

Der in diesem Artikel vorgestellte Inhalt ist eine Zusammenfassung von PHP-Interviews, die einen gewissen Referenzwert haben. Jetzt kann ich ihn mit allen Freunden in Not teilen.
Tabelle
Typ
mögliche_Tasten
key
key_len
ref
Zeilen
Extra
Umgebungsvorbereitung

CREATE TABLE people( id bigint auto_increment primary key, zipcode char(32) not null default '', address varchar(128) not null default '', lastname char(64) not null default '', firstname char(64) not null default '', birthdate char(10) not null default '' ); CREATE TABLE people_car( people_id bigint, plate_number varchar(16) not null default '', engine_number varchar(16) not null default '', lasttime timestamp );
insert into people (zipcode,address,lastname,firstname,birthdate) values ('230031','anhui','zhan','jindong','1989-09-15'), ('100000','beijing','zhang','san','1987-03-11'), ('200000','shanghai','wang','wu','1988-08-25') insert into people_car (people_id,plate_number,engine_number,lasttime) values (1,'A121311','12121313','2013-11-23 :21:12:21'), (2,'B121311','1S121313','2011-11-23 :21:12:21'), (3,'C121311','1211SAS1','2012-11-23 :21:12:21')
EXPLAIN-Einführung<🎜 verwendet >
alter table people add key(zipcode,firstname,lastname);
id
Query-1 explain select zipcode,firstname,lastname from people;

id wird zur sequentiellen Identifizierung der verwendet Ganz Für die SELELCT-Anweisung in der Abfrage können Sie anhand der einfachen verschachtelten Abfrage oben sehen, dass die Anweisung mit der größeren ID zuerst ausgeführt wird. Dieser Wert kann NULL sein, wenn diese Zeile verwendet wird, um das Vereinigungsergebnis anderer Zeilen zu beschreiben, z. B. die UNION-Anweisung:
Query-2 explain select zipcode from (select * from people a) b;

