

Wenn Sie mit Begeisterung grundlegende Crawler-Kenntnisse aus dem Internet erlernen, ist es, als würden Sie ein Ziel zum Üben finden. Als nächstes das kurze Buch Wenn Sie es ausprobieren, werden Sie feststellen, dass es nicht so einfach ist, wie Sie denken, da es viele JS-bezogene Datenübertragungen enthält . Lassen Sie mich es zunächst mit einem herkömmlichen Crawler demonstrieren: >
Öffnen Sie die Homepage von Jianshu, da scheint nichts Besonderes zu sein

Jianshu-Homepage
Öffnen Sie den Entwicklermodus von
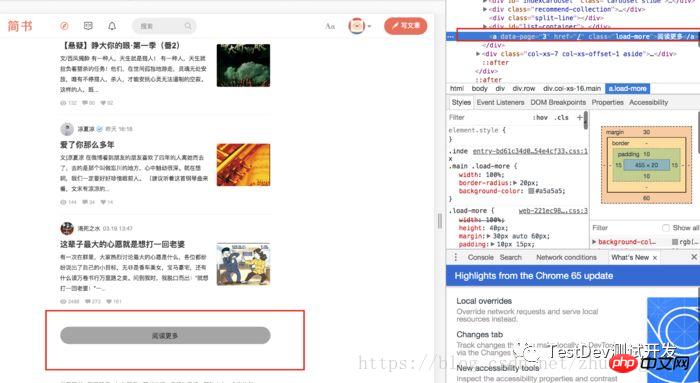
chromeund stellen Sie fest, dass sich der Titel des Artikels undhrefalle ima-Tag befinden, und es scheint nein zu geben Unterschied

a.png
Der nächste Schritt besteht darin, alle
erscheint.a-Tags auf der Seite zu finden, aber warten Sie, wenn Wenn Sie genau hinschauen, werden Sie feststellen, dass die Rolle zur Hälfte gerollt ist. Dann wird die Seite weiter geladen und dieser Schritt wird dreimal wiederholt, bis unten die Schaltfläche阅读更多

Pulley
Nicht nur das, sondern auch die weiterführenden Informationen unten
hrefsagen uns nicht, dass wir die restlichen Seiteninformationen laden sollen , der einzige Weg ist不断点击阅读更多这个按钮
load_more.png
was, die Riemenscheibe dreimal wiederholen, um sie nach unten zu schieben in der Mitte der SeiteundKontinuierliches Klicken auf die SchaltflächeDiese Art von Vorganghttpkann nicht mit Anfragen durchgeführt werden. Ist das eher eine JS-Operation? Richtig, bei Jianshus Artikel handelt es sich nicht um eine normale HTTP-Anfrage. Wir können nicht ständig nach verschiedenen URLs umleiten, sondern nach einigen Aktionen auf der Seite, um die Seiteninformationen zu laden.

