

NodeJS-Crawler-Framework-Superagent
Dieses Mal präsentiere ich Ihnen den NodeJS-Crawler-Framework-Superagent. Was sind die Vorsichtsmaßnahmen für den NodeJS-Crawler-Framework-Superagent?
Vorwort
Ich habe in den letzten Tagen angefangen, NodeJS zu lernen und einen Crawler geschriebenhttps://github.com/leichangchun/node-crawlers/tree/master/superagent_cheerio_demo, crawlen Sie den Artikeltitel, den Benutzernamen, die Anzahl der Lesevorgänge, die Anzahl der Empfehlungen und den Benutzeravatar auf der Homepage des Blogparks , und machen Sie nun eine kurze Zusammenfassung.
Verwenden Sie diese Punkte:
1. Das Kernmodul des Knotens – Dateisystem
2. Von Drittanbietern für HTTP-Anfragen verwendetes Modul – Superagent
3. Drittanbietermodul zum Parsen von DOM – cheerio
Detaillierte Erklärungen und APIs verschiedener Module finden Sie unter den einzelnen Links. In der Demo sind nur einfache Verwendungen aufgeführt.
Verwenden Sie npm, um Abhängigkeiten zu verwalten, und Abhängigkeitsinformationen werden in package.json gespeichert
//安装用到的第三方模块 cnpm install --save superagent cheerio
Stellen Sie die erforderlichen Funktionsmodule vor
//引入第三方模块,superagent用于http请求,cheerio用于解析DOM
const request = require('superagent');
const cheerio = require('cheerio');
const fs = require('fs');Seite anfordern + analysieren
Möchten Sie zum Bloggarten aufsteigen? Für den Inhalt der Homepage müssen Sie zuerst die Homepage-Adresse anfordern und den zurückgegebenen HTML-Code abrufen. Hier wird Superagent verwendet, um http-Anfragen auszuführen. Die grundlegende Verwendungsmethode ist wie folgt:
request.get(url)
.end(error,res){
//do something
}Initiieren Sie eine Get-Anfrage an die angegebene URL. Wenn die Anfrage falsch ist, wird ein Fehler zurückgegeben (wenn kein Fehler vorliegt, ist der Fehler null oder undefiniert) und res sind die zurückgegebenen Daten.
Nachdem wir den HTML-Inhalt erhalten haben, müssen wir Cheerio zum Parsen des DOM verwenden. Cheerio muss zuerst den Ziel-HTML-Inhalt laden und ihn dann analysieren. Die API ist der JQuery sehr ähnlich API. Ich bin mit JQuery vertraut und kann sehr schnell loslegen. Schauen Sie sich direkt das Codebeispiel an
//目标链接 博客园首页
let targetUrl = 'https://www.cnblogs.com/';
//用来暂时保存解析到的内容和图片地址数据
let content = '';
let imgs = [];
//发起请求
request.get(targetUrl)
.end( (error,res) => {
if(error){ //请求出错,打印错误,返回
console.log(error)
return;
}
// cheerio需要先load html
let $ = cheerio.load(res.text);
//抓取需要的数据,each为cheerio提供的方法用来遍历
$('#post_list .post_item').each( (index,element) => {
//分析所需要的数据的DOM结构
//通过选择器定位到目标元素,再获取到数据
let temp = {
'标题' : $(element).find('h3 a').text(),
'作者' : $(element).find('.post_item_foot > a').text(),
'阅读数' : +$(element).find('.article_view a').text().slice(3,-2),
'推荐数' : +$(element).find('.diggnum').text()
}
//拼接数据
content += JSON.stringify(temp) + '\n';
//同样的方式获取图片地址
if($(element).find('img.pfs').length > 0){
imgs.push($(element).find('img.pfs').attr('src'));
}
});
//存放数据
mkdir('./content',saveContent);
mkdir('./imgs',downloadImg);
})Speicherdaten
