
 Backend-Entwicklung
Python-Tutorial
Detaillierte Erläuterung der Klassifizierungsbewertungsindikatoren und Regressionsbewertungsindikatoren sowie der Python-Code-Implementierung
Backend-Entwicklung
Python-Tutorial
Detaillierte Erläuterung der Klassifizierungsbewertungsindikatoren und Regressionsbewertungsindikatoren sowie der Python-Code-Implementierung
Detaillierte Erläuterung der Klassifizierungsbewertungsindikatoren und Regressionsbewertungsindikatoren sowie der Python-Code-Implementierung

Der Inhalt dieses Artikels ist eine detaillierte Erklärung der Klassifizierungsbewertungsindikatoren und der Python-Code-Implementierung. Jetzt kann ich ihn mit Ihnen teilen .
1. Konzept
Leistungsmessungsindikatoren (Bewertung) werden hauptsächlich in zwei Kategorien unterteilt:
1) Klassifizierungsbewertungsindikatoren (Klassifizierung), hauptsächlich Analyse, diskret, Ganzzahl. Zu seinen spezifischen Indikatoren gehören Genauigkeit (Genauigkeit), Präzision (Präzision), Rückruf (Rückruf), F-Wert, P-R-Kurve, ROC-Kurve und AUC.
2) Der Regressionsbewertungsindex (Regression) analysiert hauptsächlich die Beziehung zwischen ganzen Zahlen und reellen Zahlen. Zu seinen spezifischen Indikatoren gehören explianed_variance_score, mittlerer absoluter Fehler MAE (mean_absolute_error), mittlerer quadratischer Fehler MSE (mean-squared_error), quadratischer Mittelwert der Differenz RMSE, Kreuzentropieverlust (Log-Verlust, Kreuzentropieverlust), R-Quadrat-Wert (Bestimmungskoeffizient). , r2_score).
1.1. Prämisse
Gehen Sie davon aus, dass es nur zwei Kategorien gibt – positiv und negativ. Normalerweise ist die Kategorie von Besorgnis die positive Kategorie und die anderen Kategorien sind die negativen Kategorien. mehrere Arten von Problemen können auch in zwei Kategorien zusammengefasst werden)
Die Verwirrungsmatrix lautet wie folgt
| Tatsächliche Kategorie | Vorhergesagte Kategorie | |||||||||||||||||||||||
|
Positiv | Negativ | Zusammenfassung | td > |
||||||||||||||||||||
| Positiv | TP | FN | P (tatsächlich positiv) | |||||||||||||||||||||
| Negativ | FP | TN | N (eigentlich negativ) | |||||||||||||||||||||
AB-Modus in der Tabelle: Der erste zeigt an, ob das Vorhersageergebnis richtig oder falsch ist, und der zweite zeigt an die Kategorie der Vorhersage. Beispielsweise bedeutet TP „True Positive“, das heißt, die richtige Vorhersage ist die positive Klasse; FN bedeutet „False Negative“, das heißt, die falsche Vorhersage ist die negative Klasse.
2. Bewertungsindikatoren (Leistungsmessung)2.1. Klassifizierungsbewertungsindikatoren| 度量 | Accuracy(准确率) | Precision(精确率) | Recall(召回率) | F值 |
| 定义 | 正确分类的样本数与总样本数之比(预测为垃圾短信中真正的垃圾短信的比例) | 判定为正例中真正正例数与判定为正例数之比(所有真的垃圾短信被分类求正确找出来的比例) | 被正确判定为正例数与总正例数之比 | 准确率与召回率的调和平均F-score |
| 表示 | accuracy=
|
precision=
|
recall=
|
F - score =
|
| Messung | Genauigkeit | Präzision | Rückruf (Rückrufrate) td> | F-Wert |
