

Manchmal durchsuchen wir aufgrund der Arbeit und unserer eigenen Bedürfnisse verschiedene Websites, um die Daten zu erhalten, die wir benötigen. Daher sind Crawler entstanden. Im Folgenden wird der Prozess der Entwicklung eines einfachen Crawlers und die aufgetretenen Probleme beschrieben. Um einen Crawler zu entwickeln, müssen Sie zunächst wissen, wofür Ihr Crawler verwendet werden soll. Ich möchte damit Artikel mit bestimmten Schlüsselwörtern auf verschiedenen Websites finden und deren Links erhalten, damit ich sie schnell lesen kann.
Je nach persönlichen Gewohnheiten muss ich zunächst eine Schnittstelle schreiben und meine Ideen klären.
1. Besuchen Sie verschiedene Websites. Dann brauchen wir ein URL-Eingabefeld.
2. Finden Sie Artikel mit bestimmten Schlüsselwörtern. Dann benötigen wir ein Eingabefeld für den Artikeltitel.
3. Holen Sie sich den Artikellink. Dann benötigen wir einen Anzeigecontainer für Suchergebnisse.
[xhtml] view plain copy
<p class="jumbotron" id="mainJumbotron">
<p class="panel panel-default">
<p class="panel-heading">文章URL抓取</p>
<p class="panel-body">
<p class="form-group">
<label for="article_title">文章标题</label>
<input type="text" class="form-control" id="article_title" placeholder="文章标题">
</p>
<p class="form-group">
<label for="website_url">网站URL</label>
<input type="text" class="form-control" id="website_url" placeholder="网站URL">
</p>
<button type="submit" class="btn btn-default">抓取</button>
</p>
</p>
<p class="panel panel-default">
<p class="panel-heading">文章URL</p>
<p class="panel-body">
<h3></h3>
</p>
</p>
</p>Fügen Sie den Code direkt hinzu und fügen Sie dann einige eigene Stilanpassungen hinzu, und die Schnittstelle ist fertig:
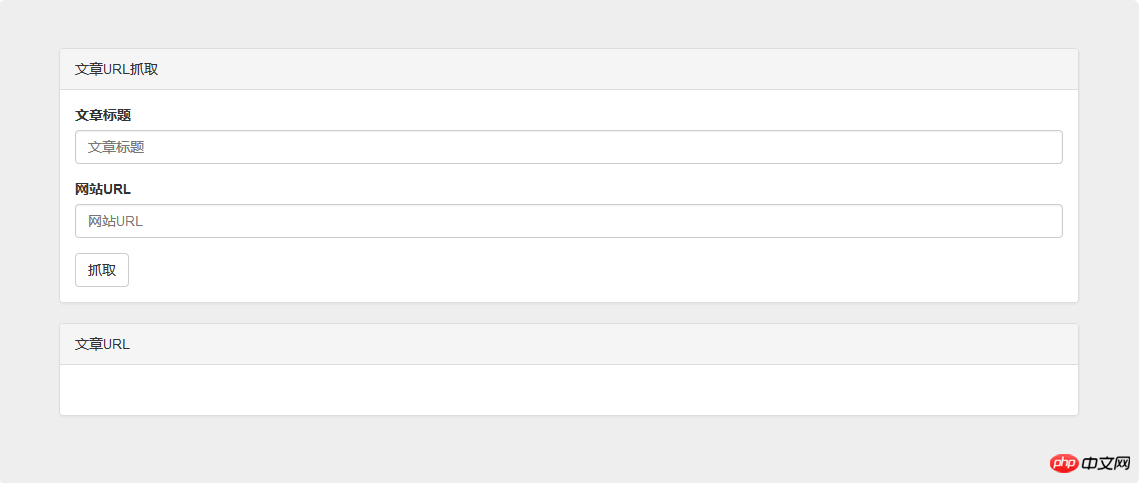
Dann die Der nächste Schritt ist die Implementierung der Funktion. Der erste Schritt besteht darin, den HTML-Code abzurufen. Ich werde sie hier nicht einzeln vorstellen Ich verwende Curl, um es zu erhalten. Geben Sie einfach die URL der Website ein:
[xhtml] view plain copy
private function get_html($url){
$ch = curl_init();
$timeout = 10;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36');
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$html = curl_exec($ch);
return $html;
}Obwohl Sie den HTML-Code erhalten haben, werden Sie bald auf ein Problem stoßen, nämlich auf das Codierungsproblem Möglicherweise ist Ihr nächster Schritt des Abgleichs vergeblich. Hier vereinheitlichen wir den erhaltenen HTML-Inhalt in der UTF8-Codierung:
[php] view plain copy $coding = mb_detect_encoding($html); if ($coding != "UTF-8" || !mb_check_encoding($html, "UTF-8")) $html = mb_convert_encoding($html, 'utf-8', 'GBK,UTF-8,ASCII');
Um die URL des Artikels zu erhalten, ist der nächste Schritt Um alle A-Tags unter der Webseite abzugleichen, ist die Verwendung regulärer Ausdrücke erforderlich. Nach vielen Tests haben wir endlich einen relativ zuverlässigen regulären Ausdruck erhalten. Egal wie komplex die Struktur unter dem A-Tag ist, wir werden es nicht zulassen go, solange es sich um ein Tag handelt: (Der kritischste Schritt)
