

Der Inhalt dieses Artikels dient dazu, die Entfernungsmessung und Python-Implementierung mit Ihnen zu teilen. Freunde in Not können sich auf den Inhalt des Artikels beziehen
Nachdruck von: http://www.cnblogs.com/denny402/p/7027954.html
https://www.cnblogs.com/denny402 /p /7028832.html
1. Euklidischer Abstand
Der euklidische Abstand ist die am einfachsten zu verstehende Abstandsberechnungsmethode, abgeleitet aus dem euklidischen Raum. Die Abstandsformel zwischen zwei Punkten.
(1) Der euklidische Abstand zwischen zwei Punkten a(x1,y1) und b(x2,y2) auf der zweidimensionalen Ebene: 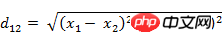
(2) Zwei Punkte a(x1) im dreidimensionalen Raum ,y1,z1) und b(x2,y2,z2) Euklidischer Abstand: 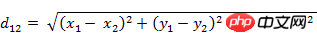
(3) Zwei n-dimensionale Vektoren a(x11,x12,…,x1n) und b( Der euklidische Abstand zwischen Implementierung: 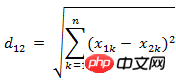 Methode 1:
Methode 1: 

import numpy as np x=np.random.random(10) y=np.random.random(10)#方法一:根据公式求解d1=np.sqrt(np.sum(np.square(x-y)))#方法二:根据scipy库求解from scipy.spatial.distance import pdistX=np.vstack([x,y]) d2=pdist(X)
Die Berechnungsmethode dieser Entfernung können Sie anhand des Namens erraten. Stellen Sie sich vor, Sie fahren in Manhattan von einer Kreuzung zur anderen. Ist die Fahrstrecke die Luftlinienentfernung zwischen den beiden Punkten? Anscheinend nicht, es sei denn, Sie können durch das Gebäude gelangen. Die tatsächliche Fahrstrecke ist diese „Manhattan-Entfernung“. Daher stammt auch der Name Manhattan-Distanz. Manhattan-Distanz wird auch City-Block-Distanz (Stadtblockdistanz) genannt.
(2) Zwei n-dimensionale Vektoren a(x11 ,x12 ,…,x1n) und b(x21,x22,…,x2n) Manhattan-Abstand
Implementierung in Python: 
(1) Tschebyscheff-Abstand zwischen zwei Punkten a (x1, y1) und b (x2, y2) auf einer zweidimensionalen Ebene
Eine andere äquivalente Form dieser Formel ist
import numpy as np x=np.random.random(10) y=np.random.random(10)#方法一:根据公式求解d1=np.sum(np.abs(x-y))#方法二:根据scipy库求解from scipy.spatial.distance import pdistX=np.vstack([x,y]) d2=pdist(X,'cityblock')
Implementierung in Python:
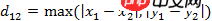

4. 闵可夫斯基距离(Minkowski Distance)
闵氏距离不是一种距离,而是一组距离的定义。
(1) 闵氏距离的定义
两个n维变量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:
也可写成

其中p是一个变参数。
当p=1时,就是曼哈顿距离
当p=2时,就是欧氏距离
当p→∞时,就是切比雪夫距离
根据变参数的不同,闵氏距离可以表示一类的距离。
(2)闵氏距离的缺点
闵氏距离,包括曼哈顿距离、欧氏距离和切比雪夫距离都存在明显的缺点。
举个例子:二维样本(身高,体重),其中身高范围是150~190,体重范围是50~60,有三个样本:a(180,50),b(190,50),c(180,60)。那么a与b之间的闵氏距离(无论是曼哈顿距离、欧氏距离或切比雪夫距离)等于a与c之间的闵氏距离,但是身高的10cm真的等价于体重的10kg么?因此用闵氏距离来衡量这些样本间的相似度很有问题。