| Definition | Das Verhältnis der Anzahl korrekt klassifizierter Proben zur Gesamtzahl der Proben (Vorhersage ist Anteil der Wahrheit). Spam-Textnachrichten unter Spam-Textnachrichten) | Das Verhältnis der Anzahl der wirklich positiven Beispiele unter den positiven Beispielen und der Anzahl der positiven Beispiele (alle echten Spam-Textnachrichten werden klassifiziert und der Anteil der richtigen wird ermittelt ) | Das Verhältnis der Anzahl korrekt beurteilter positiver Fälle zur Gesamtzahl positiver Fälle | Der harmonische Durchschnitt F-score td> |
| Darstellung | accuracy= | precision= | Recall= | F - score = |
1. Präzision wird oft auch als Präzisionsrate bezeichnet, und Rückruf wird als Rückrufrate bezeichnet
2. Am häufigsten wird F1 verwendet,
Python3.6-Code Implementierung:
#调用sklearn库中的指标求解from sklearn import metricsfrom sklearn.metrics import precision_recall_curvefrom sklearn.metrics import average_precision_scorefrom sklearn.metrics import accuracy_score#给出分类结果y_pred = [0, 1, 0, 0]
y_true = [0, 1, 1, 1]
print("accuracy_score:", accuracy_score(y_true, y_pred))
print("precision_score:", metrics.precision_score(y_true, y_pred))
print("recall_score:", metrics.recall_score(y_true, y_pred))
print("f1_score:", metrics.f1_score(y_true, y_pred))
print("f0.5_score:", metrics.fbeta_score(y_true, y_pred, beta=0.5))
print("f2_score:", metrics.fbeta_score(y_true, y_pred, beta=2.0))2.1.2 Korrelationskurve-P-R-Kurve, ROC-Kurve und AUC-Wert
1) P-R-Kurve
Schritte:
1. Stellen Sie die Punktzahl von hoch ein zu niedrig „Werte werden sortiert und wiederum als Schwellenwerte verwendet;
2. Für jeden Schwellenwert gelten Testproben mit einem „Score“-Wert größer oder gleich diesem Schwellenwert als positive Beispiele, andere als negative Beispiele. Dadurch entsteht eine Reihe von Prognosezahlen.
z. B. 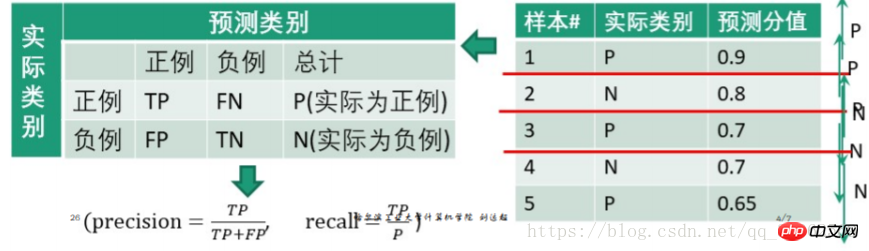
Stellen Sie 0,9 als Schwellenwert ein, dann ist die erste Testprobe ein positives Beispiel und 2, 3, 4 und 5 sind negative Beispiele
Erhalten Sie
| 预测为正例 | 预测为负例 | 总计 | |
| 正例(score大于阈值) | 0.9 | 0.1 | 1 |
| 负例(score小于阈值) | 0.2+0.3+0.3+0.35 = 1.15 | 0.8+0.7+0.7+0.65 = 2.85 | 4 |
| precision= recall= | |||
#precision和recall的求法如上
#主要介绍一下python画图的库
import matplotlib.pyplot ad plt
#主要用于矩阵运算的库
import numpy as np#导入iris数据及训练见前一博文
...
#加入800个噪声特征,增加图像的复杂度
#将150*800的噪声特征矩阵与150*4的鸢尾花数据集列合并
X = np.c_[X, np.random.RandomState(0).randn(n_samples, 200*n_features)]
#计算precision,recall得到数组
for i in range(n_classes):
#计算三类鸢尾花的评价指标, _作为临时的名称使用
precision[i], recall[i], _ = precision_recall_curve(y_test[:, i], y_score[:,i])#plot作图plt.clf()
for i in range(n_classes):
plt.plot(recall[i], precision[i])
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("Recall")
plt.ylabel("Precision")
plt.show()
recall=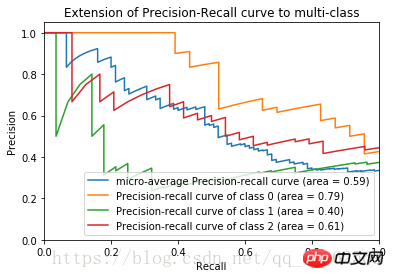
Der Teil unterhalb des Schwellenwerts ist der Wert des vorhergesagten negativen Beispiels und der korrekte vorhergesagte Wert. Wenn es sich also um ein positives Beispiel handelt, wird TP verwendet. Wenn es sich um ein negatives Beispiel handelt, wird TN verwendet , beides sind Vorhersagewerte.