Selenium ist ein Web-Automatisierungstesttool, das viele Sprachen unterstützt. Wir können Pythons Selenium hier verwenden Als Crawler besteht das Arbeitsprinzip beim Crawlen kurzer Bücher darin, kontinuierlich js-Code einzufügen, die Seite kontinuierlich laden zu lassen und schließlich alle a-Tags zu extrahieren. Zuerst müssen Sie das Selenium-Paket in Python herunterladen.
>>> pip3 install selenium
Selenium muss mit einem Browser verwendet werden. Hier verwende ich Chromedriver, die Open-Source-Beta In der Chrome-Version kann der Headless-Modus verwendet werden, um auf Webseiten zuzugreifen, ohne den ersten Absatz anzuzeigen, was die größte Funktion darstellt.
在写代码之前一定要把chromedriver同一文件夹内,因为我们需要引用PATH,这样方便点。首先我们的第一个任务是刷出加载更多的按钮,需要做3次将滑轮重复三次滑倒页面的中央,这里方便起见我滑到了底部
from selenium import webdriverimport time
browser = webdriver.Chrome("./chromedriver")
browser.get("https://www.jianshu.com/")for i in range(3):
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") // execute_script是插入js代码的
time.sleep(2) //加载需要时间,2秒比较合理看看效果
刷出了按钮
接下来就是不断点击按钮加载页面,继续加入刚才的py文件之中
for j in range(10): //这里我模拟10次点击
try:
button = browser.execute_script("var a = document.getElementsByClassName('load-more'); a[0].click();")
time.sleep(2) except: pass'''
上面的js代码说明一下
var a = document.getElementsByClassName('load-more');选择load-more这个元素
a[0].click(); 因为a是一个集合,索引0然后执行click()函数
'''这个我就不贴图了,成功之后就是不断地加载页面 ,知道循环完了为止,接下来的工作就简单很多了,就是寻找a标签,get其中的text和href属性,这里我直接把它们写在了txt文件之中.
titles = browser.find_elements_by_class_name("title")with open("article_jianshu.txt", "w", encoding="utf-8") as f: for t in titles: try:
f.write(t.text + " " + t.get_attribute("href"))
f.write("\n") except TypeError: pass最终结果
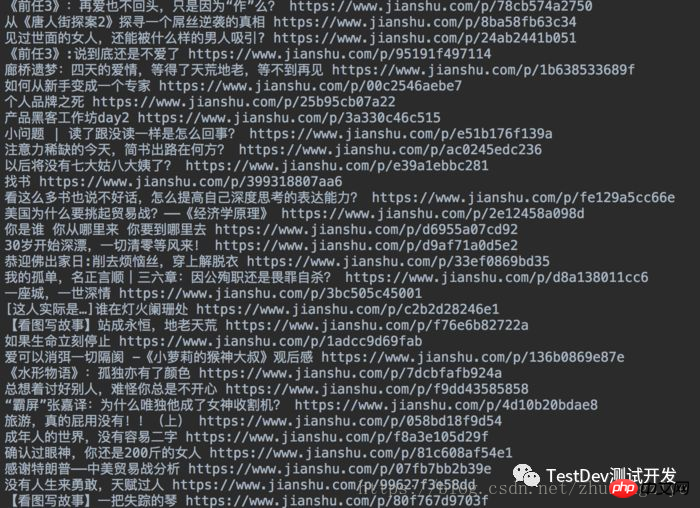
简书文章
不断加载页面肯定也很烦人,所以我们测试成功之后并不想把浏览器显示出来,这需要加上headless模式
options = webdriver.ChromeOptions()
options.add_argument('headless')
browser = webdriver.Chrome("./chromedriver", chrome_options=options) //把上面的browser加入chrome_options参数当我们没办法使用正常的http请求爬取时,可以使用selenium操纵浏览器来抓取我们想要的内容,这样有利有弊,比如
优点
可以暴力爬虫
简书并不需要cookie才能查看文章,不需要费劲心思找代理,或者说我们可以无限抓取并且不会被ban
首页应该为ajax传输,不需要额外的http请求
缺点
爬取速度太满,想象我们的程序,点击一次需要等待2秒那么点击600次需要1200秒, 20分钟...
这是所有完整的代码
from selenium import webdriverimport time
options = webdriver.ChromeOptions()
options.add_argument('headless')
browser = webdriver.Chrome("./chromedriver", chrome_options=options)
browser.get("https://www.jianshu.com/")for i in range(3):
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)# print(browser)for j in range(10): try:
button = browser.execute_script("var a = document.getElementsByClassName('load-more'); a[0].click();")
time.sleep(2) except: pass#titles = browser.find_elements_by_class_name("title")with open("article_jianshu.txt", "w", encoding="utf-8") as f: for t in titles: try:
f.write(t.text + " " + t.get_attribute("href"))
f.write("\n") except TypeError: pass相关推荐:
[python爬虫] Selenium爬取新浪微博内容及用户信息
[Python爬虫]利用Selenium等待Ajax加载及模拟自动翻页,爬取东方财富网公司公告
Python爬虫:Selenium+ BeautifulSoup 爬取JS渲染的动态内容(雪球网新闻)
Das obige ist der detaillierte Inhalt vonWie Selen+Python die Jianshu-Website crawlt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