简单说来,闵氏距离的缺点主要有两个:(1)将各个分量的量纲(scale),也就是“单位”当作相同的看待了。(2)没有考虑各个分量的分布(期望,方差等)可能是不同的。
python中的实现:
import numpy as np x=np.random.random(10) y=np.random.random(10)#方法一:根据公式求解,p=2d1=np.sqrt(np.sum(np.square(x-y)))#方法二:根据scipy库求解from scipy.spatial.distance import pdistX=np.vstack([x,y]) d2=pdist(X,'minkowski',p=2)
5. 标准化欧氏距离 (Standardized Euclidean distance )
(1)标准欧氏距离的定义
标准化欧氏距离是针对简单欧氏距离的缺点而作的一种改进方案。标准欧氏距离的思路:既然数据各维分量的分布不一样,好吧!那我先将各个分量都“标准化”到均值、方差相等吧。均值和方差标准化到多少呢?这里先复习点统计学知识吧,假设样本集X的均值(mean)为m,标准差(standard deviation)为s,那么X的“标准化变量”表示为: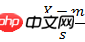
标准化后的值 = ( 标准化前的值 - 分量的均值 ) /分量的标准差
经过简单的推导就可以得到两个n维向量a(x11,x12,…,x1n)与 b(x21,x22,…,x2n)间的标准化欧氏距离的公式:
如果将方差的倒数看成是一个权重,这个公式可以看成是一种加权欧氏距离(Weighted Euclidean distance)。
python中的实现:
import numpy as np x=np.random.random(10) y=np.random.random(10) X=np.vstack([x,y])#方法一:根据公式求解sk=np.var(X,axis=0,ddof=1) d1=np.sqrt(((x - y) ** 2 /sk).sum())#方法二:根据scipy库求解from scipy.spatial.distance import pdistd2=pdist(X,'seuclidean')
6. 马氏距离(Mahalanobis Distance)
(1)马氏距离定义
有M个样本向量X1~Xm,协方差矩阵记为S,均值记为向量μ,则其中样本向量X到u的马氏距离表示为:
而其中向量Xi与Xj之间的马氏距离定义为: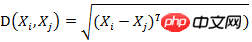
若协方差矩阵是单位矩阵(各个样本向量之间独立同分布),则公式就成了: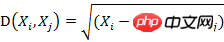
也就是欧氏距离了。
若协方差矩阵是对角矩阵,公式变成了标准化欧氏距离。
python 中的实现:
import numpy as np x=np.random.random(10) y=np.random.random(10)#马氏距离要求样本数要大于维数,否则无法求协方差矩阵#此处进行转置,表示10个样本,每个样本2维X=np.vstack([x,y]) XT=X.T#方法一:根据公式求解S=np.cov(X) #两个维度之间协方差矩阵SI = np.linalg.inv(S) #协方差矩阵的逆矩阵#马氏距离计算两个样本之间的距离,此处共有10个样本,两两组合,共有45个距离。n=XT.shape[0] d1=[]for i in range(0,n): for j in range(i+1,n): delta=XT[i]-XT[j] d=np.sqrt(np.dot(np.dot(delta,SI),delta.T)) d1.append(d) #方法二:根据scipy库求解from scipy.spatial.distance import pdist d2=pdist(XT,'mahalanobis')
马氏优缺点:
1)马氏距离的计算是建立在总体样本的基础上的,这一点可以从上述协方差矩阵的解释中可以得出,也就是说,如果拿同样的两个样本,放入两个不同的总体中,最后计算得出的两个样本间的马氏距离通常是不相同的,除非这两个总体的协方差矩阵碰巧相同;
2)在计算马氏距离过程中,要求总体样本数大于样本的维数,否则得到的总体样本协方差矩阵逆矩阵不存在,这种情况下,用欧式距离计算即可。
3)还有一种情况,满足了条件总体样本数大于样本的维数,但是协方差矩阵的逆矩阵仍然不存在,比如三个样本点(3,4),(5,6)和(7,8),这种情况是因为这三个样本在其所处的二维空间平面内共线。这种情况下,也采用欧式距离计算。
4)在实际应用中“总体样本数大于样本的维数”这个条件是很容易满足的,而所有样本点出现3)中所描述的情况是很少出现的,所以在绝大多数情况下,马氏距离是可以顺利计算的,但是马氏距离的计算是不稳定的,不稳定的来源是协方差矩阵,这也是马氏距离与欧式距离的最大差异之处。
优点:它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关;由标准化数据和中心化数据(即原始数据与均值之差)计算出的二点之间的马氏距离相同。马氏距离还可以排除变量之间的相关性的干扰。缺点:它的缺点是夸大了变化微小的变量的作用。
7. 夹角余弦(Cosine)
Man kann es auch Kosinusähnlichkeit nennen. Der Kosinus des Winkels in der Geometrie kann verwendet werden, um die Differenz zwischen den Richtungen zweier Vektoren zu messen. übernimmt dieses Konzept, um die Differenz zwischen Beispielvektoren zu messen.
