
 Backend-Entwicklung
Python-Tutorial
pandas+dataframe implementiert Zeilen- und Spaltenauswahl- und Slicing-Vorgänge
Backend-Entwicklung
Python-Tutorial
pandas+dataframe implementiert Zeilen- und Spaltenauswahl- und Slicing-Vorgänge
pandas+dataframe implementiert Zeilen- und Spaltenauswahl- und Slicing-Vorgänge
Dieses Mal werde ich Ihnen Pandas + Dataframe vorstellen, um Zeilen- und Spaltenauswahl- und Slicing-Operationen zu implementieren. Was sind die Vorsichtsmaßnahmen für Pandas + Dataframe, um Zeilen- und Spaltenauswahl- und Slicing-Operationen zu implementieren? Praktischer Fall, werfen wir einen Blick darauf.
Die Auswahl in SQL basiert auf dem Namen der Spalte; Pandas ist flexibler. Sie kann nicht nur basierend auf dem Spaltennamen, sondern auch basierend auf derPosition (Nummer) ausgewählt werden , in welcher Position Zeile und Spalte, bitte beachten Sie, dass die Position der Pandas-Zeilen und -Spalten bei 0 beginnt). Die zugehörigen -Funktionen lauten wie folgt:
1) loc, basierend auf der Spaltenbezeichnung, bestimmte Zeilen können ausgewählt werden (basierend auf dem Zeilenindex); 2) iloc, basierend auf der Zeilen-/Spaltenposition ;3) at, schnell die Elemente von DataFrame entsprechend dem angegebenen Zeilenindex und der Spaltenbezeichnung finden 4) iat, ähnlich wie at, außer dass es wird entsprechend der Position positioniert; 5) ix, eine Mischung aus loc und iloc, unterstützt sowohl Label als auch Position; >Falsche Darstellung:
import pandas as pd
import numpy as np
df = pd.DataFrame({'total_bill': [16.99, 10.34, 23.68, 23.68, 24.59],
'tip': [1.01, 1.66, 3.50, 3.31, 3.61],
'sex': ['Female', 'Male', 'Male', 'Male', 'Female']})
# data type of columns
print df.dtypes
# indexes
print df.index
# return pandas.Index
print df.columns
# each row, return array[array]
print df.values
print dfsex object tip float64 total_bill float64 dtype: object RangeIndex(start=0, stop=5, step=1) Index([u'sex', u'tip', u'total_bill'], dtype='object') [['Female' 1.01 16.99] ['Male' 1.66 10.34] ['Male' 3.5 23.68] ['Male' 3.31 23.68] ['Female' 3.61 24.59]] sex tip total_bill 0 Female 1.01 16.99 1 Male 1.66 10.34 2 Male 3.50 23.68 3 Male 3.31 23.68 4 Female 3.61 24.59
print df.loc[1:3, ['total_bill', 'tip']] print df.loc[1:3, 'tip': 'total_bill'] print df.iloc[1:3, [1, 2]] print df.iloc[1:3, 1: 3]
total_bill tip 1 10.34 1.66 2 23.68 3.50 3 23.68 3.31 tip total_bill 1 1.66 10.34 2 3.50 23.68 3 3.31 23.68 tip total_bill 1 1.66 10.34 2 3.50 23.68 tip total_bill 1 1.66 10.34 2 3.50 23.68
print df.loc[1:3, [2, 3]]#.loc仅支持列名操作
KeyError: 'None of [[2, 3]] are in the [columns]'
print df.loc[[2, 3]]#.loc可以不加列名,则是行选择
sex tip total_bill 2 Male 3.50 23.68 3 Male 3.31 23.68
print df.iloc[1:3]#.iloc可以不加第几列,则是行选择
sex tip total_bill 1 Male 1.66 10.34 2 Male 3.50 23.68
print df.iloc[1:3, 'tip': 'total_bill']
TypeError: cannot do slice indexing on <class 'pandas.indexes.base.Index'> with these indexers [tip] of <type 'str'>
print df.at[3, 'tip'] print df.iat[3, 1] print df.ix[1:3, [1, 2]] print df.ix[1:3, ['total_bill', 'tip']]
3.31 3.31 tip total_bill 1 1.66 10.34 2 3.50 23.68 3 3.31 23.68 total_bill tip 1 10.34 1.66 2 23.68 3.50 3 23.68 3.31
print df.ix[[1, 2]]#行选择
sex tip total_bill 1 Male 1.66 10.34 2 Male 3.50 23.68
print df[1: 3] print df[['total_bill', 'tip']] # print df[1:2, ['total_bill', 'tip']] # TypeError: unhashable type
sex tip total_bill 1 Male 1.66 10.34 2 Male 3.50 23.68 total_bill tip 0 16.99 1.01 1 10.34 1.66 2 23.68 3.50 3 23.68 3.31 4 24.59 3.61
print df[1:3,1:2]
TypeError: unhashable type
Was sind die Methoden der Dataframe-Abfrage in Pandas?
