

So implementieren Sie einen Crawler in PHP

Verwenden Sie die Curl-Erweiterung von PHP, um Seitendaten abzurufen. Die Curl-Erweiterung von PHP ist eine von PHP unterstützte Bibliothek, die Ihnen die Verbindung und Kommunikation mit verschiedenen Servern über verschiedene Protokolltypen ermöglicht.
Dieses Programm erfasst Zhihu-Benutzerdaten. Um auf die persönliche Seite des Benutzers zugreifen zu können, muss der Benutzer vor dem Zugriff angemeldet sein. Wenn wir auf der Browserseite auf einen Benutzer-Avatar-Link klicken, um die persönliche Center-Seite des Benutzers aufzurufen, können wir die Informationen des Benutzers sehen, weil der Browser Ihnen beim Klicken auf den Link dabei hilft, die lokalen Cookies zusammenzubringen und zu senden auf eine neue Seite, sodass Sie die persönliche Center-Seite des Benutzers aufrufen können. Daher müssen Sie vor dem Zugriff auf die persönliche Seite die Cookie-Informationen des Benutzers abrufen und diese dann bei jeder Curl-Anfrage mitbringen. Um Cookie-Informationen zu erhalten, habe ich meine eigenen Cookies verwendet. Sie können Ihre eigenen Cookie-Informationen auf der Seite sehen:
Kopieren Sie sie einzeln in der Form „__utma=?;__utmb=?;“. Cookie-String. Dieser Cookie-String kann dann zum Versenden von Anfragen verwendet werden.
Anfangsbeispiel:
$url = 'http://www.zhihu.com/people/mora-hu/about'; //此处mora-hu代表用户ID $ch = curl_init($url); //初始化会话 curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_COOKIE, $this->config_arr['user_cookie']); //设置请求COOKIE curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //将curl_exec()获取的信息以文件流的形式返回,而不是直接输出。 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $result = curl_exec($ch); return $result; //抓取的结果Nach dem Login kopieren
Führen Sie den obigen Code aus, um die persönliche Center-Seite des mora-hu-Benutzers abzurufen. Mithilfe dieses Ergebnisses und der anschließenden Verarbeitung der Seite mithilfe regulärer Ausdrücke können Sie den Namen, das Geschlecht und andere Informationen erhalten, die Sie erfassen müssen.
Bild-Hotlink-Schutz
Bei der Ausgabe persönlicher Informationen nach der Regularisierung der zurückgegebenen Ergebnisse wurde festgestellt, dass der Avatar des Benutzers bei der Ausgabe auf der Seite nicht geöffnet werden konnte. Nachdem ich die Informationen überprüft hatte, fand ich heraus, dass es daran lag, dass Zhihu die Bilder vor Hotlinking geschützt hatte. Die Lösung besteht darin, beim Anfordern eines Bildes einen Verweis im Anforderungsheader zu fälschen.
Nachdem Sie den regulären Ausdruck verwendet haben, um den Link zum Bild zu erhalten, senden Sie eine weitere Anfrage. Geben Sie diesmal die Quelle der Bildanfrage an und geben Sie an, dass die Anfrage von der Zhihu-Website weitergeleitet wird. Konkrete Beispiele sind wie folgt:
function getImg($url, $u_id){ if (file_exists('./images/' . $u_id . ".jpg")) { return "images/$u_id" . '.jpg'; } if (empty($url)) { return ''; } $context_options = array( 'http' => array( 'header' => "Referer:http://www.zhihu.com"//带上referer参数 ) ); $context = stream_context_create($context_options); $img = file_get_contents('http:' . $url, FALSE, $context); file_put_contents('./images/' . $u_id . ".jpg", $img); return "images/$u_id" . '.jpg';}Nach dem Login kopieren
Mehr Benutzer crawlen
Die URLs verschiedener Benutzer sind fast gleich, der Unterschied liegt im Benutzernamen. Verwenden Sie den regulären Abgleich, um die Benutzernamenliste abzurufen, buchstabieren Sie die URLs einzeln und senden Sie dann die Anforderungen einzeln (einzeln ist natürlich langsamer, es gibt unten eine Lösung, die später besprochen wird). Wiederholen Sie nach dem Aufrufen der Seite des neuen Benutzers die obigen Schritte und fahren Sie in dieser Schleife fort, bis Sie die gewünschte Datenmenge erreicht haben.