(1) Die Kosinusformel des Winkels zwischen Vektor A(x1, y1) und Vektor B(x2, y2) im zweidimensionalen Raum: 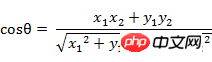
(2) Zwei n-dimensional Beispielpunkte Der Kosinus des Winkels zwischen a(x11,x12,…,x1n) und b(x21,x22,…,x2n)
Ähnlich gilt für zwei n-dimensionale Beispielpunkte a(x11,x12,…,x1n ) und b (x21,x22,…,x2n) können Sie ein Konzept ähnlich dem Kosinus des Winkels verwenden, um den Grad der Ähnlichkeit zwischen ihnen zu messen. 
Das heißt: 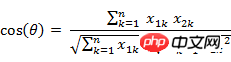
Der Wertebereich des Kosinus beträgt [-1,1]. Finden Sie den Winkel zwischen den beiden Vektoren und erhalten Sie den dem Winkel entsprechenden Kosinuswert. Dieser Kosinuswert kann zur Charakterisierung der Ähnlichkeit der beiden Vektoren verwendet werden. Je kleiner der Winkel ist, der sich 0 Grad nähert, desto näher liegt der Kosinuswert bei 1, und je konsistenter ihre Richtungen sind, desto ähnlicher sind sie. Wenn die Richtungen zweier Vektoren völlig entgegengesetzt sind, nimmt der Kosinus des Winkels zwischen ihnen den Minimalwert -1 an. Wenn der Kosinuswert 0 ist, sind die beiden Vektoren orthogonal und der eingeschlossene Winkel beträgt 90 Grad. Daher ist ersichtlich, dass die Kosinusähnlichkeit nichts mit der Größe des Vektors zu tun hat, sondern nur mit der Richtung des Vektors.
import numpy as np x=np.random.random(10) y=np.random.random(10)#方法一:根据公式求解d1=np.dot(x,y)/(np.linalg.norm(x)*np.linalg.norm(y))#方法二:根据scipy库求解from scipy.spatial.distance import pdist X=np.vstack([x,y]) d2=1-pdist(X,'cosine')
两个向量完全相等时,余弦值为1,如下的代码计算出来的d=1。
d=1-pdist([x,x],'cosine')
8. 皮尔逊相关系数(Pearson correlation)
(1) 皮尔逊相关系数的定义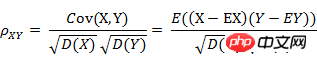
Die zuvor erwähnte Kosinusähnlichkeit bezieht sich nur auf die Vektorrichtung, wird jedoch durch die Verschiebung des Vektors in der Winkelkosinusformel beeinflusst, wenn x verschoben wird auf x+ 1 ändert sich der Kosinuswert. Wie kann Übersetzungsinvarianz erreicht werden? Dies erfordert die Verwendung des Pearson-Korrelationskoeffizienten (Pearson-Korrelation), manchmal auch direkt Korrelationskoeffizient genannt.
Wenn die Winkelkosinusformel wie folgt geschrieben wird:
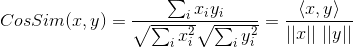
stellt den Kosinus des Winkels zwischen Vektor x und Vektor y dar, dann kann Pearson-Korrelationskoeffizient ausgedrückt werden als:
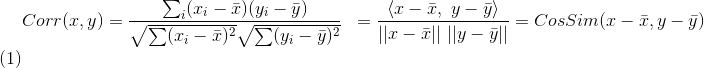
皮尔逊相关系数具有平移不变性和尺度不变性,计算出了两个向量(维度)的相关性。
在python中的实现:
import numpy as np x=np.random.random(10) y=np.random.random(10)#方法一:根据公式求解x_=x-np.mean(x) y_=y-np.mean(y) d1=np.dot(x_,y_)/(np.linalg.norm(x_)*np.linalg.norm(y_))#方法二:根据numpy库求解X=np.vstack([x,y]) d2=np.corrcoef(X)[0][1]
Der Korrelationskoeffizient ist eine Methode zur Messung der Korrelation zwischen Zufallsvariablen X und Y. Der Wertebereich des Korrelationskoeffizienten beträgt [-1,1]. Je größer der Absolutwert des Korrelationskoeffizienten ist, desto höher ist die Korrelation zwischen X und Y. Wenn X und Y linear zusammenhängen, nimmt der Korrelationskoeffizient den Wert 1 (positive lineare Korrelation) oder -1 (negative lineare Korrelation) an.