Python implementiert Pseudocode
Nach Abschluss des obigen Codes wird die P-R-Kurve des Irisblütendatensatzes erhalten
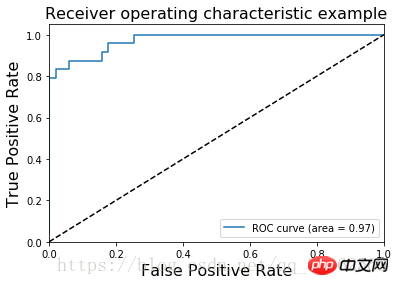
2) ROC-Kurve
Horizontal Achse: Falsch-Positiv-Rate fp-Rate = FP/NVertikale Achse: Wahre Rate tp-Rate = TP/N
Schritte:  1. Sortieren Sie die „Score“-Werte von hoch nach niedrig und verwenden Sie sie als Schwellenwerte nacheinander;
1. Sortieren Sie die „Score“-Werte von hoch nach niedrig und verwenden Sie sie als Schwellenwerte nacheinander;
2. Für jeden Schwellenwert gelten die Testproben, deren „Score“-Wert größer oder gleich diesem Schwellenwert ist, als positive Beispiele, und die anderen sind negative Beispiele. Dadurch entsteht eine Reihe von Prognosezahlen. 
Sie ähnelt der P-R-Kurvenberechnung und wird nicht noch einmal beschrieben
Das ROC-Bild des Irisblütendatensatzes ist 
 AUC (Area Under Curve) ist definiert als die Fläche unter der ROC-Kurve
AUC (Area Under Curve) ist definiert als die Fläche unter der ROC-Kurve
Der AUC-Wert liefert einen numerischen Gesamtwert für den Klassifikator. Normalerweise ist der Klassifikator umso besser, je größer der Wert ist 🎜>
2) Mittlerer absoluter Fehler MAE (mittlerer absoluter Fehler) 
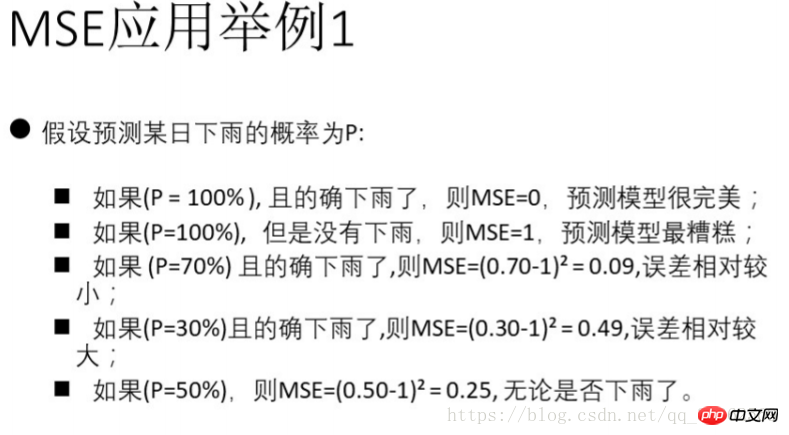
3) mittlerer quadratischer Fehler MSE (mittlerer quadratischer Fehler) 
from sklearn.metrics import log_loss log_loss(y_true, y_pred)from scipy.stats import pearsonr pearsonr(rater1, rater2)from sklearn.metrics import cohen_kappa_score cohen_kappa_score(rater1, rater2)
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Klassifizierungsbewertungsindikatoren und Regressionsbewertungsindikatoren sowie der Python-Code-Implementierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1205
24
52
1205
24

 PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP ist hauptsächlich prozedurale Programmierung, unterstützt aber auch die objektorientierte Programmierung (OOP). Python unterstützt eine Vielzahl von Paradigmen, einschließlich OOP, funktionaler und prozeduraler Programmierung. PHP ist für die Webentwicklung geeignet, und Python eignet sich für eine Vielzahl von Anwendungen wie Datenanalyse und maschinelles Lernen.
 Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
PHP eignet sich für Webentwicklung und schnelles Prototyping, und Python eignet sich für Datenwissenschaft und maschinelles Lernen. 1.PHP wird für die dynamische Webentwicklung verwendet, mit einfacher Syntax und für schnelle Entwicklung geeignet. 2. Python hat eine kurze Syntax, ist für mehrere Felder geeignet und ein starkes Bibliotheksökosystem.
 Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
VS -Code kann zum Schreiben von Python verwendet werden und bietet viele Funktionen, die es zu einem idealen Werkzeug für die Entwicklung von Python -Anwendungen machen. Sie ermöglichen es Benutzern: Installation von Python -Erweiterungen, um Funktionen wie Code -Abschluss, Syntax -Hervorhebung und Debugging zu erhalten. Verwenden Sie den Debugger, um Code Schritt für Schritt zu verfolgen, Fehler zu finden und zu beheben. Integrieren Sie Git für die Versionskontrolle. Verwenden Sie Tools für die Codeformatierung, um die Codekonsistenz aufrechtzuerhalten. Verwenden Sie das Lining -Tool, um potenzielle Probleme im Voraus zu erkennen.
 Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
VS -Code kann unter Windows 8 ausgeführt werden, aber die Erfahrung ist möglicherweise nicht großartig. Stellen Sie zunächst sicher, dass das System auf den neuesten Patch aktualisiert wurde, und laden Sie dann das VS -Code -Installationspaket herunter, das der Systemarchitektur entspricht und sie wie aufgefordert installiert. Beachten Sie nach der Installation, dass einige Erweiterungen möglicherweise mit Windows 8 nicht kompatibel sind und nach alternativen Erweiterungen suchen oder neuere Windows -Systeme in einer virtuellen Maschine verwenden müssen. Installieren Sie die erforderlichen Erweiterungen, um zu überprüfen, ob sie ordnungsgemäß funktionieren. Obwohl VS -Code unter Windows 8 möglich ist, wird empfohlen, auf ein neueres Windows -System zu upgraden, um eine bessere Entwicklungserfahrung und Sicherheit zu erzielen.
 Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
VS -Code -Erweiterungen stellen böswillige Risiken dar, wie das Verstecken von böswilligem Code, das Ausbeutetieren von Schwachstellen und das Masturbieren als legitime Erweiterungen. Zu den Methoden zur Identifizierung böswilliger Erweiterungen gehören: Überprüfung von Verlegern, Lesen von Kommentaren, Überprüfung von Code und Installation mit Vorsicht. Zu den Sicherheitsmaßnahmen gehören auch: Sicherheitsbewusstsein, gute Gewohnheiten, regelmäßige Updates und Antivirensoftware.
 Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: Die Lernkurve und Benutzerfreundlichkeit
Apr 16, 2025 am 12:12 AM
Python eignet sich besser für Anfänger mit einer reibungslosen Lernkurve und einer kurzen Syntax. JavaScript ist für die Front-End-Entwicklung mit einer steilen Lernkurve und einer flexiblen Syntax geeignet. 1. Python-Syntax ist intuitiv und für die Entwicklung von Datenwissenschaften und Back-End-Entwicklung geeignet. 2. JavaScript ist flexibel und in Front-End- und serverseitiger Programmierung weit verbreitet.
 PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP und Python: Ein tiefes Eintauchen in ihre Geschichte
Apr 18, 2025 am 12:25 AM
PHP entstand 1994 und wurde von Rasmuslerdorf entwickelt. Es wurde ursprünglich verwendet, um Website-Besucher zu verfolgen und sich nach und nach zu einer serverseitigen Skriptsprache entwickelt und in der Webentwicklung häufig verwendet. Python wurde Ende der 1980er Jahre von Guidovan Rossum entwickelt und erstmals 1991 veröffentlicht. Es betont die Lesbarkeit und Einfachheit der Code und ist für wissenschaftliche Computer, Datenanalysen und andere Bereiche geeignet.
 So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
Im VS -Code können Sie das Programm im Terminal in den folgenden Schritten ausführen: Erstellen Sie den Code und öffnen Sie das integrierte Terminal, um sicherzustellen, dass das Codeverzeichnis mit dem Terminal Working -Verzeichnis übereinstimmt. Wählen Sie den Befehl aus, den Befehl ausführen, gemäß der Programmiersprache (z. B. Pythons Python your_file_name.py), um zu überprüfen, ob er erfolgreich ausgeführt wird, und Fehler auflösen. Verwenden Sie den Debugger, um die Debugging -Effizienz zu verbessern.