select_type
Query-3 explain select * from people where zipcode = 100000 union select * from people where zipcode = 200000;
Die Typen von SELECT-Anweisungen können wie folgt sein. 
EINFACH
PRIMÄR
in einer verschachtelten Abfrage ist das Äußerste Die SELECT-Anweisung ist die vorderste SELECT-Anweisung in einer UNION-Abfrage. Siehe Abfrage-2
undAbfrage-3.
UNIONDie zweite und die folgenden in UNION SELECT-Anweisung. Siehe Abfrage-3
.
DERIVED
FROM-Unteranweisung in der abgeleiteten Tabelle SELECT-Anweisung SELECT-Anweisung im Satz. Siehe Abfrage-2
.
UNIONSERGEBNIS
一个UNION查询的结果。见Query-3。 DEPENDENT UNION 顾名思义,首先需要满足UNION的条件,及UNION中第二个以及后面的SELECT语句,同时该语句依赖外部的查询。 Query-4中select id from people where zipcode = 200000的select_type为DEPENDENT UNION。你也许很奇怪这条语句并没有依赖外部的查询啊。 这里顺带说下MySQL优化器对IN操作符的优化,优化器会将IN中的uncorrelated subquery优化成一个correlated subquery(关于correlated subquery参见这里)。 类似这样的语句会被重写成这样: 所以Query-4实际上被重写成这样: 题外话:有时候MySQL优化器这种太过“聪明” 的做法会导致WHERE条件包含IN()的子查询语句性能有很大损失。可以参看《高性能MySQL第三版》6.5.1关联子查询一节。 SUBQUERY 子查询中第一个SELECT语句。 DEPENDENT SUBQUERY 和DEPENDENT UNION相对UNION一样。见Query-5。 除了上述几种常见的select_type之外还有一些其他的这里就不一一介绍了,不同MySQL版本也不尽相同。 显示的这一行信息是关于哪一张表的。有时候并不是真正的表名。 可以看到如果指定了别名就显示的别名。 还有 注意:MySQL对待这些表和普通表一样,但是这些“临时表”是没有任何索引的。 type列很重要,是用来说明表与表之间是如何进行关联操作的,有没有使用索引。MySQL中“关联”一词比一般意义上的要宽泛,MySQL认为任何一次查询都是一次“关联”,并不仅仅是一个查询需要两张表才叫关联,所以也可以理解MySQL是如何访问表的。主要有下面几种类别。 const 当确定最多只会有一行匹配的时候,MySQL优化器会在查询前读取它而且只读取一次,因此非常快。const只会用在将常量和主键或唯一索引进行比较时,而且是比较所有的索引字段。people表在id上有一个主键索引,在(zipcode,firstname,lastname)有一个二级索引。因此Query-8的type是const而Query-9并不是: 注意下面的Query-10也不能使用const table,虽然也是主键,也只会返回一条结果。 system 这是const连接类型的一种特例,表仅有一行满足条件。 eq_ref eq_ref类型是除了const外最好的连接类型,它用在一个索引的所有部分被联接使用并且索引是UNIQUE或PRIMARY KEY。 需要注意InnoDB和MyISAM引擎在这一点上有点差别。InnoDB当数据量比较小的情况type会是All。我们上面创建的people 和 people_car默认都是InnoDB表。 我们创建两个MyISAM表people2和people_car2试试: 我想这是InnoDB对性能权衡的一个结果。 eq_ref可以用于使用 = 操作符比较的带索引的列。比较值可以为常量或一个使用在该表前面所读取的表的列的表达式。如果关联所用的索引刚好又是主键,那么就会变成更优的const了: ref 这个类型跟eq_ref不同的是,它用在关联操作只使用了索引的最左前缀,或者索引不是UNIQUE和PRIMARY KEY。ref可以用于使用=或<=>操作符的带索引的列。 为了说明我们重新建立上面的people2和people_car2表,仍然使用MyISAM但是不给id指定primary key。然后我们分别给id和people_id建立非唯一索引。 然后再执行下面的查询: 看上面的Query-15,Query-16和Query-17,Query-18我们发现MyISAM在ref类型上的处理也是有不同策略的。 对于ref类型,在InnoDB上面执行上面三条语句结果完全一致。 fulltext 链接是使用全文索引进行的。一般我们用到的索引都是B树,这里就不举例说明了。 ref_or_null 该类型和ref类似。但是MySQL会做一个额外的搜索包含NULL列的操作。在解决子查询中经常使用该联接类型的优化。(详见这里)。 注意Query-20使用的并不是ref_or_null,而且InnnoDB这次表现又不相同(数据量大的情况下有待验证)。 index_merger 该联接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。关于索引合并优化看这里。 unique_subquery 该类型替换了下面形式的IN子查询的ref: unique_subquery是一个索引查找函数,可以完全替换子查询,效率更高。 index_subquery 该联接类型类似于unique_subquery。可以替换IN子查询,但只适合下列形式的子查询中的非唯一索引:<br/> range 只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引。key_len包含所使用索引的最长关键元素。在该类型中ref列为NULL。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range: 注意在我的测试中:发现只有id是主键或唯一索引时type才会为range。 这里顺便挑剔下MySQL使用相同的range来表示范围查询和列表查询。 但事实上这两种情况下MySQL如何使用索引是有很大差别的: 我们不是挑剔:这两种访问效率是不同的。对于范围条件查询,MySQL无法使用范围列后面的其他索引列了,但是对于“多个等值条件查询”则没有这个限制了。 ——出自《高性能MySQL第三版》 index 该联接类型与ALL相同,除了只有索引树被扫描。这通常比ALL快,因为索引文件通常比数据文件小。这个类型通常的作用是告诉我们查询是否使用索引进行排序操作。 至于什么情况下MySQL会利用索引进行排序,等有时间再仔细研究。最典型的就是order by后面跟的是主键。 ALL Der langsamste Weg ist der vollständige Tabellenscan. Generell: Die Leistung der oben genannten Verbindungstypen nimmt in der Reihenfolge (System>const), unterschiedlichen MySQL-Versionen, unterschiedlichen Speicher-Engines ab und selbst unterschiedliche Datenmengen können eine unterschiedliche Leistung erbringen. Die Spalte „possible_keys“ gibt an, welchen Index MySQL verwenden kann, um die Tabelle zu finden OK. Die Schlüsselspalte zeigt den Schlüssel (Index), den MySQL tatsächlich verwenden wollte. Wenn kein Index ausgewählt ist, ist der Schlüssel NULL. Um MySQL zu zwingen, den Index für die Spalte „posable_keys“ zu verwenden oder zu ignorieren, verwenden Sie FORCE INDEX, USE INDEX oder IGNORE INDEX in der Abfrage. In der Spalte „key_len“ wird die Schlüssellänge angezeigt, für deren Verwendung sich MySQL entschieden hat. Wenn der Schlüssel NULL ist, ist die Länge NULL. Die Länge des verwendeten Index. Je kürzer die Länge, desto besser, ohne dass die Genauigkeit verloren geht. Die Ref-Spalte zeigt, welche Spalte oder Konstante mit dem Schlüssel verwendet wird aus der Tabelle Zeilen auswählen in . rows-Spalte zeigt, was MySQL seiner Meinung nach wann tun muss Ausführen der Abfrage Anzahl der zu prüfenden Zeilen. Beachten Sie, dass es sich hierbei um eine Schätzung handelt. <br/>Extra ist eine weitere sehr wichtige Spalte in der EXPLAIN-Ausgabe. Die Spalten Zeigen Sie während des Abfragevorgangs einige detaillierte Informationen zu MySQL an. Es enthält viele Informationen, daher werde ich nur einige wichtige Punkte vorstellen. Filesort verwenden zeigt an, dass es sich um eine temporäre Tabelle handelt Im Allgemeinen weist dies darauf hin, dass die Abfrage optimiert werden muss. Auch wenn die Verwendung temporärer Tabellen nicht vermieden werden kann, sollte die Verwendung temporärer Festplattentabellen so weit wie möglich vermieden werden. Nicht vorhanden MYSQL optimiert LEFT JOIN, Once Es findet eine Zeile, die den LEFT JOIN-Kriterien entspricht, und sucht nicht weiter. Index verwenden Gibt an, dass die Abfrage Folgendes abdeckt index Ja, das ist eine gute Sache. MySQL filtert unerwünschte Datensätze direkt aus dem Index und gibt die Treffer zurück. Dies erfolgt durch die MySQL-Serviceschicht, es ist jedoch nicht erforderlich, zur Tabelle zurückzukehren, um Datensätze abzufragen. Indexbedingung verwenden Hier kommt MySQL 5.6 out Die neue Funktion heißt „Index Condition Push“. Um es einfach auszudrücken: MySQL war ursprünglich nicht in der Lage, Vorgänge wie „Like“ für Indizes auszuführen. Dies reduziert unnötige E/A-Vorgänge, kann jedoch nur für sekundäre Indizes verwendet werden. Verwenden von where Verwenden der WHERE-Klausel zur Einschränkung Welche Zeilen passen zur nächsten Tabelle oder werden an den Benutzer zurückgegeben? Hinweis: Die Verwendung von „wo“ in der Spalte „Extra“ bedeutet, dass der MySQL-Server die Speicher-Engine an die Serviceschicht zurückgibt und dann die WHERE-Bedingungsfilterung anwendet. Der Ausgabeinhalt von EXPLAIN wurde grundsätzlich eingeführt. Es gibt auch einen erweiterten Befehl namens EXPLAIN EXTENDED, der mit dem kombiniert werden kann Weitere Informationen finden Sie unter dem Befehl SHOW WARNINGS. Eines der nützlicheren Dinge ist, dass Sie die SQL nach der Rekonstruktion durch den MySQL-Optimierer sehen können. Okay, das war's mit EXPLAIN. Diese Inhalte sind zwar online verfügbar, aber Sie werden mehr beeindruckt sein, wenn Sie sie selbst üben. Im nächsten Abschnitt werden SHOW PROFILE, langsame Abfrageprotokolle und einige Tools von Drittanbietern vorgestellt. <br/> Bei OAuth geht es um die Autorisierung Der Standard ist weltweit weit verbreitet. Die aktuelle Version ist Version 2.0. Dieser Artikel bietet eine prägnante und beliebte Erläuterung der Designideen und des Betriebsprozesses von OAuth 2.0. Das Hauptreferenzmaterial ist RFC 6749. Um die anwendbaren Szenarien von OAuth zu verstehen, möchte ich ein hypothetisches Beispiel geben. Es gibt eine „Cloud-Printing“-Website, auf der von Nutzern bei Google gespeicherte Fotos ausgedruckt werden können. Um diesen Dienst nutzen zu können, müssen Nutzer „Cloud Print“ erlauben, ihre bei Google gespeicherten Fotos auszulesen. Das Problem ist, dass Google „Cloud Print“ nur erlaubt, diese Fotos mit der Genehmigung des Nutzers zu lesen. Wie erhält „Cloud Print“ also die Autorisierung des Benutzers? Die traditionelle Methode besteht darin, dass der Benutzer „Cloud Print“ seinen Google-Benutzernamen und sein Passwort mitteilt, woraufhin Letzterer die Fotos des Benutzers lesen kann. Dieser Ansatz weist mehrere schwerwiegende Mängel auf. (1) „Cloud Printing“ speichert das Passwort des Benutzers für nachfolgende Dienste, was sehr unsicher ist. (2) Google muss die Passwort-Anmeldung bereitstellen, und wir wissen, dass eine einfache Passwort-Anmeldung nicht sicher ist. (3) „Cloud Print“ hat das Recht, alle in Google gespeicherten Daten des Nutzers zu erhalten, und Nutzer können den Umfang und die Gültigkeitsdauer der „Cloud Print“-Autorisierung nicht einschränken. (4) Nur durch eine Änderung des Passworts kann der Benutzer die dem „Cloud Printing“ gewährte Befugnis zurückerhalten. Dadurch werden jedoch alle anderen vom Benutzer autorisierten Drittanbieteranwendungen ungültig. (5) Solange eine Drittanbieteranwendung geknackt wird, führt dies zum Verlust von Benutzerkennwörtern und zum Verlust aller passwortgeschützten Daten. OAuth wurde geboren, um die oben genannten Probleme zu lösen. Bevor Sie OAuth 2.0 im Detail erklären, müssen Sie einige spezielle Substantive verstehen. Sie sind für das Verständnis der folgenden Erläuterungen, insbesondere der einzelnen Bilder, von entscheidender Bedeutung. (1) Drittanbieteranwendung: Drittanbieteranwendung, in diesem Artikel auch „Client“ genannt, d. h. „Cloud-Druck“ im vorherigen Beispiel Abschnitt ". (2)HTTP-Dienst: HTTP-Dienstanbieter, in diesem Artikel als „Dienstanbieter“ bezeichnet, im Beispiel im vorherigen Abschnitt Google. (3) Ressourcenbesitzer: Ressourcenbesitzer, in diesem Artikel auch „Benutzer“ genannt. (4)Benutzeragent: Benutzeragent, bezieht sich in diesem Artikel auf den Browser. (5)Autorisierungsserver: Authentifizierungsserver, d. h. ein Server, der speziell vom Dienstanbieter für die Authentifizierung verwendet wird. (6) Ressourcenserver: Ressourcenserver, also der Server, auf dem der Dienstanbieter benutzergenerierte Ressourcen speichert. Es und der Authentifizierungsserver können derselbe Server oder verschiedene Server sein. Nachdem man die oben genannten Begriffe kennt, ist es nicht schwer zu verstehen, dass die Funktion von OAuth darin besteht, dem „Client“ zu ermöglichen, die Autorisierung des „Benutzers“ auf sichere und kontrollierbare Weise zu erhalten und zu interagieren mit dem „Dienstleister“. OAuth richtet eine Autorisierungsschicht zwischen dem „Client“ und dem „Dienstanbieter“ ein. Der „Client“ kann sich nicht direkt beim „Dienstanbieter“ anmelden, sondern kann sich nur bei der Autorisierungsschicht anmelden, um den Benutzer vom Client zu unterscheiden. Das Token, mit dem sich der „Client“ bei der Autorisierungsschicht anmeldet, unterscheidet sich vom Passwort des Benutzers. Benutzer können beim Anmelden den Berechtigungsbereich und die Gültigkeitsdauer des Autorisierungsschicht-Tokens angeben. Nachdem sich der „Client“ bei der Autorisierungsschicht angemeldet hat, öffnet der „Dienstanbieter“ die gespeicherten Informationen des Benutzers für den „Client“ basierend auf dem Berechtigungsumfang und der Gültigkeitsdauer des Tokens. Der Betriebsprozess von OAuth 2.0 ist wie unten dargestellt, Auszug aus RFC 6749. (A) Nachdem der Benutzer den Client geöffnet hat, verlangt der Client vom Benutzer eine Autorisierung. (B) Der Benutzer erklärt sich damit einverstanden, dem Kunden eine Autorisierung zu erteilen. (C) Der Client nutzt die im vorherigen Schritt erhaltene Autorisierung, um ein Token vom Authentifizierungsserver zu beantragen. (D) Nachdem der Authentifizierungsserver den Client authentifiziert hat, bestätigt er die Richtigkeit und stimmt der Ausstellung des Tokens zu. (E) Der Client verwendet das Token, um es beim Ressourcenserver anzufordern, um Ressourcen zu erhalten. (F)资源服务器确认令牌无误,同意向客户端开放资源。 不难看出来,上面六个步骤之中,B是关键,即用户怎样才能给于客户端授权。有了这个授权以后,客户端就可以获取令牌,进而凭令牌获取资源。 下面一一讲解客户端获取授权的四种模式。 客户端必须得到用户的授权(authorization grant),才能获得令牌(access token)。OAuth 2.0定义了四种授权方式。 授权码模式(authorization code) 简化模式(implicit) 密码模式(resource owner password credentials) 客户端模式(client credentials) 授权码模式(authorization code)是功能最完整、流程最严密的授权模式。它的特点就是通过客户端的后台服务器,与"服务提供商"的认证服务器进行互动。 它的步骤如下: (A)用户访问客户端,后者将前者导向认证服务器。 (B)用户选择是否给予客户端授权。 (C)假设用户给予授权,认证服务器将用户导向客户端事先指定的"重定向URI"(redirection URI),同时附上一个授权码。 (D)客户端收到授权码,附上早先的"重定向URI",向认证服务器申请令牌。这一步是在客户端的后台的服务器上完成的,对用户不可见。 (E)认证服务器核对了授权码和重定向URI,确认无误后,向客户端发送访问令牌(access token)和更新令牌(refresh token)。 下面是上面这些步骤所需要的参数。 A步骤中,客户端申请认证的URI,包含以下参数: response_type:表示授权类型,必选项,此处的值固定为"code" client_id:表示客户端的ID,必选项 redirect_uri:表示重定向URI,可选项 scope:表示申请的权限范围,可选项 state:表示客户端的当前状态,可以指定任意值,认证服务器会原封不动地返回这个值。 下面是一个例子。 C步骤中,服务器回应客户端的URI,包含以下参数: code:表示授权码,必选项。该码的有效期应该很短,通常设为10分钟,客户端只能使用该码一次,否则会被授权服务器拒绝。该码与客户端ID和重定向URI,是一一对应关系。 state:如果客户端的请求中包含这个参数,认证服务器的回应也必须一模一样包含这个参数。 下面是一个例子。 D步骤中,客户端向认证服务器申请令牌的HTTP请求,包含以下参数: grant_type:表示使用的授权模式,必选项,此处的值固定为"authorization_code"。 code:表示上一步获得的授权码,必选项。 redirect_uri:表示重定向URI,必选项,且必须与A步骤中的该参数值保持一致。 client_id:表示客户端ID,必选项。 下面是一个例子。 E步骤中,认证服务器发送的HTTP回复,包含以下参数: access_token:表示访问令牌,必选项。 token_type:表示令牌类型,该值大小写不敏感,必选项,可以是bearer类型或mac类型。 expires_in:表示过期时间,单位为秒。如果省略该参数,必须其他方式设置过期时间。 refresh_token:表示更新令牌,用来获取下一次的访问令牌,可选项。 scope:表示权限范围,如果与客户端申请的范围一致,此项可省略。 下面是一个例子。 从上面代码可以看到,相关参数使用JSON格式发送(Content-Type: application/json)。此外,HTTP头信息中明确指定不得缓存。 简化模式(implicit grant type)不通过第三方应用程序的服务器,直接在浏览器中向认证服务器申请令牌,跳过了"授权码"这个步骤,因此得名。所有步骤在浏览器中完成,令牌对访问者是可见的,且客户端不需要认证。 它的步骤如下: (A)客户端将用户导向认证服务器。 (B)用户决定是否给于客户端授权。 (C)假设用户给予授权,认证服务器将用户导向客户端指定的"重定向URI",并在URI的Hash部分包含了访问令牌。 (D)浏览器向资源服务器发出请求,其中不包括上一步收到的Hash值。 (E)资源服务器返回一个网页,其中包含的代码可以获取Hash值中的令牌。 (F)浏览器执行上一步获得的脚本,提取出令牌。 (G)浏览器将令牌发给客户端。 下面是上面这些步骤所需要的参数。 A步骤中,客户端发出的HTTP请求,包含以下参数: response_type:表示授权类型,此处的值固定为"token",必选项。 client_id:表示客户端的ID,必选项。 redirect_uri:表示重定向的URI,可选项。 scope:表示权限范围,可选项。 state:表示客户端的当前状态,可以指定任意值,认证服务器会原封不动地返回这个值。 下面是一个例子。 C步骤中,认证服务器回应客户端的URI,包含以下参数: access_token:表示访问令牌,必选项。 token_type:表示令牌类型,该值大小写不敏感,必选项。 expires_in:表示过期时间,单位为秒。如果省略该参数,必须其他方式设置过期时间。 scope:表示权限范围,如果与客户端申请的范围一致,此项可省略。 state:如果客户端的请求中包含这个参数,认证服务器的回应也必须一模一样包含这个参数。 下面是一个例子。 在上面的例子中,认证服务器用HTTP头信息的Location栏,指定浏览器重定向的网址。注意,在这个网址的Hash部分包含了令牌。 根据上面的D步骤,下一步浏览器会访问Location指定的网址,但是Hash部分不会发送。接下来的E步骤,服务提供商的资源服务器发送过来的代码,会提取出Hash中的令牌。 密码模式(Resource Owner Password Credentials Grant)中,用户向客户端提供自己的用户名和密码。客户端使用这些信息,向"服务商提供商"索要授权。 在这种模式中,用户必须把自己的密码给客户端,但是客户端不得储存密码。这通常用在用户对客户端高度信任的情况下,比如客户端是操作系统的一部分,或者由一个著名公司出品。而认证服务器只有在其他授权模式无法执行的情况下,才能考虑使用这种模式。 它的步骤如下: (A)用户向客户端提供用户名和密码。 (B)客户端将用户名和密码发给认证服务器,向后者请求令牌。 (C)认证服务器确认无误后,向客户端提供访问令牌。 B步骤中,客户端发出的HTTP请求,包含以下参数: grant_type:表示授权类型,此处的值固定为"password",必选项。 username:表示用户名,必选项。 password:表示用户的密码,必选项。 scope:表示权限范围,可选项。 下面是一个例子。 C步骤中,认证服务器向客户端发送访问令牌,下面是一个例子。 上面代码中,各个参数的含义参见《授权码模式》一节。 整个过程中,客户端不得保存用户的密码。 客户端模式(Client Credentials Grant)指客户端以自己的名义,而不是以用户的名义,向"服务提供商"进行认证。严格地说,客户端模式并不属于OAuth框架所要解决的问题。在这种模式中,用户直接向客户端注册,客户端以自己的名义要求"服务提供商"提供服务,其实不存在授权问题。 它的步骤如下: (A)客户端向认证服务器进行身份认证,并要求一个访问令牌。 (B)认证服务器确认无误后,向客户端提供访问令牌。 A步骤中,客户端发出的HTTP请求,包含以下参数: granttype:表示授权类型,此处的值固定为"clientcredentials",必选项。 scope:表示权限范围,可选项。 认证服务器必须以某种方式,验证客户端身份。 B步骤中,认证服务器向客户端发送访问令牌,下面是一个例子。 上面代码中,各个参数的含义参见《授权码模式》一节。 如果用户访问的时候,客户端的"访问令牌"已经过期,则需要使用"更新令牌"申请一个新的访问令牌。 客户端发出更新令牌的HTTP请求,包含以下参数: granttype:表示使用的授权模式,此处的值固定为"refreshtoken",必选项。 refresh_token:表示早前收到的更新令牌,必选项。 scope:表示申请的授权范围,不可以超出上一次申请的范围,如果省略该参数,则表示与上一次一致。 下面是一个例子。 (完) <br/> yii2框架的安装我们在之前文章中已经提到下面我们开始了解YII2框架 强大的YII2框架网上指南:http://www.yii-china.com/doc/detail/1.html?postid=278或者<br/> http://www.yiichina.com/doc/guide/2.0<br/> Yii2的应用结构:<br/> 目录篇:<br/> <br/> <br/> <br/>3.console Die Konsolenanwendung enthält die vom System benötigten Konsolenbefehle. <br/> Unter ihnen: config ist eine allgemeine Konfiguration. Diese Konfigurationen gelten für das Front- und Backend sowie die Befehlszeile. Mail sind die E-Mail-bezogenen Layoutdateien des Front- und Backends der Anwendung und der Befehlszeile. Modelle sind Datenmodelle, die sowohl im Front- und Backend als auch in der Befehlszeile verwendet werden können. Dies ist auch der wichtigste Teil von Gemeinsamkeit. <br/> Die im öffentlichen Verzeichnis (Common) enthaltenen Dateien werden für die gemeinsame Nutzung mit anderen Anwendungen verwendet. Beispielsweise muss möglicherweise jede Anwendung über ActiveRecord auf die Datenbank zugreifen. Daher können wir die AR-Modellklasse im gemeinsamen Verzeichnis platzieren. Wenn einige Helfer oder Widgets in mehreren Anwendungen verwendet werden, sollten wir diese ebenfalls in einem gemeinsamen Verzeichnis ablegen, um eine Duplizierung des Codes zu vermeiden. Wie wir gleich erläutern werden, können Anwendungen auch Teile einer gemeinsamen Konfiguration teilen. Daher können wir auch allgemeine Konfigurationen im Konfigurationsverzeichnis speichern. <br/>Bei der Entwicklung eines Großprojekts mit einem langen Entwicklungszyklus müssen wir die Datenbankstruktur ständig anpassen. Aus diesem Grund können wir auch die DB-Migrationsfunktion nutzen, um Datenbankänderungen im Auge zu behalten. Wir platzieren außerdem alle DB-Migrationsverzeichnisse im gemeinsamen Verzeichnis. <br/><br/>5.Umgebung Jede Yii-Umgebung besteht aus einer Reihe von Konfigurationsdateien, einschließlich des Eingabeskripts index.php und verschiedener Konfigurationsdateien. Tatsächlich sind sie alle im Verzeichnis /environments abgelegt <br/> Verzeichnis dev Verzeichnis prod Datei index.php Darunter haben dev und prod die gleiche Struktur und enthalten 4 Verzeichnisse bzw. 1 Datei: Frontend-Verzeichnis, das für Front-End-Anwendungen verwendet wird und die Konfiguration enthält zum Speichern von Konfigurationsdateien. Verzeichnis und Webverzeichnis, in dem Web-Eingabeskripte gespeichert werden Backend-Verzeichnis, das für Hintergrundanwendungen verwendet wird. Der Inhalt ist derselbe wie im Frontend Konsolenverzeichnis, verwendet für Die Befehlszeilenanwendung enthält nur das Konfigurationsverzeichnis, da für die Befehlszeilenanwendung kein Webeingabeskript erforderlich ist und daher kein Webverzeichnis vorhanden ist. Gemeinsames Verzeichnis wird für gemeinsame Umgebungskonfigurationen verschiedener Webanwendungen und Befehlszeilenanwendungen verwendet. Es enthält nur das Konfigurationsverzeichnis, da verschiedene Anwendungen nicht dasselbe Eingabeskript verwenden können. Beachten Sie, dass die Ebene dieser Gemeinsamkeit niedriger ist als die Ebene der Umgebung. Mit anderen Worten, ihre Universalität ist nur in einer bestimmten Umgebung, nicht in allen Umgebungen, vorhanden. yii-Datei ist die Eingabeskriptdatei für Befehlszeilenanwendungen. Für die überall verstreuten Web- und Konfigurationsverzeichnisse gibt es auch etwas gemeinsam. Jedes Webverzeichnis speichert das Eingabeskript der Webanwendung, eine index.php und eine Testversion von index-test.php Alle Konfigurationsverzeichnisse speichern lokale Konfigurationsinformationen main-local.php und params-local.php <br/>6.vendor 1、入口文件路径:<br/> http://127.0.0.1/yii2/advanced/frontend/web/index.php 每个应用都有一个入口脚本 web/index.PHP,这是整个应用中唯一可以访问的 PHP 脚本。一个应用处理请求的过程如下: 1.用户向入口脚本 web/index.php 发起请求。 <br/>2.入口脚本加载应用配置并创建一个应用实例去处理请求。 <br/>3.应用通过请求组件解析请求的路由。 <br/>4.应用创建一个控制器实例去处理请求。 <br/>5.控制器创建一个操作实例并针对操作执行过滤器。 <br/>6.如果任何一个过滤器返回失败,则操作退出。 <br/>7.如果所有过滤器都通过,操作将被执行。 <br/>8.操作会加载一个数据模型,或许是来自数据库。<br/>9.操作会渲染一个视图,把数据模型提供给它。 <br/>10.渲染结果返回给响应组件。 <br/>11.响应组件发送渲染结果给用户浏览器 可以看到中间有模型-视图-控制器 ,即常说的MVC。入口脚本并不会处理请求,而是把请求交给了应用主体,在处理请求时,会用到控制器,如果用到数据库中的东西,就会去访问模型,如果处理请求完成,要返回给用户信息,则会在视图中回馈要返回给用户的内容。<br/> 2、为什么我们访问方法会出现url加密呢? 我们找到文件:vendor/yiisoft/yii2/web/UrlManager.php <br/> MVC篇: 一、控制器详解: 1、修改默认控制器和方法 修改全局控制器:打开vendor/yiisoft/yii2/web/Application.php eg: 2、建立控制器示例:StudentController.php //命名空间<br/> <br/> <br/><br/> //显示视图<br/> return $this->render('add'); 默认.php<br/> return $this->render('upda',["data"=>$data]); <br/><br/> } <br/>}<br/><br/> 二、模型层详解 简单模型建立: <br/> <br/><br/> 三、视图层详解首先在frontend下建立与控制器名一致的文件(小写)eg:student 在文件下建立文件<br/> eg:index.php<br/>每一个controller对应一个view的文件夹,但是视图文件yii不要求是HTML,而是php,所以每个视图文件php里面都是视图片段: 当然了,视图与模板之间还有数据传递以及继承覆盖的功能。<br/><br/><br/><br/><br/><br/> YII2框架数据的运用 1、数据库连接 简介 一个项目根据需要会要求连接多个数据库,那么在yii2中如何链接多数据库呢?其实很简单,在配置文件中稍加配置即可完成。 配置 打开数据库配置文件common\config\main-local.php,在原先的db配置项下面添加db2,配置第二个数据库的属性即可 [php] view plain copy 如上配置就可以完成yii2连接多个数据库的功能,但还是需要注意几个点 如果使用的数据库前缀 在建立模型时 这样: eg:这个库叫 haiyong_test return {{%test}}<br/> 应用 1.我们在hyii数据库中新建一个测试表test 2.通过gii生成模型,这里需要注意的就是数据库链接ID处要改成db2<br/> 3.查看生成的模型,比正常的model多了红色标记的地方 所以各位童鞋,如果使用多数据配置,在建db2的模型的时候,也要加上上图红色的代码。 好了,以上步骤就完成了,yii2的多数据库配置,配置完成之后可以和原因一样使用model或者数据库操作 2、数据操作: <br/>方式一:使用createCommand()函数<br/> 增加 <br/> 获取自增id [php] view plain copy 批量插入数据 [php] view plain copy 修改 [php] view plain copy 方式二:模型处理数据(优秀程序媛必备)!! <br/> 新增(因为save方法有点low)所以自己在模型层中定义:add和addAll方法<br/> 注意:!!!当setAttributes($attributes,fase);时不用设置rules规则,否则则需要设置字段规则;<br/> 删除<br/> 使用model::delete()进行删除 [php] view plain copy 直接删除:删除年龄为30的所有用户 [php] view plain copy 根据主键删除:删除主键值为1的用户<br/> [php] view plain copy <br/> <br/> <br/> <br/> <br/> 修改<br/> 使用model::save()进行修改 <br/> <br/> <br/> 直接修改:修改用户test的年龄为40<br/> <br/> <br/> 基础查询 <br/> <br/> 关联查询 <br/> <br/> <br/> 翻译 2015年07月30日 10:29:03 <br/> yii2 rbac 详解DbManager <br/> 1.yii config文件配置(我用的高级模板)(配置在common/config/main-local.php或者main.php) 'authManager' => [ 'class' => 'yiirbacDbManager', 'itemTable' => ],<br/> 2.Natürlich kann die Standardrolle auch in der Konfiguration eingestellt werden, aber ich habe es nicht geschrieben. Rbac unterstützt zwei Klassen, PhpManager und DbManager. Hier verwende ich DbManager. yii migrate (führen Sie diesen Befehl aus, um die Benutzertabelle zu generieren) <br/>yii migrate --migrationPath=@yii/rbac/migrations/ Führen Sie diesen Befehl aus, um die Berechtigungsdatentabelle zu generieren Die Abbildung unten<br/>3.yii rbac betreibt tatsächlich 4 Tabellen <br/> 推荐文章 微信H5支付完整版含PHP回调页面.代码精简2018年2月 <br/>支付宝手机支付,本身有提供一个手机网站支付DEMO,是lotusphp版本的,里面有上百个文件,非常复杂.本文介绍的接口, <br/>只需通过一个PHP文件即可实现手机支付宝接口的付款,非常简洁,并兼容微信. <br/>代码在最下面. 注意事项(重要): <br/>一,支付宝接口已经升级了加密方式,现在申请的接口都是公钥加私钥的加密形式.公钥与私钥都需要申请者自己生成,而且是成对的,不能拆开用.并把公钥保存到支付宝平台,该公钥对应的私钥不需要保存在支付宝,只能自己保存,并放在api支付宝接口文件中使用.下面会提到. APPID 应该填哪个呢? 这个是指开放平台id,格式应该填2018或2016等日期开头的,不要填合作者pid,那个pid新版不需要的.APPID下面还对应一个网关.这个也要对应填写.正式申请通过的网关为https://openapi.alipay.com/gateway.do 如果你是沙箱测试账号, <br/>则填https://openapi.alipaydev.com/gateway.do 注意区别 <br/>密钥生成方式为, https://docs.open.alipay.com/291/105971 打开这个地址,下载该相应工具后,解压打开文件夹,运行“RSA签名验签工具.bat”这个文件后.打开效果如下图 <br/>如果你的网站是jsp的,密钥格式如下图,点击选择第一个pkcs8的,如果你的网站是php,asp等,则点击pkcs1 <br/>密钥长度统一为2048位. <br/>然后点击 生成密钥 <br/>然后,再点击打开密钥文件路径按钮.即可看到生成的密钥文件,打开txt文件.即可看到生成的公钥与私钥了. <br/>公钥复制后(注意不要换行),需提供给支付宝账号管理者,并上传到支付宝开放平台。如下图第二 <br/>界面示例: <br/> 二,如下,同步回调地址与异步回调地址的区别. <br/>同步地址是指用户付款成功,他自动跳转到这个地址,以get方式返回,你可以设置为跳转回会员中心,也可以转到网站首页或充值日志页面,通过$_GET 的获取支付宝发来的签名,金额等参数.然后进本地数据库验证支付是否正常. <br/>而异步回调地址指支付成功后,支付宝会自动多次的访问你的这个地址,以静默方式进行,用户感受不到地址的跳转.注意,异步回调地址中不能有问号,&等符号,可以放在根目录中.如果你设置为notify_url.php,则你也需要在notify_url.php这个文件中做个判断.比如如果用户付款成功了.则用户的余额则增加多少,充值状态由付款中.修改为付款成功等. 1 2 三,orderName 订单名称,注意编码,否则签名可能会失败 <br/>向支付宝发起支付请求时,有个orderName 订单名称参数.注意这个参数的编码,如果你的本页面是gb2312编码,$this->charset = ‘UTF-8’这个参数最好还是UTF-8,不需要修改.否则签名时,可能会出现各种问题.,可用下面的方法做个转码. 1 四,微信中如何使用支付宝 <br/>支付宝有方案,可以进这个页面把ap.js及pay.htm下载后,保存到你的支付文件pay.php文件所在的目录中. <br/>方案解释,会员在微信中打开你网站的页面,登录,并点击充值或购买链接时,他如果选择支付宝付款,则ap.js会自动弹出这个pay.htm页面,提示你在右上角选择用浏览器中打开,打开后,自动跳转到支付宝app中,不需要重新登录原网站的会员即可完成充值,并跳转回去. <br/>注意,在你的客户从微信转到手机浏览器后,并没有让你重新登录你的商城网站,这是本方案的优势所在. <br/>https://docs.open.alipay.com/203/105285/ 五,如果你申请的支付宝手机支付接口在审核中,则可以先申请一个沙箱测试账号,该账号申请后就可以使用非常方便.同时会提供你一个支付宝商家账号及买家测试账号.登录即可测试付款情况. 代码如下(参考) <br/>一.表单付款按钮所在页面代码 <br/> 二,pay.php页面代码(核心代码) 三,回调页面案例一,即notify_url.php文件. post回调, 四.异步回调案例2, 与上面三是重复的,可选择其中一个.本回调可直接放根目录中 如果你服务器不支持mysqli 就替换为mysql 测试回调时, 请先直接访问本页面,进行测试.订单号可以先写一个固定值. 参考原文 <br/>http://blog.csdn.net/jason19905/article/details/78636716 <br/>https://github.com/dedemao/alipay <br/> 抓包就是把网络数据包用软件截住或者纪录下来,这样做我们可以分析网络数据包,可以修改它然后发送一个假包给服务器,这种技术多应用于网络游戏外挂的制作方面或者密码截取等等 常用的几款抓包工具!<br/>标签: 软件测试软件测试方法软件测试学习<br/>原创来自于我们的微信公众号:软件测试大师 <br/>最近很多同学,说面试的时候被问道,有没有用过什么抓包工具,其实抓包工具并没有什么很难的工具,只要你知道你要用抓包是干嘛的,就知道该怎么用了!一般<br/>对于测试而言,并不需要我们去做断点或者是调试代码什么的,只需要用一些抓包工具抓取发送给服务器的请求,观察下它的请求时间还有发送内容等等,有时候,<br/>可能还会用到这个去观察某个页面下载组件消耗时间太长,找出原因,要开发做性能调优。那么下面就给大家推荐几款抓包工具,好好学习下,下次面试也可以拿来<br/>装一下了! <br/>1<br/>Flidder<br/>Fiddler是位于客户端和服务器端的HTTP代理,也是目前最常用的http抓包工具之一 。 它能够记录客户端和服务器之间的所有 <br/>HTTP请求,可以针对特定的HTTP请求,分析请求数据、设置断点、调试web应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是<br/>web调试的利器。<br/>小编发现了有个兄台写的不错的文章,分享给大家,有兴趣的同学,可以自己去查阅并学习下,反正本小编花了点时间就学会了,原来就这么回事!作为测试学会这点真的是足够用了!<br/>学习链接如下:<br/>http://blog.csdn.net/ohmygirl/article/details/17846199<br/>http://blog.csdn.net/ohmygirl/article/details/17849983<br/>http://blog.csdn.net/ohmygirl/article/details/17855031 2<br/>Httpwatch<br/>火狐浏览器下有著名的httpfox,而HttpWatch则是IE下强大的网页数据分析工具。教程小编也不详述了,找到了一个超级棒的教程!真心很赞!要想学习的同学,可以点击链接去感受下!<br/>http://jingyan.baidu.com/article/5553fa820539ff65a339345d.html <br/>3其他浏览器的内置抓包工具<br/>如果用过Firefox的F12功能键,应该也知道这里也有网络抓包的工具,是内置在浏览器里面的,貌似现在每款浏览器都有这个内置的抓包工具,虽然没有上面两个工具强大,但是对于测试而言,我觉得是足够了!下面是一个非常详细的教程,大家可以去学习下。<br/>http://jingyan.baidu.com/article/3c343ff703fee20d377963e7.html 对于想学习点新知识去面试装逼的同学,小编只能帮你们到这里了,要想学习到新知识,除了动手指去点击这些链接,还需要你们去动脑好好学习下! <br/> <br/> 超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。 为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。 一、HTTP和HTTPS的基本概念 HTTP:是互联网上应用最为广泛的一种网络协议,是一个客户端和服务器端请求和应答的标准(TCP),用于从WWW服务器传输超文本到本地浏览器的传输协议,它可以使浏览器更加高效,使网络传输减少。 HTTPS: Es handelt sich um einen HTTP-Kanal, der auf Sicherheit abzielt. Einfach ausgedrückt handelt es sich um eine sichere Version von HTTP, d SSL. Die Hauptfunktionen des HTTPS-Protokolls können in zwei Arten unterteilt werden: Die eine besteht darin, einen Informationssicherheitskanal einzurichten, um die Sicherheit der Datenübertragung zu gewährleisten. Die andere besteht darin, die Authentizität der Website zu bestätigen. 2. Was ist der Unterschied zwischen HTTP und HTTPS? Die vom HTTP-Protokoll übertragenen Daten sind unverschlüsselt, also im Klartext. Daher ist es sehr unsicher, das HTTP-Protokoll zur Übertragung privater Informationen zu verwenden Kann verschlüsselt und übertragen werden, Netscape hat das SSL-Protokoll (Secure Sockets Layer) entwickelt, um die vom HTTP-Protokoll übertragenen Daten zu verschlüsseln, und so wurde HTTPS geboren. Einfach ausgedrückt ist das HTTPS-Protokoll ein Netzwerkprotokoll, das auf dem SSL+HTTP-Protokoll basiert und eine verschlüsselte Übertragung und Identitätsauthentifizierung durchführen kann. Es ist sicherer als das http-Protokoll. Die Hauptunterschiede zwischen HTTPS und HTTP sind wie folgt: 1. Für das https-Protokoll ist die Beantragung eines Zertifikats bei einer Zertifizierungsstelle erforderlich. Im Allgemeinen sind weniger kostenlose Zertifikate erforderlich . 2. http ist ein Hypertext-Übertragungsprotokoll und Informationen werden im Klartext übertragen, während https ein sicheres SSL-verschlüsseltes Übertragungsprotokoll ist. 3. http und https verwenden völlig unterschiedliche Verbindungsmethoden und verwenden unterschiedliche Ports. Ersteres ist 80 und letzteres ist 443. 4. Die HTTP-Verbindung ist sehr einfach und zustandslos; das HTTPS-Protokoll ist ein Netzwerkprotokoll, das auf dem SSL+HTTP-Protokoll basiert und eine verschlüsselte Übertragung und Identitätsauthentifizierung durchführen kann und sicherer als das HTTP-Protokoll ist. 3. Wie HTTPS funktioniert Wir alle wissen, dass HTTPS Informationen verschlüsseln kann, um zu verhindern, dass Dritte an sensible Informationen gelangen, so wie es bei vielen Bank-Websites oder E-Mail-Adressen der Fall ist Sicher. Übergeordnete Dienste verwenden das HTTPS-Protokoll. 1. Der Client initiiert eine HTTPS-Anfrage Dazu gibt es nichts zu sagen. Der Benutzer gibt eine https-URL in den Browser ein und verbindet sich dann mit Port 443 Der Server. 2. Serverkonfiguration Ein Server, der das HTTPS-Protokoll verwendet, muss über einen Satz digitaler Zertifikate verfügen. Sie können diese selbst erstellen oder bei der Organisation beantragen ist, dass das Zertifikat von Ihnen selbst ausgestellt werden muss, bevor Sie weiterhin darauf zugreifen können. Wenn Sie ein von einem vertrauenswürdigen Unternehmen angewendetes Zertifikat verwenden, wird die Eingabeaufforderungsseite nicht angezeigt (startssl ist eine gute Wahl). mit 1 Jahr kostenlosem Service). Dieses Zertifikat ist eigentlich ein Paar aus öffentlichem Schlüssel und privatem Schlüssel. Wenn Sie den öffentlichen Schlüssel und den privaten Schlüssel nicht verstehen, können Sie es sich als Schlüssel und Schloss vorstellen, aber Sie sind der Einzige Die Welt, die diesen Schlüssel hat, kann das Schloss an andere weitergeben, und andere können dieses Schloss verwenden, um wichtige Dinge zu verschließen und sie dann an Sie zu senden. Weil Sie der Einzige sind, der diesen Schlüssel hat, können nur Sie sehen, was verschlossen ist durch dieses Schloss. 3. Übertragen Sie das Zertifikat Dieses Zertifikat ist eigentlich ein öffentlicher Schlüssel, aber es enthält viele Informationen, wie z. B. die ausstellende Behörde des Zertifikats, die Ablaufzeit , usw. 4. Client-Parsing-Zertifikat Dieser Teil der Arbeit wird vom TLS des Clients erledigt. Zunächst wird überprüft, ob der öffentliche Schlüssel gültig ist, z. B. die Ausstellung Berechtigung und Ablaufzeit. Wenn eine Ausnahme gefunden wird, wird ein Warnfeld angezeigt, das darauf hinweist, dass ein Problem mit dem Zertifikat vorliegt. Wenn es kein Problem mit dem Zertifikat gibt, generieren Sie einen Zufallswert und verwenden Sie dann das Zertifikat, um den Zufallswert zu verschlüsseln. Sperren Sie den Zufallswert wie oben erwähnt mit einer Sperre, sodass Sie keinen haben Der gesperrte Inhalt ist nicht verfügbar. 5. Übermittlung verschlüsselter Informationen Dieser Teil überträgt einen zufälligen Wert, der mit einem Zertifikat verschlüsselt ist. Der Zweck besteht darin, dass der Server diesen zufälligen Wert erhält. Über diesen Zufallswert können der Client und die Kommunikation auf der Serverseite ver- und entschlüsselt werden. 6. Informationen zur Entschlüsselung des Dienstsegments Nachdem der Server sie mit dem privaten Schlüssel entschlüsselt hat, erhält er den vom Client übergebenen Zufallswert (privaten Schlüssel) und dann Der Inhalt wird durch diesen Wert symmetrisch verschlüsselt. Bei der sogenannten symmetrischen Verschlüsselung werden die Informationen und der private Schlüssel durch einen bestimmten Algorithmus gemischt, sodass der Inhalt nicht abgerufen werden kann und sowohl der Client als auch der private Schlüssel nicht bekannt sind Der Server kennt zufällig den privaten Schlüssel. Solange der Verschlüsselungsalgorithmus leistungsstark genug ist, ist der private Schlüssel komplex genug und die Daten sind sicher genug. 7. Verschlüsselte Informationen übertragen Bei diesem Teil der Informationen handelt es sich um die durch den privaten Schlüssel im Servicesegment verschlüsselten Informationen, die auf dem Client wiederhergestellt werden können. 8. Der Client entschlüsselt die Informationen Der Client verwendet den zuvor generierten privaten Schlüssel, um die vom Dienstsegment übergebenen Informationen zu entschlüsseln, und erhält dann den entschlüsselten Inhalt. Der gesamte Prozess Selbst wenn ein Dritter die Daten abfängt, kann er nichts dagegen tun. 6. Vorteile von HTTPS Gerade weil HTTPS sehr sicher ist, finden Angreifer keinen Ansatzpunkt HTTPS Die Vorteile sind wie folgt: 1. SEO-Aspekt Google hat den Suchmaschinenalgorithmus im August 2014 angepasst und erklärt, dass „im Vergleich zu gleichwertigen HTTP-Websites HTTPS verwendet wird.“ -Verschlüsselte Websites werden in den Suchergebnissen höher gerankt.“ 2. Sicherheit Obwohl HTTPS nicht absolut sicher ist, können Organisationen, die Root-Zertifikate beherrschen, und Organisationen, die Verschlüsselungsalgorithmen beherrschen, auch Man-in-the-Middle durchführen Angriffe, aber HTTPS ist immer noch die sicherste Lösung unter der aktuellen Architektur und bietet die folgenden Hauptvorteile: (1) Verwenden Sie das HTTPS-Protokoll, um Benutzer und Server zu authentifizieren und sicherzustellen, dass Daten an den richtigen Client und Server gesendet werden. (2) Das HTTPS-Protokoll basiert auf dem SSL+HTTP-Protokoll und kann sein verschlüsselt Das Netzwerkprotokoll für die Übertragung und Identitätsauthentifizierung ist sicherer als das http-Protokoll, wodurch verhindert werden kann, dass Daten während der Übertragung gestohlen oder geändert werden, und die Integrität der Daten sichergestellt wird. (3) HTTPS ist die sicherste Lösung unter der aktuellen Architektur. Obwohl es nicht absolut sicher ist, erhöht es die Kosten von Man-in-the-Middle-Angriffen erheblich. 7. Nachteile von HTTPS Obwohl HTTPS große Vorteile hat, gibt es dennoch einige Mängel: 1. SEO-Aspekte Laut ACM CoNEXT-Daten verlängert die Verwendung des HTTPS-Protokolls die Ladezeit der Seite um fast 50 % und erhöht den Stromverbrauch um 10 % bis 20 % Darüber hinaus wirkt sich das HTTPS-Protokoll auch auf das Caching aus, erhöht den Datenaufwand und den Stromverbrauch und sogar bestehende Sicherheitsmaßnahmen werden beeinträchtigt. Darüber hinaus ist auch der Verschlüsselungsumfang des HTTPS-Protokolls relativ begrenzt und hat kaum Auswirkungen auf Hackerangriffe, Denial-of-Service-Angriffe, Server-Hijacking usw. Das Wichtigste ist, dass das Kreditkettensystem des SSL-Zertifikats nicht sicher ist, insbesondere wenn einige Länder das CA-Stammzertifikat kontrollieren können, sind auch Man-in-the-Middle-Angriffe möglich. 