

Beim Schreiben eines Crawlers in Python tritt bei html.getcode() das Problem des 403-Zugriffsverbots auf, bei dem es sich um ein Verbot automatisierter Crawler auf der Website handelt. In diesem Artikel wird hauptsächlich die Lösung des 403-Crawler-Problems in Angular2 Advanced vorgestellt. Der Herausgeber hält ihn für recht gut, daher werde ich ihn jetzt mit Ihnen teilen und als Referenz verwenden. Folgen wir dem Editor, um einen Blick darauf zu werfen
Um dieses Problem zu lösen, müssen Sie das Python-Modul urllib2-Modul verwenden
urllib2 Modul Es handelt sich um ein erweitertes Crawler-Crawling-Modul. Es gibt viele Methoden
Verbinden Sie beispielsweise url=http://blog.csdn.net/qysh123
Möglicherweise liegt für diese Verbindung ein 403 Forbidden Access-Problem vor
Um dieses Problem zu lösen, sind die folgenden Schritte erforderlich:
<span style="font-size:18px;">req = urllib2.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36")
req.add_header("GET",url)
req.add_header("Host","blog.csdn.net")
req.add_header("Referer","http://blog.csdn.net/")</span>User-Agent ist ein browserspezifisches Attribut. Sie können den Quellcode über den Browser anzeigen, um
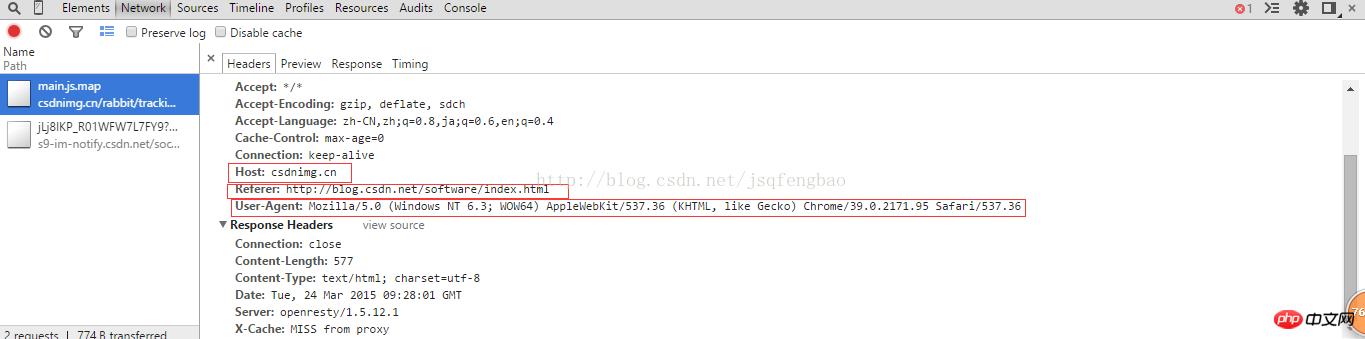
und dann html=urllib2 anzuzeigen .urlopen(req)
print html.read()
kann den gesamten Webseitencode ohne das 403-Zugriffsverbotsproblem herunterladen.
Für die oben genannten Probleme kann es zur einfachen Verwendung in Zukunft in Funktionen gekapselt werden:
#-*-coding:utf-8-*-
import urllib2
import random
url="http://blog.csdn.net/qysh123/article/details/44564943"
my_headers=["Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:30.0) Gecko/20100101 Firefox/30.0"
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14",
"Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; Win64; x64; Trident/6.0)"
]
def get_content(url,headers):
'''''
@获取403禁止访问的网页
'''
randdom_header=random.choice(headers)
req=urllib2.Request(url)
req.add_header("User-Agent",randdom_header)
req.add_header("Host","blog.csdn.net")
req.add_header("Referer","http://blog.csdn.net/")
req.add_header("GET",url)
content=urllib2.urlopen(req).read()
return content
print get_content(url,my_headers)
Die Zufallsfunktion wird verwendet, um automatisch die User-Agent-Informationen des geschriebenen Browsertyps abzurufen. In der benutzerdefinierten Funktion müssen Sie Ihre eigenen schreiben Host, Referrer, GET-Informationen usw. Nach der Lösung dieser Probleme können Sie problemlos darauf zugreifen und die 403-Zugriffsinformationen werden nicht mehr angezeigt.
Natürlich werden einige Websites trotzdem gefiltert, wenn die Zugriffshäufigkeit zu hoch ist. Um dieses Problem zu lösen, müssen Sie eine Proxy-IP-Methode verwenden. . . Lösen Sie es gezielt selbst
Verwandte Empfehlungen:
Python-Crawler behebt 403-Zugriffsverbotsfehler
Python3 HTTP-Fehler 403: Verboten
Das obige ist der detaillierte Inhalt vonSo lösen Sie das 403-Problem in Crawlern. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