Anzahl der Linux-Statistikdateien
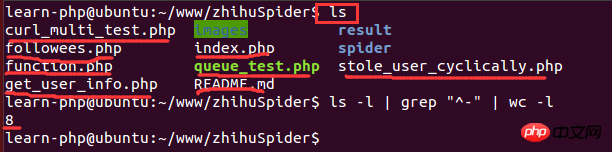
Nachdem das Skript eine Weile ausgeführt wurde, müssen Sie sehen, wie viele Bilder erhalten wurden. Wenn die Datenmenge relativ groß ist, ist es ein bisschen Öffnen Sie den Ordner langsam, um die Anzahl der Bilder zu überprüfen. Das Skript wird in der Linux-Umgebung ausgeführt, sodass Sie den Linux-Befehl verwenden können, um die Anzahl der Dateien zu zählen:
Unter diesen ist ls -l eine lange Listenausgabe der Dateiinformationen im Verzeichnis (die Dateien hier). kann Verzeichnisse, Links, Gerätedateien usw. sein); grep „^-“ filtert lange Listenausgabeinformationen, „^-“ behält nur allgemeine Dateien bei, wenn nur das Verzeichnis beibehalten wird, „^d“; Anzahl der Zeilen mit statistischen Ausgabeinformationen. Das Folgende ist ein laufendes Beispiel:
Umgang mit doppelten Daten beim Einfügen in MySQL
Nachdem das Programm eine Zeit lang ausgeführt wurde, wurde festgestellt, dass Die Daten vieler Benutzer wurden dupliziert, sodass sie beim Einfügen doppelter Benutzerdaten verarbeitet werden müssen. Die Lösung lautet wie folgt:
1) Überprüfen Sie, ob die Daten bereits in der Datenbank vorhanden sind, bevor Sie sie in die Datenbank einfügen.
2) Fügen Sie einen eindeutigen Index hinzu und verwenden Sie INSERT INTO. . ON DUPliCATE KEY UPDATE beim Einfügen..
3) Fügen Sie einen eindeutigen Index hinzu, verwenden Sie INSERT INGNO beim Einfügen
<br/>Nach dem Login kopierenRE INTO...<br/>
4) Fügen Sie beim Einfügen einen eindeutigen Index hinzu. Verwenden Sie REPLACE INTO...
Verwenden Sie curl_multi, um E/A-Multiplexing zum Erfassen von Seiten zu implementieren.
Zu Beginn ein einzelner Prozess und Die Geschwindigkeit war sehr langsam und der Crawling-Vorgang wurde unterbrochen. Nach einer Nacht konnte ich nur 2 W an Daten erfassen, sodass ich darüber nachdachte, ob ich bei der Eingabe eines neuen Benutzers mehrere Benutzer gleichzeitig anfordern könnte Seite und stellte eine Curl-Anfrage. Später entdeckte ich die gute Sache curl_multi. Funktionen wie „curl_multi“ können mehrere URLs gleichzeitig anfordern, anstatt sie einzeln anzufordern. Dies ist ein E/A-Multiplexmechanismus. Das Folgende ist ein Beispiel für die Verwendung des Curl_multi-Crawlers:
$mh = curl_multi_init(); //返回一个新cURL批处理句柄 for ($i = 0; $i < $max_size; $i++) { $ch = curl_init(); //初始化单个cURL会话 curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_URL, 'http://www.zhihu.com/people/' . $user_list[$i] . '/about'); curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie); curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $requestMap[$i] = $ch; curl_multi_add_handle($mh, $ch); //向curl批处理会话中添加单独的curl句柄 } $user_arr = array(); do { //运行当前 cURL 句柄的子连接 while (($cme = curl_multi_exec($mh, $active)) == CURLM_CALL_MULTI_PERFORM); if ($cme != CURLM_OK) {break;} //获取当前解析的cURL的相关传输信息 while ($done = curl_multi_info_read($mh)) { $info = curl_getinfo($done['handle']); $tmp_result = curl_multi_getcontent($done['handle']); $error = curl_error($done['handle']); $user_arr[] = array_values(getUserInfo($tmp_result)); //保证同时有$max_size个请求在处理 if ($i < sizeof($user_list) && isset($user_list[$i]) && $i < count($user_list)) { $ch = curl_init(); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_URL, 'http://www.zhihu.com/people/' . $user_list[$i] . '/about'); curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie); curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $requestMap[$i] = $ch; curl_multi_add_handle($mh, $ch); $i++; } curl_multi_remove_handle($mh, $done['handle']); } if ($active) curl_multi_select($mh, 10); } while ($active); curl_multi_close($mh); return $user_arr;Nach dem Login kopieren
HTTP 429 Too Many Requests
Mit der Funktion „curl_multi“ können mehrere Anfragen gleichzeitig gesendet werden. Aber während der Ausführung wurde beim gleichzeitigen Senden von 200 Anfragen festgestellt, dass viele Anfragen nicht zurückgegeben werden konnten, dh es wurde ein Paketverlust festgestellt. Verwenden Sie nach der weiteren Analyse die Funktion „curl_getinfo“, um die Informationen zu jedem Anforderungshandle zu drucken. Eines der Felder ist http_code, das den von der Anforderung zurückgegebenen HTTP-Statuscode darstellt. Ich habe gesehen, dass der http_code vieler Anfragen 429 war. Dieser Rückkehrcode bedeutet, dass zu viele Anfragen gesendet wurden. Ich vermutete, dass Zhihu einen Anti-Crawler-Schutz implementiert hatte, also habe ich ihn auf anderen Websites getestet und festgestellt, dass es beim gleichzeitigen Senden von 200 Anfragen kein Problem gab, was meine Vermutung bestätigte Die Anzahl der einmaligen Anfragen ist begrenzt. Also reduzierte ich die Anzahl der Anfragen weiter und stellte fest, dass es bei 5 keinen Paketverlust gab. Es zeigt, dass Sie in diesem Programm nur bis zu 5 Anfragen gleichzeitig senden können, obwohl es nicht viele sind, aber eine kleine Verbesserung.
使用Redis保存已经访问过的用户