2. Wirtschaftliche Aspekte Je leistungsfähiger das Zertifikat ist, desto höher sind die Kosten kleine Websites verwenden. (2) SSL-Zertifikate müssen normalerweise an eine IP gebunden werden. IPv4-Ressourcen können diesen Verbrauch nicht unterstützen (SSL verfügt über Erweiterungen, die dieses Problem teilweise lösen können ist problematischer. Außerdem ist eine Browser- und Betriebssystemunterstützung erforderlich. In Anbetracht der installierten Kapazität von XP ist diese Funktion nahezu nutzlos. (3) Das Zwischenspeichern von HTTPS-Verbindungen ist nicht so effizient wie HTTP. Websites mit hohem Datenverkehr verwenden es nur, wenn dies erforderlich ist. (4) Die serverseitigen Ressourcen für HTTPS-Verbindungen sind viel höher und die Unterstützung von Websites mit etwas mehr Besuchern erfordert höhere Kosten. Wenn ausschließlich HTTPS verwendet wird, basieren die durchschnittlichen Kosten für VPS auf der Annahme, dass die meisten Rechenressourcen vorhanden sind sind untätig. (5) Die Handshake-Phase des HTTPS-Protokolls ist zeitaufwändig und wirkt sich negativ auf die Reaktionsgeschwindigkeit der Website aus. Es gibt keinen Grund, die Benutzererfahrung zu opfern, es sei denn, dies ist notwendig. <br/> <br/> mit msyql Bei Fuzzy-Abfragen ist es natürlich, die Like-Anweisung zu verwenden. Wenn die Datenmenge klein ist, ist es normalerweise nicht einfach, die Effizienz der Abfrage zu erkennen, aber wenn die Datenmenge Millionen oder Dutzende Millionen erreicht, ist die Effizienz von Die Frage ist, dass Effizienz leicht zu erkennen ist. Zu diesem Zeitpunkt wird die Effizienz der Abfrage sehr wichtig! <br/><br/> <br/><br/>Im Allgemeinen wird die ähnliche Fuzzy-Abfrage wie folgt geschrieben (Feld wurde indiziert): <br/><br/>SELECT `column` FROM `table` WHERE `field` like '%keyword %';<br/><br/>Verwenden Sie EXPLAIN, um die obige Anweisung zu erläutern. Die SQL-Anweisung verwendet keinen Index und es handelt sich um eine vollständige Tabellensuche. Wenn die Datenmenge extrem groß ist, ist es denkbar, dass die endgültige Effizienz wird so aussehen <br/><br/>Vergleichen Sie die folgende Schreibweise: <br/><br/>SELECT `column` FROM `table` WHERE `field` like 'keyword%';<br/><br/>Verwenden Sie „explain“, um dies anzuzeigen Beim Schreiben von SQL-Anweisungen werden Indizes verwendet, und die Sucheffizienz wird erheblich verbessert! <br/><br/> <br/><br/>Aber manchmal, wenn wir Fuzzy-Abfragen durchführen, möchten wir nicht, dass alle Schlüsselwörter zu Beginn abgefragt werden. Wenn also keine besonderen Anforderungen vorliegen, ist dies bei „keywork%“ nicht der Fall Geeignet. Alle Fuzzy-Abfragen <br/><br/> <br/><br/>Zu diesem Zeitpunkt können wir die Verwendung anderer Methoden in Betracht ziehen <br/><br/>1 LOCATE ('substr', str, pos) Methode <br/> Kopieren Code <br/><br/>SELECT LOCATE('xbar',`foobar`); <br/>###returns 0 <br/><br/>SELECT LOCATE('bar',`foobarbar`); # Return 4<br/><br/>SELECT LOCATE('bar',`foobarbar`,5);<br/>###Return 7<br/><br/>Code kopieren<br/><br/>Hinweis: Substr in zurückgeben str Die Position des ersten Vorkommens in str. Wenn substr nicht in str vorhanden ist, ist der Rückgabewert 0. Wenn pos vorhanden ist, wird die Position zurückgegeben, an der substr zum ersten Mal nach der pos-ten Position in str erscheint. Wenn substr nicht in str vorhanden ist, ist der Rückgabewert 0. <br/><br/>SELECT `column` FROM `table` WHERE LOCATE('keyword', `field`)>0<br/><br/>Hinweis: keyword ist der zu durchsuchende Inhalt und field ist das übereinstimmende Feld . Alle Daten mit dem Schlüsselwort <br/><br/> <br/><br/>2.POSITION('substr' IN `field`) Methode <br/><br/>position kann als Alias von „locate“ und seiner Funktion betrachtet werden ist dasselbe wie „locate Same“<br/><br/>SELECT `column` FROM `table` WHERE POSITION('keyword' IN `filed`)<br/><br/>3.INSTR(`str`,'substr') Methode <br/><br/>SELECT `column` FROM `table` WHERE INSTR(`field`, 'keyword' )>0 <br/><br/> <br/><br/>Zusätzlich zu den oben genannten Methoden gibt es auch eine Funktion FIND_IN_SET<br/><br/>FIND_IN_SET(str1,str2):<br/><br/>Gibt den Positionsindex von str1 in str2 zurück, wobei str2 durch "," getrennt werden muss. <br/><br/>SELECT * FROM `person` WHERE FIND_IN_SET('apply',`name`);<br/><br/> Original 2013, 30. April , 15:36:36 🎜> A: ator Der UNION <br/>-Operator kombiniert zwei andere Ergebnistabellen wie TABLE1 und TABLE2) und leiten Sie eine Ergebnistabelle ab, indem Sie alle doppelten Zeilen in der Tabelle entfernen. Wenn ALL mit UNION verwendet wird (d. h. UNION ALL), erfolgt keine Eliminierung doppelte Zeilen. In beiden Fällen stammt jede Zeile der abgeleiteten Tabelle entweder aus TABLE1 oder aus TABLE2. B<br/>: AUSSEROperator Die Der EXCEPT <br/>-Operator eliminiert, indem er alle Zeilen einbezieht, die in TABELLE1, aber nicht in TABELLE2 enthalten sind. Ein Ergebnis Die Tabelle wird aus allen doppelten Zeilen abgeleitet. Wenn ALL mit EXCEPT (EXCEPT ALL) verwendet wird, erfolgt keine Eliminierung. Wiederholen Reihen. C<br/>: INTERSECTOperator Der Der INTERSECT <br/>-Operator eliminiert alle Wiederholungszeilen, um eine Ergebnistabelle abzuleiten. Wenn ALL mit INTERSECT (INTERSECT ALL) verwendet wird, wird dies nicht beseitigt Reihen wiederholen. Hinweis: Mehrere Abfrageergebniszeilen, die Operatorwörter verwenden, müssen konsistent sein. Es ist besser, es in die folgende Aussage zu ändern<br/>--Vereinigen Sie die beiden Ergebnismengen Vorgänge, einschließlich doppelter Zeilen, werden nicht sortiert; SELECT * FROM dbo.banji UNION ALL SELECT* FROM dbo.banjinew; -- Führen Sie eine Schnittoperation für die beiden Ergebnismengen durch, schließen Sie doppelte Zeilen aus und sortieren Sie nach Standardregeln SELECT *FROM dbo.banji INTERSECT SELECT * FROM dbo.banjinew; --运算符通过包括所有在TABLE1中但不在TABLE2中的行并消除所有重复行而派生出一个结果表 SELECT * FROM dbo.banji EXCEPT SELECT * FROM dbo.banjinew;<br/>有些DBMS不支持except all和intersect all <br/> 1. 接口<br/> 在php编程语言中接口是一个抽象类型,是抽象方法的集合。接口通常以interface来声明。一个类通过实现接口的方式,从而来实现接口的方法(抽象方法)。<br/> 接口定义: 特别注意:<br/> * 类全部为抽象方法(不需要声明abstract) <br/> * 接口抽象方法是public <br/> * 成员(字段)必须是常量 2. 继承<br/> 继承自另一个类的类被称为该类的子类。这种关系通常用父类和孩子来比喻。子类将继 <br/>承父类的特性。这些特性由属性和方法组成。子类可以增加父类之外的新功能,因此子类也 <br/>被称为父类的“扩展”。<br/> 在PHP中,类继承通过extends关键字实现。继承自其他类的类成为子类或派生类,子 <br/>类所继承的类成为父类或基类。 特别注意:<br/> 有时候并不需要父类的字段和方法,那么可以通过子类的重写来修改父类的字段和方法。 通过重写调用父类的方法<br/> 有的时候,我们需要通过重写的方法里能够调用父类的方法内容,这个时候就必须使用<br/> 语法:父类名::方法()、parent::方法()即可调用。<br/>final关键字可以防止类被继承,有些时候只想做个独立的类,不想被其他类继承使用。 3. 抽象类和方法<br/>抽象类特性:<br/>* 抽象类不能产生实例对象,只能被继承; <br/>* 抽象方法一定在抽象类中,抽象类中不一定有抽象方法; <br/>* 继承一个抽象类时,子类必须重写父类中所有抽象方法; <br/>* 被定义为抽象的方法只是声明其调用方式(参数),并不实现。 3. 多态<br/>多态是指OOP 能够根据使用类的上下文来重新定义或改变类的性质或行为,或者说接口的多种不同的实现方式即为多态。<br/> Verwandte Empfehlungen: <br/> PHP-objektorientiertes Identifikationsobjekt Entwicklungsideen und Fallanalyse der PHP-objektorientierten Programmierung Praktische Grundkenntnisse des PHP-Objekts -orientiert Das Obige ist der detaillierte Inhalt der Einführung in die objektorientierte Vererbung, den Polymorphismus und die Kapselung von PHP. Weitere Informationen finden Sie in anderen verwandten Artikeln auf der chinesischen PHP-Website! Tag: Polymorphe Kapselung von PHP Vorheriger Artikel: PHP implementiert WeChat-Applet-Zahlungscode-Sharing Nächster Artikel: PHP-Sitzungssteuerungssitzung und Cookie-Einführung Empfohlen für Sie 2018-02-1174 2018 - 02-1074 2018-02-1059 2018-01-0567 <br/> Softwarearchitektur-Muster, die Software transformieren Das System ist in drei grundlegende Teile unterteilt: Modell, Ansicht und Controller. Das MVC-Modell wurde erstmals 1978 von Trygve Reenskaug vorgeschlagen , also Ein Software-Designmuster, das in den 1980er Jahren vom Xerox Palo Alto Research Center (Xerox PARC) für die Programmiersprache Smalltalk erfunden wurde. Der Zweck des MVC-Musters besteht darin, ein dynamisches Programmdesign zu implementieren, nachträgliche Änderungen und Erweiterungen des Programms zu vereinfachen und die Wiederverwendung bestimmter Programmteile zu ermöglichen. Darüber hinaus macht dieser Modus die Programmstruktur intuitiver, indem er die Komplexität vereinfacht. Das Softwaresystem trennt seine Grundteile und gibt jedem Grundteil auch die ihm zustehenden Funktionen. Fachleute können nach ihrem eigenen Fachwissen gruppiert werden: (Controller) – Verantwortlich für die Weiterleitung von Anfragen und deren Bearbeitung. (Ansicht) – Interface-Designer entwerfen grafische Schnittstellen. (Modell) – Programmierer schreiben die Funktionen, die Programme haben sollten (implementieren Algorithmen usw.), Datenbankexperten führen Datenverwaltung und Datenbankdesign durch (können spezifische implementieren). Funktion). Ansicht: In der Ansicht findet keine echte Verarbeitung statt, unabhängig davon, ob die Daten online oder in einer Mitarbeiterliste gespeichert sind. Als Ansicht dient sie lediglich dazu, Daten auszugeben und dem Benutzer die Möglichkeit zu geben, sie zu manipulieren. <br/>Modell: <br/>Modell repräsentiert Unternehmensdaten und Geschäftsregeln. Unter den drei Komponenten von MVC hat das -Modell die meisten Verarbeitungsaufgaben . Beispielsweise könnten Komponentenobjekte wie EJBs und ColdFusionComponents für die Verwaltung von Datenbanken verwendet werden. Die vom Modell zurückgegebenen Daten sind neutral, das heißt, das -Modell hat nichts mit dem Datenformat zu tun, sodass ein Modell Daten für mehrere Ansichten bereitstellen kann . Die Codeduplizierung wird reduziert, da der auf das Modell angewendete Code nur einmal geschrieben werden muss und von mehreren Ansichten wiederverwendet werden kann. <br/>Controller: <br/>Controller akzeptiert Benutzereingaben und ruft Modelle und Ansichten auf, um die Anforderungen des Benutzers zu erfüllen . Wenn also auf einer Webseite auf einen Hyperlink geklickt und ein HTML-Formular gesendet wird, gibt der Controller selbst nichts aus und führt keine Verarbeitung durch. Es empfängt lediglich die Anfrage und entscheidet, welche Modellkomponente aufgerufen werden soll, um die Anfrage zu bearbeiten, und bestimmt dann, welche Ansicht zum Anzeigen der zurückgegebenen Daten verwendet werden soll. <br/> Vorteile von MVC<br/>1. Geringe Kopplung<br/> Die Ansichtsschicht und die Geschäftsschicht sind getrennt, was dies ermöglicht Zeigen Sie den zu ändernden Layer-Code an, ohne den Modell- und Controller-Code neu kompilieren zu müssen Ebenso erfordern Änderungen am Geschäftsprozess oder an den Geschäftsregeln einer Anwendung nur Änderungen an der MVC-Modellebene. Da das Modell vom Controller und der Ansicht getrennt ist, ist es einfach, die Datenschicht und die Geschäftsregeln der Anwendung zu ändern. <br/>2. Hohe Wiederverwendbarkeit und Anwendbarkeit <br/> Mit der kontinuierlichen Weiterentwicklung der Technologie werden immer mehr Methoden benötigt. Mit dem MVC-Muster können Sie verschiedene Ansichtsstile verwenden, um auf denselben serverseitigen Code zuzugreifen. Es umfasst jeden WEB-Browser (HTTP) oder drahtlosen Browser (WAP). Benutzer können beispielsweise ein bestimmtes Produkt über einen Computer oder ein Mobiltelefon bestellen. Obwohl die Bestellmethoden unterschiedlich sind, ist die Art und Weise, wie die bestellten Produkte verarbeitet werden. Da die vom Modell zurückgegebenen Daten nicht formatiert sind, kann dieselbe Komponente von verschiedenen Schnittstellen verwendet werden. Beispielsweise können viele Daten durch HTML dargestellt werden, sie können jedoch auch durch WAP dargestellt werden, und die für diese Darstellung erforderlichen Befehle bestehen darin, die Implementierung der Ansichtsschicht zu ändern, während dies für die Steuerungsschicht und die Modellschicht nicht erforderlich ist Nehmen Sie eventuelle Änderungen vor. <br/>3. Niedrigere Lebenszykluskosten <br/> MVC reduziert den technischen Inhalt der Entwicklung und Wartung von Benutzeroberflächen. <br/>4. Schnelle Bereitstellung <br/>Die Verwendung des MVC-Modells kann die Entwicklungszeit erheblich verkürzen, wodurch sich Programmierer (Java-Entwickler) auf die Geschäftslogik konzentrieren können. Schnittstellenprogrammierer (HTML- und JSP-Entwickler) konzentrieren sich auf die Präsentation. <br/>5. Wartbarkeit <br/> Durch die Trennung der Ansichtsschicht und der Geschäftslogikschicht sind WEB-Anwendungen auch einfacher zu warten und zu ändern. <br/>6. Förderlich für das Software-Engineering-Management <br/> Da verschiedene Schichten ihre eigenen Aufgaben erfüllen, weisen unterschiedliche Anwendungen auf jeder Schicht bestimmte Merkmale auf förderlich für die Verwaltung von Programmcode durch Technik und Werkzeuge. Erweiterung: WAP (Wireless Application Protocol) ist Wireless Application Protocol ist ein globales Netzwerkkommunikationsprotokoll. WAP bietet einen gemeinsamen Standard für das mobile Internet und sein Ziel besteht darin, die umfangreichen Informationen und erweiterten Dienste des Internets in drahtlose Endgeräte wie Mobiltelefone einzuführen. WAP definiert eine universelle Plattform, die die aktuellen HTML-Sprache-Informationen im Internet in in WML (Wireless Markup Language) beschriebene Informationen umwandelt, die auf dem Display des Mobiltelefons angezeigt werden. WAP erfordert nur die Unterstützung von Mobiltelefonen und WAP-Proxyservern und erfordert keine Änderungen an den bestehenden Netzwerkprotokollen des Mobilkommunikationsnetzwerks , sodass es in großem Umfang in GSM und CDMA verwendet werden kann , TDMA, 3G und andere Netzwerke. Da mobiler Internetzugang zum neuen Liebling des Internetzeitalters wird, sind verschiedene Anwendungsanforderungen für WAP entstanden. Einige Handheld-Geräte, wie z. B. PDA, verwenden nach der Installation eines Mikrobrowsers WAP, um auf das Internet zuzugreifen. Die Mikrobrowserdatei ist sehr klein, wodurch die Einschränkungen des kleinen Speichers von Handheld-Geräten und der unzureichenden Bandbreite des drahtlosen Netzwerks besser gelöst werden können. Obwohl WAP HTHL und XML unterstützen kann, ist WML eine Sprache, die speziell für kleine Bildschirme und Handheld-Geräte ohne Tastatur entwickelt wurde. WAP unterstützt auch WMLScript. Diese Skriptsprache ähnelt JavaScript, hat jedoch geringere Speicher- und CPU-Anforderungen, da sie grundsätzlich keine andere Skriptsprache enthält, die nutzlose Funktionen enthält . <br/> 11. Die Rolle von CDN Der Unterschied zwischen kostenpflichtigem und kostenlosem GOQR<br/> Im Allgemeinen begrenzen Browser die Anzahl gleichzeitiger Anfragen (Laden von Dateien) unter a Einzelner Domainname, normalerweise sind es höchstens 4, dann wird das Add-In blockiert, bis eine vorherige Datei geladen wird. Da CDN Dateien in unterschiedlichen Bereichen (verschiedene ) gespeichert werden, ist dies für den Browser möglich alle für die Seite benötigten Dateien gleichzeitig zu laden (weit mehr als 4) und so die Seitenladegeschwindigkeit zu erhöhen. 2. Die Datei wurde möglicherweise geladen und zwischengespeichert Einige gängige js-Bibliotheken oder -Stilbibliotheken wie jQuery werden im Internet sehr häufig verwendet. Wenn ein Benutzer eine Ihrer Webseiten durchsucht, ist es sehr wahrscheinlich, dass er eine andere Website über das von Ihrer Website verwendete CDN besucht hat. Es kommt vor, dass diese Website auch über If < verfügt 🎜>jQuery wird verwendet, dann hat der Browser des Benutzers die jQuery-Datei bereits zwischengespeichert (dasselbe wie IP<). Wenn eine Datei mit dem gleichen Namen wie 🎜> zwischengespeichert wird, verwendet der Browser die zwischengespeicherte Datei direkt und lädt sie nicht erneut, sodass sie nicht erneut geladen wird, was indirekt die Zugriffsgeschwindigkeit der Website verbessert. 3. Hohe Effizienz Ihre Website kann nicht besser sein Noch NB NBGoogle, oder? Ein gutes CDNs sorgt für höhere Effizienz, geringere Netzwerklatenz und geringere Paketverlustrate. 4. Verteiltes Rechenzentrum Wenn sich Ihr Standort in Peking befindet, wenn ein Benutzer aus Hongkong oder weiter entfernt ist Wenn er auf Ihre Website zugreift, ist seine Datenanfrage zwangsläufig sehr langsam. Und CDNs ermöglichen es dem Benutzer, die erforderlichen Dateien von dem Knoten zu laden, der ihm am nächsten liegt, sodass die Ladegeschwindigkeit natürlich verbessert wird. 5. Integrierte Versionskontrolle Normalerweise für CSS Dateien und JavaScript-Bibliotheken haben alle Versionsnummern. Sie können die erforderlichen Dateien von CDNs über eine bestimmte Versionsnummer laden. Datei können Sie auch latest verwenden, um die neueste Version zu laden (nicht empfohlen). Nutzungsanalyse Allgemein CDNs Anbieter ( (z. B. Baidu Cloud Acceleration) stellt Datenstatistikfunktionen bereit, um mehr über die Besuche der Benutzer auf ihren eigenen Websites zu erfahren, und kann auf der Grundlage statistischer Daten zeitnahe und angemessene Anpassungen an ihren eigenen Websites vornehmen. 7. Verhindern Sie wirksam, dass die Website angegriffen wird Unter normalen Umständen CDNs Der Anbieter stellt auch Website-Sicherheitsdienste bereit. <br/> ? 3. ISP-Verbindung, d. h. die Verbindung zwischen Internetdienstanbietern, wie beispielsweise die Verbindung zwischen China Telecom und China Unicom. Wenn ein Website-Server im Computerraum von Betreiber A bereitgestellt wird und Benutzer von Betreiber B auf die Website zugreifen möchten, müssen sie für den netzwerkübergreifenden Zugriff den Verbindungspunkt zwischen A und B durchlaufen. Aus Sicht der Architektur des Internets macht die Verbindungsbandbreite zwischen verschiedenen Betreibern nur einen sehr geringen Anteil des Netzwerkverkehrs eines Betreibers aus. Daher ist dies häufig ein Überlastungspunkt für die Netzwerkübertragung. <br/>4. Fernübertragung über das Backbone. Das erste ist das Problem der Übertragungsverzögerung über große Entfernungen und das zweite ist das Überlastungsproblem des Backbone-Netzwerks. Diese Probleme führen zu einer Überlastung der World Wide Web-Verkehrsübertragung. <br/>Aus der obigen Analyse der Netzwerküberlastung geht hervor, dass es höchstwahrscheinlich zu einer Zugriffsüberlastung kommt, wenn die Daten im Netzwerk direkt vom Quellstandort an den Benutzer übermittelt werden. <br/>Wenn es eine technische Lösung gibt, um Daten an einem Ort in der Nähe des Benutzers zwischenzuspeichern, damit der Benutzer sie mit der schnellsten Geschwindigkeit abrufen kann, dann wird dies eine große Rolle bei der Reduzierung des Exportbandbreitendrucks der Website und der Reduzierung des Netzwerks spielen Übertragungsstau große Wirkung. CDN ist eine solche technische Lösung. <br/> Der Prozess für Benutzer, über einen Browser auf herkömmliche Websites (ohne CDN) zuzugreifen, ist wie folgt. <br/> Wenn ein CDN verwendet wird, sieht der Prozess wie folgt aus. <br/> Nach der Einführung von CDN zwischen der Website und dem Benutzer wird sich der Benutzer nicht anders fühlen als beim Original. <br/>Websites, die CDN-Dienste nutzen, müssen lediglich die Auflösungsrechte ihrer Domänennamen an das Lastausgleichsgerät des CDN übergeben. Das CDN-Lastausgleichsgerät wählt einen geeigneten Cache-Server für den Benutzer aus und der Benutzer erhält seine eigenen Informationen durch Zugriff auf die erforderlichen Daten des Cache-Servers. <br/>Da der Cache-Server im Computerraum von Netzwerkbetreibern bereitgestellt wird und diese Betreiber Netzwerkdienstanbieter der Benutzer sind, können Benutzer über den kürzesten Weg und mit der schnellsten Geschwindigkeit auf die Website zugreifen. Daher kann CDN den Benutzerzugriff beschleunigen und den Lastdruck auf das Ursprungszentrum verringern. <br/> <br/> Lastausgleichsstrategie: 1. Round Robin: Jede Anfrage aus dem Netzwerk wird der Reihe nach an die internen Server verteilt, von 1 bis N, und beginnt dann erneut. Dieser Ausgleichsalgorithmus eignet sich für Situationen, in denen alle Server in der Servergruppe über die gleiche Hardware- und Softwarekonfiguration verfügen und die durchschnittlichen Dienstanforderungen relativ ausgeglichen sind. 2. Gewichteter Round Robin: Je nach den unterschiedlichen Verarbeitungsmöglichkeiten des Servers werden jedem Server unterschiedliche Gewichte zugewiesen, damit er Serviceanfragen mit entsprechenden Gewichten annehmen kann. Beispiel: Die Gewichtung von Server A soll 1 betragen, die Gewichtung von B beträgt 3 und die Gewichtung von C beträgt 6. Dann erhalten die Server A, B und C 10 %, 30 % und 60 % des Dienstes Anfragen bzw. Dieser Ausgleichsalgorithmus sorgt dafür, dass Hochleistungsserver stärker ausgelastet werden und verhindert, dass Server mit geringer Leistung überlastet werden. 3. Zufällige Balance (zufällig): Verteilen Sie Anfragen vom Netzwerk zufällig an mehrere interne Server. 4. Gewichteter Zufall: Dieser Ausgleichsalgorithmus ähnelt dem gewichteten Round-Robin-Algorithmus, es handelt sich jedoch um einen zufälligen Auswahlprozess bei der Verarbeitung der Anforderungsfreigabe. 5. Reaktionszeitausgleich (Reaktionszeit): Das Lastausgleichsgerät sendet eine Erkennungsanforderung (z. B. Ping) an jeden internen Server und entscheidet dann anhand der schnellsten Antwortzeit jedes internen Servers, an welchen die Erkennungsanforderung. Ein Server, der auf Client-Serviceanfragen antwortet. Dieser Ausgleichsalgorithmus kann den aktuellen Betriebsstatus des Servers besser widerspiegeln, aber die schnellste Antwortzeit bezieht sich nur auf die schnellste Antwortzeit zwischen dem Lastausgleichsgerät und dem Server, nicht auf die schnellste Antwortzeit zwischen dem Client und dem Server. 6. Geringster Verbindungsausgleich: Die Verweildauer jedes Client-Anforderungsdienstes auf dem Server kann stark variieren. Wenn ein einfacher Round-Robin- oder Zufallsausgleichsalgorithmus verwendet wird, kann der Verbindungsprozess auf jedem Server stark variieren , und ein echter Lastausgleich wird nicht erreicht. Der Algorithmus zum Ausgleich der Mindestanzahl von Verbindungen verfügt über einen Datensatz für jeden Server, der intern geladen werden muss und die Anzahl der Verbindungen aufzeichnet, die derzeit vom Server verarbeitet werden. Wenn eine neue Dienstverbindungsanforderung vorliegt, wird die aktuelle Anforderung zugewiesen Server mit der geringsten Anzahl von Verbindungen sorgt dafür, dass die Balance besser mit der tatsächlichen Situation übereinstimmt und die Last ausgeglichener ist. Dieser Ausgleichsalgorithmus eignet sich für die langfristige Verarbeitung von Anforderungsdiensten wie FTP. 7. Verarbeitungskapazitätsausgleich: Dieser Ausgleichsalgorithmus weist Serviceanfragen dem Server mit der geringsten internen Verarbeitungslast zu (basierend auf dem Server-CPU-Modell, der Anzahl der CPUs, der Speichergröße, der aktuellen Anzahl der Verbindungen usw.). ) Da dieser Ausgleichsalgorithmus die Verarbeitungsleistung des internen Servers und die aktuellen Netzwerkbetriebsbedingungen berücksichtigt, ist er relativ genauer und eignet sich insbesondere für den Lastausgleich auf Schicht 7 (Anwendungsschicht). 8. DNS-Antwortausgleich (Flash DNS): Unabhängig davon, ob es sich um HTTP-, FTP- oder andere Dienstanfragen handelt, findet der Client normalerweise die genaue IP-Adresse des Servers durch Domänennamenauflösung. Bei diesem Ausgleichsalgorithmus erhalten Lastausgleichsgeräte, die sich an verschiedenen geografischen Standorten befinden, eine Anforderung zur Domänennamenauflösung vom selben Client und lösen den Domänennamen gleichzeitig in die IP-Adresse ihres entsprechenden Servers (d. h. des Lastausgleichsgeräts) auf . Die IP-Adresse des Servers am selben geografischen Standort) und gibt sie an den Client zurück. Der Client fordert weiterhin Dienste mit der ersten empfangenen IP-Adresse zur Domänennamenauflösung an und ignoriert andere IP-Adressantworten. Wenn diese Ausgleichsstrategie für den globalen Lastausgleich geeignet ist, ist sie für den lokalen Lastausgleich bedeutungslos. Methoden und Funktionen zur Erkennung von Dienstfehlern: 1. Ping-Erkennung: Erkennen Sie den Server- und Netzwerksystemstatus durch Ping Erkennt grob, ob das Betriebssystem im Netzwerk und auf dem Server normal ist, kann jedoch die Anwendungsdienste auf dem Server nicht erkennen. 2. TCP-Offen-Erkennung: Jeder Dienst öffnet eine TCP-Verbindung und erkennt, ob ein bestimmter TCP-Port auf dem Server (z. B. Telnet-Port 23, HTTP-Port 80 usw.) geöffnet ist, um festzustellen, ob der Dienst geöffnet ist ist normal. 3. HTTP-URL-Erkennung: Wenn beispielsweise eine Zugriffsanforderung auf die Datei main.html an den HTTP-Server gesendet wird und eine Fehlermeldung empfangen wird, gilt der Server als fehlerhaft. <br/> <br/> Lassen Sie uns zunächst kurz über das Caching sprechen. Die Idee des Cachings besteht schon seit langem darin, die Berechnungsergebnisse zu speichern, die viel Zeit in Anspruch nehmen, und sie bei Bedarf direkt zu verwenden die Zukunft, um wiederholte Berechnungen zu vermeiden. In Computersystemen gibt es zahlreiche Cache-Anwendungen, z. B. die dreistufige Speicherstruktur des Computers und den Cache in Webdiensten. In diesem Artikel wird hauptsächlich die Verwendung von Cache in der Webumgebung erläutert, einschließlich Browser-Cache, Server-Cache, Reverse-Proxy-Cache und verteiltem Cache und andere Aspekte. 1. Dynamisches Inhalts-Caching 1.1 Seiten-Cache Es gibt viele Implementierungsmethoden für das Seiten-Caching, beispielsweise Template-Engines wie Smarty oder MVC-Frameworks wie Zend und Diango. Der Controller und die Ansicht sind getrennt, und der Controller kann problemlos über eine eigene Cache-Steuerung verfügen. Normalerweise speichern wir den Cache dynamischer Inhalte auf der Festplatte . Die Festplatte bietet eine kostengünstige Möglichkeit, eine große Anzahl von Dateien zu speichern. Machen Sie sich also keine Sorgen. Die Eliminierung von Caching aufgrund von Platzproblemen ist ein einfacher und leicht umzusetzender Ansatz. Es ist jedoch immer noch möglich, dass sich im Cache-Verzeichnis eine große Anzahl von Cache-Dateien befindet, was dazu führt, dass die CPU viel Zeit damit verbringt, das Verzeichnis zu durchsuchen. Um dieses Problem zu lösen, können Cache-Verzeichnishierarchien verwendet werden Stellen Sie sicher, dass die Unterverzeichnisse unter jedem Verzeichnis vorhanden sind. Oder halten Sie die Anzahl der Dateien in einem kleinen Bereich. Auf diese Weise kann beim Speichern einer großen Anzahl von Cache-Dateien der Zeitverbrauch der CPU beim Durchlaufen des Verzeichnisses reduziert werden. Beim Speichern von Cache-Daten in Festplattendateien entsteht für jede Cache-Lade- und Ablaufprüfung ein Festplatten-E/A-Overhead, der auch von der Festplattenlast beeinflusst wird Es kommt zu einer gewissen Verzögerung bei E/A-Vorgängen. Darüber hinaus können Sie den Cache im lokalen Speicher platzieren, was mit Hilfe des APC-Moduls von PHP oder der PHP-Cache-Erweiterung XCache einfach implementiert werden kann, sodass kein Festplatten-I entsteht beim Laden des Caches. Schließlich kann der Cache auch auf einem unabhängigen Cache-Server gespeichert werden. Mit Memcached kann der Cache problemlos auf anderen Servern über TCP gespeichert werden. Die Verwendung von Memcached ist etwas langsamer als die Verwendung des lokalen Speichers, aber im Vergleich zum Speichern des Caches im lokalen Speicher hat die Verwendung von Memcached zur Implementierung des Cachings zwei Vorteile: Webserverspeicher ist kostbar, nicht möglich bieten viel Platz für das HTML-Caching. Die Verwendung eines separaten Cache-Servers bietet eine gute Skalierbarkeit. Da wir über Cache sprechen, müssen wir über die Ablaufprüfung sprechen, die hauptsächlich auf der Cache-Gültigkeit basiert Zeitraum-Mechanismus. Es gibt zwei Hauptmechanismen: Basierend auf der Cache-Erstellungszeit, der Länge der Cache-Gültigkeitseinstellung und der aktuellen Zeit, um festzustellen, ob sie abgelaufen ist Das heißt, wenn die aktuelle Zeit weit von der Cache-Erstellungszeit entfernt ist. Wenn die Länge den Gültigkeitszeitraum überschreitet, gilt der Cache als abgelaufen. Beurteilung anhand der Cache-Ablaufzeit und der aktuellen Uhrzeit. Es ist nicht einfach, den Cache-Gültigkeitszeitraum festzulegen, obwohl die Cache-Trefferquote hoch ist zu kurz, obwohl der dynamische Inhalt aktualisiert wird, zeitnah, aber die Cache-Trefferquote wird reduziert. Daher ist es sehr wichtig, einen angemessenen Gültigkeitszeitraum festzulegen. Noch wichtiger ist jedoch, dass wir erkennen können, wann der Gültigkeitszeitraum geändert werden muss, und dann jederzeit einen geeigneten Wert finden können. Zusätzlich zur Cache-Gültigkeitsdauer bietet der Cache auch eine Kontrollmethode, mit der der Cache jederzeit zwangsweise geleert werden kann. In einigen Fällen muss der Inhalt eines bestimmten Bereichs der Seite rechtzeitig aktualisiert werden, wenn der gesamte Seitencache für einen Bereich neu erstellt wird Muss rechtzeitig aktualisiert werden, es scheint, dass es sich nicht lohnt. Beliebte Template-Frameworks wie Smary bieten teilweise Cache-freie Unterstützung. Die vorherige Methode muss dynamisch steuern, ob der Cache verwendet werden soll. Die statische Methode generiert statischen Inhalt aus dynamischem Inhalt und ermöglicht es Benutzern dann, statischen Inhalt direkt anzufordern, was die Verwendung erheblich verbessert Durchsatzrate. In ähnlicher Weise müssen auch statische Inhalte aktualisiert werden. Es gibt im Allgemeinen zwei Methoden: Statische Inhalte neu generieren, wenn die Daten aktualisiert werden. Statische Inhalte regelmäßig neu generieren. Ähnlich wie beim zuvor erwähnten dynamischen Cache müssen statische Seiten nicht die gesamte Seite aktualisieren. Jede Teilseite kann durch die Server-Inclusion-Technologie (SSI) unabhängig aktualisiert werden, wodurch die Rekonstruktion erheblich reduziert wird . Rechen- und Festplatten-E/A-Overhead für die gesamte Seite sowie Netzwerk-E/A-Overhead während der Verteilung. Heutzutage unterstützen gängige Webserver die SSI-Technologie wie Apache, lighttpd usw. Aus der Sicht der Verschwörung sind die Menschen daran gewöhnt, Browser nur als ein Stück Software auf ihren PCs zu betrachten, aber tatsächlich Browser sind wichtig für das Web Komponenten . Wenn Sie Inhalte im Browser zwischenspeichern, können Sie nicht nur den Server-Rechenaufwand reduzieren, sondern auch unnötige Übertragungen und Bandbreitenverschwendung vermeiden. Um zwischengespeicherte Inhalte auf der Browserseite zu speichern, wird im Allgemeinen ein Verzeichnis im Dateisystem des Benutzers erstellt, um zwischengespeicherte Dateien zu speichern, und jeder zwischengespeicherten Datei werden einige erforderliche Tags zugewiesen, z. B. Ablaufzeit usw. Darüber hinaus weisen verschiedene Browser geringfügige Unterschiede in der Art und Weise auf, wie sie Cache-Dateien speichern. Der Browser-Cache-Inhalt wird auf der Browserseite gespeichert und der Inhalt wird vom Webserver generiert. Um den Browser-Cache zu verwenden, müssen der Browser und der Webserver kommunizieren ist HTTP „Cache Negotiation“ in . 当 Web 服务器接收到浏览器请求后,Web 服务器需要告知浏览器哪些内容可以缓存,一旦浏览器知道哪些内容可以缓存后,下次当浏览器需要请求这个内容时,浏览器便不会直接向服务器请求完整内容,二是询问服务器是否可以使用本地缓存,服务器在收到浏览的询问后回应是使用浏览器本地缓存还是将最新内容传回给浏览器。 Last-Modified Last-Modified 是一种协商方式。通过动态程序为 HTTP 相应添加最后修改时间的标记 此时,Web 服务器的响应头部会多出一条: 这代表 Web 服务器对浏览器的暗示,告诉浏览器当前请求内容的最后修改时间。收到 Web 服务器响应后,再次刷新页面,注意到发出的 HTTP 请求头部多了一段标记: 这表示浏览器询问 Web 服务器在该时间后是否有更新过请求的内容,此时,Web 服务器需要检查请求的内容在该时间后是否有过更新并反馈给浏览器,这其实就是缓存过期检查。 如果这段时间里请求的内容没有发生变化,服务器做出回应,此时,Web 服务器响应头部: 注意到此时的状态码是304,意味着 Web 服务器告诉浏览器这个内容没有更新,浏览器使用本地缓存。如下图所示: ETag HTTP/1.1 还支持ETag缓存协商方法,与最后过期时间不同的是,ETag不再采用内容的最后修改时间,而是采用一串编码来标记内容,称为ETag,如果一个内容的 ETag 没有变化,那么这个内容就一定没有更新。 ETag 由 Web 服务器生成,浏览器在获得内容的 ETag 后,会在下次请求该内容时,在 HTTP 请求头中附加上相应标记来询问服务器该内容是否发生了变化: 这时,服务器需要重新计算这个内容的 ETag,并与 HTTP 请求中的 ETag 进行对比,如果相同,便返回 304,若不同,则返回最新内容。如下图所示,服务器发现请求的 ETag 与重新计算的 ETag 不同,返回最新内容,状态码为200。 Last-Modified VS ETag 基于最后修改时间的缓存协商存在一些缺点,如有时候文件需频繁更新,但内容并没有发生变化,这种情况下,每次文件修改时间变化后,无论内容是否发生变化,都会重新获取全部内容。另外,在采用多台 Web 服务器时,用户请求可能在多台服务器间变化,而不同服务器上同一文件最后修改时间很难保证完全一样,便会导致重新获取所有内容。采用 ETag 方法就可以避免这些问题。 首先,原本使用浏览器缓存的动态内容,在使用浏览器缓存后,能否获得大的吞吐率提升,关键在于是否能避免一些额外的计算开销,同事,还取决于 HTTP 响应正文的长度,若 HTTP 响应较长,如较长的视频,则能带来大的吞吐率提到。 但使用浏览器缓存的最大价值并不在此,而在于减少带宽消耗。使用浏览器缓存后,如果 Web 服务器计算后发现可以使用浏览器端缓存,则返回的响应长度将大大减少,从而,大大减少带宽消耗。 The goal of caching in HTTP/1.1 is to eliminate the need to send requests in many cases. 在上面两图中,有个 对于主流浏览器,有三种请求页面方式: Ctrl + F5:强制刷新,使网页以及所有组件都直接向 Web 浏览器发送请求,并且不适用缓存协商,从而获取所有内容的最新版本。等价于按住 Ctrl 键后点击浏览器刷新按钮。 F5:允许浏览器在请求中附加必要的缓存协商,但不允许直接使用本地缓存,即让Last-Modified生效、Expires无效。等价于单击浏览器刷新按钮。 单击浏览器地址栏“转到”按钮或通过超链接跳转:浏览器对于所有没过期的内容直接使用本地缓存,Expires只对这种方式生效。等价于在地址栏输入 URL 后回车。 Expires指定的过期时间来源于 Web 服务器的系统时间,如果与用户本地时间不一致,就会影响到本地缓存的有效期检查。 一般情况下,操作系统都使用基于 GMT 的标准时间,然后通过时区来进行偏移计算,HTTP 中也使用 GMT 时间,所以,一般不会因为时区导致本地与服务器相差数个小时,但没人能保证本地时间与服务器一直,甚至有时服务器时间也是错误的。 针对这个问题,HTTP/1.1 添加了标记 Cache-Control,如上图1所示, HTTP 是浏览器与 Web 服务器沟通的语言,且是它们唯一的沟通方式,好好学学 HTTP 吧! 前面提到的动态内容缓存和静态化基本都是通过动态程序来实现的,下面讨论 Web 服务器自己实现缓存机制。 Web 服务器接收到 HTTP 请求后,需要解析 URL,然后将 URL 映射到实际内容或资源,这里的“映射”指服务器处理请求并生成响应内容的过程。很多时候,在一段时间内,一个 URL 对应一个唯一的响应内容,比如静态内容或更新不频繁的动态内容,如果将最终内容缓存起来,下次 Web 服务器接收到请求后可以直接将响应内容返回给浏览器,从而节省大量开销。现在,主流 Web 服务器都提供了对这种类型缓存的支持。 当使用 Web 服务器缓存时,如果直接命中,那么将省略后面的一系列操作,如 CPU 计算、数据库查询等,所以,Web 服务器缓存能带来较大性能提升,但对于普通 HTML 也,带来的性能提升较有限。 那么,缓存内容存储在什么位置呢?一般来说,本机内存和磁盘是主要选择,也可以采用分布式设计,存储到其它服务器的内存或磁盘中,这点跟前面提到的动态内容缓存类似,Apache、lighttpd 和 Nginx 都提供了支持,但配置上略有差别。 提到缓存,就不得不提有效期控制。与浏览器缓存相似,Web 服务器缓存过期检查仍然建立在 HTTP/1.1 协议上,要指定缓存有效期,仍然是在 HTTP 响应头中加入 这样一来,Web服务器就不会将这个动态内容缓存起来,当然,也有其它方法实现这个功能。 如果动态内容没有输出 Expires 标记,也可以采用 那么,是否可以使用 Web 服务器缓存取代动态程序自身的缓存机制呢?当然可以,但有些注意: 让动态程序依赖特定 Web 服务器,降低应用的可移植性。 Web 服务器缓存机制实质上是以 URL 为键的 key-value 结构缓存,所以,必须保证所有希望缓存的动态内容有唯一的 URL。 编写面向 HTTP 缓存友好的动态程序是唯一需要考虑的事。 对静态内容,特别是大量小文件站点, Web 服务器很大一部分开销花在了打开文件上,所以,可以考虑将打开后的文件描述符直接缓存到 Web 服务器的内存中,从而减少开销。但是,缓存文件描述符仅仅适用于静态内容,而且仅适用于小文件,对大文件,处理它们的开销主要在传送数据上,打开文件开销小,缓存文件描述符带来的收益小。 代理(Proxy),也称网络代理,是一种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。提供代理服务的电脑系统或其它类型的网络终端称为代理服务器(Proxy Server)。 