Selenium+Cookie überspringt die Implementierung des Bestätigungscodes Detaillierte Erklärung der Schritte
Das obige ist der detaillierte Inhalt vonpandas+dataframe implementiert Zeilen- und Spaltenauswahl- und Slicing-Vorgänge. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1207
24
52
1207
24

 Kann die Wallpaper-Engine von Familien gemeinsam genutzt werden?
Mar 18, 2024 pm 07:28 PM
Kann die Wallpaper-Engine von Familien gemeinsam genutzt werden?
Mar 18, 2024 pm 07:28 PM
Unterstützt Wallpaper die Familienfreigabe? Leider kann dies nicht unterstützt werden. Dennoch haben wir Lösungen. Sie können beispielsweise mit einem kleinen Konto einkaufen oder die Software und Hintergrundbilder zunächst von einem großen Konto herunterladen und dann zum kleinen Konto wechseln. Das einfache Starten der Software ist vollkommen in Ordnung. Kann Wallpaperengine mit der Familie geteilt werden? Antwort: Wallpaper unterstützt derzeit nicht die Familienfreigabefunktion. 1. Es versteht sich, dass WallpaperEngine nicht für Familienfreigabeumgebungen geeignet zu sein scheint. 2. Um dieses Problem zu lösen, wird empfohlen, den Kauf eines neuen Kontos in Betracht zu ziehen. 3. Oder laden Sie zuerst die erforderliche Software und Hintergrundbilder im Hauptkonto herunter und wechseln Sie dann zu anderen Konten. 4. Öffnen Sie einfach die Software mit einem leichten Klick und alles ist in Ordnung. 5. Sie können die Eigenschaften auf der oben genannten Webseite einsehen.
 iBatis vs. MyBatis: Welches ist besser für Sie?
Feb 19, 2024 pm 04:38 PM
iBatis vs. MyBatis: Welches ist besser für Sie?