抓取用户的过程中,发现有些用户是已经访问过的,而且他的关注者和关注了的用户都已经获取过了,虽然在数据库的层面做了重复数据的处理,但是程序还是会使用curl发请求,这样重复的发送请求就有很多重复的网络开销。还有一个就是待抓取的用户需要暂时保存在一个地方以便下一次执行,刚开始是放到数组里面,后来发现要在程序里添加多进程,在多进程编程里,子进程会共享程序代码、函数库,但是进程使用的变量与其他进程所使用的截然不同。不同进程之间的变量是分离的,不能被其他进程读取,所以是不能使用数组的。因此就想到了使用Redis缓存来保存已经处理好的用户以及待抓取的用户。这样每次执行完的时候都把用户push到一个already_request_queue队列中,把待抓取的用户(即每个用户的关注者和关注了的用户列表)push到request_queue里面,然后每次执行前都从request_queue里pop一个用户,然后判断是否在already_request_queue里面,如果在,则进行下一个,否则就继续执行。
在PHP中使用redis示例:
<?php $redis = new Redis(); $redis->connect('127.0.0.1', '6379'); $redis->set('tmp', 'value'); if ($redis->exists('tmp')) { echo $redis->get('tmp') . "\n"; }Nach dem Login kopieren
使用PHP的pcntl扩展实现多进程
改用了curl_multi函数实现多线程抓取用户信息之后,程序运行了一个晚上,最终得到的数据有10W。还不能达到自己的理想目标,于是便继续优化,后来发现php里面有一个pcntl扩展可以实现多进程编程。下面是多编程编程的示例:
//PHP多进程demo //fork10个进程 for ($i = 0; $i < 10; $i++) { $pid = pcntl_fork(); if ($pid == -1) { echo "Could not fork!\n"; exit(1); } if (!$pid) { echo "child process $i running\n"; //子进程执行完毕之后就退出,以免继续fork出新的子进程 exit($i); } } //等待子进程执行完毕,避免出现僵尸进程 while (pcntl_waitpid(0, $status) != -1) { $status = pcntl_wexitstatus($status); echo "Child $status completed\n"; }Nach dem Login kopieren
在linux下查看系统的cpu信息
实现了多进程编程之后,就想着多开几条进程不断地抓取用户的数据,后来开了8调进程跑了一个晚上后发现只能拿到20W的数据,没有多大的提升。于是查阅资料发现,根据系统优化的CPU性能调优,程序的最大进程数不能随便给的,要根据CPU的核数和来给,最大进程数最好是cpu核数的2倍。因此需要查看cpu的信息来看看cpu的核数。在linux下查看cpu的信息的命令:
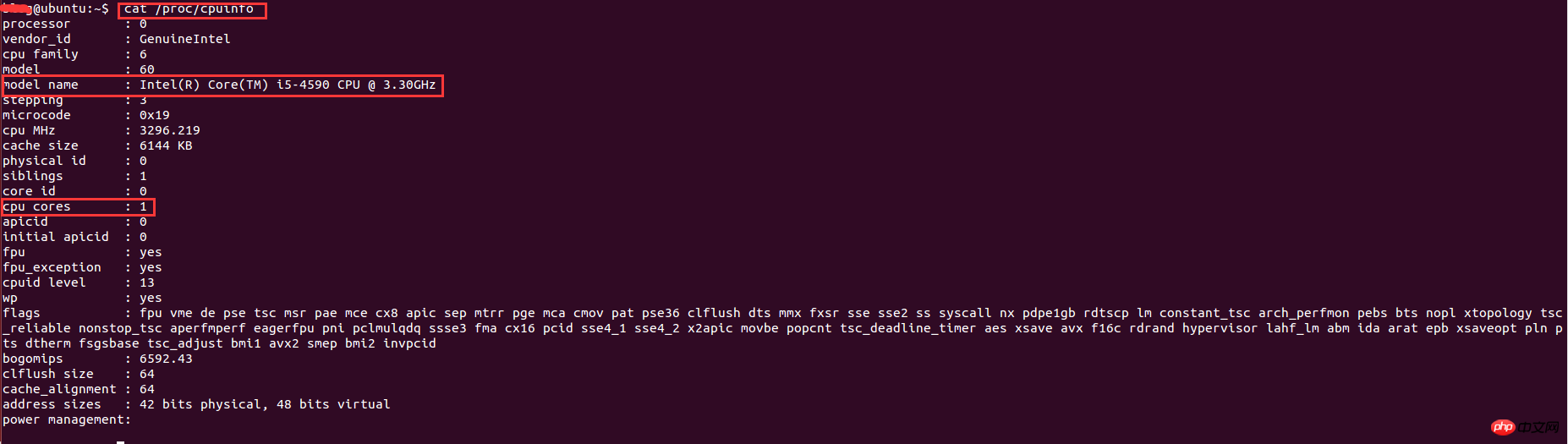
其中,model name表示cpu类型信息,cpu cores表示cpu核数。这里的核数是1,因为是在虚拟机下运行,分配到的cpu核数比较少,因此只能开2条进程。最终的结果是,用了一个周末就抓取了110万的用户数据。
多进程编程中Redis和MySQL连接问题
在多进程条件下,程序运行了一段时间后,发现数据不能插入到数据库,会报mysql too many connections的错误,redis也是如此。
下面这段代码会执行失败:
<?php for ($i = 0; $i < 10; $i++) { $pid = pcntl_fork(); if ($pid == -1) { echo "Could not fork!\n"; exit(1); } if (!$pid) { $redis = PRedis::getInstance(); // do something exit; } }Nach dem Login kopieren
根本原因是在各个子进程创建时,就已经继承了父进程一份完全一样的拷贝。对象可以拷贝,但是已创建的连接不能被拷贝成多个,由此产生的结果,就是各个进程都使用同一个redis连接,各干各的事,最终产生莫名其妙的冲突。
解决方法:
程序不能完全保证在fork进程之前,父进程不会创建redis连接实例。因此,要解决这个问题只能靠子进程本身了。试想一下,如果在子进程中获取的实例只与当前进程相关,那么这个问题就不存在了。于是解决方案就是稍微改造一下redis类实例化的静态方式,与当前进程ID绑定起来。
改造后的代码如下:
<?php public static function getInstance() { static $instances = array(); $key = getmypid();//获取当前进程ID if ($empty($instances[$key])) { $inctances[$key] = new self(); } return $instances[$key]; }Nach dem Login kopieren
PHP统计脚本执行时间
因为想知道每个进程花费的时间是多少,因此写个函数统计脚本执行时间:
function microtime_float() { list($u_sec, $sec) = explode(' ', microtime()); return (floatval($u_sec) + floatval($sec)); }$start_time = microtime_float(); //do somethingusleep(100);$end_time = microtime_float();$total_time = $end_time - $start_time;$time_cost = sprintf("%.10f", $total_time);echo "program cost total " . $time_cost . "s\n";Nach dem Login kopieren