Das Obige ist die Wikipedia-Definition von Proxy. In diesem Fall ist der Reverse-Proxy-Server genau das Gegenteil Der Mechanismus ist Reverse Proxy. Ebenso wird der Server, der diesen Mechanismus implementiert, Reverse Proxy Server genannt. Wir bezeichnen den Webserver hinter dem Reverse-Proxy-Server normalerweise als Back-End-Server (Back-End-Server). Dementsprechend wird der Reverse-Proxy-Server als Front-End-Server (Front-End-Server) bezeichnet ist dem Internet ausgesetzt, der Back-End-Webserver ist über das interne Netzwerk mit ihm verbunden, und Benutzer greifen indirekt über den Reverse-Proxy-Server auf den Webserver zu, was nicht nur ein gewisses Maß an Sicherheit mit sich bringt, sondern auch Cache ermöglicht. basierte Beschleunigung. Es gibt viele Möglichkeiten, Reverse-Proxy zu implementieren, beispielsweise kann der gängigste Nginx-Server als Reverse-Proxy-Server verwendet werden. Damit Benutzerbrowser und Webserver ordnungsgemäß funktionieren, müssen sie über den Reverse-Proxy-Server laufen. Daher hat der Reverse-Proxy-Server eine gute Kontrolle. Durchlaufende HTTP-Header-Informationen können auf beliebige Weise umgeschrieben werden, oder es können andere benutzerdefinierte Mechanismen verwendet werden, um direkt in die Cache-Strategie einzugreifen. Wie wir aus dem vorherigen Inhalt wissen, bestimmen die HTTP-Header-Informationen, ob der Inhalt zwischengespeichert werden kann. Um die Leistung zu verbessern, kann der Reverse-Proxy-Server daher die HTTP-Header-Informationen der durch ihn übertragenen Daten ändern, um zu bestimmen, welcher Inhalt sein kann zwischengespeichert werden und nicht zwischengespeichert werden können. Der Reverse-Proxy-Server bietet auch die Funktion, den Cache zu leeren. Im Gegensatz zum dynamischen Inhaltscache können wir den Cache jedoch aktiv löschen Die Methode implementiert Aktualisierungen, bevor der Cache abläuft, aber der auf HTTP basierende Reverse-Proxy-Caching-Mechanismus ist nicht einfach. Das dynamische Back-End-Programm kann einen zwischengespeicherten Inhalt nicht aktiv löschen, es sei denn, der Cache-Bereich auf dem Reverse-Proxy-Server wird gelöscht. Es gibt viele ausgereifte verteilte Caching-Systeme, wie zum Beispiel Memcached. Um Caching zu erreichen, legen wir den Cache-Inhalt nicht auf der Festplatte ab. Basierend auf diesem Prinzip verwendet memcached den physischen Speicher als Cache-Bereich und speichert Daten in einer Schlüsselwert-Struktur Wir nennen jeden Schlüssel und den entsprechenden Wert ein Datenelement, das unabhängig voneinander ist. Benutzer können dieses Datenelement über den Schlüssel lesen oder aktualisieren Der Hash-Algorithmus wird verwendet, um die Speicherdatenstruktur zu entwerfen, und ein sorgfältig entworfener Speicherzuweiser wird verwendet, um die Komplexität der Datenelementabfragezeit auf O(1) zu bringen. memcached verwendet einen Eliminierungsmechanismus, der auf dem LRU-Algorithmus (Lease Recent Used) basiert, um Daten zu eliminieren. Gleichzeitig kann die Ablaufzeit auch für Datenelemente festgelegt werden wurde bereits zuvor besprochen. Als verteiltes Cache-System kann Memcached auf einem unabhängigen Server ausgeführt werden, und der Zugriff auf dynamische Inhalte erfolgt über TCP Socket. In diesem Fall ist das eigene Netzwerk-Parallelitätsverarbeitungsmodell von Memcached sehr wichtig. Memcached verwendet die Funktionsbibliothek libevent, um das Netzwerk-Parallelitätsmodell zu implementieren. Memcached kann in Umgebungen mit einer großen Anzahl gleichzeitiger Benutzer verwendet werden. Die Verwendung des Cache-Systems zur Implementierung von Lesevorgängen entspricht der Verwendung des „Pre-Read-Cache“ der Datenbank, wodurch die Durchsatzrate erheblich verbessert werden kann . Auch bei Schreibvorgängen können Caching-Systeme enorme Vorteile bringen. Zu den üblichen Schreibvorgängen für Daten gehören das Einfügen, Aktualisieren und Löschen. Diese Schreibvorgänge werden häufig von Suchvorgängen und Indexaktualisierungen begleitet, was häufig zu einem enormen Mehraufwand führt. Bei Verwendung des verteilten Caches können wir Daten vorübergehend im Cache speichern und dann Batch-Schreibvorgänge ausführen. Als verteiltes Cache-System kann memcached Aufgaben gut erledigen. Gleichzeitig stellt memcached auch Protokolle bereit, die es uns ermöglichen, seinen Echtzeitstatus zu ermitteln Es gibt mehrere wichtige Informationen: Speicherplatznutzung: Wenn wir auf die Cache-Speicherplatznutzung achten, können wir wissen, wann wir das Cache-System erweitern müssen, um eine passive Löschung von Daten aufgrund des Cache-Speicherplatzes zu vermeiden satt sein. Cache-Trefferrate E/A-Verkehr: spiegelt die Arbeitslast des Cache-Systems wider, anhand derer Sie erkennen können, ob Memcached inaktiv ist oder beschäftigt. Gleichzeitige Verarbeitungsfähigkeiten, Cache-Speicherplatzkapazität usw. können an ihre Grenzen stoßen und eine Erweiterung ist unvermeidlich. Wenn es mehrere Cache-Server gibt, besteht das Problem darin, wie wir die Cache-Daten ausbalancieren auf mehrere Cache-Server verteilen können? In diesem Fall können Sie eine schlüsselbasierte Partitionierungsmethode wählen, um die Schlüssel aller Datenelemente gleichmäßig auf verschiedene Server zu verteilen, z. B. die Verwendung der Restmethode. Wenn wir in diesem Fall das System aufgrund von Änderungen im Partitionierungsalgorithmus erweitern, müssen wir die zwischengespeicherten Daten von einem Cache-Server auf einen anderen migrieren. Tatsächlich besteht überhaupt keine Notwendigkeit, über eine Migration nachzudenken Da es sich um zwischengespeicherte Daten handelt, erstellen Sie einfach den Cache neu. Die Verwendung des Caches erfordert eine detaillierte Analyse spezifischer Probleme. Als ich beispielsweise ein Praktikant bei Baidu war, wurde die Verwendung des dynamischen Inhalts-Cachings nur für die Ergebnisse einer Suche in viele Ebenen unterteilt. Kurz gesagt: Verwenden Sie Caching, wenn Sie können, und verwenden Sie Caching so schnell wie möglich Aktueller Job Das Startup-Unternehmen Youzan verwendet Redis jetzt für dynamisches Content-Caching und verbessert sich Schritt für Schritt. Oh, ich hätte es fast vergessen, es gibt auch Browser-Caching. <br/> Das einfache Verständnis von PHP Static besteht darin, die von der Website generierten Seiten in Form von statischem HTML anzuzeigen. PHP ist in Rein statisch Pseudostatisch : Speichern Sie den Inhalt im NoSQL-Speicher (memcached) und greifen Sie dann beim Lesen direkt auf die Seite zu aus der Erinnerung. Statisierung großer dynamischer Websites Referenzartikel: „Statische Verarbeitung großer Websites“ <br/>Große Websites (hoher Datenverkehr, hohe Parallelität), wenn Da es sich um eine statische Website handelt, können Sie genügend Webserver erweitern, um einen extrem großen gleichzeitigen Zugriff zu unterstützen. Wenn es sich um eine dynamische Website handelt, insbesondere um eine Website, die eine dynamische Websites statisch zu machen. js, css, img und andere Ressourcen, der Server führt zusammen und gibt zurück CDN-Inhaltsverteilungsnetzwerktechnologie [Effizienz der Netzwerkübertragung und Entfernung Verwandte Prinzipien berechnen mithilfe von Algorithmen den nächstgelegenen statischen Serverknoten. Nachteile: Da die Daten in HTML gespeichert sind, ist die Datei sehr groß. Und das schwerwiegendste Problem besteht darin, dass Sie, wenn Sie den Quellcode ändern, den gesamten Quellcode ändern müssen. Sie können nicht eine Stelle ändern und die statischen Seiten der gesamten Site werden automatisch geändert. Wenn es sich um eine große Website mit vielen Daten handelt, nimmt sie viel Serverplatz ein und jedes Mal, wenn Inhalte hinzugefügt werden, wird eine neue HTML-Seite generiert. Die Wartung ist mühsam, wenn Sie kein Fachmann sind. 2. Dynamische Seite Vorteile: Der Platzbedarf ist sehr gering, im Allgemeinen für Websites mit Zehntausenden Daten: Bei Verwendung dynamischer Seiten kann die Dateigröße nur wenige MB betragen, während bei Verwendung statischer Seiten nur zehn MB, bis zu Dutzende MB oder sogar mehr betragen können. Da die Datenbank aus der Datenbank aufgerufen wird, werden alle dynamischen Webseiten automatisch aktualisiert, wenn Sie einige Werte ändern und die Datenbank direkt ändern müssen. Dieser Vorteil gegenüber statischen Seiten liegt auf der Hand. Nachteile: Die Benutzerzugriffsgeschwindigkeit ist langsam. Warum ist der Zugriff auf dynamische Seiten langsam? Dieses Problem beginnt mit dem Zugriffsmechanismus dynamischer Seiten. Tatsächlich gibt es auf unserem Server eine Interpretations-Engine. Wenn ein Benutzer darauf zugreift, übersetzt diese Interpretations-Engine die dynamische Seite in eine statische Seite, sodass jeder sie sehen kann Browser. Sehen Sie sich den Quellcode an. Und dieser Quellcode ist der Quellcode nach der Übersetzung durch die Interpretationsmaschine. Zusätzlich zur langsamen Zugriffsgeschwindigkeit werden die Daten dynamischer Seiten aus der Datenbank abgerufen. Bei mehr Besuchern ist der Druck auf die Datenbank sehr hoch. Die meisten heutigen dynamischen Programme verwenden jedoch Caching-Technologie. Generell gilt jedoch, dass dynamische Seiten eine größere Belastung für den Server darstellen. Gleichzeitig stellen Websites mit dynamischen Seiten im Allgemeinen höhere Anforderungen an den Server. Je mehr Personen gleichzeitig besuchen, desto größer ist der Druck auf den Server. 3. Pseudostatische Seite Durch URL-Umschreiben wird index.php zu index.html<br/> Pseudostatische SeiteDefinition: „Gefälschte“ statische Seite, im Wesentlichen eine dynamische Seite. Vorteile: Im Vergleich zu statischen Seiten gibt es keine offensichtliche Verbesserung der Geschwindigkeit, da es sich um eine „gefälschte“ statische Seite handelt, aber es handelt sich tatsächlich um eine dynamische Seite, und das muss auch so sein in eine statische Seite übersetzt werden. Der größte Vorteil besteht darin, dass Suchmaschinen Ihre Webseiten als statische Seiten behandeln können. Nachteile: Wie der Name schon sagt, wird „pseudostatisch“ von Suchmaschinen nicht als statische Seite behandelt empirische Logik und nicht unbedingt korrekt. Vielleicht betrachten Suchmaschinen es direkt als dynamische Seite. Einfache Zusammenfassung: Der Zugriff auf statische Seiten ist am schnellsten; die Wartung ist aufwändiger. Dynamische Seiten nehmen wenig Platz ein und sind einfach zu warten; die Zugriffsgeschwindigkeit ist langsam, und wenn viele Leute sie besuchen, wird die Datenbank belastet. Es gibt keinen wesentlichen Unterschied zwischen der Verwendung von rein statischem und pseudostatischem für SEO (Suchmaschinenoptimierung: Suchmaschinenoptimierung). Die Verwendung von Pseudostatik beansprucht einen bestimmten Teil der CPU-Auslastung, und eine starke Nutzung führt zu einer CPU-Überlastung. <br/> Ich bin in dieser Zeit mehrmals mit dem Konzept der CSS-Sprites in Kontakt gekommen, zum einen, als ich CSS zur Herstellung einer Schiebetür verwendet habe, und zum anderen, als ich YSlow verwendet habe Um die Website-Leistung zu analysieren, hat das Konzept der CSS-Sprites großes Interesse geweckt. Ich habe viele Informationen im Internet gesucht, aber leider bestanden die meisten davon nur aus ein paar Wörtern, und einige davon waren direkt empfohlene ausländische Informationswebsites. Leider habe ich den Englischtest nicht bestanden. und ich verstand im Grunde keine CSS-Sprites, ganz zu schweigen davon, wie man sie benutzt. Schließlich ließ ich mich von einem Artikel in Blue Ideal inspirieren und nachdem ich lange darüber nachgedacht hatte, habe ich endlich die Konnotation verstanden, um anderen dabei zu helfen, CSS-Sprites schneller zu beherrschen. Lassen Sie mich das Konzept zunächst kurz vorstellen. Es ist überall im Internet zu finden, daher werde ich es hier kurz erwähnen. Was sind CSS-Sprites? CSS-Sprites werden wörtlich als CSS-Sprites übersetzt, aber diese Übersetzung reicht offensichtlich nicht aus. Tatsächlich erfolgt die Verschmelzung mehrerer Bilder zu einem Bild und dann über CSS Einige Techniken zum Layouten auf Webseiten. Die Vorteile liegen auf der Hand, denn wenn viele Bilder vorhanden sind, erhöht sich die Anzahl der HTTP-Anfragen, was zweifellos die Leistung der Website verringert, insbesondere bei Websites mit vielen Bildern. Wenn Sie CSS-Sprites verwenden können, um diese zu reduzieren Je mehr Bilder es gibt, desto schneller wird es. 下面我们来用一个实例来理解css sprites,受蓝色理想中的《制作一副扑克牌系列教程》启发。 我们仅仅只需要制作一个扑克牌,拿黑桃10为例子。 可以直接把蓝色理想中融合好的一幅大图作为背景,这也是css sprites的一个中心思想,就是把多个图片融进一个图里面。 这就是融合后的图,相信对PS熟悉的同学应该很容易的理解,通过PS我们就可以组合多个图为一个图。 现在我们书写html的结构: 在这里我们来分析强调几点: 一:card为这个黑桃十的盒子或者说快,对p了解的同学应该很清楚这点。 二:我用span,b,em三种标签分别代表三种不同类型的图片,span用来表标中间的图片,b用来表示数定,em用来表示数字下面的小图标。 三:class里面的声明有2种,一个用来定位黑桃10中间的图片的位置,一个用来定义方向(朝上,朝下)。 上面是p基本概念,这还不是重点,不过对p不太清楚的同学可以了解。 下面我们重点谈下定义CSS: span{display:block;width:20px;height:21px; osition:absolute;background:url(images/card.gif) no-repeat;} 这个是对span容器的CSS定义,其他属性就不说了,主要谈下如何从这个里面来理解css sprites。 背景图片,大家看地址就是最开始我们融合的一张大图,那么如何将这个大图中的指定位置显示出来呢?因为我们知道我们做的是黑桃10,这个大图其他的图像我们是不需要的,这就用到了css中的overflow:hidden; 但大家就奇怪了span的CSS定义里面没有overflow:hidden啊,别急,我们已经在定义card的CSS里面设置了(这是CSS里面的继承关系): .card{width:125px;height:170px; position:absolute;overflow:hidden;border:1px #c0c0c0 solid;} 理解到这点还不够,还要知道width:125px;height:170px; 这个可以理解成是对这个背景图片的准确切割,当然其实并不是切割,而是把多余其他的部分给隐藏了,这就是overflow:hidden的妙用。 通过以上的部分的讲解,你一定可以充分的把握css sprites的运用,通过这个所谓的“切割”,然后再通过CSS的定位技术将这些图准确的分散到这个card里面去! PS:CSS的定位技术,大家可以参考其他资料,例如相对定位和绝对定位,这里我们只能尝试用绝对定位。 最后我们来补充一点: 为什么要采取这样的结构? span这个容器是主要作用就是存放这张大的背景图片,并在里面实现”切割“,span里面切割后的背景是所有内容块里面通用的! 后面class为什么要声明2个属性? 很显然,一个是用来定位内容块的位置,一个是用来定义内容块中的图像的朝上和朝下,方位的! 下面我们附上黑桃10的完整源码: 最后感谢蓝色理想提供的参考资料! <br/> <br/> 1、前言 Ich habe kürzlich Reverse-Proxy bei der Arbeit verwendet und festgestellt, dass es viele Möglichkeiten gibt, mit Netzwerk-Proxy zu spielen. Es gibt viel hinter dem Netzwerk, das gelernt werden muss. Zuvor hatte ich nur eine Proxy-Software verwendet. Um auf Google zuzugreifen, musste ich eine Proxy-Software verwenden und die Proxy-Adresse im Browser konfigurieren. Ich kannte nur das Konzept der Agentur, wusste aber nicht, dass es Vorwärts- und Rückwärtsagentur gibt, also habe ich mich schnell damit beschäftigt und mein Wissen ergänzt. Finden Sie zunächst heraus, was ein Forward-Proxy und was ein Reverse-Proxy ist, dann wie die beiden in der tatsächlichen Verwendung demonstriert werden und fassen Sie schließlich zusammen, wofür der Forward-Proxy verwendet wird und was der Reverse-Proxy tun kann. 2. Forward-Proxy Der Forward-Proxy ähnelt einem Sprungbrett und der Proxy greift auf externe Ressourcen zu. Zum Beispiel: Ich kann nicht auf eine Website zugreifen, aber ich kann auf einen Proxyserver zugreifen Ich konnte auf die Website zugreifen, auf die ich nicht zugreifen konnte, also stellte ich zunächst eine Verbindung zum Proxyserver her und teilte ihm mit, dass ich den Inhalt der Website benötige, auf die ich nicht zugreifen konnte. Der Proxyserver holte ihn zurück und gab ihn dann zurück Mich. Aus der Sicht der Website gibt es nur einen Datensatz, wenn der Proxy-Server den Inhalt abruft. Manchmal ist nicht bekannt, dass es sich um die Anfrage des Benutzers handelt, und die Informationen des Benutzers werden auch ausgeblendet. Dies hängt davon ab, ob der Proxy dies der Website mitteilt nicht. Der Client muss einen Forward-Proxy-Server einrichten. Voraussetzung ist natürlich, dass er die IP-Adresse des Forward-Proxy-Servers und den Port des Proxy-Programms kennt. Wenn Sie beispielsweise diese Art von Software bereits verwendet haben, z. B. CCproxy, http://www.ccproxy.com/, müssen Sie die Proxy-Adresse im Browser konfigurieren. Zusammenfassend: Forward-Proxy ist ein Server, der sich zwischen dem Client und dem Ursprungsserver befindet (Ursprungsserver). Für den Inhalt sendet der Client eine Anfrage an den Proxy und gibt das Ziel (ursprünglicher Server) an. Anschließend leitet der Proxy die Anfrage an den ursprünglichen Server weiter und gibt den erhaltenen Inhalt an den Client zurück. Der Client muss einige spezielle Einstellungen vornehmen, um den Forward-Proxy nutzen zu können. Zweck des Forward-Proxys: (1) Zugriff auf Ressourcen, auf die ursprünglich nicht zugegriffen werden konnte, z. B. Google (2) Kann zwischengespeichert werden, um den Zugriff auf Ressourcen zu beschleunigen (3) Client-Zugriff autorisieren und Zugriff auf das Internet authentifizieren (4) Der Agent kann Benutzerzugriffsdatensätze (Online-Verhalten) aufzeichnen Verwaltung), Benutzerinformationen vor der Außenseite verbergen Zum Beispiel CCProxy-Nutzung: 3. Reverse-Proxy Erster Kontakt Richtungs-Proxy Das Gefühl ist, dass der Kunde sich der Existenz des Proxys nicht bewusst ist und der Reverse-Proxy für die Außenwelt transparent ist. Besucher wissen nicht, dass sie einen Proxy besuchen. Weil der Client für den Zugriff keine Konfiguration benötigt. Die eigentliche Betriebsmethode des Reverse Proxy (Reverse Proxy) besteht darin, einen Proxyserver zu verwenden, um Verbindungsanfragen im Internet zu akzeptieren, die Anfrage dann an den Server im internen Netzwerk weiterzuleiten und die vom Server erhaltenen Ergebnisse zurückzugeben Wenn ein Client eine Verbindung im Internet anfordert, erscheint der Proxyserver nach außen als Server. Die Rolle des Reverse-Proxys: (1) Um die Sicherheit des Intranets zu gewährleisten, kann Reverse-Proxy verwendet werden, um WAF-Funktionen bereitzustellen und Webangriffe zu verhindern Große Websites normalerweise verwenden Der Reverse-Proxy dient als öffentliche Netzwerkzugriffsadresse und der Webserver ist das Intranet. (2) Lastausgleich durch Reverse-Proxy-Server zur Optimierung der Auslastung der Website 4. Der Unterschied zwischen den beiden kann anhand von zwei Bildern von Zhihu ausgedrückt werden: https://www.zhihu.com/question/24723688 5. Nginx-Reverse-Proxy Nginx unterstützt die Konfiguration des Reverse-Proxys und erreicht den Lastausgleich der Website über den Reverse-Proxy . In diesem Teil schreiben wir zunächst eine Nginx-Konfiguration und müssen uns dann eingehend mit dem Proxy-Modul und dem Lastausgleichsmodul von Nginx befassen. nginx konfiguriert die Proxy-Site über Proxy_Pass_http und Upstream implementiert den Lastausgleich. Referenz: Proxy bedeutet, wie der Name schon sagt, dass Sie einen Dritten nutzen, um das auszuführen, was Sie in Ihrem Namen tun möchten, und nicht durch Sie selbst. Sie können sich vorstellen, dass zwischen dem lokalen Computer und dem Computer ein zusätzlicher Zwischenserver (Proxyserver) vorhanden ist der Zielserver Ein Forward-Proxy ist ein Server (Proxy-Server), der sich zwischen dem Client und dem ursprünglichen Server befindet Der Client muss zunächst einige notwendige Einstellungen vornehmen (Sie müssen die IP-Adresse und den Port kennen.) sendet jede Anfrage zuerst an den Proxyserver, nachdem sie das Antwortergebnis erhalten hat, und sendet es an den Client zurück . >Eine einfache Erklärung ist, dass der Proxyserver den Client ersetzt, um auf den Zielserver zuzugreifen (Client ausblenden )Funktion: Ein Reverse-Proxy ist genau das Gegenteil, er verhält sich für den Client wie der Ursprungsserver, und Erklären Sie einfach, dass der Proxyserver den Zielserver ersetzt (Zielserver ausblenden). Verstecken Sie den ursprünglichen Server und verhindern Sie, dass der Server böswillige Angriffe usw. vornimmt. Transparenter Proxy bedeutet, dass der Client nicht über die Existenz eines Proxys Bescheid wissen muss Server überhaupt. Es passt Ihre Anfragefelder (Nachrichten) an und überträgt die echte IP. Der transparente Proxy ist ein anonymer Proxy, was bedeutet, dass kein Proxy eingerichtet werden muss >Funktion CDN Ermöglicht Kunden den Zugriff auf jede Website darüber und verbirgt die Daher müssen Sie Sicherheitsmaßnahmen ergreifen, um sicherzustellen, dass nur autorisierte Clients bedient werden. Lösung CDN nutzt das technische Prinzip des Reverse-Proxys und seine wichtigste Kerntechnologie ist Smart DNS usw. MySQL verwendet die Master-Slave-Synchronisationsmethode, um Lesen und Schreiben zu trennen und den Druck auf den Hauptserver zu verringern. Die Praxis wird mittlerweile in der Branche sehr häufig durchgeführt. Durch die Master-Slave-Synchronisation kann grundsätzlich eine Echtzeitsynchronisation erreicht werden. Ich habe mir das Master-Slave-Synchronisationsschema von einer anderen Website ausgeliehen. <br/> <br/> Nachdem die Master-Slave-Synchronisation abgeschlossen ist, schreibt der Master-Server die Update-Anweisung Geben Sie das Binlog ein und lesen Sie es aus dem E/A-Thread des Servers (Beachten Sie hier, dass es vor 5.6.3 nur einen E/A-Thread gab, nach 5.6.3 jedoch mehrere Threads zum Lesen vorhanden sind und die Geschwindigkeit natürlich zunimmt beschleunigt werden) Gehen Sie zurück, lesen Sie das Binlog des Master-Servers und schreiben Sie es in das Relay-Log des Slave-Servers. Anschließend führt der SQL-Thread des Slave-Servers die SQL im Relay-Log nacheinander aus um eine Datenwiederherstellung durchzuführen. <br/> Relais bedeutet Übertragung, Staffellauf bedeutet Staffellauf <br/> 1. Der Grund für die Verzögerung Wir wissen, dass ein Server N Links öffnet, damit Clients eine Verbindung herstellen können. Auf diese Weise wird es große gleichzeitige Aktualisierungsvorgänge geben, aber es gibt nur einen Thread, der das Binlog vom Server liest Erstens: Wenn die Ausführung einer bestimmten SQL auf dem Slave-Server etwas länger dauert oder weil eine bestimmte SQL die Tabelle sperren muss, führt dies zu einem großen SQL-Rückstand auf dem Master-Server und wird nicht mit dem Slave-Server synchronisiert. Dies führt zu einer Master-Slave-Inkonsistenz, also einer Master-Slave-Verzögerung. <br/> 2. Lösung für die Master-Slave-Synchronisationsverzögerung Tatsächlich gibt es keine One-Shot-Lösung für Master-Slave Bei dieser Methode muss das gesamte SQL auf dem Slave-Server ausgeführt werden. Wenn jedoch weiterhin Aktualisierungsvorgänge auf dem Master-Server ausgeführt werden, ist die Wahrscheinlichkeit größer, dass sich die Verzögerung verschlimmert, sobald eine Verzögerung auftritt. Natürlich können wir einige Abhilfemaßnahmen ergreifen. a. Da der Master-Server für Aktualisierungsvorgänge verantwortlich ist, sind einige Einstellungen änderbar, z. B. sync_binlog=1, innodb_flush_log_at_trx_commit = 1 Klasseneinstellungen, und Slave benötigt keine so hohe Datensicherheit. Sie können sync_binlog auf 0 setzen oder binlog deaktivieren, innodb_flushlog, innodb_flush_log_at_trx_commit kann auch auf 0 gesetzt werden, um die Ausführungseffizienz von SQL zu verbessern. Dies kann die Effizienz erheblich verbessern . Die andere Möglichkeit besteht darin, als Slave ein besseres Hardwaregerät als die Hauptbibliothek zu verwenden. b. Das heißt, ein Slave-Server wird als Backup verwendet, ohne Abfragen bereitzustellen. Wenn seine Last reduziert wird, verringert sich natürlich die Effizienz der Ausführung des SQL hoch. . c. Der Zweck des Hinzufügens von Slave-Servern besteht darin, den Lesedruck zu verteilen und dadurch die Serverlast zu reduzieren. <br/> 3. Methode zur Bestimmung der Master-Slave-Verzögerung MySQL bietet Der Befehl „Slave-Server-Status“ kann über „Slave-Status anzeigen“ angezeigt werden. Sie können beispielsweise den Wert des Parameters Seconds_Behind_Master anzeigen, um festzustellen, ob eine Master-Slave-Verzögerung vorliegt. <br/>Es gibt mehrere Werte: <br/>NULL – zeigt an, dass entweder io_thread oder sql_thread fehlgeschlagen ist, d. h. der Ausführungsstatus des Threads ist Nein, nicht Ja.<br/>0 – Dieser Wert ist Null, worauf wir sehr gespannt sind, was darauf hinweist, dass der Master-Slave-Replikationsstatus normal ist <br/> <br/> > . Memcached unterstützt nur einfache Schlüssel-Wert-Strukturen. <br/>> 2. Memcached-Schlüsselwertspeicher hat eine höhere Speicherauslastung als Redis, das eine Hash-Struktur für den Schlüsselwertspeicher verwendet. <br/>> 3. Redis bietet Transaktionsfunktionen, die die Atomizität einer Reihe von Befehlen sicherstellen können <br/>> 4. Redis unterstützt Datenpersistenz und kann Daten im Speicher auf der Festplatte halten <br/>> verwendet einen einzelnen Kern, während Memcached mehrere Kerne verwenden kann, sodass Redis im Durchschnitt eine höhere Leistung als Memcached aufweist, wenn kleine Daten auf jedem Kern gespeichert werden. <br/><br/>- Wie erreicht Redis Persistenz? <br/><br/>> 1. RDB-Persistenz, Speichern des Redis-Status im Speicher auf der Festplatte, was einer Sicherung des Datenbankstatus entspricht. <br/>> 2. AOF-Persistenz (Append-Only-File), AOF-Persistenz zeichnet die Datenbank auf, indem der Schreibstatus der Redis-Serversperrenausführung gespeichert wird. Äquivalent zu den von der Sicherungsdatenbank empfangenen Befehlen werden alle in AOF geschriebenen Befehle im Redis-Protokollformat gespeichert. <br/> <br/> <br/> Apache HTTP Server ist ein modularer Server, der auf fast allen weit verbreiteten < laufen kann 🎜>Computerplattform. Es gehört zum Anwendungsserver. Apache unterstützt viele Module und hat eine stabile Leistung Apache selbst ist eine statische Analyse, geeignet für statisches HTML , Bilder usw., kann aber dynamische Seiten usw. durch erweiterte Skripte, Module usw. unterstützen. (Apche kann PHPcgiperl, unterstützen, aber Sie müssen verwenden Java, Sie benötigen Tomcat, um Apache im Hintergrund zu unterstützen, und verwenden Sie Java Anfragen werden von Apache an Tomcat )<🎜 weitergeleitet > 2. Tomcat: ist ein Anwendungsserver (Java). ist nur ein Servlet (JSP wird auch als Servlet übersetzt) Container, der als Apache betrachtet werden kann Erweiterung, kann aber unabhängig von Apache ausgeführt werden. 3. Nginx ist ein sehr leichter HTTP<🎜, der von den Russen geschrieben wurde > Server , Nginx , das als „Engine X“ ausgesprochen wird, ist ein leistungsstarkes HTTP und Reverse-Proxy-Server, auch ein IMAP/POP3/SMTP -Proxyserver. 2. Vergleich l Beide werden von der ApacheOrganisationl entwickelt BeideHTTPFunktion des Dienstesl Beide kostenlos Unterschiede: l Apache wird speziell zur Bereitstellung von HTTP < verwendet 🎜>-Dienst und zugehörige Konfiguration (z. B. virtueller Host, URL-Weiterleitung usw.), während Tomcat ist Apache ist in Java EE-kompatiblem JSP, Servlet organisiert Ein JSPServerl Apache ist ein Web Serverumgebungsprogramm , aktiviert es als Web Der Server verwendet , , unterstützt aber nur statische Webseiten wie (ASP, PHP, CGI, JSP) und andere dynamische Seiten Die Webseite funktioniert nicht. Wenn Sie JSP in der Apache-Umgebung ausführen möchten, benötigen Sie einen Interpreter, um JSP<🎜 auszuführen > Webseite, und dieser JSP-Interpreter ist Tomcat. l Apache: HTTPServer , Tomcat : konzentriert sich auf die Servlet-Engine. Wenn sie im Standalone-Modus ausgeführt wird, ist sie funktional die Das Gleiche wie Apache ist äquivalent und unterstützt JSP, ist jedoch nicht ideal für statische Webseiten; 🎜>l Apache ist ein Web Server, Tomcat ist ein Anwendungsserver (Java), es ist nur ein Servlet (JSP wird auch als Servlet übersetzt) -Container, der als Apache-Erweiterung betrachtet werden kann, aber unabhängig von Apache ausgeführt werden kann. Im tatsächlichen Einsatz sind Apache und häufig integriert und verwendet: l Wenn der Client eine statische Seite anfordert, benötigen Sie nur den Apache-Server um auf die Anfrage zu antworten. l Wenn der Client eine dynamische Seite anfordert, ist es der Tomcat-Server, der auf die Anfrage antwortet. l Da JSP Code auf der Serverseite interpretiert, kann die Integration reduzieren Service-Overhead von Tomcat. Es versteht sich, dass Tomcat eine Erweiterung von Apache ist. belegt weniger Speicher und Ressourcen l Anti-Parallelität, nginx verarbeitet Anfragen asynchron und nicht blockierend, während Apache blockiert , bei hoher Parallelität nginx kann einen geringen Ressourcenverbrauch und eine hohe Leistung aufrechterhalten l Sehr modularer Aufbau, das Schreiben von Modulen ist relativ einfach Sorgen für Lastausgleichl 2) Vorteile von ; Unterstützt dynamische Seiten; l unterstützt viele Module, die grundsätzlich alle Anwendungen abdecken l hat eine stabile Leistung, während nginx als . 3) Vergleich der Vor- und Nachteile der beiden l Nginx Einfache Konfiguration, Apache Komplex statische Verarbeitungsleistung ist mehr als Apache 3 mal höher als ; Nginx muss mit anderen Backends verwendet werden l Apache hat mehr Komponenten als Nginx viele l ; ist ein synchrones Multiprozessmodell, eine Verbindung entspricht einem Prozess; nginx ist asynchron, mehrere Verbindungen (10.000 Ebenen) kann einem Prozess entsprechen l nginx verarbeitet statische Dateien gut , verbraucht weniger Speicher l Dynamische Anfragen werden von Apache erledigt, nginx ist nur für Statik und Reverse geeignet; l Nginx ist für Front-End-Server geeignet und hat eine gute Lastleistung; >l selbst ist ein Reverse-Proxy-Server und unterstützt den Lastausgleich3 Vorteile: Lastausgleich, Reverse-Proxy, Vorteile der statischen Dateiverarbeitung. nginx verarbeitet statische Anfragen schneller als Apache; >Apache Vorteile: Im Vergleich zum Tomcat Apache ist eine statische Analyse, geeignet für statisches HTML, Bilder usw. l Tomcat: Dynamisches Parsen des Containers, Verarbeiten dynamischer Anforderungen und Kompilieren von JSPServlet Nginx verfügt über einen dynamischen Trennungsmechanismus. Statische Anfragen können direkt über Nginx verarbeitet werden, und dynamische Anfragen werden an den weitergeleitet Hintergrund für die Verarbeitung. Verwaltet von Tomcat. Apache hat Vorteile, Nginx hat eine bessere Parallelität, CPUgeringer Speicherverbrauch, wenn Umschreiben häufig ist Apache ist besser geeignet. 22 Port, Prozess<br/>1. Verwenden Sie lsof <br/> <br/><br/>Der Befehl top ist ein unter Linux häufig verwendetes Leistungsanalysetool. Er kann die Ressourcennutzung jedes Prozesses im System in Echtzeit anzeigen, ähnlich wie der Windows-Task-Manager 1. 在 LINUX 命令平台输入 1-2 个字符后按 Tab 键会自动补全后面的部分(前提是要有这个东西,例如在装了 tomcat 的前提下, 输入 tomcat 的 to 按 tab)。<br/>2. ps 命令用于查看当前正在运行的进程。<br/>grep 是搜索<br/>例如: ps -ef | grep java<br/>表示查看所有进程里 CMD 是 java 的进程信息<br/>ps -aux | grep java<br/>-aux 显示所有状态<br/>ps<br/>3. kill 命令用于终止进程<br/>例如: kill -9 [PID]<br/>-9 表示强迫进程立即停止<br/>通常用 ps 查看进程 PID ,用 kill 命令终止进程<br/>网上关于这两块的内容<br/> <br/> <br/> <br/> 优化手段主要有缓存、集群、异步等。 网站性能优化第一定律:优先考虑使用缓存。 1 2 <br/> <br/> <br/> 任何可以晚点做的事情都应该晚点再做。 摘自《大型网站技术架构》–李智慧 <br/> 手机网站支付主要应用于手机、掌上电脑等无线设备的网页上,通过网页跳转或浏览器自带的支付宝快捷支付实现买家付款的功能,资金即时到账。 1、您申请前必须拥有企业支付宝账号(不含个体工商户账号),且通过支付宝实名认证审核。<br/>2、如果您有已经建设完成的无线网站(非淘宝、天猫、诚信通网店),网站经营的商品或服务内容明确、完整(古玩、珠宝等奢侈品、投资类行业无法申请本产品)。<br/>3、网站必须已通过ICP备案,备案信息与签约商户信息一致。 假设我们已经成功申请到手机网站支付接口,在进行开发之前,需要使用公司账号登录支付宝开放平台。 1、开发者登录开放平台,点击右上角的“账户及密钥管理”。<br/> 2、选择“合作伙伴密钥”,即可查询到合作伙伴身份(PID),以2088开头的16位纯数字。<br/> 支付宝提供了DSA、RSA、MD5三种签名方式,本次开发中,我们使用RSA签名和加密,那就只配置RSA密钥就好了。 关于RSA加密的详解,参见《支付宝签名与验签》。 本节可以忽略,本节可以忽略,本节可以忽略!因为官方文档并没有提及应用环境配置的问题。 进入管理中心,对应用进行设置。<br/> return_url,支付完成后的回调url;notify_url,支付完成后通知的url。支付宝发送给两个url的参数是一样的,只不过一个是get,一个是post。 以上两种发起请求的方式中,return_url在Node端,notify_url在后端。我们也可以根据需要,把两个url都放在后端,或者都放在Node端,改变相应业务逻辑即可。 Node端发起支付请求有两种选择,一种是获取到后端给的参数后,通过request模块发起get请求,获取到支付宝返回的支付页面,然后显示到页面上;另一种是获取到后端给的参数后,把参数全部输出到页面中的form表单,然后通过js自动提交表单,获取到支付宝返回的支付页面(同时显示出来)。 理论上完全正确的请求,然而,获取到的支付页面,输出到页面上,却是乱码。没错,还是一个错误提示页面。<br/> 神奇的地方在于,在刷新页面多次后,正常了!!!啊嘞,这是什么鬼? 先解决乱码问题,看看报什么错! 很遗憾,无效!乱码依然是乱码。。。和沈晨帅哥讨论很久,最终决定换一种方案——利用表单提交。 开始时,打算把alidata直接输出到form表单的action中接口的后面,因为这样似乎最简便。但是,提交表单时,后面的参数全部被丢弃了。所以,不得不得把所有参数放在form表单中。Node端拆分了一下参数,组装成了一个alipayParam对象,这个工作也可以交给后端来做。 显然,request模拟表单提交和真实表单提交结果的不同,得出的结论是,request并不能完全模拟表单提交。或者,request可以模拟,而我不会-_-|||。 以上,大功告成?不!还有一个坑要填,因为微信屏蔽了支付宝!<br/>在电脑上,跳转支付宝支付页面正常,很完美!然而,在微信浏览器中测试时,却没有跳转,而是出现如下信息。<br/> 微信端支付宝支付,iframe改造<br/>http://www.cnblogs.com/jiqing9006/p/5584268.html 该办法的核心在于:把微信屏蔽的链接,赋值给iframe的src属性。 然而,在改造时,先是报错ILLEGAL_SIGN,于是利用urlencode处理了字符串。接着,又报错ILLEGAL_EXTERFACE,没有找到解决办法。 暂时放弃,以后如果有了解决办法再补上。 关于微信公众平台无法使用支付宝收付款的解决方案说明<br/>https://cshall.alipay.com/enterprise/help_detail.htm?help_id=524702 该方法的核心在于:确认支付时,提示用户打开外部系统浏览器,在系统浏览器中支付。 该页面会自动跳转到同一文件夹下的pay.htm,该文件官方已经提供,把其中的引入ap.js的路径修改一下即可。最终效果如下:<br/> 支付宝的支付流程和微信的支付流程,有很多相似之处。沈晨指出一点不同:支付宝支付完成后有return_url和notify_url;微信支付完成后只有notify_url。 研读了一下微信支付的开发文档,确实如此。微信支付完成后的通知也分成两路,一路通知到notify_url,另一路返回给调用支付接口的JS,同时发微信消息提示。也就是说,跳转return_url的工作我们需要自己做。 最后,感谢沈晨帅哥提供的思路和帮助,感谢体超帅哥辛苦改后端。 Alipay Open Platform<br/>https://openhome.alipay.com/platform/home.htm Alipay Open Platform-Mobile Website Payment-Document Center<br/> https://doc.open.alipay.com/doc2/detail?treeId=60&articleId=103564&docType=1 Entwicklung der Alipay WAP-Zahlungsschnittstelle<br/>http://blog.csdn.net/tspangle/article /details/39932963 wap h5 mobile Website-Zahlungsschnittstelle erinnert an Alipay-Wallet-Zahlung Händlerservice – Alipay kennt das Vertrauen! <br/>https://b.alipay.com/order/techService.htm WeChat Payment-Development Document<br/>https://pay.weixin.qq.com/wiki/doc/api/ jsapi.php?chapter=7_1 Alipay-Zahlung auf WeChat, Iframe-Transformation<br/>http://www.cnblogs.com/jiqing9006/p/5584268.html Wie man durchbricht Alipay zur WeChat-Blockade<br/>http://blog.csdn.net/lee_sire/article/details/49530875 JavaScript-Thema (2): Vertiefendes Verständnis von Iframe<br/>http://www .cnblogs.com/ fangjins/archive/2012/08/19/2645631.html Anweisungen zur Lösung für die Unfähigkeit, Alipay zum Empfangen und Bezahlen auf der öffentlichen WeChat-Plattform zu verwenden<br/>https:// cshall.alipay.com/enterprise/help_detail.htm ?help_id=524702 <br/> Wie kann das Verkehrsproblem bei den heutigen stark frequentierten Websites mit Dutzenden oder sogar Hunderten Millionen Zugriffen pro Tag gelöst werden? Im Folgenden finden Sie einige zusammenfassende Methoden: Bestätigen Sie zunächst, ob Die Serverhardware reicht aus, um den aktuellen Datenverkehr zu unterstützen. Gewöhnliche P4-Server können im Allgemeinen bis zu 100.000 unabhängige IPs pro Tag unterstützen. Wenn die Anzahl der Besuche höher ist, müssen Sie zunächst einen dedizierten Server mit höherer Leistung konfigurieren, um das Problem zu lösen Es ist unmöglich, das Leistungsproblem vollständig zu lösen. Zweitens optimieren Sie den Datenbankzugriff. Ein wichtiger Grund für die übermäßige Belastung des Servers ist, dass die CPU-Last zu groß ist. Nur durch eine Reduzierung der Belastung der Server-CPU kann der Engpass effektiv beseitigt werden. Durch die Verwendung statischer Seiten kann die Belastung der CPU minimiert werden. Natürlich ist es am besten, eine vollständige Statik der Rezeption zu erreichen, da überhaupt kein Zugriff auf die Datenbank erforderlich ist. Bei Websites, die häufig aktualisiert werden, kann die Statik jedoch häufig bestimmte Funktionen nicht erfüllen. Eine weitere Lösung ist die Caching-Technologie, die darin besteht, dynamische Daten in Cache-Dateien zu speichern, ohne auf die Datenbank zugreifen zu müssen. Sowohl WordPress als auch Z-Blog nutzen diese Caching-Technologie umfassend. Ich habe auch ein Z-Blog-Counter-Plugin geschrieben, das ebenfalls auf diesem Prinzip basiert. Wenn es tatsächlich unvermeidbar ist, auf die Datenbank zuzugreifen, können Sie versuchen, die Abfrage-SQL der Datenbank zu optimieren. Vermeiden Sie die Verwendung von Anweisungen wie „Select *from“ (Jede Abfrage gibt nur die Ergebnisse zurück, die Sie benötigen), und vermeiden Sie so eine große Anzahl von SQL-Abfragen Zeitspanne. Drittens ist das externe Hotlinking verboten. Das Hotlinken von Bildern oder Dateien von externen Websites bringt oft einen hohen Lastdruck mit sich, daher sollte das Hotlinken von eigenen Bildern oder Dateien strikt eingeschränkt werden. Glücklicherweise kann das Hotlinking einfach durch Verweis gesteuert werden, und Apache selbst kann es so konfigurieren, dass es Hotlinks verbietet , IIS verfügt auch über einige ISAPIs von Drittanbietern, die dieselbe Funktion erreichen können. Natürlich können gefälschte Verweise auch verwendet werden, um Hotlinking durch Code zu erreichen, aber derzeit gibt es nicht viele Leute, die absichtlich Verweise und Hotlinking fälschen. Sie können dies vorerst ignorieren oder nichttechnische Mittel verwenden, um das Problem zu lösen, z. B. das Hinzufügen von Wasserzeichen zu Bildern. Viertens kontrollieren Sie den Download großer Dateien. Das Herunterladen großer Dateien nimmt viel Datenverkehr in Anspruch, und bei Nicht-SCSI-Festplatten verbraucht das Herunterladen einer großen Anzahl von Dateien die CPU und verringert die Reaktionsfähigkeit der Website. Versuchen Sie daher, keine Downloads großer Dateien mit einer Größe von mehr als 2 MB bereitzustellen. Wenn Sie diese bereitstellen müssen, wird empfohlen, die großen Dateien auf einem anderen Server zu platzieren. Derzeit gibt es viele kostenlose Web2.0-Websites, die Funktionen zum Teilen von Bildern und Dateien bieten. Sie können also versuchen, Bilder und Dateien auf diese Sharing-Websites hochzuladen. Fünftens: Verwenden Sie verschiedene Hosts, um den Hauptverkehr umzuleiten. Platzieren Sie Dateien auf verschiedenen Hosts und stellen Sie den Benutzern unterschiedliche Bilder zum Herunterladen zur Verfügung. Wenn Sie beispielsweise das Gefühl haben, dass RSS-Dateien viel Datenverkehr beanspruchen, nutzen Sie Dienste wie FeedBurner oder FeedSky, um die RSS-Ausgabe auf anderen Hosts zu platzieren. Auf diese Weise wird der größte Teil des Datenverkehrsdrucks durch den Zugriff anderer Personen konzentriert Der Host von FeedBurner und RSS belegen nicht zu viele Ressourcen. Sechstens: Verwenden Sie eine Verkehrsanalyse- und Statistiksoftware. Durch die Installation einer Verkehrsanalyse- und Statistiksoftware auf der Website können Sie sofort erkennen, wo viel Verkehr verbraucht wird und welche Seiten optimiert werden müssen. Daher ist eine genaue statistische Analyse erforderlich, um das Verkehrsproblem zu lösen. Die von mir empfohlene Software zur Verkehrsanalyse und -statistik ist Google Analytics. Ich bin der Meinung, dass die Wirkung bei der Verwendung sehr gut ist. Später werde ich einige gesunde Menschenverstand und Fähigkeiten im Umgang mit Google Analytics im Detail vorstellen. 