Nach dem Parsen des obigen DOM wurde der erforderliche Informationsinhalt gespleißt und abgerufen. Die URL des Bildes wird jetzt gespeichert, der Inhalt wird in einer TXT-Datei im angegebenen Verzeichnis gespeichert und das Bild wird in das angegebene Verzeichnis heruntergeladen
Erstellen Sie zuerst das Verzeichnis und verwenden Sie die NodeJS-Kerndatei System
//创建目录
function mkdir(_path,callback){
if(fs.existsSync(_path)){
console.log(`${_path}目录已存在`)
}else{
fs.mkdir(_path,(error)=>{
if(error){
return console.log(`创建${_path}目录失败`);
}
console.log(`创建${_path}目录成功`)
})
}
callback(); //没有生成指定目录不会执行
}Nachdem Sie das angegebene Verzeichnis haben, können Sie die Daten bereits dort schreiben. Verwenden Sie writeFile()
//将文字内容存入txt文件中
function saveContent() {
fs.writeFile('./content/content.txt',content.toString());
}Um den Link zum Bild zu erhalten, müssen Sie ihn erneut verwenden. Superagent lädt Bilder herunter und speichert sie lokal. Superagent kann direkt einen Antwortstrom zurückgeben und dann mit der NodeJS-Pipeline zusammenarbeiten, um den Bildinhalt direkt in den lokalen
//下载爬到的图片
function downloadImg() {
imgs.forEach((imgUrl,index) => {
//获取图片名
let imgName = imgUrl.split('/').pop();
//下载图片存放到指定目录
let stream = fs.createWriteStream(`./imgs/${imgName}`);
let req = request.get('https:' + imgUrl); //响应流
req.pipe(stream);
console.log(`开始下载图片 https:${imgUrl} --> ./imgs/${imgName}`);
} )
}Effekt
zu schreiben. Führen Sie die Demo aus und sehen Sie sich den Effekt an wurde normal nach unten gecrawlt
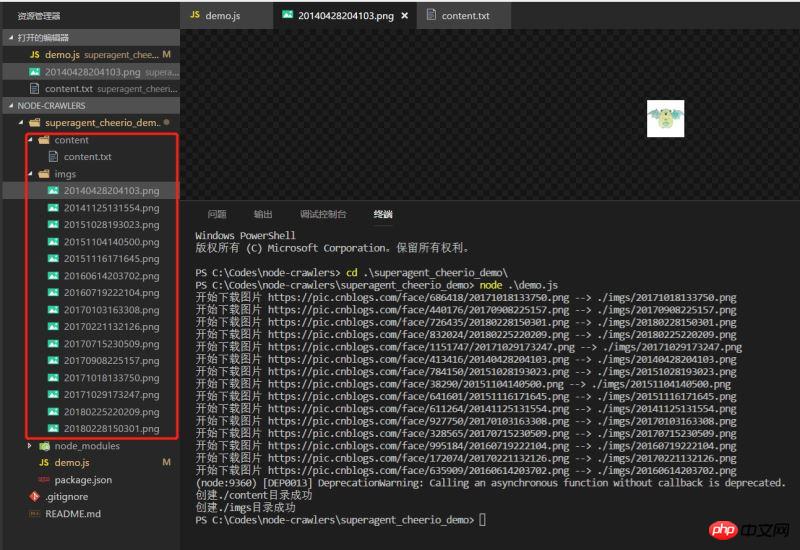
Eine sehr einfache Demo, die vielleicht nicht so streng ist, aber immer der erste kleine Schritt in Richtung Knoten ist.
Ich glaube, dass Sie die Methode beherrschen, nachdem Sie den Fall in diesem Artikel gelesen haben. Weitere spannende Informationen finden Sie in anderen verwandten Artikeln auf der chinesischen PHP-Website!
Empfohlene Lektüre:
H5-Methode zum Lesen von Dateien und Hochladen auf den Server
So erzielen Sie den Animationseffekt des Bilddrehens in HTML5
Das obige ist der detaillierte Inhalt vonNodeJS-Crawler-Framework-Superagent. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 Ist NodeJS ein Backend-Framework?
Apr 21, 2024 am 05:09 AM
Ist NodeJS ein Backend-Framework?
Apr 21, 2024 am 05:09 AM
Node.js kann als Backend-Framework verwendet werden, da es Funktionen wie hohe Leistung, Skalierbarkeit, plattformübergreifende Unterstützung, ein umfangreiches Ökosystem und einfache Entwicklung bietet.
 So verbinden Sie NodeJS mit der MySQL-Datenbank
Apr 21, 2024 am 06:13 AM
So verbinden Sie NodeJS mit der MySQL-Datenbank
Apr 21, 2024 am 06:13 AM
Um eine Verbindung zu einer MySQL-Datenbank herzustellen, müssen Sie die folgenden Schritte ausführen: Installieren Sie den MySQL2-Treiber. Verwenden Sie mysql2.createConnection(), um ein Verbindungsobjekt zu erstellen, das die Hostadresse, den Port, den Benutzernamen, das Passwort und den Datenbanknamen enthält. Verwenden Sie „connection.query()“, um Abfragen durchzuführen. Verwenden Sie abschließend Connection.end(), um die Verbindung zu beenden.
 Was ist der Unterschied zwischen den Dateien npm und npm.cmd im Installationsverzeichnis von nodejs?
