
 Backend-Entwicklung
PHP-Tutorial
ELK-Bereitstellungsarchitektur für eine verteilte Echtzeit-Protokollanalyselösung
Backend-Entwicklung
PHP-Tutorial
ELK-Bereitstellungsarchitektur für eine verteilte Echtzeit-Protokollanalyselösung
ELK-Bereitstellungsarchitektur für eine verteilte Echtzeit-Protokollanalyselösung

ELK ist derzeit die beliebteste zentralisierte Protokolllösung. Sie besteht hauptsächlich aus Beats, Logstash, Elasticsearch, Kibana und anderen Komponenten, um gemeinsam die Sammlung, Speicherung, Anzeige und andere One-Stop-Lösungen von Echtzeitprotokollen zu vervollständigen . Dieser Artikel stellt Ihnen hauptsächlich die ELK-Bereitstellungsarchitektur für verteilte Echtzeit-Protokollanalysen vor. Freunde in Not können einen Blick auf
Kursempfehlung →: 《 Elasticsearch werfen Volltextsuche in der Praxis“ (aktuelles Kampfvideo)
Aus dem Kurs „Parallelitätslösung für Dutzende Millionen Daten (Theorie + praktischer Kampf)“
1 , Übersicht
ELK ist derzeit die beliebteste zentralisierte Protokolllösung. Sie besteht hauptsächlich aus Beats, Logstash, Elasticsearch, Kibana und anderen Komponenten, um die Erfassung, Speicherung und Anzeige gemeinsam zu vervollständigen von Echtzeitprotokollen aus einer Hand. In diesem Artikel wird die gemeinsame Architektur von ELK vorgestellt und damit verbundene Probleme gelöst.
Filebeat: Filebeat ist eine schlanke Datenerfassungs-Engine, die nur sehr wenige Dienstressourcen beansprucht. Sie ist ein neues Mitglied der ELK-Familie und kann Logstash als Protokollsammlung auf dem Anwendungsserver ersetzen . Die Engine unterstützt die Ausgabe gesammelter Daten an Warteschlangen wie Kafka und Redis.
Logstash: Datenerfassungs-Engine, die schwerer ist als Filebeat, aber eine große Anzahl von Plug-Ins integriert und eine umfangreiche Datenquellenerfassung unterstützt. Die gesammelten Daten können gefiltert und analysiert werden . Protokollformat formatieren.
Elasticsearch: eine verteilte Datensuchmaschine, implementiert auf Basis von Apache
Lucene, kann geclustert werden und bietet eine zentrale Speicherung und Analyse von Daten sowie eine leistungsstarke Datensuche und -aggregation Funktionen.Kibana: Eine Datenvisualisierungsplattform, mit der Sie relevante Daten in Elasticsearch in Echtzeit anzeigen und umfangreiche Diagrammstatistiken bereitstellen können.
2. ELK gemeinsame Bereitstellungsarchitektur
2.1. Logstash als Protokollsammler
Diese Architektur ist eine relativ primitive Bereitstellungsarchitektur : Stellen Sie auf jedem Anwendungsserver eine Logstash-Komponente als Protokollsammler bereit, filtern, analysieren und formatieren Sie dann die von Logstash gesammelten Daten, senden Sie sie an den Elasticsearch-Speicher und verwenden Sie schließlich Kibana für die visuelle Anzeige. Diese Architektur ist unzureichend. Der entscheidende Punkt ist: Logstash verbraucht mehr Serverressourcen und erhöht daher den Lastdruck auf dem Anwendungsserver.
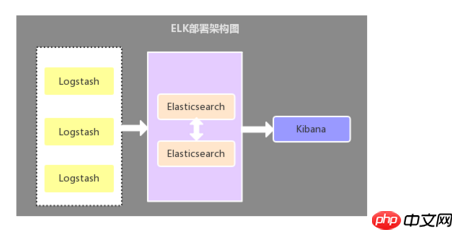
2.2. Filebeat als Protokollsammler
Der einzige Unterschied zwischen dieser Architektur und der ersten Architektur Ja: Der anwendungsseitige Protokollkollektor wird durch Filebeat ersetzt und beansprucht weniger Serverressourcen. Daher wird Filebeat im Allgemeinen zusammen mit Logstash verwendet die derzeit am häufigsten verwendete Architektur.