1. Geteilte Tabellen 2. Trennung von Lesen und Schreiben 3. Front-End-Optimierung. Nginx ersetzt Apache (Front-End-Lastausgleich). Die Optimierung von MySQL und Cache ist jedoch begrenzt, nachdem die PV gewachsen ist , nur die Heap-Maschine kann erweitert werden. Im Anhang finden Sie einige Optimierungserfahrungen. Lernen Sie zunächst, EXPLAIN-Anweisungen zur Analyse von Indizes und Tabellenstrukturen zu verwenden. Versuchen Sie es schließlich, wenn möglich, mit Caches wie Memcache um Facebooks Hiphop-PHP zu verwenden, um die Programmeffizienz zu verbessern. <br/> Vergleich von NoSQL- und relationalen Datenbankdesignkonzepten <br/> Relationale Datenbank Tabellen speichern einige formatierte Datenstrukturen. Auch wenn nicht jedes Tupel alle Felder zuordnet, kann eine solche Struktur Operationen wie Verbindungen zwischen Tabellen erleichtern Aus einer anderen Perspektive ist es auch ein Faktor für den Leistungsengpass relationaler Datenbanken. Nicht relationale Datenbanken speichern Schlüssel-Wert-Paare und ihre Struktur ist nicht festgelegt. Jedes Tupel kann nach Bedarf einige seiner eigenen Schlüssel-Wert-Paare hinzufügen Struktur kann den Zeit- und Platzaufwand reduzieren. <br/><br/>Eigenschaften: <br/>Sie können extrem große Datenmengen verarbeiten. <br/>Sie laufen auf Clustern billiger PC-Server. <br/>Sie beseitigen Leistungsengpässe. <br/>Keine übermäßigen Operationen. <br/>Bootstrap-Unterstützung <br/><br/>Nachteile: <br/>Aber einige Leute geben zu, dass es ohne formelle offizielle Unterstützung schrecklich sein kann, wenn etwas schief geht, zumindest sehen das viele Manager so. <br/>Außerdem hat nosql keinen bestimmten Standard entwickelt, und das interne Chaos ist intern. Es braucht Zeit, um verschiedene Projekte zu testen > MySQL oder NoSQL: So wählen Sie eine Datenbank im Open-Source-Zeitalter aus Zusammenfassung: MySQL, eine relationale Datenbank, hat eine große Anzahl von Unterstützern. NoSQL, eine nicht relationale Datenbank, gilt als Datenbankrevolutionär. Die beiden scheinen dazu bestimmt zu sein, gegeneinander zu kämpfen, aber sie gehören beide zur Open-Source-Familie, können aber Hand in Hand gehen, in Harmonie leben und zusammenarbeiten, um Entwicklern bessere Dienste zu bieten. Wie man wählt: Die immer richtige klassische Antwort lautet immer noch: spezifische Analyse spezifischer Probleme. <br/>MySQL ist klein, schnell, kostengünstig, stabil in der Struktur, einfach abzufragen und kann Datenkonsistenz gewährleisten, aber es mangelt ihm an Flexibilität. NoSQL verfügt über eine hohe Leistung, hohe Skalierbarkeit und hohe Verfügbarkeit. Es ist nicht auf eine feste Struktur beschränkt und reduziert den Zeit- und Platzaufwand, es ist jedoch schwierig, die Datenkonsistenz sicherzustellen. Beide haben eine große Anzahl von Nutzern und Unterstützern, und die Suche nach einer Kombination aus beiden ist zweifellos eine gute Lösung. Der Autor John Engates ist CTO der Hosting-Abteilung von Rackspace und ein Open-Cloud-Unterstützer. Er liefert uns eine detaillierte Analyse. http://www.csdn.net/article/2014-03-05/2818637-open-source-data-grows-choosing-mysql-nosql Eines auswählen? Oder willst du beides? Ob die Anwendung an einer relationalen Datenbank oder NoSQL (vielleicht an beiden) ausgerichtet werden soll, hängt natürlich von der Art der Daten ab, die generiert oder abgerufen werden. Wie bei den meisten Dingen in der Technik gibt es bei der Entscheidungsfindung Kompromisse. Wenn Skalierung und Leistung wichtiger sind als 24-Stunden-Datenkonsistenz, dann ist NoSQL eine ideale Wahl (NoSQL basiert auf dem BASE-Modell – grundsätzlich verfügbar, weich). Zustand, letztendliche Konsistenz). Aber wenn Sie „immer konsistent“ sein möchten, insbesondere bei vertraulichen Informationen und Finanzinformationen, dann ist MySQL wahrscheinlich die beste Wahl (MySQL basiert auf dem ACID-Modell). - Atomarität, Konsistenz, Unabhängigkeit und Haltbarkeit). Da es sich um eine Open-Source-Datenbank handelt, entwickeln sich sowohl relationale als auch nicht-relationale Datenbanken ständig weiter. Wir können davon ausgehen, dass es eine große Anzahl von Datenbanken geben wird, die auf ACID basieren und BASE-Modelle werden generiert. Obwohl 2009 ein relativ radikaler Artikel „Relationale Datenbank ist tot“ erschien, wissen wir alle in unserem Herzen, dass relationale Datenbanken tatsächlich noch am Leben sind. Auf eine relationale Datenbank geht es noch nicht. Es verdeutlicht aber auch, dass es bei der Verarbeitung von WEB2.0-Daten tatsächlich zu Engpässen in relationalen Datenbanken gekommen ist. Sollten wir also NoSQL oder eine relationale Datenbank verwenden? Ich glaube nicht, dass wir eine absolute Antwort geben müssen. Wir müssen anhand unserer Anwendungsszenarien entscheiden, was wir verwenden. Wenn die relationale Datenbank in Ihrem Anwendungsszenario sehr gut funktionieren kann und Sie die relationale Datenbank sehr gut verwenden und warten können, besteht meiner Meinung nach keine Notwendigkeit für Sie, auf NoSQL zu migrieren, es sei denn, Sie sind ein Person, die gerne wirft. Wenn Sie in Schlüsselbereichen tätig sind, in denen Daten von entscheidender Bedeutung sind, beispielsweise im Finanzwesen und in der Telekommunikation, verwenden Sie derzeit eine Oracle-Datenbank, um eine hohe Zuverlässigkeit zu gewährleisten. Probieren Sie NoSQL nicht überstürzt aus, es sei denn, Sie stoßen auf einen besonders großen Engpass. Allerdings weisen die meisten relationalen Datenbanken auf WEB2.0-Websites Engpässe auf. Entwickler investieren viel Aufwand in die Optimierung der Festplatten-E/A und der Datenbankskalierbarkeit, z. B. Datenbank-Sharding, Master-Slave-Replikation, heterogene Replikation usw. Diese Aufgaben erfordern jedoch mehr technische Fähigkeiten und werden immer anspruchsvoller. Wenn Sie diese Situationen durchmachen, sollten Sie NoSQL meiner Meinung nach ausprobieren. <br/> Relativ zu strukturierten In-Begriffen Daten (d. h. Zeilendaten, die in der Datenbank gespeichert sind und deren implementierte Daten mithilfe einer zweidimensionalen Tabellenstruktur logisch ausgedrückt werden können) werden als unstrukturiert bezeichnet Daten, einschließlich aller Formate Office-Dokumente, Text, Bilder, XML, HTML, verschiedene Berichte, Bilder und Audio-/Videoinformationen usw. Unstrukturierte Datenbank bezieht sich auf eine Datenbank, deren Feldlängen variabel sind und deren Datensätze aus wiederholbaren oder nicht wiederholbaren Unterfeldern bestehen können. Sie kann nicht nur strukturierte Daten (z. B. Zahlen), Symbole usw. verarbeiten andere Informationen) und eignet sich besser für die Verarbeitung unstrukturierter Daten (Volltext, Bilder, Töne, Film und Fernsehen, Hypermedia und andere Informationen). Die unstrukturierte WEB-Datenbank wird hauptsächlich für unstrukturierte Daten generiert. Im Vergleich zu den in der Vergangenheit beliebten relationalen Datenbanken besteht ihr größter Unterschied darin, dass sie die Einschränkungen der relationalen Datenbankstrukturdefinition durchbricht, die nicht einfach zu ändern ist Die feste Länge der Daten unterstützt wiederholte Felder, Unterfelder und Felder variabler Länge und implementiert die Verarbeitung von Daten variabler Länge und wiederholter Felder sowie die Speicherverwaltung variabler Länge von Datenelementen. Textinformationen) und unstrukturierte Informationen (einschließlich verschiedener Multimediainformationen) bieten Vorteile, die herkömmliche relationale Datenbanken nicht bieten können. Strukturierte Daten (d. h. Zeilendaten, die in der Datenbank gespeichert sind und eine zweidimensionale Tabellenstruktur verwenden können, um die implementierten Daten logisch auszudrücken) Unstrukturierte Daten, einschließlich aller Formate von Office-Dokumenten, Text, Bildern, XML, HTML, verschiedenen Berichten, Bildern und Audio-/Videoinformationen usw. Die sogenannten Halbstrukturierte Daten sind Daten zwischen vollständig strukturierten Daten (z. B. Daten in relationalen Datenbanken und objektorientierten Datenbanken) und vollständig unstrukturierten Daten (z. B. Töne, Bilddateien usw.). HTML-Dokumente sind halbstrukturierte Daten. Es ist im Allgemeinen selbstbeschreibend und die Struktur und der Inhalt der Daten sind ohne offensichtliche Unterscheidung miteinander vermischt. Strukturierte Daten: zweidimensionale Tabelle (relational) <br/>Halbstrukturierte Daten: Baum, Diagramm <br/>Unstrukturierte Daten: keine Zu den Datenmodellen von RMDBS gehören: Netzwerkdatenmodell, hierarchisches Datenmodell, relationales Andere: Strukturierte Daten: zuerst Struktur, dann Daten <br/> Halbstrukturierte Daten: zuerst Daten, dann Struktur Mit der Entwicklung der Netzwerktechnologie, insbesondere der rasanten Entwicklung des Internets und Die Intranet-Technologie hat dazu geführt, dass die Menge unstrukturierter Daten von Tag zu Tag zunimmt. Zu dieser Zeit wurden die Grenzen relationaler Datenbanken, die hauptsächlich zur Verwaltung strukturierter Daten eingesetzt werden, immer deutlicher. Daher ist die Datenbanktechnologie entsprechend in das „postrelationale Datenbankzeitalter“ eingetreten und hat sich zum Zeitalter unstrukturierter Datenbanken basierend auf Netzwerkanwendungen entwickelt. Die unstrukturierte Datenbank meines Landes wird durch die IBase-Datenbank von Beijing Guoxin Base (iBase) Software Co., Ltd. repräsentiert. Die IBase-Datenbank ist eine unstrukturierte Datenbank für Endbenutzer. Sie befindet sich auf dem international fortgeschrittenen Niveau in den Bereichen Verarbeitung unstrukturierter Informationen, Volltextinformationen, Multimedia-Informationen und Masseninformationen Ebene in der Verwaltung und Verwaltung unstrukturierter Daten. Ein Durchbruch in der Volltextsuche. Es hat hauptsächlich die folgenden Vorteile: (1) In Internetanwendungen gibt es eine große Anzahl komplexer Datentypen. iBase kann verschiedene Dokumentinformationen und Multimediainformationen über seine externen Dateidatentypen und für verschiedene Dokumente verwalten Informationsressourcen mit Abrufbedeutung wie HTML, DOC, RTF, TXT usw. bieten auch leistungsstarke Volltextabruffunktionen. (2) Es nutzt den Mechanismus von Unterfeldern, Mehrwertfeldern und Feldern variabler Länge und ermöglicht die Erstellung vieler verschiedener Arten von unstrukturierten oder beliebigen Formatfeldern, wodurch die sehr strenge Tabellenstruktur relationaler Felder durchbrochen wird Datenbanken, die die Speicherung und Verwaltung unstrukturierter Daten ermöglichen. (3) iBase definiert sowohl unstrukturierte als auch strukturierte Daten als Ressourcen, sodass das Grundelement einer unstrukturierten Datenbank die Ressource selbst ist und die Ressourcen in der Datenbank sowohl strukturierte als auch unstrukturierte Informationen enthalten können. Daher können unstrukturierte Datenbanken eine Vielzahl unstrukturierter Daten speichern und verwalten und so den Wandel von der Datenverwaltung des Datenbanksystems zur Inhaltsverwaltung realisieren. (4) iBase übernimmt den objektorientierten Eckpfeiler zur engen Integration von Unternehmensgeschäftsdaten und Geschäftslogik und eignet sich besonders zum Ausdruck komplexer Datenobjekte und Multimediaobjekte. (5) iBase ist eine Datenbank, die entwickelt wurde, um den Anforderungen der Entwicklung des Internets gerecht zu werden. Basierend auf der Idee, dass das Web eine riesige Datenbank eines Weitverkehrsnetzwerks ist, bietet es ein Online-Ressourcenverwaltungssystem iBase Web, das den Netzwerkserver (WebServer) und die Datenbank kombiniert. Der Server (Datenbankserver) ist direkt in ein Ganzes integriert, wodurch das Datenbanksystem und die Datenbanktechnologie zu einem wichtigen und integralen Bestandteil des Webs werden und die Einschränkungen der Datenbank nur durchbrochen werden Als Backend-Rolle des Web-Systems zu fungieren, die organische und nahtlose Kombination von Datenbank und Web zu realisieren und so Informationsmanagement und sogar E-Commerce-Anwendungen im Internet/Intranet bereitzustellen, haben ein breiteres Feld eröffnet. (6) iBase ist vollständig kompatibel mit verschiedenen großen, mittleren und kleinen Datenbanken und bietet Import- und Linkunterstützung für herkömmliche relationale Datenbanken wie Oracle, Sybase, SQLServer, DB2, Informix usw. Durch die obige Analyse können wir vorhersagen, dass mit der rasanten Entwicklung der Netzwerktechnologie und der Netzwerkanwendungstechnologie unstrukturierte Datenbanken, die vollständig auf Internetanwendungen basieren, zum Nachfolger von hierarchischen Datenbanken, Netzwerkdatenbanken und relationalen Datenbanken werden und heiße Technologie. Beim Entwurf eines Informationssystems wird es auf jeden Fall eine Datenspeicherung geben. Im Allgemeinen verwenden wir das System. Die Informationen werden in einem gespeichert angegebene relationale Datenbank. Wir klassifizieren die Daten nach Unternehmen, entwerfen entsprechende Tabellen und speichern dann die entsprechenden Informationen in den entsprechenden Tabellen. Wenn wir beispielsweise ein Geschäftssystem aufbauen und grundlegende Mitarbeiterinformationen speichern müssen: Jobnummer, Name, Geschlecht, Geburtsdatum usw., erstellen wir eine entsprechende Personaltabelle. Aber nicht allen Informationen im System können Felder in einer Tabelle zugeordnet werden. Genau wie im Beispiel oben. Diese Art von Daten lässt sich am besten verarbeiten, indem einfach eine entsprechende Tabelle erstellt wird. Wie Bilder, Töne, Videos usw. Normalerweise können wir den Inhalt dieser Art von Informationen nicht direkt kennen und die Datenbank kann sie nur in einem BLOB-Feld speichern, was für den zukünftigen Abruf sehr mühsam ist. Der allgemeine Ansatz besteht darin, eine Tabelle mit drei Feldern zu erstellen (Nummer, Inhaltsbeschreibung varchar(1024), Inhaltsblob). Zitieren nach Nummer, Suche nach Inhaltsbeschreibung. Es gibt viele Tools zur Verarbeitung unstrukturierter Daten, und der gängige Content Manager auf dem Markt ist eines davon. Diese Art von Daten unterscheidet sich von den beiden oben genannten Kategorien. Es handelt sich um strukturierte Daten, aber die Struktur ändert sich stark. Da wir die Details der Daten verstehen müssen, können wir die Daten nicht einfach in einer Datei organisieren und als unstrukturierte Daten verarbeiten. Da sich die Struktur stark ändert, können wir nicht einfach eine entsprechende Tabelle erstellen. In diesem Artikel werden hauptsächlich zwei häufig verwendete Methoden zur halbstrukturierten Datenspeicherung erläutert. 先举一个半结构化的数据的例子,比如存储员工的简历。不像员工基本信息那样一致每个员工的简历大不相同。有的员工的简历很简单,比如只包括教育情况;有的员工的简历却很复杂,比如包括工作情况、婚姻情况、出入境情况、户口迁移情况、党籍情况、技术技能等等。还有可能有一些我们没有预料的信息。通常我们要完整的保存这些信息并不是很容易的,因为我们不会希望系统中的表的结构在系统的运行期间进行变更。 这种方法通常是对现有的简历中的信息进行粗略的统计整理,总结出简历中信息所有的类别同时考虑系统真正关心的信息。对每一类别建立一个子表,比如上例中我们可以建立教育情况子表、工作情况子表、党籍情况子表等等,并在主表中加入一个备注字段,将其它系统不关心的信息和已开始没有考虑到的信息保存在备注中。 优点:查询统计比较方便。 缺点:不能适应数据的扩展,不能对扩展的信息进行检索,对项目设计阶段没有考虑到的同时又是系统关心的信息的存储不能很好的处理。 XML可能是最适合存储半结构化的数据了。将不同类别的信息保存在XML的不同的节点中就可以了。 优点:能够灵活的进行扩展,信息进行扩展式只要更改对应的DTD或者XSD就可以了。 缺点:查询效率比较低,要借助XPATH来完成查询统计,随着数据库对XML的支持的提升性能问题有望能够很好的解决。 <br/> 单链表<br/><br/> 1、链接存储方法<br/> 链接方式存储的线性表简称为链表(Linked List)。<br/> 链表的具体存储表示为:<br/> ① 用一组任意的存储单元来存放线性表的结点(这组存储单元既可以是连续的,也可以是不连续的)<br/> ② 链表中结点的逻辑次序和物理次序不一定相同。为了能正确表示结点间的逻辑关系,在存储每个结点值的同时,还必须存储指示其后继结点的地址(或位置)信息(称为指针(pointer)或链(link))<br/> 注意:<br/> 链式存储是最常用的存储方式之一,它不仅可用来表示线性表,而且可用来表示各种非线性的数据结构。<br/> <br/> 2、链表的结点结构<br/> ┌──┬──┐<br/> │data│next│<br/> └──┴──┘ <br/> data域--存放结点值的数据域<br/> next域--存放结点的直接后继的地址(位置)的指针域(链域)<br/>注意:<br/> ①链表通过每个结点的链域将线性表的n个结点按其逻辑顺序链接在一起的。<br/> ②每个结点只有一个链域的链表称为单链表(Single Linked List)。<br/> 【例】线性表(bat,cat,eat,fat,hat,jat,lat,mat)的单链表示如示意图<br/><br/> 单链表的反转是常见的面试题目。本文总结了2种方法。 单链表node的数据结构定义如下: 把当前链表的下一个节点pCur插入到头结点dummy的下一个节点中,就地反转。 dummy->1->2->3->4->5的就地反转过程: pCur是需要反转的节点。 prev连接下一次需要反转的节点 反转节点pCur 纠正头结点dummy的指向 pCur指向下一次要反转的节点 伪代码 1个头结点,2个指针,4行代码 注意初始状态和结束状态,体会中间的图解过程。 新建一个头结点,遍历原链表,把每个节点用头结点插入到新建链表中。最后,新建的链表就是反转后的链表。 pCur是要插入到新链表的节点。 pNex是临时保存的pCur的next。 pNex保存下一次要插入的节点 把pCur插入到dummy中 纠正头结点dummy的指向 pCur指向下一次要插入的节点 伪代码 <br/> MySQL官方对索引的定义:索引是帮助MySQL高效获取数据的数据结构。索引是在存储引擎中实现的,所以每种存储引擎中的索引都不一样。如MYISAM和InnoDB存储引擎只支持BTree索引;MEMORY和HEAP储存引擎可以支持HASH和BTREE索引。 这里仅针对常用的InnoDB存储引擎所支持的BTree索引进行介绍: 先创建一个新表,用于演示索引类型 这是最基本的索引,没有任何限制。 索引列的值必须唯一,可以有空值 是一种特殊的唯一索引,必须指定为 PRIMARY KEY,如我们常用的AUTO_INCREMENT自增主键 也称为组合索引,就是在多个字段上联合建立一个索引 这里一个组合索引,相当于在有如下三个索引: name; name,age; name,age,phoneNum; 这里或许有这样一个疑惑:为什么age或者age,phoneNum字段上没有索引。这是由于BTree索引因要遵守最左前缀原则,这个原则在后面详细展开。 创建索引简单,但是在哪些列上创建索引则需要好好思考。可以考虑在where字句中出现列或者join字句中出现的列上建索引 联合索引(name,age,phoneNum) ,B+树是按照从左到右的顺序来建立搜索树的。如('张三',18,'18668247652')来检索数据的时候,B+树会优先匹配name来确定搜索方向,name匹配成功再依次匹配age、phoneNum,最后检索到最终的数据。也就是说这种情况下是有三级索引,当name相同,查找age,age也相同时,去比较phoneNum;但是如果拿 (18,'18668247652')来检索时,B+树没有拿到一级索引,根本就无法确定下一步的搜索方向。('张三','18668247652')这种场景也是一样,当name匹配成功后,没有age这个二级索引,只能在name相同的情况下,去遍历所有的phoneNum。 B+树的数据结构决定了在使用索引的时候必须遵守最左前缀原则,在创建联合索引的时候,尽量将经常参与查询的字段放在联合索引的最左边。 一般情况下不建议使用like操作,如果非使用不可的话,需要注意:like '%abd%'不会使用索引,而like ‘aaa%’可以使用索引。这也是前面的最左前缀原则的一个使用场景。 mysql会按照联合索引从左往右进行匹配,直到遇到范围查询,如:>,<,between,like等就停止匹配,a = 1 and b =2 and c > 3 and d = 4,如果建立(a,b,c,d)顺序的索引,d是不会使用索引的。但如果联合索引是(a,b,d,c)的话,则a b d c都可以使用到索引,只是最终c是一个范围值。 order by排序有两种排序方式:using filesort使用算法在内存中排序以及使用mysql的索引进行排序;我们在部分不情况下希望的是使用索引。 如果ID是单列索引,则order by会使用索引 Wenn ID ein einspaltiger Index und name kein Index ist oder name ebenfalls ein einspaltiger Index ist, wird bei „Ordnung nach“ der Index nicht verwendet. Da eine MySQL-Abfrage nur einen Index aus vielen Indizes auswählt und in dieser Abfrage der ID-Spaltenindex und nicht der Namensspaltenindex verwendet wird. Wenn Sie in diesem Szenario auch den Index verwenden möchten, müssen Sie auf das Prinzip des am weitesten links stehenden Präfixes achten. Erstellen Sie keinen solchen gemeinsamen Index (Name, ID). Abschließend ist zu beachten, dass MySQL eine Grenze für die Größe sortierter Datensätze hat: max_length_for_sort_data ist standardmäßig auf 1024 eingestellt, was bedeutet, dass die zu sortierende Datenmenge größer als 1024 ist , order by verwendet nicht den Index, sondern die Verwendung von filesort. <br/> <br/> Derzeit gibt es mehrere Arten verteilter großer Websites: 1. Große Portale wie NetEase, Sina usw.; 2. SNS-Websites wie Xiaonei, Kaixin.com usw.; 3. E-Commerce-Websites: Zum Beispiel Alibaba, JD.com, Gome Online, Autohome usw. Kundenanforderungen: Erstellen Sie einen E-Commerce mit allen Kategorien Auf der Website (B2C) können Benutzer Waren online kaufen, online bezahlen oder per Nachnahme bezahlen. Benutzer können beim Kauf online mit dem Kundendienst kommunizieren Wir hoffen, die Geschäftsentwicklung in 3 bis 5 Jahren unterstützen zu können. Es wird erwartet, dass die Zahl der Benutzer in 3 bis 5 Jahren 10 Millionen erreichen wird Jahre; Veranstalten Sie regelmäßig Double 11, Double 12, 8. März Männertag und andere Aktivitäten; Weitere Veranstaltungen finden Sie auf den Websites wie JD.com oder Gome Online. Kunden sind Kunden. Sie sagen Ihnen nicht, was sie wollen, sie sagen Ihnen nur, was sie wollen. Oft müssen wir die Bedürfnisse der Kunden anleiten und erforschen. Glücklicherweise gibt es eine übersichtliche Referenz-Website. Daher besteht der nächste Schritt darin, viele Analysen durchzuführen, die Branche zu kombinieren und auf Websites zu verweisen, um Kunden Lösungen anzubieten. Das Obige ist ein einfaches Beispiel dafür Die Nachfrage nach E-Commerce-Websites soll erklären, dass (1) die Anforderungen umfassend sein müssen und sich auf nichtfunktionale Anforderungen für große verteilte Systeme konzentrieren müssen Jeder hat eine Grundlage für den nächsten Schritt der Analyse und des Designs. 3 Primäre Website-Architektur (1) Verwenden Sie Cluster für redundante Anwendungsserver, um eine hohe Verfügbarkeit zu erreichen (Lastausgleichsgeräte können zusammen mit der Anwendung bereitgestellt werden) 4 Schätzung der Systemkapazität Schätzschritte: Spitzenschätzung: 2–3-fache des normalen Betrags Berechnen Sie die Systemkapazität basierend auf der Parallelität (Parallelität, Anzahl der Transaktionen) und der Speicherkapazität 🎜> 5 Analyse der Website-Architektur (2) Kernsystem und Nicht-Kernsystem werden in Kombination bereitgestellt Der Cache wird entsprechend dem Standort gespeichert Das Cache-Verhältnis beträgt im Allgemeinen 1:4, Sie können die Verwendung von Cache in Betracht ziehen. (Theoretisch reicht 1:2). Die folgenden Cache-Ablaufstrategien können je nach Geschäftsmerkmalen verwendet werden: (1) Automatischer Cache-Ablauf; (2) Ablauf des Cache-Triggers; ( 3) Im Allgemeinen mithilfe der Cache-Middleware implementiert. Es wird empfohlen, Redis zu verwenden, damit es über eine Persistenzfunktion verfügt, sodass nach dem Ausfall der verteilten Sitzung Sitzungsinformationen aus dem persistenten Speicher geladen werden können ; (4) Speichern Sie die Sitzung. Sie können die Sitzungsaufbewahrungszeit festlegen, z. B. 15 Minuten. Nach Ablauf dieser Zeit wird das Zeitlimit automatisch überschritten. Große Websites müssen riesige Datenmengen speichern, um eine massive Datenspeicherung zu erreichen, (1) Nach der Geschäftsaufteilung: Jedes Subsystem erfordert eine separate Bibliothek (4) Auf der Grundlage der Datenbank- und Tabellenaufteilung , Lese- und Schreibtrennung wird durchgeführt; 6.7 Nachrichtenwarteschlange . Es handelt sich um die Standardkonfiguration verteilter Systeme. In diesem Fall wird die Nachrichtenwarteschlange hauptsächlich in Einkaufs- und Lieferlinks verwendet. (2) Inventar-Subsystem: Lesen Sie die Nachrichtenwarteschlange Informationen und Bestandsreduzierung abschließen; 目前使用较多的MQ有Active MQ,Rabbit MQ,Zero MQ,MS MQ等,需要根据具体的业务场景进行选择。 除了以上介绍的业务拆分, 此处不详细介绍,大家可以问度娘/Google,有机会的话也可以分享给大家。 <br/> RESTful是"分布式超媒体应用"的架构风格<br/>1.采用URI标识资源;<br/><br/>2.使用“链接”关联相关的资源;<br/><br/>3.使用统一的接口;<br/><br/>4.使用标准的HTTP方法;<br/><br/>5.支持多种资源表示方式;<br/><br/> 6.无状态性; <br/> <br/> windows 最近要熟悉一下网站优化,包括前端优化,后端优化,涉及到的细节Opcode,Xdebuge等,都会浅浅的了解一下。 像类似于,刷刷CSDN博客的人气啦,完全是得心应手啊。 我测试了博客园,使用ab并不能刷访问量,为什么CSDN可以,因为两者统计的方式不同。 1 2 3 4 5 6 PV与来访者的数量成正比,但是PV并不直接决定页面的真实来访者数量。比如一个网站就你一个人进来,通过不断的刷新页面,也可以制造出非常高的PV。这也就是ab可以刷csdn访问的原因了。 UV是指不同的、通过互联网访问、浏览一个网页的自然人。类似于注册用户,保存session的形式 IP就不用说啦。类似于博客园,使用的统计方式就必须是IP啦 ab是Apache的自带的工具,如果是window安装的,找到Apache的bin目录,在系统全局变量中添加Path,然后就可以使用ab了 1 2 3 4 5 6 1 2 3 1 2 3 本文介绍ab测试,并没有恶意使用它。途中的博客地址,也只是测试过程中借用了一下,没有别的恶意。 原创 2015年10月19日 18:24:31 <br/> 安装ab工具 ubuntu安装ab apt-get install apache2-utils centos安装ab yum install httpd-tools ab 测试命令 ab -kc 1000-n 1000 http://localhost/ab.html(是服务器下的页面) <br/> Protokolle in ySQL umfassen : Fehlerprotokoll, Binärprotokoll, allgemeines Abfrageprotokoll, langsames Abfrageprotokoll usw . Hier stellen wir hauptsächlich zwei häufig verwendete Funktionen vor: das allgemeine Abfrageprotokoll und das langsame Abfrageprotokoll. 1) Allgemeines Abfrageprotokoll : Zeichnet die hergestellte Client-Verbindung und ausgeführte Anweisungen auf. 2) Langsames Abfrageprotokoll : Zeichnen Sie alle Abfragen auf, deren Ausführungszeit long_query_time Sekunden überschreitet, oder Abfragen, die keine Indizes verwenden (1) Allgemeines Abfrageprotokoll Wenn Sie die allgemeine Protokollabfrage erlernen, müssen Sie die allgemeinen Befehle in den beiden Datenbanken kennen: 1) Variablen wie „%version%“ anzeigen; Die Das Rendern erfolgt wie folgt: Der obige Befehl zeigt Dinge an, die sich auf die Versionsnummer in der aktuellen Datenbank beziehen. 1) showvariables like '%general%'; Sie können überprüfen, ob die aktuelle allgemeine Protokollabfrage aktiviert ist, wenn der Wert von general_log ist ON bedeutet eingeschaltet, OFF bedeutet ausgeschaltet ( ist standardmäßig ausgeschaltet ). 1) Variablen wie „%log_output%“ anzeigen; Anzeigen des aktuellen Protokollausgabeformats für langsame Abfragen, das als DATEI (gespeichert) gespeichert werden kann in den Daten hostname.log in der Datendatei der Datenbank) oder TABLE (mysql.general_log in der Datenbank gespeichert) Frage: So aktivieren Sie das allgemeine MySQL-Abfrageprotokoll, und wie man das erforderliche festlegt. Was ist mit dem allgemeinen Protokollausgabeformat für die Ausgabe? Allgemeine Protokollabfrage aktivieren: set global general_log=on; Allgemeine Protokollabfrage ausschalten: set globalgeneral_log=off; Stellen Sie die allgemeine Protokollausgabe im Tabellenmodus ein: set globallog_output='TABLE'; Stellen Sie die allgemeine Protokollausgabe im Dateimodus ein: set globallog_output='FILE '; Allgemeine Protokollausgabe auf Tabellen- und Dateimodus setzen: set global log_output='FILE,TABLE'; (Hinweis: Der obige Befehl ist nur derzeit wirksam , wenn MySQLNeustart fehlschlägt, Wenn Sie möchten, dass es dauerhaft wirksam wird, müssen Sie my.cnf konfigurieren) Die Darstellung der Protokollausgabe ist wie folgt : In der mysql.general_log-Tabelle aufzeichnen. Die Daten in sind wie folgt: Das im lokalen .log aufgezeichnete Format ist wie folgt : Die Konfiguration der my.cnf-Datei ist wie folgt: general_log=1 # Ein Wert von 1 bedeutet, die allgemeine Protokollabfrage zu aktivieren, ein Wert von 0 bedeutet, die allgemeine Protokollabfrage zu deaktivieren log_output =FILE,TABLE#Legen Sie das Ausgabeformat des allgemeinen Protokolls auf Dateien und Tabellen fest (2) Langsames Abfrageprotokoll Das langsame Abfrageprotokoll von MySQL wird von MySQL Logging bereitgestellt und zum Aufzeichnen von Anweisungen verwendet, deren Antwortzeit den Schwellenwert in MySQL überschreitet. Es bezieht sich insbesondere auf SQL, dessen Laufzeit den long_query_time-Wert überschreitet , wird im langsamen Abfrageprotokoll aufgezeichnet (das Protokoll kann in eine Datei oder Datenbanktabelle geschrieben werden, wenn die Leistungsanforderungen hoch sind. Wenn ja, wird empfohlen, eine Datei zu schreiben). Standardmäßig aktiviert die MySQL-Datenbank keine langsamen Abfrageprotokolle. Der Standardwert von long_query_time ist 10 (dh 10 Sekunden, normalerweise auf 1 Sekunde festgelegt), dh Anweisungen, die länger als 10 Sekunden ausgeführt werden, sind langsame Abfrageanweisungen. Im Allgemeinen treten langsame Abfragen in großen Tabellen auf (z. B. beträgt die Datenmenge in einer Tabelle Millionen), und die Felder der Abfragebedingungen sind zu diesem Zeitpunkt nicht indiziert Die Abfragebedingungen sind Vollständiger Tabellenscan, long_query_time ist zeitaufwändig und ist eine langsame Abfrageanweisung. Frage: Wie kann überprüft werden, ob das aktuelle Protokoll für langsame Abfragen aktiviert ist? Geben Sie den Befehl in MySQL ein: zeige Variablen wie '%quer%'; Beherrschen Sie hauptsächlich die folgenden Parameter: (1) Der Wert von slow_query_log ist ON, um das langsame Abfrageprotokoll einzuschalten, und OFF bedeutet, das langsame Abfrageprotokoll auszuschalten. (2) Der Wert von slow_query_log_file ist das in der Datei aufgezeichnete Protokoll für langsame Abfragen (Hinweis: Der Standardname lautet hostname.log, unabhängig davon, ob das Protokoll für langsame Abfragen aufgezeichnet wird In die angegebene Datei müssen Sie das Ausgabeprotokollformat der langsamen Abfrage als Datei angeben. Der entsprechende Befehl lautet: Variablen wie „%log_output%“ anzeigen. (3) long_query_time gibt den Schwellenwert für die langsame Abfrage an. Wenn die Zeit zum Ausführen der Anweisung den Schwellenwert überschreitet, handelt es sich um eine langsame Abfrageanweisung. Der Standardwert beträgt 10 Sekunden . (4) log_queries_not_using_indexes Wenn der Wert auf ON gesetzt ist, werden alle Abfragen, die keine Indizes verwenden, protokolliert (Hinweis: Wenn Sie nur log_queries_not_using_indexes auf ON und slow_query_log auf OFF gesetzt ist, wird diese Einstellung zu diesem Zeitpunkt nicht wirksam. Das heißt, die Voraussetzung dafür, dass diese Einstellung wirksam wird, ist, dass der Wert von slow_query_log auf ON gesetzt ist und im Allgemeinen während der Leistungsoptimierung vorübergehend aktiviert wird. Frage: Das Ausgabeprotokollformat der langsamen MySQL-Abfrage auf Datei oder Tabelle oder beides festlegen? Verwenden Sie den Befehl: Variablen wie „%log_output%“ anzeigen; Sie können das Ausgabeformat anhand des Werts von überprüfen log_output. Der obige Wert ist TABLE. Natürlich können wir das Ausgabeformat auch auf Text festlegen oder Text und Datenbanktabellen gleichzeitig aufzeichnen. Der Einstellungsbefehl lautet wie folgt: #Geben Sie das langsame Abfrageprotokoll in die Tabelle aus (d. h. MySQL. slow_log) set globallog_output='TABLE'; #Das langsame Abfrageprotokoll wird nur als Text ausgegeben (dh: die durch slow_query_log_file angegebene Datei) setglobal log_output=' FILE'; #Langsames Abfrageprotokoll wird gleichzeitig in Text und Tabelle ausgegeben setglobal log_output='FILE,TABLE' Über die Daten in der Tabelle des langsamen Abfrageprotokolls und den Daten im Text Formatanalyse: Der Protokolldatensatz der langsamen Abfrage befindet sich in der Tabelle myql.slow_log, das Format ist wie folgt: Der Protokolldatensatz einer langsamen Abfrage lautet: In der Datei hostname.log ist das Format wie folgt: Sie können sehen, dass unabhängig davon, ob es sich um eine Tabelle oder eine Datei handelt, speziell aufgezeichnet wird: welche Anweisung die langsame Abfrage verursacht hat (sql_text), die Abfragezeit (query_time), die Tabellensperrzeit (Lock_time) und die Anzahl der gescannten Zeilen (rows_examined) der langsamen Abfrageanweisung. Frage: Wie kann die Anzahl der aktuellen langsamen Abfrageanweisungen abgefragt werden? Es gibt eine Variable in MySQL, die die Anzahl der aktuellen langsamen Abfrageanweisungen aufzeichnet: Geben Sie den Befehl ein: show global status like '%slow%'; (Hinweis: Wenn bei allen oben genannten Befehlen die Parameter über die MySQL-Shell festgelegt werden und MySQL neu gestartet wird, sind alle eingestellten Parameter ungültig . Wenn Sie möchten, dass es dauerhaft wirksam wird, müssen Sie die Konfigurationsparameter in die Datei my.cnf schreiben. Zusätzliche Wissenspunkte: Wie verwende ich MySQLs eigenes Protokollanalysetool für langsame Abfragen, mysqldumpslow, um Protokolle zu analysieren? perlmysqldumpslow –s c –t 10 slow-query.log Die spezifischen Parametereinstellungen lauten wie folgt: -s gibt an, wie sortiert werden soll. c, t, l und r sind nach der Anzahl der Datensätze, der Zeit, der Abfragezeit und der Anzahl der zurückgegebenen Datensätze sortiert. ac, at, al und ar stellen entsprechende Rückblenden dar oben. Die folgenden Daten geben an, wie viele vorherige Elemente zurückgegeben werden. Auf -g kann ein regulärer Ausdrucksabgleich folgen, bei dem die Groß-/Kleinschreibung nicht beachtet wird. Anzahl:414 Die Anweisung erscheint 414 Mal; Zeit=3,51 s (1454) Die maximale Ausführungszeit beträgt 3,51 Sekunden und die kumulierte Gesamtwartezeit beträgt 1454 Sekunden die Sperre ist 0s; Rows=2194.9 (9097604) Die maximale Anzahl der an den Client gesendeten Zeilen beträgt 2194,9 und die kumulierte Anzahl der an den Client gesendeten Funktionen beträgt 90976404 http:/ /blog.csdn.net/a600423444/article/details/6854289 ( mysqldumpslow-Skript ist in Perl-Sprache geschrieben, die spezifische Verwendung von mysqldumpslow wird später besprochen) Frage: tatsächlich im Lernprozess Wie kann man wissen, dass die eingestellte langsame Abfrage effektiv ist? Es ist sehr einfach, eine langsame Abfrageanweisung zu generieren. Wenn beispielsweise der Wert unserer langsamen Abfrage log_query_time auf 1 gesetzt ist, können wir die folgende Anweisung ausführen: selectsleep (1); Diese Anweisung ist die langsame Abfrageanweisung. Anschließend können Sie überprüfen, ob diese Anweisung in der entsprechenden Protokollausgabedatei oder -tabelle vorhanden ist. 36. <br/> ThinkPHP简称TP,TP借鉴了Java思想,基于PHP5,充分利用了PHP5的特性,部署简单只需要一个入口文件,一起搞定,简单高效。中文文档齐全,入门超级简单。自带模板引擎,具有独特的数据验证和自动填充功能,框架更新速度比较速度。 优点:这个框架易使用 易学 安全 对bae sae支持很好提供的工具也很强大 可以支持比较大的项目开发 易扩展 全中文文档 总的来说这款框架适合非常适合国人使用 性能 上比CI还要强一些 缺点:配置对有些人来说有些复杂(其实是因为没有认真的读过其框架源码)文档有些滞后 有些组件未有文档说明。 CodeIgniter简称CI 简单配置,上手很快,全部的配置使用PHP脚本来配置,没有使用很多太复杂的设计模式,(MVC设计模式)执行性能和代码可读性上都不错。执行效率较高,具有基本的MVC功能,快速简洁,代码量少,框架容易上手,自带了很多简单好用的library。 框架适合中小型项目,大型项目也可以,只是扩展能力差。优点:这个框架的入门槛很底 极易学 极易用 框架很小 静态化非常容易 框架易扩展 文档比较详尽 缺点:在极易用的极小下隐藏的缺点即是不安全 功能不是太全 缺少非常多的东西 比如你想使用MongoDB你就得自己实现接口… 对数据的操作亦不是太安全 比如对update和delete操作等不够安全 暂不支持sae bae等(毕竟是欧洲)对大型项目的支持不行 小型项目会非常好。 CI和TP的对比(http://www.jcodecraeer.com/a/phpjiaocheng/2012/0711/309.html) Laravel的设计思想是很先进的,非常适合应用各种开发模式TDD, DDD和BDD(http://blog.csdn.net/bennes/article/details/47973129 TDD DDD BDD解释 ),作为一个框架,它为你准备好了一切,composer是个php的未来,没有composer,PHP肯定要走向没落。laravel最大的特点和处优秀之就是集合了php比较新的特性,以及各种各样的设计模式,Ioc容器,依赖注入等。因此laravel是一个适合学习的框架,他和其他的框架思想有着极大的不同,这也要求你非常熟练php,基础扎实。 优点:http://www.codeceo.com/article/why-laravel-best-php-framework.html Yii是一个基于组件的高性能的PHP的框架,用于开发大规模Web应用。Yii采用严格的OOP编写,并有着完善的库引用以及全面的教程。从MVC,DAO/ActiveRecord,widgets,caching,等级式RBAC,Web服务,到主体化,I18N和L10N,Yii提供了今日Web 2.0应用开发所需要的几乎一切功能。而且这个框架的价格也并不太高。事实上,Yii是最有效率的PHP框架之一。 <br/> 原创 2016年11月09日 17:58:50 <br/> 在PHP中,出现同名函数或是同名类是不被允许的。为防止编程人员在项目中定义的类名或函数名出现重复冲突,在PHP5.3中引入了命名空间这一概念。 1.命名空间,即将代码划分成不同空间,不同空间的类名相互独立,互不冲突。一个php文件中可以存在多个命名空间,第一个命名空间前不能有任何代码。内容空间声明后的代码便属于这个命名空间,例如: 2.调用不同空间内类或方法需写明命名空间。例如: 3.在命名空间内引入其他文件不会属于本命名空间,而属于公共空间或是文件中本身定义的命名空间。例: 首先定义一个1.php和2.php文件: 4.下面我们来看use的使用方法:(use以后引用可简写) 相关推荐: Das obige ist der detaillierte Inhalt vonZusammenfassung des PHP-Interviews. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!Query-4 explain select * from people where id in (select id from people where zipcode = 100000 union select id from people where zipcode = 200000 );