Feb 19, 2024 pm 04:38 PM
iBatis vs. MyBatis: Wofür sollten Sie sich entscheiden? Einführung: Mit der rasanten Entwicklung der Java-Sprache sind viele Persistenz-Frameworks entstanden. iBatis und MyBatis sind zwei beliebte Persistenz-Frameworks, die beide eine einfache und effiziente Lösung für den Datenzugriff bieten. In diesem Artikel werden die Funktionen und Vorteile von iBatis und MyBatis vorgestellt und einige spezifische Codebeispiele gegeben, die Ihnen bei der Auswahl des geeigneten Frameworks helfen. Einführung in iBatis: iBatis ist ein Open-Source-Persistenz-Framework
 Wie stelle ich das Hintergrundbild für den Sperrbildschirm in der Wallpaper-Engine ein? So verwenden Sie die Wallpaper-Engine
Mar 13, 2024 pm 08:07 PM
Wie stelle ich das Hintergrundbild für den Sperrbildschirm in der Wallpaper-Engine ein? So verwenden Sie die Wallpaper-Engine
Mar 13, 2024 pm 08:07 PM
WallpaperEngine ist eine Software, die häufig zum Festlegen von Desktop-Hintergrundbildern verwendet wird. Benutzer können in WallpaperEngine nach ihren Lieblingsbildern suchen, um Desktop-Hintergrundbilder zu erstellen. Sie unterstützt auch das Hinzufügen von Bildern vom Computer zu WallpaperEngine, um sie als Computer-Hintergrundbilder festzulegen. Werfen wir einen Blick darauf, wie WallpaperEngine das Hintergrundbild für den Sperrbildschirm festlegt. Tutorial zum Einstellen des Hintergrundbilds für den Sperrbildschirm von WallpaperEngine 1. Rufen Sie zuerst die Software auf, wählen Sie dann „Installiert“ aus und klicken Sie auf „Hintergrundoptionen konfigurieren“. 2. Nachdem Sie das Hintergrundbild in separaten Einstellungen ausgewählt haben, müssen Sie unten rechts auf OK klicken. 3. Klicken Sie dann oben auf die Einstellungen und Vorschau. 4. Weiter
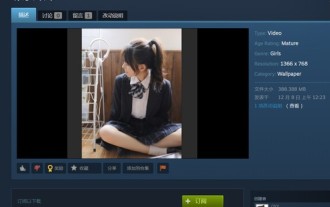 Gibt es beim Ansehen von Wallpaper Engine-Filmen einen Virus?
Mar 18, 2024 pm 07:28 PM
Gibt es beim Ansehen von Wallpaper Engine-Filmen einen Virus?
Mar 18, 2024 pm 07:28 PM
Benutzer können bei Verwendung von WallpaperEngine verschiedene Hintergrundbilder herunterladen und auch dynamische Hintergrundbilder verwenden. Viele Benutzer wissen nicht, ob beim Ansehen von Videos auf WallpaperEngine Viren vorhanden sind, Videodateien können jedoch nicht als Viren verwendet werden. Gibt es Viren beim Ansehen von Filmen auf WallpaperEngine? Antwort: Nein. 1. Nur Videodateien können nicht als Viren verwendet werden. 2. Stellen Sie einfach sicher, dass Sie Videos von vertrauenswürdigen Quellen herunterladen und Computersicherheitsmaßnahmen ergreifen, um das Risiko einer Virusinfektion zu vermeiden. 3. Anwendungshintergründe liegen im APK-Format vor und APK kann Trojaner enthalten. 4. WallpaperEngine selbst enthält keine Viren, aber einige Anwendungshintergründe in der Kreativwerkstatt können Viren enthalten.
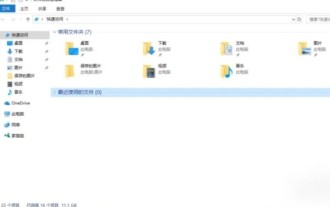 In welchem Ordner befinden sich die Hintergrundbilder der Wallpaper Engine?
Mar 19, 2024 am 08:16 AM
In welchem Ordner befinden sich die Hintergrundbilder der Wallpaper Engine?
Mar 19, 2024 am 08:16 AM
Bei der Verwendung von Hintergrundbildern können Benutzer verschiedene Hintergrundbilder herunterladen, die ihnen gefallen. Viele Benutzer wissen nicht, in welchem Ordner sich die Hintergrundbilder befinden. Die von Benutzern heruntergeladenen Hintergrundbilder werden im Inhaltsordner gespeichert. In welchem Ordner befindet sich das Hintergrundbild? Antwort: Inhaltsordner. 1. Öffnen Sie den Datei-Explorer. 2. Klicken Sie links auf „Dieser PC“. 3. Suchen Sie den Ordner „STEAM“. 4. Wählen Sie „Steamapps“. 5. Klicken Sie auf „Werkstatt“. 6. Suchen Sie den Ordner „content“.