9. Hamming-Distanz (Hamming-Distanz)
(1) Die Definition der Hamming-Distanz
Zwei gleich The Hamming Der Abstand zwischen den langen Zeichenfolgen s1 und s2 ist definiert als die Mindestanzahl von Ersetzungen, die erforderlich sind, um eine in die andere zu ändern. Beispielsweise beträgt der Hamming-Abstand zwischen den Zeichenfolgen „1111“ und „1001“ 2.
Anwendung: Informationscodierung (um die Fehlertoleranz zu erhöhen, sollte der minimale Hamming-Abstand zwischen Codes so groß wie möglich gemacht werden).
Implementierung in Python:
import numpy as npfrom scipy.spatial.distance import pdist x=np.random.random(10)>0.5y=np.random.random(10)>0.5x=np.asarray(x,np.int32) y=np.asarray(y,np.int32)#方法一:根据公式求解d1=np.mean(x!=y)#方法二:根据scipy库求解X=np.vstack([x,y]) d2=pdist(X,'hamming')
10. 杰卡德相似系数(Jaccard similarity coefficient)
(1) 杰卡德相似系数
两个集合A和B的交集元素在A,B的并集中所占的比例,称为两个集合的杰卡德相似系数,用符号J(A,B)表示。
杰卡德相似系数是衡量两个集合的相似度一种指标。
(2) 杰卡德距离
与杰卡德相似系数相反的概念是杰卡德距离(Jaccard distance)。杰卡德距离可用如下公式表示: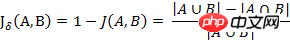
杰卡德距离用两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。
(3) 杰卡德相似系数与杰卡德距离的应用
可将杰卡德相似系数用在衡量样本的相似度上。
样本A与样本B是两个n维向量,而且所有维度的取值都是0或1。例如:A(0111)和B(1011)。我们将样本看成是一个集合,1表示集合包含该元素,0表示集合不包含该元素。
在python中的实现:
import numpy as npfrom scipy.spatial.distance import pdist x=np.random.random(10)>0.5y=np.random.random(10)>0.5x=np.asarray(x,np.int32) y=np.asarray(y,np.int32)#方法一:根据公式求解up=np.double(np.bitwise_and((x != y),np.bitwise_or(x != 0, y != 0)).sum()) down=np.double(np.bitwise_or(x != 0, y != 0).sum()) d1=(up/down) #方法二:根据scipy库求解X=np.vstack([x,y]) d2=pdist(X,'jaccard')
11. 布雷柯蒂斯距离(Bray Curtis Distance)
Bray Curtis距离主要用于生态学和环境科学,计算坐标之间的距离。该距离取值在[0,1]之间。它也可以用来计算样本之间的差异。
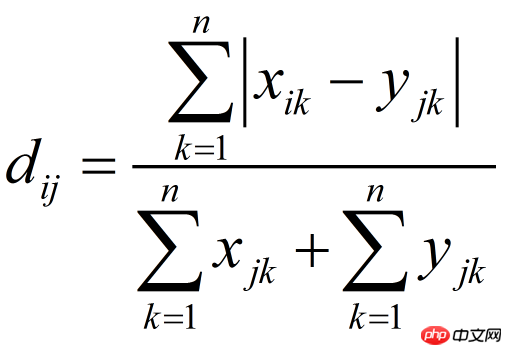
Beispieldaten:
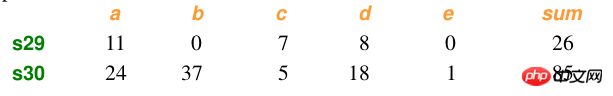
Berechnung:
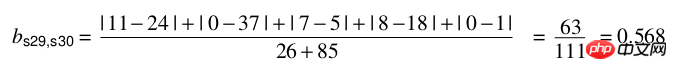
Implementierung in Python:
import numpy as npfrom scipy.spatial.distance import pdist x=np.array([11,0,7,8,0]) y=np.array([24,37,5,18,1])#方法一:根据公式求解up=np.sum(np.abs(y-x)) down=np.sum(x)+np.sum(y) d1=(up/down) #方法二:根据scipy库求解X=np.vstack([x,y]) d2=pdist(X,'braycurtis')
相关推荐:
Das obige ist der detaillierte Inhalt vonEntfernungsmessung und Python-Implementierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