SELECT ... FROM t1 WHERE t1.a IN (SELECT b FROM t2);
SELECT ... FROM t1 WHERE EXISTS (SELECT 1 FROM t2 WHERE t2.b = t1.a);
Query-5 explain select * from people o where exists (
select id from people where zipcode = 100000 and id = o.id union select id from people where zipcode = 200000 and id = o.id);

Query-6 explain select * from people where id = (select id from people where zipcode = 100000);

table
Query-7 explain select * from (select * from (select * from people a) b ) c;

<strong><em>N</em></strong>>N就是id值,指该id值对应的那一步操作的结果。type
Query-8 explain select * from people where id=1;

Query-9 explain select * from people where zipcode = 100000;

Query-10 explain select * from people where id >2;

Query-11 explain select * from (select * from people where id = 1 )b;

Query-12 explain select * from people a,people_car b where a.id = b.people_id;

CREATE TABLE people2(
id bigint auto_increment primary key,
zipcode char(32) not null default '',
address varchar(128) not null default '',
lastname char(64) not null default '',
firstname char(64) not null default '',
birthdate char(10) not null default '' )
ENGINE = MyISAM; CREATE TABLE people_car2(
people_id bigint,
plate_number varchar(16) not null default '',
engine_number varchar(16) not null default '',
lasttime timestamp
)ENGINE = MyISAM;
Query-13 explain select * from people2 a,people_car2 b where a.id = b.people_id;

Query-14 explain select * from people2 a,people_car2 b where a.id = b.people_id and b.people_id = 1;

reate index people_id on people2(id); create index people_id on people_car2(people_id);
Query-15 explain select * from people2 a,people_car2 b where a.id = b.people_id and a.id > 2;

Query-16 explain select * from people2 a,people_car2 b where a.id = b.people_id and a.id = 2;

Query-17 explain select * from people2 a,people_car2 b where a.id = b.people_id;

Query-18 explain select * from people2 where id = 1;

Query-19 mysql> explain select * from people2 where id = 2 or id is null;

Query-20 explain select * from people2 where id = 2 or id is not null;

value IN (SELECT primary_key FROM single_table WHERE some_expr)
value IN (SELECT key_column FROM single_table WHERE some_expr)
Query-21 explain select * from people where id = 1 or id = 2;
 <br/>
<br/>explain select * from people where id >1;

explain select * from people where id in (1,2);

Query-22 explain select * from people order by id;

possible_keys
ref
rows
Extra
MySQL verfügt über zwei Möglichkeiten, geordnete Ergebnisse zu generieren, durch Sortiervorgänge oder die Verwendung von Indizes bei Verwendung Wenn filesort in Extra angezeigt wird, bedeutet dies, dass MySQL letzteres verwendet. Beachten Sie jedoch, dass dies nicht bedeutet, dass die Sortierung nach Möglichkeit im Speicher erfolgt, obwohl sie filesort genannt wird. In den meisten Fällen ist die Indexsortierung schneller, daher sollten Sie zu diesem Zeitpunkt im Allgemeinen auch über die Optimierung von Abfragen nachdenken.
Die Verwendung von temporär
2. Autorisierungsmethode 2.0

1. Anwendungsszenarien

2. Definition von Substantiven
3. Die Idee von OAuth
4. Betriebsprozess

五、客户端的授权模式
六、授权码模式

GET /authorize?response_type=code&client_id=s6BhdRkqt3&state=xyz &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1 Host: server.example.com
HTTP/1.1 302 Found Location: https://client.example.com/cb?code=SplxlOBeZQQYbYS6WxSbIA &state=xyz
POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=authorization_code&code=SplxlOBeZQQYbYS6WxSbIA &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA", "example_parameter":"example_value" }七、简化模式

GET /authorize?response_type=token&client_id=s6BhdRkqt3&state=xyz &redirect_uri=https%3A%2F%2Fclient%2Eexample%2Ecom%2Fcb HTTP/1.1 Host: server.example.com
HTTP/1.1 302 Found Location: http://example.com/cb#access_token=2YotnFZFEjr1zCsicMWpAA &state=xyz&token_type=example&expires_in=3600
八、密码模式

POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=password&username=johndoe&password=A3ddj3w
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "refresh_token":"tGzv3JOkF0XG5Qx2TlKWIA", "example_parameter":"example_value" }九、客户端模式

POST /token HTTP/1.1 Host: server.example.com Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW Content-Type: application/x-www-form-urlencoded grant_type=client_credentials
HTTP/1.1 200 OK Content-Type: application/json;charset=UTF-8 Cache-Control: no-store Pragma: no-cache { "access_token":"2YotnFZFEjr1zCsicMWpAA", "token_type":"example", "expires_in":3600, "example_parameter":"example_value" }十、更新令牌
POST /token HTTP/1.1
Host: server.example.com
Authorization: Basic czZCaGRSa3F0MzpnWDFmQmF0M2JW
Content-Type: application/x-www-form-urlencoded
grant_type=refresh_token&refresh_token=tGzv3JOkF0XG5Qx2TlKWIA3. yii 配置文件
 <br/>
<br/>
 <br/> advance版本的特点是:根目录下预先分配了三个模块,分别是前台、后台、控制台模块。1.backend它主要用于管理后台,网站管理员来管理整个系统。<br/>
<br/> advance版本的特点是:根目录下预先分配了三个模块,分别是前台、后台、控制台模块。1.backend它主要用于管理后台,网站管理员来管理整个系统。<br/> <br/>assets 目录用于存放前端资源包PHP类。 这里不需要了解什么是前端资源包,只要大致知道是用于管理CSS、js等前端资源就可以了。config 用于存放本应用的配置文件,包含主配置文件 main.php 和全局参数配置文件 params.php 。models views controllers 3个目录分别用于存放数据模型类、视图文件、控制器类。这个是我们编码的核心,也是我们工作最多的目录。widgets 目录用于存放一些常用的小挂件的类文件。tests 目录用于存放测试类。web 目录从名字可以看出,这是一个对于Web服务器可以访问的目录。 除了这一目录,其他所有的目录不应对Web用户暴露出来。这是安全的需要。runtime 这个目录是要求权限为 chmod 777 ,即允许Web服务器具有完全的权限, 因为可能会涉及到写入临时文件等。 但是一个目录并未对Web用户可见。也就是说,权限给了,但是并不是Web用户可以访问到的。<br/> <br/>2.frontend
<br/>assets 目录用于存放前端资源包PHP类。 这里不需要了解什么是前端资源包,只要大致知道是用于管理CSS、js等前端资源就可以了。config 用于存放本应用的配置文件,包含主配置文件 main.php 和全局参数配置文件 params.php 。models views controllers 3个目录分别用于存放数据模型类、视图文件、控制器类。这个是我们编码的核心,也是我们工作最多的目录。widgets 目录用于存放一些常用的小挂件的类文件。tests 目录用于存放测试类。web 目录从名字可以看出,这是一个对于Web服务器可以访问的目录。 除了这一目录,其他所有的目录不应对Web用户暴露出来。这是安全的需要。runtime 这个目录是要求权限为 chmod 777 ,即允许Web服务器具有完全的权限, 因为可能会涉及到写入临时文件等。 但是一个目录并未对Web用户可见。也就是说,权限给了,但是并不是Web用户可以访问到的。<br/> <br/>2.frontend <br/>我们的目标最终用户提供的主要接口的前端应用。其实,前台和后台是一样的,只是我们逻辑上的一个划分.。<br/> 好了,现在问题来了。对于 frontend backend console 等独立的应用而言, 他们的内容放在各自的目录下面,他们的运作必然用到Yii框架等 vendor 中的程序。 他们是如何关联起来的?这个秘密,或者说整个Yii应用的目录结构的秘密, 就包含在一个传说中的称为入口文件的地方。<br/>
<br/>我们的目标最终用户提供的主要接口的前端应用。其实,前台和后台是一样的,只是我们逻辑上的一个划分.。<br/> 好了,现在问题来了。对于 frontend backend console 等独立的应用而言, 他们的内容放在各自的目录下面,他们的运作必然用到Yii框架等 vendor 中的程序。 他们是如何关联起来的?这个秘密,或者说整个Yii应用的目录结构的秘密, 就包含在一个传说中的称为入口文件的地方。<br/><?phpdefined('YII_DEBUG') or define('YII_DEBUG', true);
defined('YII_ENV') or define('YII_ENV', 'dev');
require(__DIR__ . '/../../vendor/autoload.php');
require(__DIR__ . '/../../vendor/yiisoft/yii2/Yii.php');
require(__DIR__ . '/../../common/config/bootstrap.php');
require(__DIR__ . '/../config/bootstrap.php');
$config = yii\helpers\ArrayHelper::merge(
require(__DIR__ . '/../../common/config/main.php'),
require(__DIR__ . '/../../common/config/main-local.php'),
require(__DIR__ . '/../config/main.php'),
require(__DIR__ . '/../config/main-local.php'));
$application = new yii\web\Application($config);$application->run();
 <br/><br/><br/>Das Folgende ist der globale öffentliche Ordner 4.common
<br/><br/><br/>Das Folgende ist der globale öffentliche Ordner 4.common <br/>
<br/> <br/> Aus dem Verzeichnisstrukturdiagramm oben können Sie erkennen, dass sich im Umgebungsverzeichnis drei Dinge befinden:
<br/> Aus dem Verzeichnisstrukturdiagramm oben können Sie erkennen, dass sich im Umgebungsverzeichnis drei Dinge befinden:  vendor 。 这个目录从字面的意思看,就是各种第三方的程序。 这是Composer安装的其他程序的存放目录,包含Yii框架本身,也放在这个目录下面。 如果你向composer.json 目录增加了新的需要安装的程序,那么下次调用Composer的时候, 就会把新安装的目录也安装在这个 vendor 下面。<br/><br/>下面也是一些不太常用的文件夹7.vagrant
vendor 。 这个目录从字面的意思看,就是各种第三方的程序。 这是Composer安装的其他程序的存放目录,包含Yii框架本身,也放在这个目录下面。 如果你向composer.json 目录增加了新的需要安装的程序,那么下次调用Composer的时候, 就会把新安装的目录也安装在这个 vendor 下面。<br/><br/>下面也是一些不太常用的文件夹7.vagrant  8.tests
8.tests  <br/>
<br/>入口文件篇:
 <br/>
<br/> return "$baseUrl/{$route}{$anchor}"; } else { $url = "$baseUrl?{$this->routeParam}=" . urlencode($route); if (!empty($params) && ($query = http_build_query($params)) !== '') { $url .= '&' . $query; } 将urlencode去掉就可以了 3、入口文件内容 入口文件流程如下: <br/>
<br/>public $defaultRoute = 'student/show';
修改前台或者后台控制器: eg :打开 frontend/config/main.php 中
'params' => $params, 'defaultRoute' => 'login/show',
namespace frontend\controllers;
use Yii;
use yii\web\Controller;
vendor/yiisoft/yii2/web/Controller.php
(该控制器继承的是\yii\base\Controller) \web\Controller.php中干了些什么
1、默认开启了 授权防止csrf攻击
2、响应Ajax请求的视图渲染
3、将参数绑定到动作(就是看是不是属于框架自己定义的方法,如果没有定义就走run方法解析)
4、检测方法(beforeAction)beforeAction() 方法会触发一个 beforeAction 事件,在事件中你可以追加事件处理操作;
5、重定向路径 以及一些http Response(响应) 的设置
<br/>
use yii\db\Query; //使用query查询
use yii\data\Pagination;//分页
use yii\data\ActiveDataProvider;//活动记录
use frontend\models\ZsDynasty;//自定义数据模型
class StudentController extends Controller {
$request = YII::$app->request;//获取请求组件
$request->get('id');//获取get方法数据
$request->post('id');//获取post方法数据
$request->isGet;//判断是不是get请求
$request->isPost;//判断是不是post请求
$request->userIp;//获取用户IP地址
$res = YII::$app->response;//获取响应组件
$res->statusCode = '404';//设置状态码
$this->redirect('http://baodu.com');//页面跳转
$res->sendFile('./b.jpg');//文件下载
$session = YII::$app->session;
$session->isActive;//判断session是否开启
$session->open();//开启session
//设置session值
$session->set('user','zhangsan');//第一个参数为键,第二个为值
$session['user']='zhangsan';
//获取session值
$session->get('user');
$session['user'];
//删除session值
$session-remove('user');
unset($session['user']);
$cookies = Yii::$app->response->cookies;//获取cookie对象
$cookie_data = array('name'=>'user','value'=>'zhangsan')//新建cookie数据
$cookies->add(new Cookie($cookie_data));
$cookies->remove('id');//删除cookie
$cookies->getValue('user');//获取cookie<?php
namespace frontend\models;
class ListtModel extends \yii\db\ActiveRecord {
public static function tableName()
{
return 'listt';
}
public function one(){
return $this->find()->asArray()->one();
}
}控制器引用
<?php namespace frontend\controllers; use Yii; use yii\web\controller; use frontend\models\ListtModel; class ListtController extends Controller{ public function actionAdd(){ $model=new ListtModel; $list=$model->one(); $data=$model->find()->asArray()->where("id=1")->all(); print_r($data); } } ?> <br/>
<br/> <br/> 而views下面会有一个默认的layouts文件夹,里面存放的就是布局文件,什么意思呢?:在控制器中,会有一个layout字段,如果制定他为一个layout视图文件,比如common.php,那么视图就会以他为主视图,其他的view视图片段都会作为显示片段嵌入到layout文件common.php中.而如果不明确重载layout字段,那么默认layout的值是main,意味着layouts的main.php是视图模板。控制器:
<br/> 而views下面会有一个默认的layouts文件夹,里面存放的就是布局文件,什么意思呢?:在控制器中,会有一个layout字段,如果制定他为一个layout视图文件,比如common.php,那么视图就会以他为主视图,其他的view视图片段都会作为显示片段嵌入到layout文件common.php中.而如果不明确重载layout字段,那么默认layout的值是main,意味着layouts的main.php是视图模板。控制器: <br/>common.php:
<br/>common.php: <br/><br/>layouts
<br/><br/>layouts 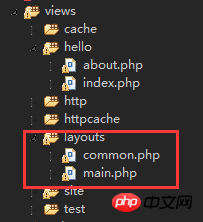 <br/>这样就达到了视图复用的作用。<br/> 控制器中写入$layout <br/>
<br/>这样就达到了视图复用的作用。<br/> 控制器中写入$layout <br/>//$layout="main" 系统默认文件
//$layout=null 会找父类中默认定义的main public $layout="common";
public function actionIndex(){
return $this->render('index');
}
将以下内容插入 common中 <?=$content;?>
它就是index文件中的内容
'db' => [
'class' => 'yii\db\Connection',
'dsn' => 'mysql:host=localhost;dbname=hyii2', //数据库hyii2
'username' => 'root',
'password' => 'pwhyii2',
'charset' => 'utf8',
],
'db2' => [
'class' => 'yii\db\Connection',
'dsn' => 'mysql:host=localhost;dbname=hyii', //数据库hyii
'username' => 'root',
'password' => 'pwhyii',
'charset' => 'utf8',
],


$id=Yii::$app->db->getLastInsertID();
Yii::$app->db->createCommand()->insert('user', [
'name' => 'test',
'age' => 30,
])->execute();Yii::$app->db->createCommand()->batchInsert('user', ['name', 'age'], [
['test01', 30],
['test02', 20],
['test03', 25],
])->execute();
删除[php] view plain copy
Yii::$app->db->createCommand()->delete('user', 'age = 30')->execute();Yii::$app->db->createCommand()->update('user', ['age' => 40], 'name = test')->execute();
查询[php] view plain copy
//createCommand(执行原生的SQL语句)
$sql= "SELECT u.account,i.* FROM sys_user as u left join user_info as i on u.id=i.user_id";
$rows=Yii::$app->db->createCommand($sql)->query();
查询返回多行:
$command = Yii::$app->db->createCommand('SELECT * FROM post');
$posts = $command->queryAll();
返回单行
$command = Yii::$app->db->createCommand('SELECT * FROM post WHERE id=1');
$post = $command->queryOne();
查询多行单值:
$command = Yii::$app->db->createCommand('SELECT title FROM post');
$titles = $command->queryColumn();
查询标量值/计算值:
$command = Yii::$app->db->createCommand('SELECT COUNT(*) FROM post');
$postCount = $command->queryScalar();
//入库一维数组
public function add($data)
{
$this->setAttributes($data);
$this->isNewRecord = true;
$this->save();
return $this->id;
}
//入库二维数组
public function addAll($data){
$ids=array();
foreach($data as $attributes)
{
$this->isNewRecord = true;
$this->setAttributes($attributes);
$this->save()&& array_push($ids,$this->id) && $this->id=0;
}
return $ids;
}
public function rules()
{
return [
[['title','content'],'required'
]];
}
控制器:
$ids=$model->addAll($data);
var_dump($ids);$user = User::find()->where(['name'=>'test'])->one();
$user->delete();
$result = User::deleteAll(['age'=>'30']);
$result = User::deleteByPk(1);
/**
* @param $files 字段
* @param $values 值
* @return int 影响行数
*/ public function del($field,$values){
//
$res = $this->find()->where(['in', "$files", $values])->deleteAll();
$res=$this->deleteAll(['in', "$field", "$values"]);
return $res;
}[php] view plain copy
$user = User::find()->where(['name'=>'test'])->one(); //获取name等于test的模型
$user->age = 40; //修改age属性值
$user->save(); //保存
[php] view plain copy
$result = User::model()->updateAll(['age'=>40],['name'=>'test']);
/** * @param $data 修改数据 * @param $where 修改条件 * @return int 影响行数 */ public function upda($data,$where){ $result = $this->updateAll($data,$where); // return $this->id; return $result; }Customer::find()->one();
此方法返回一条数据;
Customer::find()->all();
此方法返回所有数据;
Customer::find()->count();
此方法返回记录的数量;
Customer::find()->average();
此方法返回指定列的平均值;
Customer::find()->min();
此方法返回指定列的最小值 ;
Customer::find()->max();
此方法返回指定列的最大值 ;
Customer::find()->scalar();
此方法返回值的第一行第一列的查询结果;
Customer::find()->column();
此方法返回查询结果中的第一列的值;
Customer::find()->exists();
此方法返回一个值指示是否包含查询结果的数据行;
Customer::find()->batch(10);
每次取10条数据
Customer::find()->each(10);
每次取10条数据,迭代查询
//根据sql语句查询:查询name=test的客户 Customer::model()->findAllBySql("select * from customer where name = test");
//根据主键查询:查询主键值为1的数据 Customer::model()->findByPk(1);
//根据条件查询(该方法是根据条件查询一个集合,可以是多个条件,把条件放到数组里面)
Customer::model()->findAllByAttributes(['username'=>'admin']);
//子查询 $subQuery = (new Query())->select('COUNT(*)')->from('customer');
// SELECT `id`, (SELECT COUNT(*) FROM `customer`) AS `count` FROM `customer` $query = (new Query())->select(['id', 'count' => $subQuery])->from('customer');
//关联查询:查询客户表(customer)关联订单表(orders),条件是status=1,客户id为1,从查询结果的第5条开始,查询10条数据 $data = (new Query())
->select('*')
->from('customer')
->join('LEFT JOIN','orders','customer.id = orders.customer_id')
->where(['status'=>'1','customer.id'=>'1'])
->offset(5) ->limit(10) ->all()[php] view plain copy
/**
*客户表Model:CustomerModel
*订单表Model:OrdersModel
*国家表Model:CountrysModel
*首先要建立表与表之间的关系
*在CustomerModel中添加与订单的关系
*/
Class CustomerModel extends \yii\db\ActiveRecord
{
...
//客户和订单是一对多的关系所以用hasMany
//此处OrdersModel在CustomerModel顶部别忘了加对应的命名空间
//id对应的是OrdersModel的id字段,order_id对应CustomerModel的order_id字段
public function getOrders()
{
return $this->hasMany(OrdersModel::className(), ['id'=>'order_id']);
}
//客户和国家是一对一的关系所以用hasOne
public function getCountry()
{
return $this->hasOne(CountrysModel::className(), ['id'=>'Country_id']);
}
....
}
// 查询客户与他们的订单和国家
CustomerModel::find()->with('orders', 'country')->all();
// 查询客户与他们的订单和订单的发货地址(注:orders 与 address都是关联关系)
CustomerModel::find()->with('orders.address')->all();
// 查询客户与他们的国家和状态为1的订单
CustomerModel::find()->with([
'orders' => function ($query) {
$query->andWhere('status = 1');
},
'country',
])->all();yii2 rbac 详解
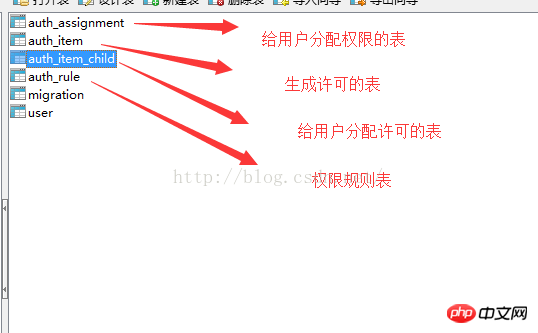 <br/><br/> 4. Verwenden Sie yii rbac für Vorgänge (jede von Ihnen ausgeführte Operation verarbeitet Daten in den 4 Tabellen von rbac, um zu überprüfen, ob relevante Berechtigungen eingerichtet wurden. Sie können diese Tabellen direkt zum Anzeigen eingeben) <br/>Registrieren Sie a Berechtigung: (Daten werden in der oben beschriebenen Berechtigungstabelle generiert) öffentliche Funktion createPermission($item) { $auth = Yii::$app->authManager;<br/> $createPost = $auth-> createPermission($item ); $createPost->description = 'Erstellt' . $auth->add($createPost); ><br/>public function createRole($item) { $auth = Yii::$app->authManager; $role = $auth->createRole($role- >description = ' Erstellt'. $item . 'Role'; $auth->add($role); app->authManager; $parent = $auth->createRole($items['name']); $child = $auth->createPermission($items['description' ]); $auth->addChild($parent, $child); }<br/>Eine Regel zu einer Berechtigung hinzufügen: <br/><br/>Die Regel besteht darin, Rollen und Berechtigungen hinzuzufügen. Zusätzliche Einschränkungen. Eine Regel besagt, dass eine Klasse, die von <br/><br/> erweitert wird, die Methode <br/> implementieren muss. In der Hierarchie kann der
<br/><br/> 4. Verwenden Sie yii rbac für Vorgänge (jede von Ihnen ausgeführte Operation verarbeitet Daten in den 4 Tabellen von rbac, um zu überprüfen, ob relevante Berechtigungen eingerichtet wurden. Sie können diese Tabellen direkt zum Anzeigen eingeben) <br/>Registrieren Sie a Berechtigung: (Daten werden in der oben beschriebenen Berechtigungstabelle generiert) öffentliche Funktion createPermission($item) { $auth = Yii::$app->authManager;<br/> $createPost = $auth-> createPermission($item ); $createPost->description = 'Erstellt' . $auth->add($createPost); ><br/>public function createRole($item) { $auth = Yii::$app->authManager; $role = $auth->createRole($role- >description = ' Erstellt'. $item . 'Role'; $auth->add($role); app->authManager; $parent = $auth->createRole($items['name']); $child = $auth->createPermission($items['description' ]); $auth->addChild($parent, $child); }<br/>Eine Regel zu einer Berechtigung hinzufügen: <br/><br/>Die Regel besteht darin, Rollen und Berechtigungen hinzuzufügen. Zusätzliche Einschränkungen. Eine Regel besagt, dass eine Klasse, die von <br/><br/> erweitert wird, die Methode <br/> implementieren muss. In der Hierarchie kann der author-Charakter, den wir zuvor erstellt haben, seine eigenen Artikel nicht bearbeiten. Lassen Sie uns das beheben. <br/>Zuerst benötigen wir eine Regel, um zu überprüfen, ob dieser Benutzer der Autor des Artikels ist: <br/>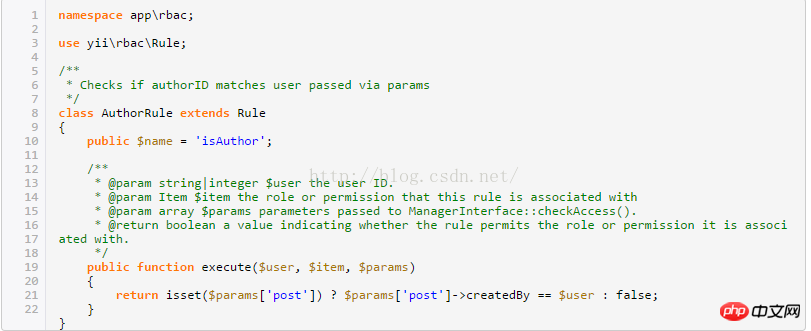 <br/> <br/>Hinweis: Im Excut in der obigen Methode stammt $user von der user_id, nachdem sich der Benutzer angemeldet hat<br/>
<br/> <br/>Hinweis: Im Excut in der obigen Methode stammt $user von der user_id, nachdem sich der Benutzer angemeldet hat<br/>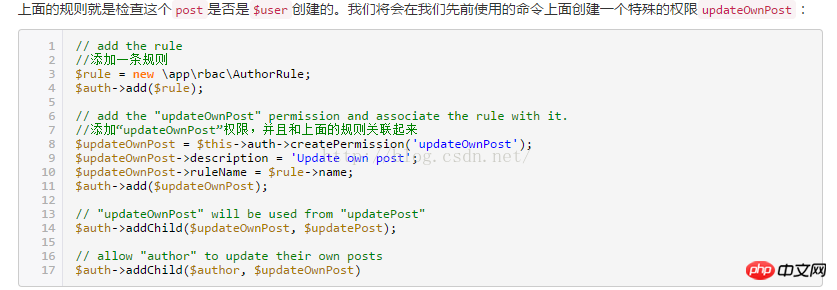 <br/>Bestimmen Sie die Berechtigungen des Benutzers, nachdem sich der Benutzer angemeldet hat
<br/>Bestimmen Sie die Berechtigungen des Benutzers, nachdem sich der Benutzer angemeldet hat <br/><br/>Link zur Referenz auf den Artikel: http://www.360us.net/article/13.html http://www.open-open.com/lib/view/open1424832085843.html<br/>
<br/><br/>Link zur Referenz auf den Artikel: http://www.360us.net/article/13.html http://www.open-open.com/lib/view/open1424832085843.html<br/>4. 在微信里调支付宝
 <br/>
<br/>
$returnUrl = 'http://域名/user/h5_alipay/return_url.php'; //付款成功后的 同步回调地址,可直接设置为会员中心的地址 $notifyUrl = 'http://域名/notify_url.php'; //付款成功后的异回调地址,如果你的回调地址中包含&符号,最好把回调直接放根目录
$orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');