若文中有不正确的地方,望各位指出以便改正。
相关推荐:
nodejs爬虫superagent和cheerio体验案例
Das obige ist der detaillierte Inhalt vonSo implementieren Sie einen Crawler in PHP. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1379
1379
 52
52

 PHP 8.4 Installations- und Upgrade-Anleitung für Ubuntu und Debian
Dec 24, 2024 pm 04:42 PM
PHP 8.4 Installations- und Upgrade-Anleitung für Ubuntu und Debian
Dec 24, 2024 pm 04:42 PM
PHP 8.4 bringt mehrere neue Funktionen, Sicherheitsverbesserungen und Leistungsverbesserungen mit einer beträchtlichen Menge an veralteten und entfernten Funktionen. In dieser Anleitung wird erklärt, wie Sie PHP 8.4 installieren oder auf PHP 8.4 auf Ubuntu, Debian oder deren Derivaten aktualisieren. Obwohl es möglich ist, PHP aus dem Quellcode zu kompilieren, ist die Installation aus einem APT-Repository wie unten erläutert oft schneller und sicherer, da diese Repositorys in Zukunft die neuesten Fehlerbehebungen und Sicherheitsupdates bereitstellen.
 So richten Sie Visual Studio-Code (VS-Code) für die PHP-Entwicklung ein
Dec 20, 2024 am 11:31 AM
So richten Sie Visual Studio-Code (VS-Code) für die PHP-Entwicklung ein
Dec 20, 2024 am 11:31 AM
Visual Studio Code, auch bekannt als VS Code, ist ein kostenloser Quellcode-Editor – oder eine integrierte Entwicklungsumgebung (IDE) –, die für alle gängigen Betriebssysteme verfügbar ist. Mit einer großen Sammlung von Erweiterungen für viele Programmiersprachen kann VS Code c
 7 PHP-Funktionen, die ich leider vorher nicht kannte
Nov 13, 2024 am 09:42 AM
7 PHP-Funktionen, die ich leider vorher nicht kannte
Nov 13, 2024 am 09:42 AM
Wenn Sie ein erfahrener PHP-Entwickler sind, haben Sie möglicherweise das Gefühl, dass Sie dort waren und dies bereits getan haben. Sie haben eine beträchtliche Anzahl von Anwendungen entwickelt, Millionen von Codezeilen debuggt und eine Reihe von Skripten optimiert, um op zu erreichen
 Wie analysiert und verarbeitet man HTML/XML in PHP?
Feb 07, 2025 am 11:57 AM
Wie analysiert und verarbeitet man HTML/XML in PHP?
Feb 07, 2025 am 11:57 AM
Dieses Tutorial zeigt, wie XML -Dokumente mit PHP effizient verarbeitet werden. XML (Extensible Markup-Sprache) ist eine vielseitige textbasierte Markup-Sprache, die sowohl für die Lesbarkeit des Menschen als auch für die Analyse von Maschinen entwickelt wurde. Es wird üblicherweise für die Datenspeicherung ein verwendet und wird häufig verwendet
 Erklären Sie JSON Web Tokens (JWT) und ihren Anwendungsfall in PHP -APIs.