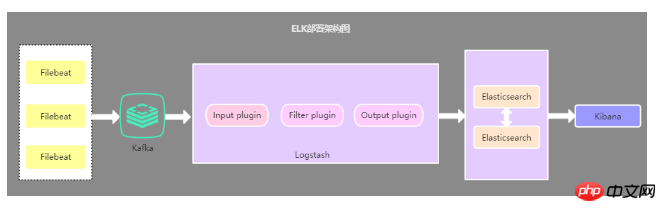
2.3. Bereitstellungsarchitektur, die eine Cache-Warteschlange einführt
Diese Architektur basiert auf der zweiten Architektur Die Kafka-Nachrichtenwarteschlange (kann auch eine andere Nachrichtenwarteschlange sein) wird eingeführt, die von Filebeat gesammelten Daten werden an Kafka gesendet und dann werden die Daten in Kafka über Logstasth gelesen. Diese Architektur wird hauptsächlich zur Lösung von Protokollerfassungslösungen für große Datenmengen verwendet. Die Verwendung von Cache-Warteschlangen dient hauptsächlich der Lösung der Datensicherheit und dem Ausgleich des Lastdrucks von Logstash und Elasticsearch.
2.4. Zusammenfassung der oben genannten drei Architekturen
Die erste Bereitstellungsarchitektur weist Probleme mit der Ressourcenbelegung auf. wird heutzutage nur noch selten verwendet, und die zweite Bereitstellungsarchitektur wird derzeit am häufigsten verwendet. Was die dritte Bereitstellungsarchitektur betrifft, bin ich persönlich der Meinung, dass keine Notwendigkeit besteht, eine Nachrichtenwarteschlange einzuführen, es sei denn, es bestehen andere Anforderungen, da es sich um große Mengen handelt Datenmenge, Filebeat-Nutzungsdruck. Sensible Protokolle senden Daten an Logstash oder Elasticsearch. Wenn Logstash mit der Verarbeitung von Daten beschäftigt ist, weist es Filebeat an, die Lesevorgänge zu verlangsamen. Sobald die Überlastung behoben ist, kehrt Filebeat zu seiner ursprünglichen Geschwindigkeit zurück und sendet weiterhin Daten.
Empfehlen Sie eine Kommunikations- und Lerngruppe: 478030634, die einige von erfahrenen Architekten aufgenommene Videos teilt: Spring, MyBatis, Netty-Quellcode-Analyse, Prinzipien hoher Parallelität, hohe Leistung, verteilte und Microservice-Architektur, JVM-Leistungsoptimierung zu einem notwendigen Wissenssystem für Architekten werden. Sie können auch kostenlose Lernressourcen erhalten und bisher viel profitieren:

3.Probleme und Lösungen
Problem : Wie implementiert man die mehrzeilige Zusammenführungsfunktion von Protokollen?
Protokolle in Systemanwendungen werden im Allgemeinen in einem bestimmten Format gedruckt. Daten, die zum selben Protokoll gehören, können daher in mehreren Zeilen gedruckt werden, wenn Sie ELK zum Sammeln von Protokollen verwenden . Zusammenführen.
Lösung: Verwenden Sie das Multiline-Multiline-Merge-Plug-In in Filebeat oder Logstash, um
Wenn Sie das Multiline-Multiline-Merge-Plug-In verwenden, benötigen Sie Achten Sie auf unterschiedliche ELK-Bereitstellungen. Die Architektur kann auch anders sein. Wenn es sich um die erste Bereitstellungsarchitektur in diesem Artikel handelt, muss Multiline in Logstash konfiguriert und verwendet werden in Filebeat konfiguriert und verwendet werden, und es ist nicht erforderlich, es in Logstash zu konfigurieren.