Apr 21, 2024 am 05:18 AM
Was ist der Unterschied zwischen den Dateien npm und npm.cmd im Installationsverzeichnis von nodejs?
Apr 21, 2024 am 05:18 AM
Es gibt zwei npm-bezogene Dateien im Node.js-Installationsverzeichnis: npm und npm.cmd. Die Unterschiede sind wie folgt: unterschiedliche Erweiterungen: npm ist eine ausführbare Datei und npm.cmd ist eine Befehlsfensterverknüpfung. Windows-Benutzer: npm.cmd kann über die Eingabeaufforderung verwendet werden, npm kann nur über die Befehlszeile ausgeführt werden. Kompatibilität: npm.cmd ist spezifisch für Windows-Systeme, npm ist plattformübergreifend verfügbar. Nutzungsempfehlungen: Windows-Benutzer verwenden npm.cmd, andere Betriebssysteme verwenden npm.
 Was sind die globalen Variablen in NodeJS?
Apr 21, 2024 am 04:54 AM
Was sind die globalen Variablen in NodeJS?
Apr 21, 2024 am 04:54 AM
Die folgenden globalen Variablen sind in Node.js vorhanden: Globales Objekt: global Kernmodul: Prozess, Konsole, erforderlich Laufzeitumgebungsvariablen: __dirname, __filename, __line, __column Konstanten: undefiniert, null, NaN, Infinity, -Infinity
 Gibt es einen großen Unterschied zwischen NodeJS und Java?
Apr 21, 2024 am 06:12 AM
Gibt es einen großen Unterschied zwischen NodeJS und Java?
Apr 21, 2024 am 06:12 AM
Die Hauptunterschiede zwischen Node.js und Java sind Design und Funktionen: Ereignisgesteuert vs. Thread-gesteuert: Node.js ist ereignisgesteuert und Java ist Thread-gesteuert. Single-Threaded vs. Multi-Threaded: Node.js verwendet eine Single-Threaded-Ereignisschleife und Java verwendet eine Multithread-Architektur. Laufzeitumgebung: Node.js läuft auf der V8-JavaScript-Engine, während Java auf der JVM läuft. Syntax: Node.js verwendet JavaScript-Syntax, während Java Java-Syntax verwendet. Zweck: Node.js eignet sich für I/O-intensive Aufgaben, während Java für große Unternehmensanwendungen geeignet ist.
 Ist NodeJS eine Back-End-Entwicklungssprache?
Apr 21, 2024 am 05:09 AM
Ist NodeJS eine Back-End-Entwicklungssprache?
Apr 21, 2024 am 05:09 AM
Ja, Node.js ist eine Backend-Entwicklungssprache. Es wird für die Back-End-Entwicklung verwendet, einschließlich der Handhabung serverseitiger Geschäftslogik, der Verwaltung von Datenbankverbindungen und der Bereitstellung von APIs.
 So stellen Sie das NodeJS-Projekt auf dem Server bereit
Apr 21, 2024 am 04:40 AM
So stellen Sie das NodeJS-Projekt auf dem Server bereit
Apr 21, 2024 am 04:40 AM
Serverbereitstellungsschritte für ein Node.js-Projekt: Bereiten Sie die Bereitstellungsumgebung vor: Erhalten Sie Serverzugriff, installieren Sie Node.js, richten Sie ein Git-Repository ein. Erstellen Sie die Anwendung: Verwenden Sie npm run build, um bereitstellbaren Code und Abhängigkeiten zu generieren. Code auf den Server hochladen: über Git oder File Transfer Protocol. Abhängigkeiten installieren: Stellen Sie eine SSH-Verbindung zum Server her und installieren Sie Anwendungsabhängigkeiten mit npm install. Starten Sie die Anwendung: Verwenden Sie einen Befehl wie node index.js, um die Anwendung zu starten, oder verwenden Sie einen Prozessmanager wie pm2. Konfigurieren Sie einen Reverse-Proxy (optional): Verwenden Sie einen Reverse-Proxy wie Nginx oder Apache, um den Datenverkehr an Ihre Anwendung weiterzuleiten
 Welches soll man zwischen NodeJS und Java wählen?
Apr 21, 2024 am 04:40 AM
Welches soll man zwischen NodeJS und Java wählen?
Apr 21, 2024 am 04:40 AM
Node.js und Java haben jeweils ihre Vor- und Nachteile in der Webentwicklung, und die Wahl hängt von den Projektanforderungen ab. Node.js zeichnet sich durch Echtzeitanwendungen, schnelle Entwicklung und Microservices-Architektur aus, während Java sich durch Support, Leistung und Sicherheit auf Unternehmensniveau auszeichnet.