密钥管理->开放平台密钥,填写添加了电脑网站支付的应用的APPID
$notifyUrl = 'http://域名/user/h5_alipay/notify_url.php';
//付款成功后的异步回调地址支付宝以post的方式回调
$returnUrl = 'http://域名/user/pay_chongzhi.php';
//付款成功后,支付宝以 get同步的方式回调给发起支付方
$sj=date("Y-m-d H:i:s");
$userid=returnuserid($_SESSION["SHOPUSER"]);
$ddbh=$bh="h5_ali_".time()."_".$userid;
//订单编号
$uip=$_SERVER["REMOTE_ADDR"];
//ip地址 $money1=$_POST[t1];
//bz备注,ddzt与alipayzt及ifok表示订单状态,
intotable("yjcode_dingdang","bh,ddbh,userid,sj,uip,money1,ddzt,alipayzt,bz,ifok","'".$bh."','".$ddbh."',".$userid.",'".$sj."','".$uip."',".$money1.",'等待买家付款','','支付宝充值',0");
//订单入库
//die(mysql_error());
//数据库错误
//订单名称
$orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');
//注意编码
$body = $orderName=iconv("GB2312//IGNORE","UTF-8",'支付宝充值');
$outTradeNo = $ddbh;
//你自己的商品订单号
$payAmount = $money1;
//付款金额,单位:元
$signType = 'RSA2';
//签名算法类型,支持RSA2和RSA,推荐使用RSA2
$saPrivateKey='这里填2048位的私钥';
//私钥
$aliPay = new AlipayService($appid,$returnUrl,$notifyUrl,$saPrivateKey);
$payConfigs = $aliPay->doPay($payAmount,$outTradeNo,$orderName,$returnUrl,$notifyUrl);
class AlipayService {
protected $appId;
protected $returnUrl;
protected $notifyUrl;
protected $charset;
//私钥值
protected $rsaPrivateKey;
public function __construct($appid, $returnUrl, $notifyUrl,$saPrivateKey) {
$this->appId = $appid;
$this->returnUrl = $returnUrl;
$this->notifyUrl = $notifyUrl;
$this->charset = 'UTF-8';
$this->rsaPrivateKey=$saPrivateKey;
}
/**
* 发起订单
* @param float $totalFee 收款金额 单位元
* @param string $outTradeNo 订单号
* @param string $orderName 订单名称
* @param string $notifyUrl 支付结果通知url 不要有问号
* @param string $timestamp 订单发起时间
* @return array
*/
public function doPay($totalFee, $outTradeNo, $orderName, $returnUrl,$notifyUrl)
{
//请求参数
$requestConfigs = array( 'out_trade_no'=>$outTradeNo, 'product_code'=>'QUICK_WAP_WAY', 'total_amount'=>$totalFee,
//单位 元 'subject'=>$orderName, //订单标题 );
$commonConfigs = array(
//公共参数
'app_id' => $this->appId, 'method' => 'alipay.trade.wap.pay',
//接口名称 'format' => 'JSON',
'return_url' => $returnUrl, 'charset'=>$this->charset, 'sign_type'=>'RSA2',
'timestamp'=>date('Y-m-d H:i:s'), 'version'=>'1.0', 'notify_url' => $notifyUrl,
'biz_content'=>json_encode($requestConfigs), );
$commonConfigs["sign"] = $this->generateSign($commonConfigs, $commonConfigs['sign_type']);
return $commonConfigs;
}
public function generateSign($params, $signType = "RSA") {
return $this->sign($this->getSignContent($params), $signType);
}
protected function sign($data, $signType = "RSA") {
$priKey=$this->rsaPrivateKey;
$res = "-----BEGIN RSA PRIVATE KEY-----\n" .
wordwrap($priKey, 64, "\n", true) .
"\n-----END RSA PRIVATE KEY-----";
($res) or die('您使用的私钥格式错误,请检查RSA私钥配置');
if ("RSA2" == $signType) {
openssl_sign($data, $sign, $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
//OPENSSL_ALGO_SHA256是php5.4.8以上版本才支持
} else {
openssl_sign($data, $sign, $res);
}
$sign = base64_encode($sign);
return $sign;
}
/**
* 校验$value是否非空
* if not set ,return true;
* if is null , return true;
**/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
}
/**
* 转换字符集编码
* @param $data
* @param $targetCharset
* @return string
*/
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
}
}
return $data;
} }
function isWeixin(){
if ( strpos($_SERVER['HTTP_USER_AGENT'],'MicroMessenger') !== false ) {
return true;
}
return false;
}
$queryStr = http_build_query($payConfigs); if(isWeixin()):
//注意下面的ap.js ,文件的存在目录,如果不确定.可以写绝对地址.否则可能微信中没法弹出提示窗口,
?>
<script>
var gotoUrl = 'https://openapi.alipaydev.com/gateway.do?<?=$queryStr?>';
//注意上面及下面的alipaydev.com,用的是沙箱接口,去掉dev表示正式上线
_AP.pay(gotoUrl); </script> <?php
header('Content-type:text/html; Charset=GB2312');
//支付宝公钥,账户中心->密钥管理->开放平台密钥,找到添加了支付功能的应用,根据你的加密类型,查看支付宝公钥
$alipayPublicKey=''; $aliPay = new AlipayService($alipayPublicKey);
//验证签名,如果签名失败,注意编码问题.特别是有中文时,可以换成英文,再测试
$result = $aliPay->rsaCheck($_POST,$_POST['sign_type']);
if($result===true){
//处理你的逻辑,例如获取订单号
$_POST['out_trade_no'],订单金额$_POST['total_amount']等
//程序执行完后必须打印输出“success”(不包含引号)。
如果商户反馈给支付宝的字符不是success这7个字符,支付宝服务器会不断重发通知,直到超过24小时22分钟。
一般情况下,25小时以内完成8次通知(通知的间隔频率一般是:4m,10m,10m,1h,2h,6h,15h);
$out_trade_no = $_POST['out_trade_no'];
//支付宝交易号
$trade_no = $_POST['trade_no'];
//交易状态
$trade_status = $_POST['trade_status'];
switch($trade_status){
case "WAIT_BUYER_PAY";
$nddzt="等待买家付款";
break;
case "TRADE_FINISHED": case "TRADE_SUCCESS"; $nddzt="交易成功";
break;
}
if(empty($trade_no)){echo "success";exit;}
//注意,这里的查询不能 强制用户登录,则否支付宝没法进入本页面.没法通知成功
$sql="select ifok,jyh from yjcode_dingdang where ifok=1 and jyh='".$trade_no."'";mysql_query("SET NAMES 'GBK'");$res=mysql_query($sql);
//支付宝生成的流水号
if($row=mysql_fetch_array($res)){echo "success";exit;
}
$sql="select * from yjcode_dingdang where ddbh='".$out_trade_no."' and ifok=0 and ddzt='等待买家付款'";
mysql_query("SET NAMES 'GBK'");
$res=mysql_query($sql);
if($row=mysql_fetch_array($res)){
if(1==$row['ifok']){
echo "success";exit;
}
if($trade_status=="TRADE_SUCCESS" || $trade_status=="TRADE_FINISHED"){
if($row['money1']== $_POST['total_fee'] ){
$sj=time();$uip=$_SERVER["REMOTE_ADDR"];
updatetable("yjcode_dingdang","sj='".$sj."',uip='".$uip."',alipayzt='".$trade_status."',ddzt='".$nddzt."',ifok=1,jyh='".$trade_no."' where id=".$row[id]);
$money1=$row["money1"];
//修改订单状态为成功付款
PointIntoM($userid,"支付宝充值".$money1."元",$money1);
//会员余额增加 echo "success";exit;
}
}
}
//——请根据您的业务逻辑来编写程序(以上代码仅作参考)——
echo 'success';exit();
}
echo 'fail';exit();
class AlipayService {
//支付宝公钥
protected $alipayPublicKey;
protected $charset;
public function __construct($alipayPublicKey) {
$this->charset = 'utf8';
$this->alipayPublicKey=$alipayPublicKey;
}
/** * 验证签名 **/
public function rsaCheck($params) {
$sign = $params['sign'];
$signType = $params['sign_type'];
unset($params['sign_type']);
unset($params['sign']);
return $this->verify($this->getSignContent($params), $sign, $signType);
}
function verify($data, $sign, $signType = 'RSA') {
$pubKey= $this->alipayPublicKey;
$res = "-----BEGIN PUBLIC KEY-----\n" .
wordwrap($pubKey, 64, "\n", true) .
"\n-----END PUBLIC KEY-----";
($res) or die('支付宝RSA公钥错误。请检查公钥文件格式是否正确');
//调用openssl内置方法验签,返回bool值
if ("RSA2" == $signType) {
$result = (bool)openssl_verify($data, base64_decode($sign), $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
} else {
$result = (bool)openssl_verify($data, base64_decode($sign), $res);
} // if(!$this->checkEmpty($this->alipayPublicKey)) { //
//释放资源 //
openssl_free_key($res);
// }
return $result;
}
/** * 校验$value是否非空 * if not set ,return true; * if is null , return true; **/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
}
/** * 转换字符集编码 * @param $data * @param $targetCharset * @return string */
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
//$data = iconv($fileType, $targetCharset.'//IGNORE', $data);
}
}
return $data;
}
}<?php
define('PHPS_PATH', dirname(__FILE__).DIRECTORY_SEPARATOR);
//$_POST['trade_no']=1; if($_POST['trade_no']){ $alipayPublicKey='MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAyg8BC9UffA4ZoMl12zz';
//RSA公钥,与支付时的私钥对应
$aliPay = new AlipayService2($alipayPublicKey);
//验证签名
$result = $aliPay->rsaCheck($_POST,$_POST['sign_type']);
//file_put_contents('333.txt',$_POST);
if($result===true){
//处理你的逻辑,例如获取订单号
$_POST['out_trade_no'],订单金额$_POST['total_amount']等
$out_trade_no = $_POST['out_trade_no'];
//$out_trade_no = '2018022300293843964';
//支付宝交易号
$trade_no = $_POST['trade_no'];
//交易状态
$trade_status = $_POST['trade_status'];
//$trade_status='';
$userinfo = array();
if($trade_status=="TRADE_SUCCESS" || $trade_status=="TRADE_FINISHED"){
//ini_set('display_errors',1);
//错误信息
//ini_set('display_startup_errors',1);
//php启动错误信息
//error_reporting(-1);
//打印出所有的 错误信息
$mysql_user=include(PHPS_PATH.'/caches/configs/database.php');
$username=$mysql_user['default']['username'];
$password=$mysql_user['default']['password'];
$tablepre=$mysql_user['default']['tablepre'];
$database=$mysql_user['default']['database'];
$con = mysqli_connect($mysql_user['default']['hostname'],$username,$password); mysqli_select_db($con,$database);
$sql = ' SELECT * FROM '.$tablepre."pay_account where trade_sn='".$out_trade_no."'";
$result2=mysqli_query($con,$sql);
$orderinfo=mysqli_fetch_array($result2);;
$uid=$orderinfo['userid'];
$sql2 = ' SELECT * FROM '.$tablepre."member where userid=".$uid;
$result1=mysqli_query($con,$sql2); $userinfo=mysqli_fetch_array($result1);;
if($orderinfo){
if($orderinfo['status']=='succ'){
//file_put_contents('31.txt',1);
echo 'success';
mysqli_close($con);
exit();
}else{
// if($orderinfo['money']== $_POST['total_amount'] ){
$money = $orderinfo['money'];
$amount = $userinfo['amount'] + $money;
$sql3 = ' update '.$tablepre."member set amount= ".$amount." where userid=".$uid;
$result3=mysqli_query($con,$sql3);
$sql4 = ' update '.$tablepre."pay_account set status= 'succ' where userid=".$uid ." and trade_sn='".$out_trade_no."'";
$result4=mysqli_query($con,$sql4);
//file_put_contents('1.txt',$result4);
echo 'success';
mysqli_close($con);
exit();
// }
}
} else {
echo 'success';exit();
}
}
echo 'success';exit();
} echo 'fail';exit();
} class AlipayService2 {
//支付宝公钥
protected $alipayPublicKey;
protected $charset;
public function __construct($alipayPublicKey) {
$this->charset = 'utf8';
$this->alipayPublicKey=$alipayPublicKey;
}
/** * 验证签名 **/
public function rsaCheck($params) {
$sign = $params['sign'];
$signType = $params['sign_type'];
unset($params['sign_type']);
unset($params['sign']);
return $this->verify($this->getSignContent($params), $sign, $signType);
}
function verify($data, $sign, $signType = 'RSA') {
$pubKey= $this->alipayPublicKey;
$res = "-----BEGIN PUBLIC KEY-----\n" .
wordwrap($pubKey, 64, "\n", true) .
"\n-----END PUBLIC KEY-----";
($res) or die('支付宝RSA公钥错误。请检查公钥文件格式是否正确');
//调用openssl内置方法验签,返回bool值
if ("RSA2" == $signType) {
$result = (bool)openssl_verify($data, base64_decode($sign), $res, version_compare(PHP_VERSION,'5.4.0', '<') ? SHA256 : OPENSSL_ALGO_SHA256);
} else {
$result = (bool)openssl_verify($data, base64_decode($sign), $res);
}
// if(!$this->checkEmpty($this->alipayPublicKey)) {
//
//释放资源 //
openssl_free_key($res); //
}
return $result;
}
/** * 校验$value是否非空 * if not set ,return true; * if is null , return true; **/
protected function checkEmpty($value) {
if (!isset($value))
return true;
if ($value === null)
return true;
if (trim($value) === "")
return true;
return false;
}
public function getSignContent($params) {
ksort($params);
$stringToBeSigned = "";
$i = 0;
foreach ($params as $k => $v) {
if (false === $this->checkEmpty($v) && "@" != substr($v, 0, 1)) {
// 转换成目标字符集
$v = $this->characet($v, $this->charset);
if ($i == 0) {
$stringToBeSigned .= "$k" . "=" . "$v";
} else {
$stringToBeSigned .= "&" . "$k" . "=" . "$v";
}
$i++;
}
}
unset ($k, $v);
return $stringToBeSigned;
} /** * 转换字符集编码 * @param $data * @param $targetCharset * @return string */
function characet($data, $targetCharset) {
if (!empty($data)) {
$fileType = $this->charset;
if (strcasecmp($fileType, $targetCharset) != 0) {
$data = mb_convert_encoding($data, $targetCharset, $fileType);
//$data = iconv($fileType, $targetCharset.'//IGNORE', $data);
}
}
return $data;
}
}
?>5. 抓包
常用抓包工具
6. https / http
7. wie Effizienz
8. links, rechts, verbinden, das kartesische Produkt lösen
SQL-Vereinigung, Schnittmenge, außer Aussage
9. oop封装、继承、多态
php面向对象之继承、多态、封装简介
作者:PHP中文网2018-03-02 09:49:15
interface InterAnimal{
public function speak();
public function name($name);
}//接口实现 class cat implements InterAnimal{
public function speak(){
echo "speak";
}
public function name($name){
echo "My name is ".$name;
}
}<br/>class Computer {
private $_name = '联想';
public function __get($_key) {
return $this->$_key;
}
public function run() {
echo '父类run方法';
}}class NoteBookComputer extends Computer {}$notebookcomputer = new NoteBookComputer ();
$notebookcomputer->run ();
//继承父类中的run()方法echo $notebookcomputer->_name;
//通过魔法函数__get()获得私有字段<br/>class Computer {
public $_name = '联想';
protected function run() {
echo '我是父类';
}}//重写其字段、方法class NoteBookComputer extends Computer {
public $_name = 'IBM';
public function run() {
echo '我是子类';
}}<br/>abstract class Computer {
abstract function run();
}
final class NotebookComputer extends Computer {
public function run() {
echo '抽象类的实现';
}
}<br/>interface Computer {
public function version();
public function work();
}class NotebookComputer implements Computer {
public function version() {
echo '联想<br>';
}
public function work() {
echo '笔记本正在随时携带运行!';
}}class desktopComputer implements Computer {
public function version() {
echo 'IBM';
}
public function work() {
echo '台式电脑正在工作站运行!';
}}class Person {
public function run($type) {
$type->version ();
$type->work ();
}}
$person = new Person ();
$desktopcomputer = new desktopComputer ();
$notebookcomputer = new NoteBookComputer ();
$person->run ( $notebookcomputer );<br/> PHP objektorientiertes Identifikationsobjekt
PHP objektorientiertes Identifikationsobjekt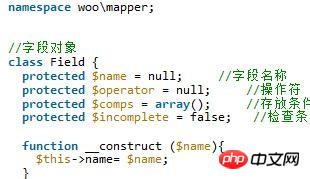 Detaillierte Erläuterung der PHP-objektorientierten Identifikationsobjektinstanz
Detaillierte Erläuterung der PHP-objektorientierten Identifikationsobjektinstanz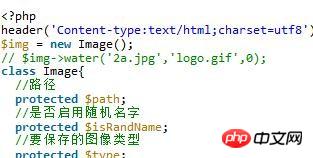 PHP-Kapselungscodefreigabe für Bildwasserzeichenklasse
PHP-Kapselungscodefreigabe für Bildwasserzeichenklasse Detaillierte Erläuterung der PHP-Kapselungs-MySQL-Operationsklasse
Detaillierte Erläuterung der PHP-Kapselungs-MySQL-Operationsklasse10 > Das MVC-Muster (Model-View-Controller) ist eines der Software-Engineering-

1. Laden von Ressourcen von mehreren Domänennamen
1. „Erste Meile“ bezieht sich auf den ersten Ausgang für den World Wide Web-Verkehr, der an Benutzer übertragen wird. Es ist die Verbindung für den Website-Server, um auf das Internet zuzugreifen. Diese Ausgangsbandbreite bestimmt die Zugriffsgeschwindigkeit und die gleichzeitigen Besuche, die eine Website den Benutzern ermöglichen kann. Wenn Benutzeranfragen die Ausgangsbandbreite der Website überschreiten, kommt es am Ausgang zu einer Überlastung.
2. „Die letzte Meile“, der letzte Link, über den der World Wide Web-Verkehr an Benutzer übertragen wird, d. h. der Link, über den Benutzer auf das Internet zugreifen. Die Bandbreite des Zugriffs eines Benutzers beeinflusst die Fähigkeit des Benutzers, Datenverkehr zu empfangen. Mit der starken Entwicklung der Telekommunikationsbetreiber wurde die Benutzerzugriffsbandbreite erheblich verbessert und das Problem der „letzten Meile“ im Wesentlichen gelöst. Grundlegender Prozess
 <br/>1. Der Benutzer gibt den Domänennamen ein, auf den im Browser zugegriffen werden soll. <br/>2. Der Browser fordert den DNS-Server auf, den Domänennamen aufzulösen. <br/>3. Der DNS-Server gibt die IP-Adresse des Domänennamens an den Browser zurück. <br/>4. Der Browser verwendet die IP-Adresse, um Inhalte vom Server anzufordern. <br/>5. Der Server gibt den vom Benutzer angeforderten Inhalt an den Browser zurück.
<br/>1. Der Benutzer gibt den Domänennamen ein, auf den im Browser zugegriffen werden soll. <br/>2. Der Browser fordert den DNS-Server auf, den Domänennamen aufzulösen. <br/>3. Der DNS-Server gibt die IP-Adresse des Domänennamens an den Browser zurück. <br/>4. Der Browser verwendet die IP-Adresse, um Inhalte vom Server anzufordern. <br/>5. Der Server gibt den vom Benutzer angeforderten Inhalt an den Browser zurück.  <br/>1. Der Benutzer gibt den Domänennamen ein, auf den im Browser zugegriffen werden soll. <br/>2. Der Browser fordert den DNS-Server auf, den Domänennamen aufzulösen. Da das CDN die Domänennamenauflösung anpasst, übergibt der DNS-Server schließlich die Rechte zur Domänennamenauflösung an den CDN-dedizierten DNS-Server, auf den der CNAME verweist. <br/>3. Der DNS-Server des CDN gibt die IP-Adresse des CDN-Lastausgleichsgeräts an den Benutzer zurück. <br/>4. Der Benutzer initiiert eine Inhalts-URL-Zugriffsanforderung an das Lastausgleichsgerät des CDN. <br/>5. Das CDN-Lastausgleichsgerät wählt einen geeigneten Cache-Server aus, um Dienste für Benutzer bereitzustellen. <br/>Die Grundlage für die Auswahl ist: Beurteilen, welcher Server dem Benutzer am nächsten ist, basierend auf der IP-Adresse des Benutzers; Beurteilen, welcher Server den Inhalt hat, den der Benutzer benötigt, basierend auf dem Inhaltsnamen, der in der vom Benutzer angeforderten URL enthalten ist; Bestimmen Sie anhand der jeweiligen Server-Auslastungssituation, welcher Server die geringere Auslastung hat. <br/>Basierend auf der umfassenden Analyse der oben genannten Punkte geben die Lastausgleichseinstellungen die IP-Adresse des Cache-Servers an den Benutzer zurück. <br/>6. Der Benutzer stellt eine Anfrage an den Cache-Server. <br/>7. Der Cache-Server reagiert auf Benutzeranfragen und liefert dem Benutzer die vom Benutzer benötigten Inhalte. <br/>Wenn dieser Cache-Server nicht über den Inhalt verfügt, den der Benutzer wünscht, und das Lastausgleichsgerät ihn dennoch dem Benutzer zuweist, fordert dieser Server den Inhalt von seinem Cache-Server der oberen Ebene an, bis er zu ihm zurückverfolgt werden kann Website Der Ursprungsserver ruft den Inhalt lokal ab.
<br/>1. Der Benutzer gibt den Domänennamen ein, auf den im Browser zugegriffen werden soll. <br/>2. Der Browser fordert den DNS-Server auf, den Domänennamen aufzulösen. Da das CDN die Domänennamenauflösung anpasst, übergibt der DNS-Server schließlich die Rechte zur Domänennamenauflösung an den CDN-dedizierten DNS-Server, auf den der CNAME verweist. <br/>3. Der DNS-Server des CDN gibt die IP-Adresse des CDN-Lastausgleichsgeräts an den Benutzer zurück. <br/>4. Der Benutzer initiiert eine Inhalts-URL-Zugriffsanforderung an das Lastausgleichsgerät des CDN. <br/>5. Das CDN-Lastausgleichsgerät wählt einen geeigneten Cache-Server aus, um Dienste für Benutzer bereitzustellen. <br/>Die Grundlage für die Auswahl ist: Beurteilen, welcher Server dem Benutzer am nächsten ist, basierend auf der IP-Adresse des Benutzers; Beurteilen, welcher Server den Inhalt hat, den der Benutzer benötigt, basierend auf dem Inhaltsnamen, der in der vom Benutzer angeforderten URL enthalten ist; Bestimmen Sie anhand der jeweiligen Server-Auslastungssituation, welcher Server die geringere Auslastung hat. <br/>Basierend auf der umfassenden Analyse der oben genannten Punkte geben die Lastausgleichseinstellungen die IP-Adresse des Cache-Servers an den Benutzer zurück. <br/>6. Der Benutzer stellt eine Anfrage an den Cache-Server. <br/>7. Der Cache-Server reagiert auf Benutzeranfragen und liefert dem Benutzer die vom Benutzer benötigten Inhalte. <br/>Wenn dieser Cache-Server nicht über den Inhalt verfügt, den der Benutzer wünscht, und das Lastausgleichsgerät ihn dennoch dem Benutzer zuweist, fordert dieser Server den Inhalt von seinem Cache-Server der oberen Ebene an, bis er zu ihm zurückverfolgt werden kann Website Der Ursprungsserver ruft den Inhalt lokal ab. Zusammenfassung
12. Nginx-Lastausgleich
13. Caching (sieben Beschreibungsebenen)
VerzeichnisModerne Websites bieten dynamischere Inhalte wie dynamische Webseiten, dynamische Bilder, Webdienste usw. Diese werden normalerweise auf der Webserverseite berechnet und generiert HTML und zurück. Beim Generieren von HTML-Seiten sind zahlreiche CPU-Berechnungen und E/A-Vorgänge beteiligt, z. B. CPU-Berechnungen und Festplatten-E/A des Datenbankservers sowie Netzwerk-E/A für die Kommunikation mit dem Datenbankserver. Diese Vorgänge nehmen jedoch viel Zeit in Anspruch. In den meisten Fällen sind die Ergebnisse dynamischer Webseiten jedoch nahezu identisch. Dann können Sie erwägen, diesen Teil des Zeitaufwands durch Caching zu eliminieren.
Für dynamische Webseiten speichern wir den generierten HTML-Code, der als Seiten-Cache bezeichnet wird. Für andere dynamische Inhalte wie dynamische Bilder und dynamische XML-Daten können wir diese auch zwischenspeichern Ergebnisse als Ganzes mit der gleichen Strategie.
1.1.1 Speichermethode
1.1.2 Ablaufprüfung
1.1.3 Lokal kein Cache
1.2 Statischer Inhalt
2. Browser-Cache
2.1 Implementierung
2.1.1 缓存协商
header("Last-Modified: " . gmdate("D, d M Y H:i:s") . " GMT");Last-Modified: Fri, 9 Dec 2014 23:23:23 GMT
If-Modified-Since: Fri, 9 Dec 2014 23:23:23 GMT
HTTP/1.1 304 Not Modified
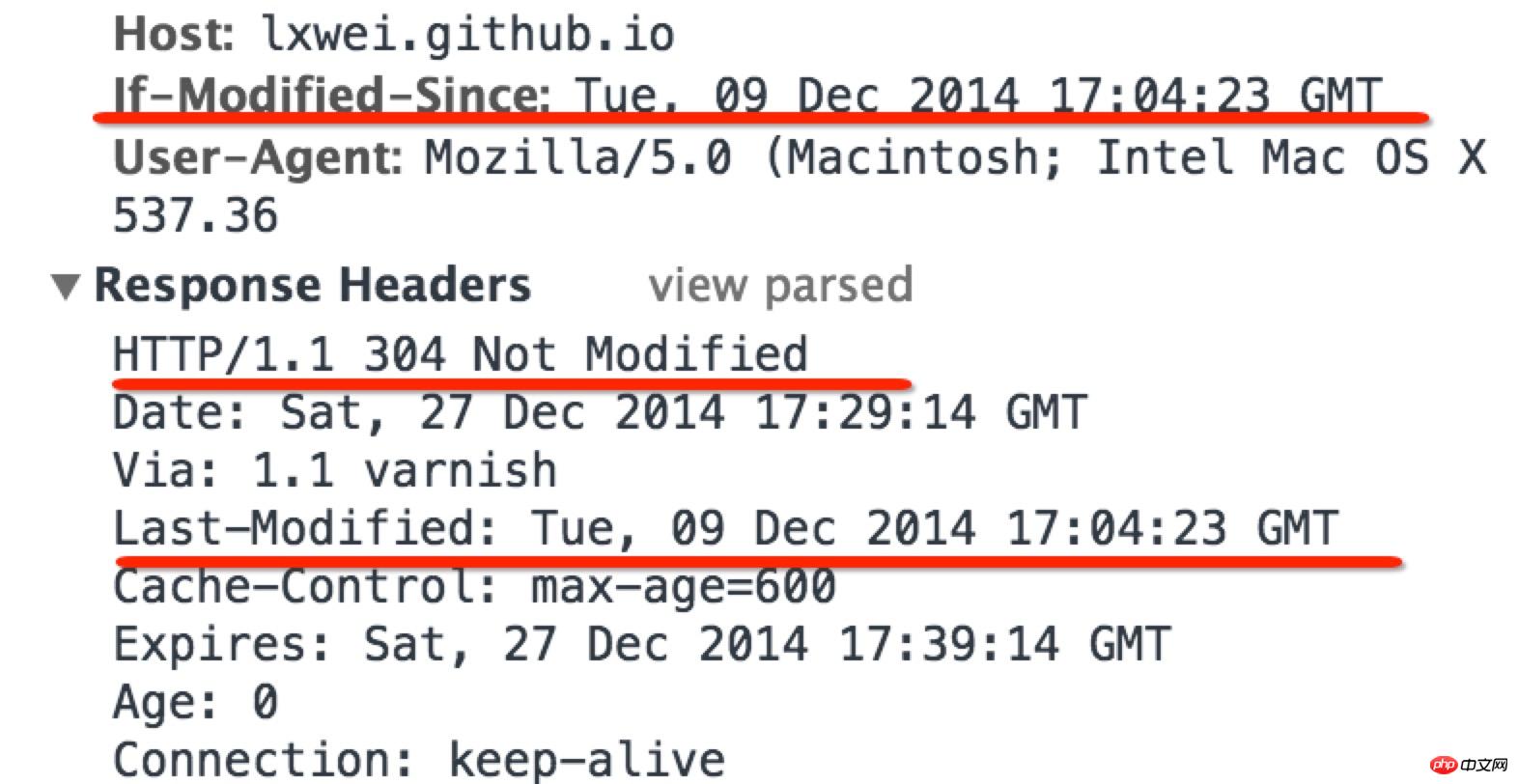
If-None-Match: "87665-c-090f0adfadf"
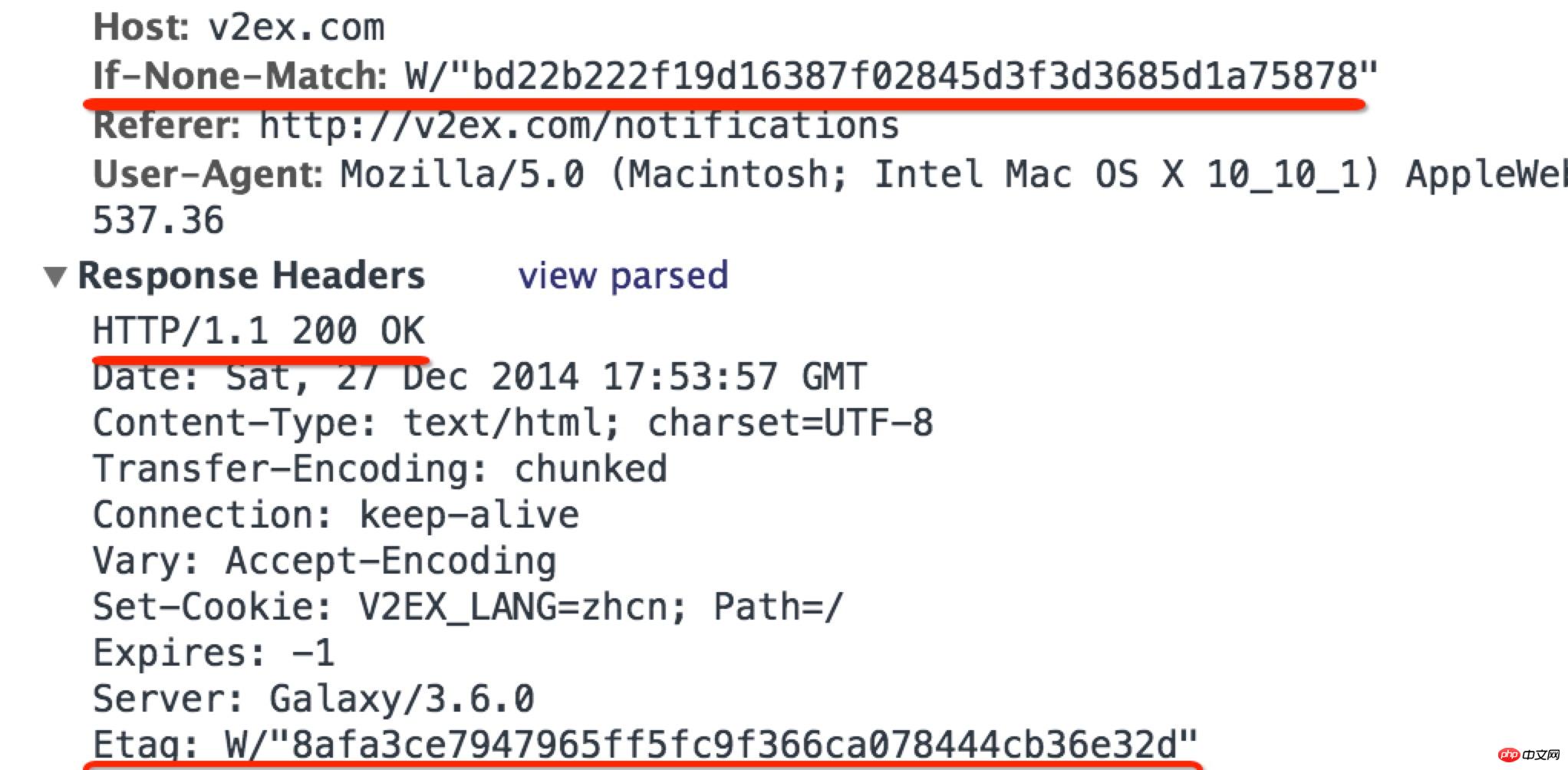
2.1.2 性能
2.2 彻底消灭请求
2.2.1 Expires 标记
Expires标记,告诉浏览器该内容何时过期,在内容过期前不需要再询问服务器,直接使用本地缓存即可。2.2.2 请求页面方式
Last-Modified Expires Ctrl + F5 无效 无效 F5 有效 无效 转到 有效 有效 2.2.3 适应过期时间
max-age 指定缓存过期的相对时间,单位是秒,相对时间指相对浏览器本地时间。目前,当 HTTP 响应中同时含有 Expires 和 Cache-Control 时,浏览器会优先使用 Cache-Control。2.3 总结
3. Web 服务器缓存
3.1 简介
Expires 标记,如果希望不缓存某个动态内容,那么最简单的办法就是使用:header("Expires: 0");Last-Modified来实现,具体方法不再叙述。3.2 取代动态内容缓存
3.3 缓存文件描述符
4. 反向代理缓存
4.1 反向代理简介
4.2 Reverse-Proxy-Cache
4.2.1 Caching-Regeln ändern
4.2.2 Cache löschen
5. Verteiltes Caching
5.1 Memcached
5.2 Lese- und Schreibcache
5.3 Cache-Überwachung
5.4 Cache-Erweiterung
6. Zusammenfassung
14. Inhaltsumleitung, CMS-Statisierung 1. Warum sollte es statisch sein?
Beschleunigen Sie das Öffnen und Durchsuchen von Seiten. Statische Seiten müssen nicht mit der Datenbank verbunden werden und sind deutlich schneller als dynamische Seiten 🎜>Es ist für die Suchmaschinenoptimierung und SEO von Vorteil, da Baidu und Google der Einbindung statischer Seiten Vorrang einräumen, die nicht nur schnell, sondern auch vollständig eingebunden werden auf dem Server, und es ist nicht erforderlich, beim Surfen im Internet die Systemdatenbank aufzurufen;
Die Präzision des statischen Algorithmus. Um Daten, Webseitenvorlagen und verschiedene Dateiverknüpfungspfade ordnungsgemäß verarbeiten zu können, müssen wir alle Aspekte des statischen Algorithmus berücksichtigen. Ein leichtes Versehen kann dazu führen, dass auf den generierten Seiten falsche Links der einen oder anderen Art oder sogar tote Links entstehen. Deshalb müssen wir diese Probleme angemessen lösen. Es kann die Möglichkeiten des Algorithmus nicht erweitern, muss aber auch alle Aspekte berücksichtigen. Es ist in der Tat nicht einfach, dies zu tun.
pseudostatisches unterteilt Zweitens verfügt PHP über unterschiedliche Verarbeitungsmechanismen zum Generieren statischer Seiten.
verwendet, ist es schwierig, die Kapazität des gleichzeitigen Zugriffs auf die Website effektiv zu erhöhen, indem die Anzahl der Webserver erhöht wird. Zum Beispiel Taobao und JD.com.
Statische Lösung: Der Grund, warum große statische Websites schnell und mit hoher Parallelität reagieren können, liegt darin, dass sie
ihr Bestes geben, um Dynamische und statische Kombination von Webservern. Einige Teile der Seite bleiben unverändert, beispielsweise die Kopf- und Fußzeile. Ob dieser Teil also im Cache platziert werden kann. Der Webserver Apache oder NGNIX, Apache verfügt über ein Modul namens ESI, CSI. Kann dynamisch und statisch spleißen. Cachen Sie den statischen Teil auf dem Webserver und fügen Sie ihn dann mit der vom Server zurückgegebenen dynamischen Seite zusammen.
15. Spirit CSS Ist je größer, desto besser?
Wann zu verwenden: Beginnen wir mit dem Prinzip. Wenn unser Anforderungsvolumen besonders groß und die Anforderungsdaten klein sind, können wir mehrere kleine Bilder zu einem großen Bild zusammenfassen und dies erreichen Positionierung; Wenn das Diagramm relativ groß ist, müssen Sie das Schneiden von Diagrammen verwenden, um die Ressourcen zu reduzieren. Auf diese Weise werden mehrere Anforderungen zu einer zusammengeführt, wodurch weniger Netzwerkressourcen verbraucht und der Front-End-Zugriff optimiert wird. <br/>