1. So konfigurieren Sie Multiline in Filebeat:
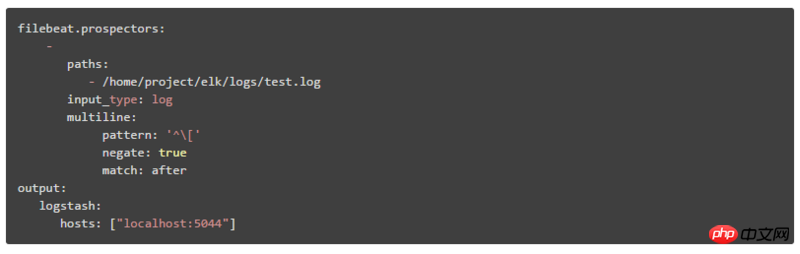
Muster: Regulärer Ausdruck
negieren: Der Standardwert ist „false“, was bedeutet, dass Zeilen, die mit dem Muster übereinstimmen, mit der vorherigen Zeile zusammengeführt werden; „true“ bedeutet, dass Zeilen, die nicht mit dem Muster übereinstimmen, mit der vorherigen Zeile zusammengeführt werden
Übereinstimmung: Nachher bedeutet Zusammenführen mit dem Ende der vorherigen Zeile, Vorher bedeutet Zusammenführen mit dem Anfang der vorherigen Zeile
Zum Beispiel:
Muster: '['
negieren: wahr
Übereinstimmung: nach
Diese Konfiguration bedeutet, dass die Zeilen, die nicht mit dem Mustermuster übereinstimmen, am Ende der vorherigen Zeile zusammengeführt werden
2. Multiline in Logstash-Konfigurationsmethode

(1) Der Wert des in Logstash konfigurierten What-Attributs ist previous Äquivalent zu after in Filebeat. Der Wert des in Logstash konfigurierten what-Attributs ist äquivalent zu before in Filebeat.
(2) Muster => „%{LOGLEVEL}s*]“ Das LOGLEVEL in „%{LOGLEVEL}s*]“ ist das vorgefertigte reguläre Übereinstimmungsmuster von Logstash Einzelheiten finden Sie unter: https://github.com/logstash-p…
Frage: Wie kann das Zeitfeld des in Kibana angezeigten Protokolls durch die Zeit in den Protokollinformationen ersetzt werden?
Standardmäßig stimmt das Zeitfeld, das wir in Kibana anzeigen, nicht mit der Zeit in den Protokollinformationen überein, da der Standardwert des Zeitfelds die aktuelle Zeit ist, zu der das Protokoll erfasst wird, die Zeit dieses Felds muss durch die Zeit in der Protokollmeldung ersetzt werden.
Lösung: Verwenden Sie das Grok-Wortsegmentierungs-Plug-In und das Datum-Uhrzeit-Formatierungs-Plug-In, um
Konfigurieren Sie das Grok-Wortsegmentierungs-Plug-In und das Datum-Uhrzeit-Format in der Filter des Logstash-Konfigurationsdatei-Plug-Ins, wie zum Beispiel:

Wenn das abzugleichende Protokollformat ist: „DEBUG[DefaultBeanDefinitionDocumentReader: 106] Laden von Bean-Definitionen“, analysieren Sie das Protokoll. Die Zeitfeldmethoden sind:
① Durch die Einführung einer schriftlichen Ausdrucksdatei lautet die Ausdrucksdatei beispielsweise customer_patterns und der Inhalt lautet:
CUSTOMER_TIME % {YEAR}%{MONTHNUM}%{MONTHDAY}s+ %{TIME}
Hinweis: Das Inhaltsformat ist: [Name des benutzerdefinierten Ausdrucks] [regulärer Ausdruck]
Dann kann es im Logstash wie folgt zitiert werden:

② In Form von Konfigurationselementen lautet die Regel: (?

Frage: So zeigen Sie Daten in Kibana an, indem Sie verschiedene Systemprotokollmodule auswählen
Im Allgemeinen werden die Protokolldaten in angezeigt Kibana mischt Daten aus verschiedenen Systemmodulen. Wie kann man also auswählen oder filtern, um nur die Protokolldaten des angegebenen Systemmoduls anzuzeigen?