[php] view plain copy $pattern = '|<a[^>]*>(.*)</a>|isU'; preg_match_all($pattern, $html, $matches);
Das Matching-Ergebnis liegt in $matches, bei dem es sich wahrscheinlich um eine mehrdimensionale Elementgruppe wie diese handelt
[js] view plain copy
array(2) {
[0]=>
array(*) {
[0]=>
string(*) "完整的a标签"
.
.
.
}
[1]=>
array(*) {
[0]=>
string(*) "与上面下标相对应的a标签中的内容"
}
}Solange Sie diese Daten abrufen können, ist alles andere vollständig bedienbar. Sie können diese Elementgruppe durchlaufen, um Ihr a-Tag zu finden, und dann die entsprechenden Attribute des a-Tags abrufen Hier ist eine Klasse, die Ihnen die Bedienung des a-Tags erleichtert:
[php] view plain copy
$dom = new DOMDocument();
@$dom->loadHTML($a);//$a是上面得到的一些a标签
$url = new DOMXPath($dom);
$hrefs = $url->evaluate('//a');
for ($i = 0; $i < $hrefs->length; $i++) {
$href = $hrefs->item($i);
$url = $href->getAttribute('href'); //这里获取a标签的href属性
}Natürlich ist dies nur eine Möglichkeit, Sie können auch reguläre Ausdrücke verwenden, um die gewünschten Informationen abzugleichen und neue Tricks mit den Daten spielen.
得到并匹配得出你想要的结果,下一步当然就是传回前端将他们显示出来啦,把接口写好,然后前端用js获取数据,用jquery动态添加内容显示出来:
[php] view plain copy
var website_url = '你的接口地址';
$.getJSON(website_url,function(data){
if(data){
if(data.text == ''){
$('#article_url').html('<p><p>暂无该文章链接</p></p>');
return;
}
var string = '';
var list = data.text;
for (var j in list) {
var content = list[j].url_content;
for (var i in content) {
if (content[i].title != '') {
string += '<p class="item">' +
'<em>[<a href="http://' + list[j].website.web_url + '" target="_blank">' + list[j].website.web_name + '</a>]</em>' +
'<a href=" ' + content[i].url + '" target="_blank" class="web_url">' + content[i].title + '</a>' +
'</p>';
}
}
}
$('#article_url').html(string);
});上最终效果图:
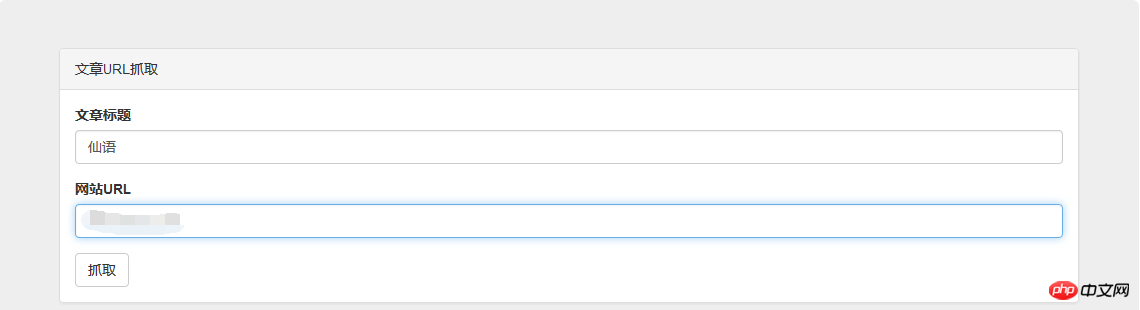

Das obige ist der detaillierte Inhalt vonSo entwickeln Sie einen einfachen Crawler mit PHP. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So öffnen Sie eine PHP-Datei
So öffnen Sie eine PHP-Datei
 Nodejs implementiert Crawler
Nodejs implementiert Crawler
 So entfernen Sie die ersten paar Elemente eines Arrays in PHP
So entfernen Sie die ersten paar Elemente eines Arrays in PHP
 Was tun, wenn die PHP-Deserialisierung fehlschlägt?
Was tun, wenn die PHP-Deserialisierung fehlschlägt?
 So verbinden Sie PHP mit der MSSQL-Datenbank
So verbinden Sie PHP mit der MSSQL-Datenbank
 So verbinden Sie PHP mit der MSSQL-Datenbank
So verbinden Sie PHP mit der MSSQL-Datenbank
 So laden Sie HTML hoch
So laden Sie HTML hoch
 So lösen Sie verstümmelte Zeichen in PHP
So lösen Sie verstümmelte Zeichen in PHP








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