 Verbraucht die Wallpaper-Engine viel Strom?
Mar 18, 2024 pm 08:30 PM
Verbraucht die Wallpaper-Engine viel Strom?
Mar 18, 2024 pm 08:30 PM
Benutzer können ihre Computerhintergründe ändern, wenn sie WallpaperEngine verwenden. Viele Benutzer wissen nicht, dass WallpaperEngine viel Strom verbraucht als statische Hintergrundbilder. Verbraucht Wallpaperengine viel Strom? Antwort: Nicht viel. 1. Dynamische Hintergrundbilder verbrauchen etwas mehr Strom als statische Hintergrundbilder, aber nicht viel. 2. Durch die Aktivierung des dynamischen Hintergrundbilds erhöht sich der Stromverbrauch des Computers und es verringert sich die Speichernutzung geringfügig. 3. Benutzer müssen sich keine Sorgen über den hohen Stromverbrauch dynamischer Hintergrundbilder machen.
 Mar 18, 2024 pm 05:37 PM
Mar 18, 2024 pm 05:37 PM
Wie überprüfe ich Hintergrundbild-Abonnementdatensätze? Viele Benutzer haben eine große Anzahl von Abonnements für diese Software abgeschlossen, wissen jedoch möglicherweise nicht, wie sie diese Datensätze abfragen sollen. Tatsächlich müssen Sie es nur im Browsing-Funktionsbereich der Software bedienen. Wo sind WallpaperEngine-Abonnementdatensätze? Antwort: In der Browseroberfläche. 1. Bitte starten Sie zuerst den Computer und rufen Sie die Hintergrundsoftware auf. 2. Suchen Sie das Symbol der Registerkarte „Durchsuchen“ in der oberen linken Ecke der Anwendung und klicken Sie darauf. 3. In der „Durchsuchen“-Oberfläche sehen Sie eine Übersicht verschiedener Hintergrundbilder und Feeds. 4. Geben Sie die Schlüsselwörter, nach denen Sie suchen möchten, in das Suchfeld in der oberen rechten Ecke ein. 5. Anhand der Suchergebnisse können Sie die Quellinformationen des Wallpaper-Abonnements finden. 6. Klicken Sie auf den entsprechenden Feed, um dessen Webseite aufzurufen. 7. Bestellung
 So ändern Sie die Schriftgröße im Microsoft Edge-Browser - So ändern Sie die Schriftgröße im Microsoft Edge-Browser
Mar 04, 2024 pm 05:58 PM
So ändern Sie die Schriftgröße im Microsoft Edge-Browser - So ändern Sie die Schriftgröße im Microsoft Edge-Browser
Mar 04, 2024 pm 05:58 PM
Ich schätze, Sie sind mit dem Microsoft Edge-Browser nicht vertraut, aber wissen Sie, wie man die Schriftgröße im Microsoft Edge-Browser ändert? Der folgende Artikel beschreibt, wie man die Schriftgröße im Microsoft Edge-Browser ändert. Suchen Sie zunächst den Microsoft Edge-Browser und doppelklicken Sie darauf, um ihn zu öffnen. Sie finden den Microsoft Edge-Browser in der Desktop-Verknüpfung, im Startmenü oder in der Taskleiste und können ihn per Doppelklick öffnen. Zweitens öffnen Sie die Benutzeroberfläche [Einstellungen], um diese Browseroberfläche aufzurufen, klicken Sie auf das [...]-Logo in der oberen linken Ecke und doppelklicken Sie auf [Einstellungen], um die Einstellungsoberfläche zu öffnen. Suchen und öffnen Sie erneut die Benutzeroberfläche [Darstellung] und scrollen Sie mit der Maus nach unten
