSocket und JavaScript
Dec 17, 2023 am 09:39 AM
So implementieren Sie ein Online-Reservierungssystem mit WebSocket und JavaScript
Dec 17, 2023 am 09:39 AM
So implementieren Sie ein Online-Reservierungssystem mit WebSocket und JavaScript. Im heutigen digitalen Zeitalter müssen immer mehr Unternehmen und Dienste Online-Reservierungsfunktionen bereitstellen. Es ist von entscheidender Bedeutung, ein effizientes Online-Reservierungssystem in Echtzeit zu implementieren. In diesem Artikel wird erläutert, wie Sie mit WebSocket und JavaScript ein Online-Reservierungssystem implementieren, und es werden spezifische Codebeispiele bereitgestellt. 1. Was ist WebSocket? WebSocket ist eine Vollduplex-Methode für eine einzelne TCP-Verbindung.
 JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems
Dec 17, 2023 pm 05:13 PM
JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems
Dec 17, 2023 pm 05:13 PM
JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems Einführung: Heutzutage ist die Genauigkeit von Wettervorhersagen für das tägliche Leben und die Entscheidungsfindung von großer Bedeutung. Mit der Weiterentwicklung der Technologie können wir genauere und zuverlässigere Wettervorhersagen liefern, indem wir Wetterdaten in Echtzeit erhalten. In diesem Artikel erfahren Sie, wie Sie mit JavaScript und WebSocket-Technologie ein effizientes Echtzeit-Wettervorhersagesystem aufbauen. In diesem Artikel wird der Implementierungsprozess anhand spezifischer Codebeispiele demonstriert. Wir
 Einfaches JavaScript-Tutorial: So erhalten Sie den HTTP-Statuscode
Jan 05, 2024 pm 06:08 PM
Einfaches JavaScript-Tutorial: So erhalten Sie den HTTP-Statuscode
Jan 05, 2024 pm 06:08 PM
JavaScript-Tutorial: So erhalten Sie HTTP-Statuscode. Es sind spezifische Codebeispiele erforderlich. Vorwort: Bei der Webentwicklung ist häufig die Dateninteraktion mit dem Server erforderlich. Bei der Kommunikation mit dem Server müssen wir häufig den zurückgegebenen HTTP-Statuscode abrufen, um festzustellen, ob der Vorgang erfolgreich ist, und die entsprechende Verarbeitung basierend auf verschiedenen Statuscodes durchführen. In diesem Artikel erfahren Sie, wie Sie mit JavaScript HTTP-Statuscodes abrufen und einige praktische Codebeispiele bereitstellen. Verwenden von XMLHttpRequest
 So verwenden Sie insertBefore in Javascript
Nov 24, 2023 am 11:56 AM
So verwenden Sie insertBefore in Javascript
Nov 24, 2023 am 11:56 AM
Verwendung: In JavaScript wird die Methode insertBefore() verwendet, um einen neuen Knoten in den DOM-Baum einzufügen. Diese Methode erfordert zwei Parameter: den neuen Knoten, der eingefügt werden soll, und den Referenzknoten (d. h. den Knoten, an dem der neue Knoten eingefügt wird).
 JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Bildverarbeitungssystems
Dec 17, 2023 am 08:41 AM
JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Bildverarbeitungssystems
Dec 17, 2023 am 08:41 AM
JavaScript ist eine in der Webentwicklung weit verbreitete Programmiersprache, während WebSocket ein Netzwerkprotokoll für die Echtzeitkommunikation ist. Durch die Kombination der leistungsstarken Funktionen beider können wir ein effizientes Echtzeit-Bildverarbeitungssystem erstellen. In diesem Artikel wird erläutert, wie dieses System mithilfe von JavaScript und WebSocket implementiert wird, und es werden spezifische Codebeispiele bereitgestellt. Zunächst müssen wir die Anforderungen und Ziele des Echtzeit-Bildverarbeitungssystems klären. Angenommen, wir haben ein Kameragerät, das Bilddaten in Echtzeit sammeln kann