Apr 05, 2025 am 12:04 AM
Erklären Sie JSON Web Tokens (JWT) und ihren Anwendungsfall in PHP -APIs.
Apr 05, 2025 am 12:04 AM
JWT ist ein offener Standard, der auf JSON basiert und zur sicheren Übertragung von Informationen zwischen Parteien verwendet wird, hauptsächlich für die Identitätsauthentifizierung und den Informationsaustausch. 1. JWT besteht aus drei Teilen: Header, Nutzlast und Signatur. 2. Das Arbeitsprinzip von JWT enthält drei Schritte: Generierung von JWT, Überprüfung von JWT und Parsingnayload. 3. Bei Verwendung von JWT zur Authentifizierung in PHP kann JWT generiert und überprüft werden, und die Funktionen und Berechtigungsinformationen der Benutzer können in die erweiterte Verwendung aufgenommen werden. 4. Häufige Fehler sind Signaturüberprüfungsfehler, Token -Ablauf und übergroße Nutzlast. Zu Debugging -Fähigkeiten gehört die Verwendung von Debugging -Tools und Protokollierung. 5. Leistungsoptimierung und Best Practices umfassen die Verwendung geeigneter Signaturalgorithmen, das Einstellen von Gültigkeitsperioden angemessen.
 PHP -Programm zum Zählen von Vokalen in einer Zeichenfolge
Feb 07, 2025 pm 12:12 PM
PHP -Programm zum Zählen von Vokalen in einer Zeichenfolge
Feb 07, 2025 pm 12:12 PM
Eine Zeichenfolge ist eine Folge von Zeichen, einschließlich Buchstaben, Zahlen und Symbolen. In diesem Tutorial wird lernen, wie Sie die Anzahl der Vokale in einer bestimmten Zeichenfolge in PHP unter Verwendung verschiedener Methoden berechnen. Die Vokale auf Englisch sind a, e, i, o, u und sie können Großbuchstaben oder Kleinbuchstaben sein. Was ist ein Vokal? Vokale sind alphabetische Zeichen, die eine spezifische Aussprache darstellen. Es gibt fünf Vokale in Englisch, einschließlich Großbuchstaben und Kleinbuchstaben: a, e, ich, o, u Beispiel 1 Eingabe: String = "TutorialPoint" Ausgabe: 6 erklären Die Vokale in der String "TutorialPoint" sind u, o, i, a, o, ich. Insgesamt gibt es 6 Yuan
 Erklären Sie die späte statische Bindung in PHP (statisch: :).
Apr 03, 2025 am 12:04 AM
Erklären Sie die späte statische Bindung in PHP (statisch: :).
Apr 03, 2025 am 12:04 AM
Statische Bindung (statisch: :) implementiert die späte statische Bindung (LSB) in PHP, sodass das Aufrufen von Klassen in statischen Kontexten anstatt Klassen zu definieren. 1) Der Analyseprozess wird zur Laufzeit durchgeführt.
 Was sind PHP Magic -Methoden (__construct, __Destruct, __call, __get, __set usw.) und geben Sie Anwendungsfälle an?
Apr 03, 2025 am 12:03 AM
Was sind PHP Magic -Methoden (__construct, __Destruct, __call, __get, __set usw.) und geben Sie Anwendungsfälle an?
Apr 03, 2025 am 12:03 AM
Was sind die magischen Methoden von PHP? Zu den magischen Methoden von PHP gehören: 1. \ _ \ _ Konstrukt, verwendet, um Objekte zu initialisieren; 2. \ _ \ _ Destruct, verwendet zur Reinigung von Ressourcen; 3. \ _ \ _ Call, behandeln Sie nicht existierende Methodenaufrufe; 4. \ _ \ _ GET, Implementieren Sie den dynamischen Attributzugriff; 5. \ _ \ _ Setzen Sie dynamische Attributeinstellungen. Diese Methoden werden in bestimmten Situationen automatisch aufgerufen, wodurch die Code -Flexibilität und -Effizienz verbessert werden.