Lösung: Fügen Sie Felder hinzu, die verschiedene Systemmodule identifizieren, oder erstellen Sie ES-Indizes basierend auf verschiedenen Systemmodulen
1 Fügen Sie Felder hinzu, die verschiedene Systemmodule identifizieren, und dann kann Kibana Filtern und Abfragen von Daten aus verschiedenen Modulen basierend auf diesem Feld
Hier erklären wir die zweite Bereitstellungsarchitektur. Der Konfigurationsinhalt in Filebeat ist:
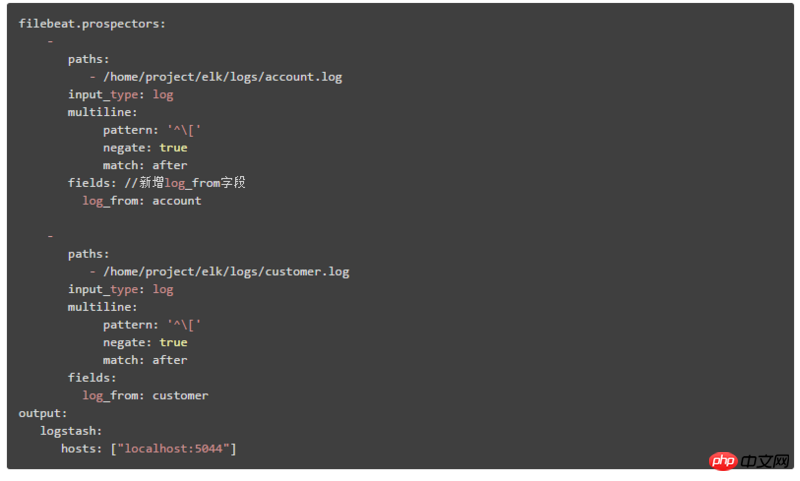
Andere identifizieren Systemmodulprotokolle durch Hinzufügen von: log_from-Feld
2. Konfigurieren Sie den entsprechenden ES-Index entsprechend den verschiedenen Systemmodulen und erstellen Sie dann den entsprechenden Indexmusterabgleich in Kibana, und Sie können den Index auf der Seite Mode Drop übergeben. Im unteren Feld werden verschiedene Systemmoduldaten ausgewählt.
Hier wird die zweite Bereitstellungsarchitektur erläutert, die in zwei Schritte unterteilt ist:
① Der Konfigurationsinhalt in Filebeat lautet:
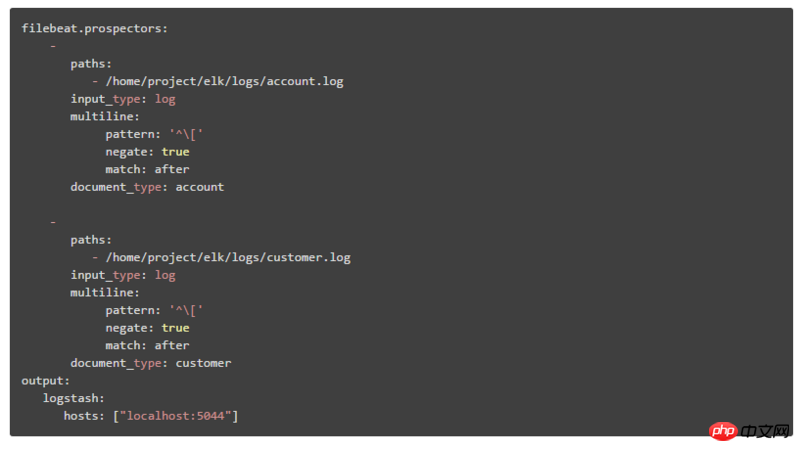
durch document_type Identifizieren verschiedene Systemmodule
② Ändern Sie den Inhalt der Ausgabekonfiguration in Logstash wie folgt:
Fügen Sie das Indexattribut zur Ausgabe hinzu. %{type} bedeutet, den ES-Index gemäß verschiedenen document_type-Werten zu erstellen
4. Zusammenfassung
In diesem Artikel werden hauptsächlich die drei Bereitstellungsarchitekturen der ELK-Echtzeitprotokollanalyse sowie die Probleme vorgestellt, die verschiedene Architekturen lösen können Die beliebteste und am häufigsten verwendete Bereitstellungsmethode stellt schließlich einige Probleme und Lösungen von ELK in der Protokollanalyse vor. Letztendlich kann ELK nicht nur für die zentrale Abfrage und Verwaltung verteilter Protokolldaten verwendet werden, sondern auch als Projektanwendung sowie Serverressourcenüberwachung und andere Szenarien.
Das obige ist der detaillierte Inhalt vonELK-Bereitstellungsarchitektur für eine verteilte Echtzeit-Protokollanalyselösung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1359
1359
 52
52

 Lösung für Win11: Chinesisches Sprachpaket konnte nicht installiert werden
Mar 09, 2024 am 09:15 AM
Lösung für Win11: Chinesisches Sprachpaket konnte nicht installiert werden
Mar 09, 2024 am 09:15 AM
Win11 ist das neueste von Microsoft eingeführte Betriebssystem. Im Vergleich zu früheren Versionen hat Win11 das Schnittstellendesign und die Benutzererfahrung erheblich verbessert. Einige Benutzer berichteten jedoch, dass sie nach der Installation von Win11 auf das Problem gestoßen waren, dass sie das chinesische Sprachpaket nicht installieren konnten, was zu Problemen bei der Verwendung von Chinesisch im System führte. Dieser Artikel bietet einige Lösungen für das Problem, dass Win11 das chinesische Sprachpaket nicht installieren kann, um Benutzern die reibungslose Verwendung von Chinesisch zu ermöglichen. Zuerst müssen wir verstehen, warum das chinesische Sprachpaket nicht installiert werden kann. Im Allgemeinen Win11
 Eine effektive Lösung zur Lösung des Problems verstümmelter Zeichen, die durch die Änderung des Oracle-Zeichensatzes verursacht werden
Mar 03, 2024 am 09:57 AM
Eine effektive Lösung zur Lösung des Problems verstümmelter Zeichen, die durch die Änderung des Oracle-Zeichensatzes verursacht werden
Mar 03, 2024 am 09:57 AM
Titel: Eine wirksame Lösung zur Lösung des Problems verstümmelter Zeichen, die durch die Änderung des Oracle-Zeichensatzes verursacht werden. Wenn in der Oracle-Datenbank der Zeichensatz geändert wird, tritt das Problem verstümmelter Zeichen aufgrund des Vorhandenseins inkompatibler Zeichen in den Daten häufig auf. Um dieses Problem zu lösen, müssen wir einige wirksame Lösungen annehmen. In diesem Artikel werden einige spezifische Lösungen und Codebeispiele vorgestellt, um das Problem verstümmelter Zeichen zu lösen, die durch die Änderung des Oracle-Zeichensatzes verursacht werden. 1. Daten exportieren und den Zeichensatz zurücksetzen. Zuerst können wir die Daten in die Datenbank exportieren, indem wir den Befehl expdp verwenden.
 Häufige Probleme und Lösungen der Oracle NVL-Funktion
Mar 10, 2024 am 08:42 AM
Häufige Probleme und Lösungen der Oracle NVL-Funktion
Mar 10, 2024 am 08:42 AM
Häufige Probleme und Lösungen für die OracleNVL-Funktion Die Oracle-Datenbank ist ein weit verbreitetes relationales Datenbanksystem, und bei der Datenverarbeitung ist es häufig erforderlich, mit Nullwerten umzugehen. Um die durch Nullwerte verursachten Probleme zu bewältigen, stellt Oracle die NVL-Funktion zur Verarbeitung von Nullwerten bereit. In diesem Artikel werden häufige Probleme und Lösungen von NVL-Funktionen vorgestellt und spezifische Codebeispiele bereitgestellt. Frage 1: Unsachgemäße Verwendung der NVL-Funktion. Die grundlegende Syntax der NVL-Funktion lautet: NVL(expr1,default_value).
 Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Implementierung von Algorithmen für maschinelles Lernen in C++: Häufige Herausforderungen und Lösungen
Jun 03, 2024 pm 01:25 PM
Zu den häufigsten Herausforderungen, mit denen Algorithmen für maschinelles Lernen in C++ konfrontiert sind, gehören Speicherverwaltung, Multithreading, Leistungsoptimierung und Wartbarkeit. Zu den Lösungen gehören die Verwendung intelligenter Zeiger, moderner Threading-Bibliotheken, SIMD-Anweisungen und Bibliotheken von Drittanbietern sowie die Einhaltung von Codierungsstilrichtlinien und die Verwendung von Automatisierungstools. Praktische Fälle zeigen, wie man die Eigen-Bibliothek nutzt, um lineare Regressionsalgorithmen zu implementieren, den Speicher effektiv zu verwalten und leistungsstarke Matrixoperationen zu nutzen.
 Häufige Ursachen und Lösungen für verstümmelte chinesische Zeichen bei der MySQL-Installation
Mar 02, 2024 am 09:00 AM
Häufige Ursachen und Lösungen für verstümmelte chinesische Zeichen bei der MySQL-Installation
Mar 02, 2024 am 09:00 AM
Häufige Gründe und Lösungen für verstümmelte chinesische Zeichen bei der MySQL-Installation MySQL ist ein häufig verwendetes relationales Datenbankverwaltungssystem. Bei der Verwendung kann es jedoch zu Problemen mit verstümmelten chinesischen Zeichen kommen, die Entwicklern und Systemadministratoren Probleme bereiten. Das Problem verstümmelter chinesischer Zeichen wird hauptsächlich durch falsche Zeichensatzeinstellungen, inkonsistente Zeichensätze zwischen dem Datenbankserver und dem Client usw. verursacht. In diesem Artikel werden die häufigsten Ursachen und Lösungen für verstümmelte chinesische Zeichen bei der MySQL-Installation ausführlich vorgestellt, um allen zu helfen, dieses Problem besser zu lösen. 1. Häufige Gründe: Zeichensatzeinstellung
 Analyse und Lösungen von Sicherheitslücken im Java-Framework
Jun 04, 2024 pm 06:34 PM
Analyse und Lösungen von Sicherheitslücken im Java-Framework
Jun 04, 2024 pm 06:34 PM
Die Analyse der Sicherheitslücken des Java-Frameworks zeigt, dass XSS, SQL-Injection und SSRF häufige Schwachstellen sind. Zu den Lösungen gehören: Verwendung von Sicherheits-Framework-Versionen, Eingabevalidierung, Ausgabekodierung, Verhinderung von SQL-Injection, Verwendung von CSRF-Schutz, Deaktivierung unnötiger Funktionen, Festlegen von Sicherheitsheadern. In tatsächlichen Fällen kann die ApacheStruts2OGNL-Injection-Schwachstelle durch Aktualisieren der Framework-Version und Verwendung des OGNL-Ausdrucksprüfungstools behoben werden.
 Analyse und Lösungen, warum sich das Black Shark-Mobiltelefon während des Ladevorgangs automatisch ausschaltet und wieder einschaltet
Mar 24, 2024 pm 02:09 PM
Analyse und Lösungen, warum sich das Black Shark-Mobiltelefon während des Ladevorgangs automatisch ausschaltet und wieder einschaltet
Mar 24, 2024 pm 02:09 PM
Das Black Shark-Mobiltelefon ist ein bei jungen Leuten beliebtes Gaming-Telefon. Seine hervorragende Leistung und sein einzigartiges Design haben die Gunst vieler Spieler auf sich gezogen. Allerdings berichteten einige Benutzer im täglichen Gebrauch, dass sich Black Shark-Telefone beim Laden automatisch abschalteten oder nach dem Anschließen an ein Ladegerät nicht starteten, was den Benutzern Probleme bereitete. In diesem Artikel wird das Problem des automatischen Herunterfahrens und Startens von Black Shark-Mobiltelefonen unter dem Aspekt der Ursachenanalyse und Lösungen erörtert, um Benutzern bei der besseren Lösung dieses Problems zu helfen. 1. Ursachenanalyse Probleme mit der Ladegerätqualität: Ladegeräte von geringer Qualität können zu Spannungsinstabilität führen
 Kann nach dem Win11-Upgrade nicht gestartet werden? Probieren Sie diese Lösungen aus!
Mar 08, 2024 pm 03:39 PM
Kann nach dem Win11-Upgrade nicht gestartet werden? Probieren Sie diese Lösungen aus!
Mar 08, 2024 pm 03:39 PM
Kann nach dem Win11-Upgrade nicht gestartet werden? Probieren Sie diese Lösungen aus! Mit der offiziellen Veröffentlichung von Windows 11 können viele Benutzer es kaum erwarten, ihr Betriebssystem zu aktualisieren. Einige Benutzer hatten jedoch das Problem, dass sie nach Abschluss des Upgrades nicht mehr booten konnten. Dieser Zustand kann frustrierend sein, aber zum Glück sind normalerweise nur einfache Reparaturschritte erforderlich, um das Problem zu beheben. Werfen wir einen Blick auf einige gängige Lösungen und hoffen, Benutzern zu helfen, die auf dieses Problem stoßen. Überprüfen Sie zunächst die Hardware-Verbindungen: Manchmal können Boot-Probleme an der Hardware liegen