<p>
<p>
<b class="N1 n10"></b>
<em class="First small_up1"></em>
<span class="A1 up1"></span>
<span class="A2 up1"></span>
<span class="A3 down1"></span>
<span class="A4 down1"></span>
<span class="B1 up1"></span>
<span class="B2 down1"></span>
<span class="C1 up1"></span>
<span class="C2 up1"></span>
<span class="C3 down1"></span>
<span class="C4 down1"></span>
<em class="Last small_down1"></em>
<b class="N2 n10_h"></b>
</p>
</p>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>制作一幅扑克牌--黑桃10</title>
<style type="text/css"><!--
.card{width:125px;height:170px; position:absolute;overflow:hidden;border:1px #c0c0c0 solid;}
/*中间图片通用设置*/
span{display:block;width:20px;height:21px; position:absolute;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat;}
/*小图片通用设置*/
b{display:block;width:15px;height:10px; position:absolute;font-size:10pt;text-align:center;font-weight:bold;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat; overflow:hidden;}
/*数字通用设置*/
em{display:block;width:15px;height:10px; position:absolute;font-size:10pt;text-align:center;font-weight:bold;background:url(http://www.blueidea.com//articleimg/2009/02/6382/00.gif) no-repeat;overflow:hidden;}
/*各坐标点位置*/
.N1{left:1px;top:8px;}
.First{left:5px;top:20px;}
.A1{left:20px;top:20px;}
.A2{left:20px;top:57px;}
.A3{left:20px;top:94px;}
.A4{left:20px;top:131px;}
.B1{left:54px;top:38px;}
.B2{left:54px;top:117px;}
.C1{left:86px;top:20px;}
.C2{left:86px;top:57px;}
.C3{left:86px;top:94px;}
.C4{left:86px;top:131px;}
.Last{bottom:20px;right:0px;}
.N2{bottom:8px;right:5px;
}
/*大图标黑红梅方四种图片-上方向*/
.up1{background-position:0 1px;}/*黑桃*/
/*大图标黑红梅方四种图片-下方向*/
.down1{background-position:0 -19px;}/*黑桃*/
/*小图标黑红梅方四种图片-上方向*/
.small_up1{background-position:0 -40px;}/*黑桃*/
/*小图标黑红梅方四种图片-下方向*/
.small_down1{background-position:0 -51px;}/*黑桃*/
/*A~k数字图片-左上角*/
.n10{background-position:-191px 0px;left:-4px;width:21px;}
/*A~k数字图片-右下角*/
.n10_h{background-position:-191px -22px;right:3px;width:21px;}
/*A~k数字图片-左上角红色字*/
.n10_red{background-position:-191px 0px;}
/*A~k数字图片-右下角红色字*/
.n10_h_red{background-position:-191px -33px;}
-->
</style>
</head>
<body>
<!--10字符-->
<p>
<p>
<b class="N1 n10"></b>
<em class="First small_up1"></em>
<span class="A1 up1"></span>
<span class="A2 up1"></span>
<span class="A3 down1"></span>
<span class="A4 down1"></span>
<span class="B1 up1"></span>
<span class="B2 down1"></span>
<span class="C1 up1"></span>
<span class="C2 up1"></span>
<span class="C3 down1"></span>
<span class="C4 down1"></span>
<em class="Last small_down1"></em>
<b class="N2 n10_h"></b>
</p>
</p>
</body>
</html>16. 反向代理/正向代理
正向代理与反向代理【总结】

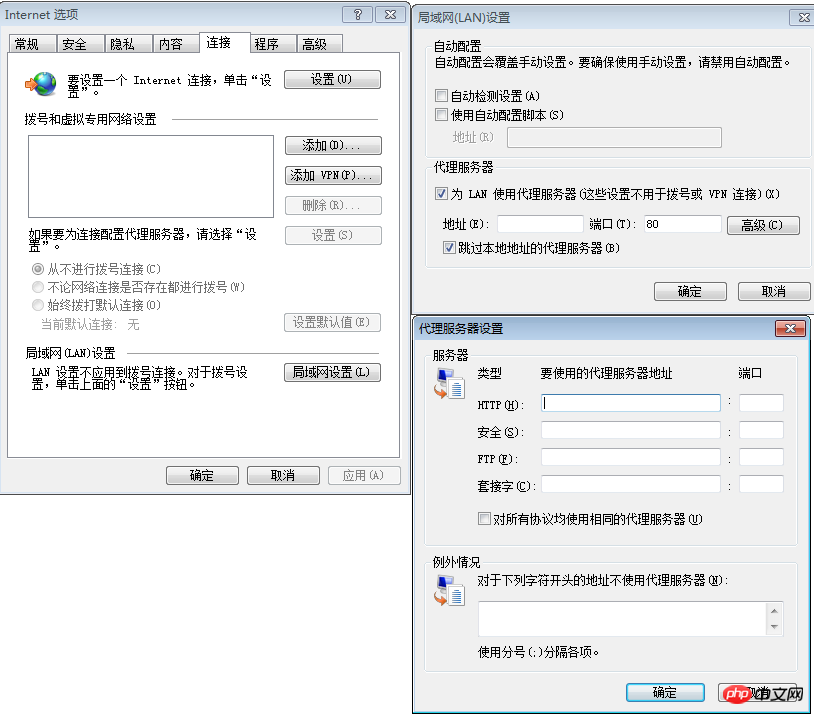

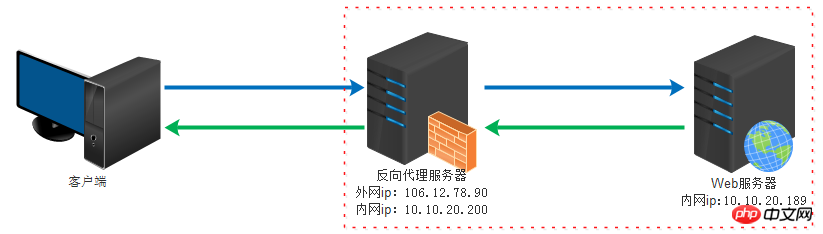
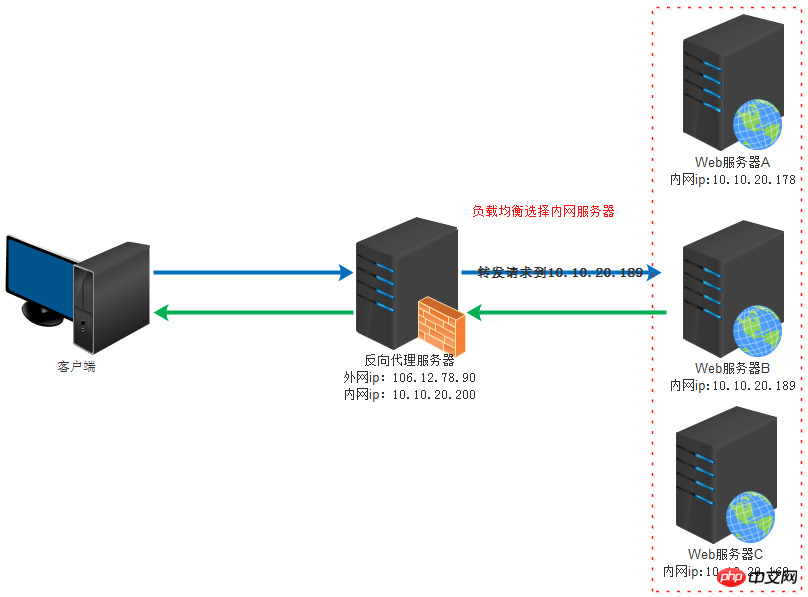
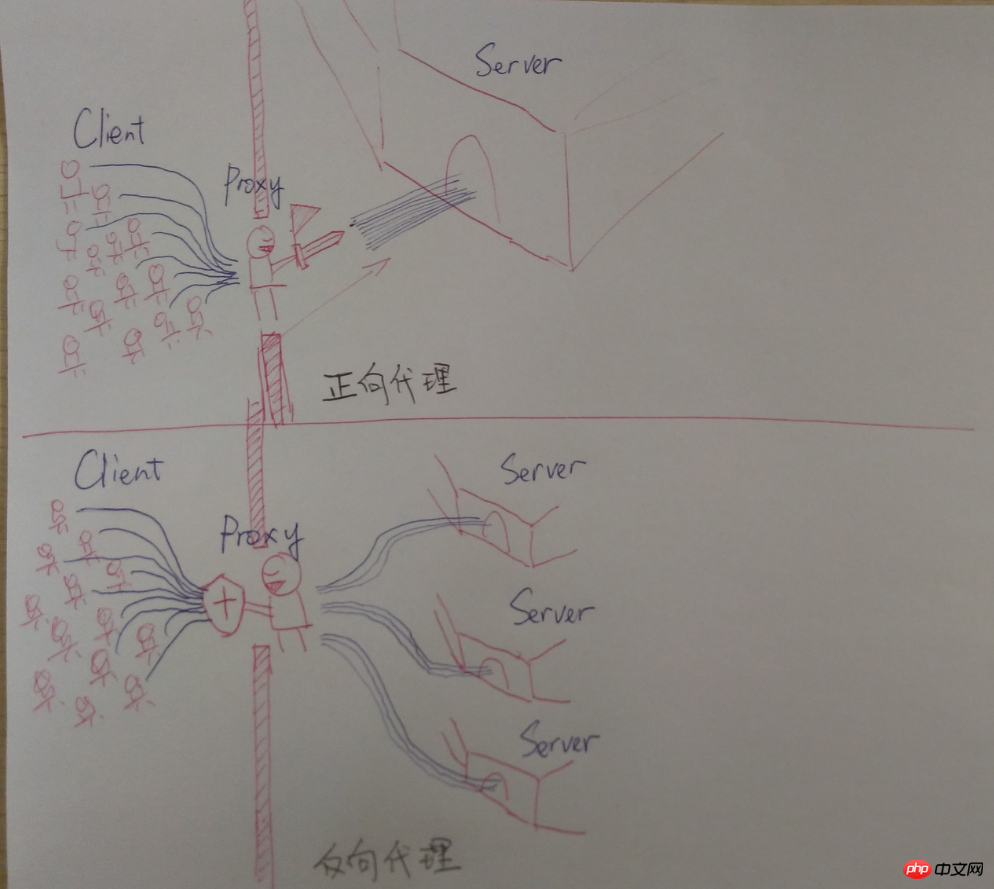
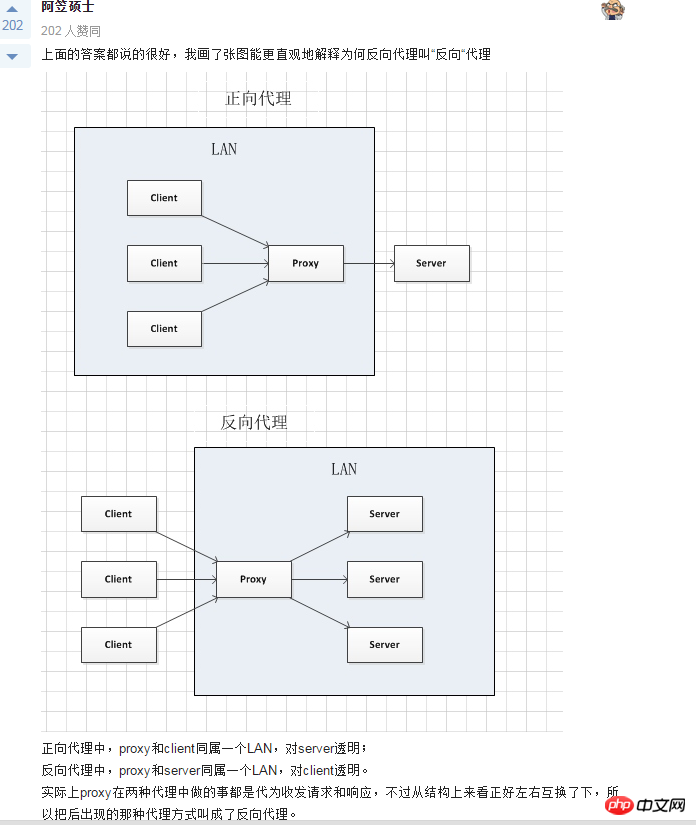
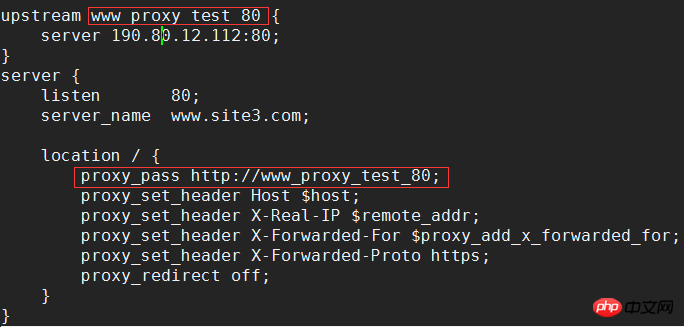
Forward-Proxy
Der Client sendet eine normale Nachricht an die Reverse-Proxy-Anfrage, und dann überträgt der Reverse-Proxy die Anfrage an den ursprünglichen Server und gibt den erhaltenen Inhalt an den Client zurück, als ob der Inhalt vorhanden wäre ursprünglich ein eigener.
Transparenter Proxy
Der Unterschied zwischen Forward-Proxy und Reverse-Proxy
ZweckForward-Proxy Typische Verwendung ist die Bereitstellung des Zugriffs auf das Internet für LAN-Clients innerhalb der Firewall.
Verwenden Sie Pufferfunktionen, um die Netzwerknutzung zu reduzieren.
Reverse-Proxy
Sicherheit
Reverse-ProxyEs ist für die Außenwelt transparent und Besucher wissen nicht, dass sie einen Proxy besuchen.
Der Unterschied zwischen Reverse-Proxy und CDNEinfach ausgedrückt ist CDN eine netzwerkbeschleunigte
, und Reverse-Proxy ist Technologie, die Benutzeranfragen an den Backend-Server weiterleitet.
17. MySQL-Master-Slave-Optimierung
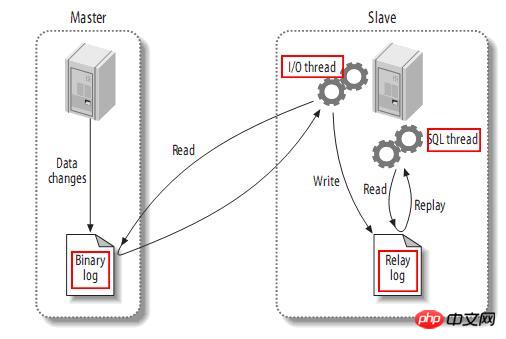
18. Web-Sicherheit
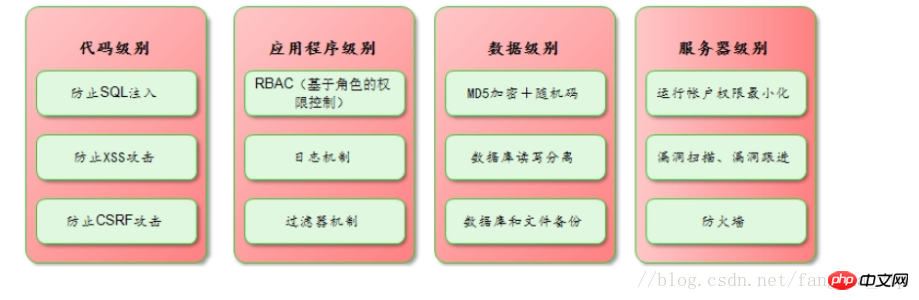 <br/>
<br/>20. Der Unterschied zwischen Memcached und Redis
21. Der Unterschied zwischen Apache und Nginx
1. Definition:
1. Apache
Gleiche Punkte:
2. Vergleich zwischen Nginx und Apache
1) nginx relativ zu Vorteile von Apache
ApacheApache gegenüber > rewrite ist leistungsfähiger als nginx
l
Nginx Weitere Informationen finden Sie hier: http://www.findme.wang/blog/detail/id/1.html
CPU anzeigen <br/> Sie können den Inhalt von %MEM direkt mit dem oberen Befehl anzeigen. Sie können wählen, ob Sie die Prozessspeichernutzung des Oracle-Benutzers anzeigen möchten, indem Sie den folgenden Befehl verwenden: <br/>$ top -u oracle<br/>
<br/> Sie können den Inhalt von %MEM direkt mit dem oberen Befehl anzeigen. Sie können wählen, ob Sie die Prozessspeichernutzung des Oracle-Benutzers anzeigen möchten, indem Sie den folgenden Befehl verwenden: <br/>$ top -u oracle<br/> Linux Prozesse anzeigen und Prozesse löschen
Linux Prozesse anzeigen und Prozesse löschen 23. 性能优化
分布式缓存
缓存的基本原理
缓存是指将数据存储在相对较高访问速度的存储介质中。
(1)访问速度快,减少数据访问时间;
(2)如果缓存的数据进过计算处理得到的,那么被缓存的数据无需重复计算即可直接使用。
缓存的本质是一个内存Hash表,以一对Key、Value的形式存储在内存Hash表中,读写时间复杂度为O(1)。
合理使用缓存
不合理使用缓存非但不能提高系统的性能,还会成为系统的累赘,甚至风险。
频繁修改的数据
如果缓存中保存的是频繁修改的数据,就会出现数据写入缓存后,应用还来不及读取缓存,数据就已经失效,徒增系统负担。一般来说,数据的读写比在2:1以上,缓存才有意义。
没有热点的访问
如果应用系统访问数据没有热点,不遵循二八定律,那么缓存就没有意义。
数据不一致与脏读
一般会对缓存的数据设置失效时间,一旦超过失效时间,就要从数据库中重新加载。因此要容忍一定时间的数据不一致,如卖家已经编辑了商品属性,但是需要过一段时间才能被买家看到。还有一种策略是数据更新立即更新缓存,不过这也会带来更多系统开销和事务一致性问题。
缓存可用性
缓存会承担大部分数据库访问压力,数据库已经习惯了有缓存的日子,所以当缓存服务崩溃时,数据库会因为完全不能承受如此大压力而宕机,导致网站不可用。
这种情况被称作缓存雪崩,发生这种故障,甚至不能简单地重启缓存服务器和数据库服务器来恢复。
实践中,有的网站通过缓存热备份等手段提高缓存可用性:当某台缓存服务器宕机时,将缓存访问切换到热备服务器上。
但这种设计有违缓存的初衷,**缓存根本就不应该当做一个可靠的数据源来使用**。
通过分布式缓存服务器集群,将缓存数据分布到集群多台服务器上可在一定程度上改善缓存的可用性。
当一台缓存服务器宕机时,只有部分缓存数据丢失,重新从数据库加载这部分数据不会产生很大的影响。
缓存预热
缓存中的热点数据利用LRU(最近最久未用算法)对不断访问的数据筛选淘汰出来,这个过程需要花费较长的时间。
那么最好在缓存系统启动时就把热点数据加载好,这个缓存预加载手段叫缓存预热。
缓存穿透
如果因为不恰当的业务、或者恶意攻击持续高并发地请求某个不存在的数据,由于缓存没有保存该数据,所有的请求都会落到数据库上,会对数据库造成压力,甚至崩溃。
**一个简单的对策是将不存在的数据也缓存起来(其value为null)** 。分布式缓存架构
分布式缓存指缓存部署在多个服务器组成的集群中,以集群方式提供缓存服务,其架构方式有两种,一种是以JBoss Cache为代表的需要更新同步的分布式缓存,一种是以Memcached为代表的不互相通信的分布式缓存。 JBoss Cache在集群中所有服务器中保存相同的缓存数据,当某台服务器有缓存数据更新,就会通知其他机器更新或清除缓存数据。 它通常将应用程序和缓存部署在同一台服务器上,但受限于单一服务器的内存空间;当集群规模较大的时候,缓存更新需要同步到所有机器,代价惊人。因此这种方案多见于企业应用系统中。 Memcached采用一种集中式的缓存集群管理(互不通信的分布式架构方式)。缓存与应用分离部署,缓存系统部署在一组专门的服务器上,应用程序通过一致性Hash等路由算法选择缓存服务器远程访问数据,缓存服务器之间不通信,集群规模可以很容易地实现扩容,具有良好的伸缩性。 (1)简单的通信协议。Memcached使用TCP协议(UDP也支持)通信; (2)丰富的客户端程序。 (3)高性能的网络通信。Memcached服务端通信模块基于Libevent,一个支持事件触发的网络通信程序库,具有稳定的长连接。 (4)高效的内存管理。 (5)互不通信的服务器集群架构。
异步操作
使用消息队列将调用异步化(生产者--消费者模式),可改善网站的扩展性,还可以改善系统的性能。
在不使用消息队列的情况下,用户的请求数据直接写入数据库,在高并发的情况下,会对数据库造成巨大压力,使得响应延迟加剧。
在使用消息队列后,用户请求的数据发送给消息队列后立即返回,再由消息队列的消费者进程(通常情况下,该进程独立部署在专门的服务器集群上)从消息队列中获取数据,
异步写入数据库。由于消息队列服务器处理速度远快于服务器(消息队列服务器也比数据库具有更好的伸缩性)。
消息队列具有很好的削峰作用--通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。
需要注意的是,由于数据写入消息队列后立即返回给用户,数据在后续的业务校验、写数据库等操作可能失败,因此在使用消息队列进行业务异步处理后,
需要适当修改业务流程进行配合,如订单提交后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完后,
甚至商品出库后,再通过电子邮件或SMS消息通知用户订单成功,以免交易纠纷。
使用集群
在网站高并发访问的场景下,使用负载均衡技术为一个应用构建一个由多台服务器组成的服务器集群,将并发访问请求分发到多台服务器上处理。
代码优化
多线程
从资源利用的角度看,使用多线程的原因主要有两个:IO阻塞与多CPU。
当前线程进行IO处理的时候,会被阻塞释放CPU以等待IO操作完成,由于IO操作(不管是磁盘IO还是网络IO)通常都需要较长的时间,这时CPU可以调度其他的线程进行处理。
理想的系统Load是既没有进程(线程)等待也没有CPU空闲,利用多线程IO阻塞与执行交替进行,可最大限度利用CPU资源。
使用多线程的另一个原因是服务器有多个CPU。
简化启动线程估算公式:
启动线程数 = [任务执行时间 / (任务执行时间 - IO等待时间)]*CPU内核数 多线程编程一个需要注意的问题是线程安全问题,即多线程并发对某个资源进行修改,导致数据混乱。
所有的资源---对象、内存、文件、数据库,乃至另一个线程都可能被多线程并发访问。
编程上,解决线程安全的主要手段有:
(1)将对象设计为无状态对象。
所谓无状态对象是指对象本身不存储状态信息(对象无成员变量,或者成员变量也是无状态对象),不过从面向对象设计的角度看,无状态对象是一种不良设计。
(2)使用局部对象。
即在方法内部创建对象,这些对象会被每个进入该方法的线程创建,除非程序有意识地将这些对象传递给其他线程,否则不会出现对象被多线程并发访问的情形。
(3)并发访问资源时使用锁。
即多线程访问资源的时候,通过锁的方式使多线程并发操作转化为顺序操作,从而避免资源被并发修改。
资源复用
1系统运行时,要尽量减少那些开销很大的系统资源的创建和销毁,比如数据库连接、网络通信连接、线程、复杂对象等。
2从编程角度,资源复用主要有两种模式:单例(Singleton)和对象池(Object Pool)。
3单例虽然是GoF经典设计模式中较多被诟病的一个模式,但由于目前Web开发中主要使用贫血模式,从Service到Dao都是些无状态对象,无需重复创建,使用单例模式也就自然而然了。
4对象池模式通过复用对象实例,减少对象创建和资源消耗。
5对于数据库连接对象,每次创建连接,数据库服务端都需要创建专门的资源以应对,因此频繁创建关闭数据库连接,对数据库服务器是灾难性的,
同时频繁创建关闭连接也需要花费较长的时间。
6因此实践中,应用程序的数据库连接基本都使用连接池(Connection Pool)的方式,数据库连接对象创建好以后,
将连接对象放入对象池容器中,应用程序要连接的时候,就从对象池中获取一个空闲的连接使用,使用完毕再将该对象归还到对象池中即可,不需要创建新的连接。
数据结构
早期关于程序的一个定义是,程序就是数据结构+算法,数据结构对于编程的重要性不言而喻。
在不同场景中合理使用数据结构,灵活组合各种数据结构改善数据读写和计算特性可极大优化程序的性能。
垃圾回收
理解垃圾回收机制有助于程序优化和参数调优,以及编写内存安全的代码。
24. 支付
手机网站支付接口
产品简介
申请条件
配置
查看PID

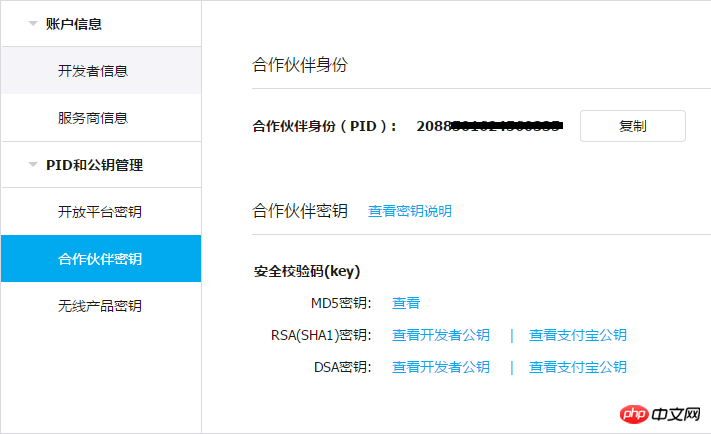
配置密钥
应用环境
 <br/>
<br/> <br/>上图是我的应用配置选项,公司账号也许会有所不同。具体哪些参数需要配置?请参照接口参数说明,需要什么就配置什么。
<br/>上图是我的应用配置选项,公司账号也许会有所不同。具体哪些参数需要配置?请参照接口参数说明,需要什么就配置什么。交互
Node端发起支付请求
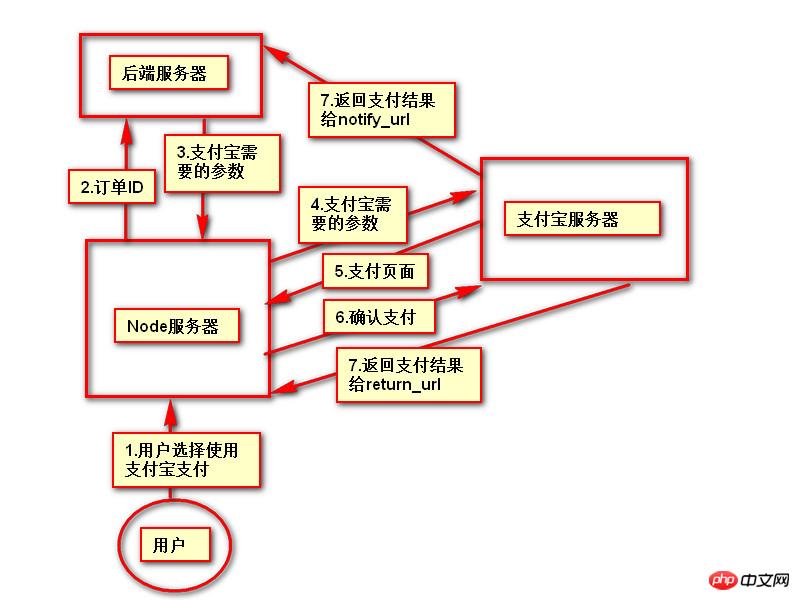 <br/>我们公司采用的,就是这种方式,步骤3中Node端获取到的支付宝参数,包括sign。其实,sign的计算工作也可以放在Node端,只不过支付宝没有给出Node的demo,实现起来需要耗费多一点时间。
<br/>我们公司采用的,就是这种方式,步骤3中Node端获取到的支付宝参数,包括sign。其实,sign的计算工作也可以放在Node端,只不过支付宝没有给出Node的demo,实现起来需要耗费多一点时间。后端发起支付请求
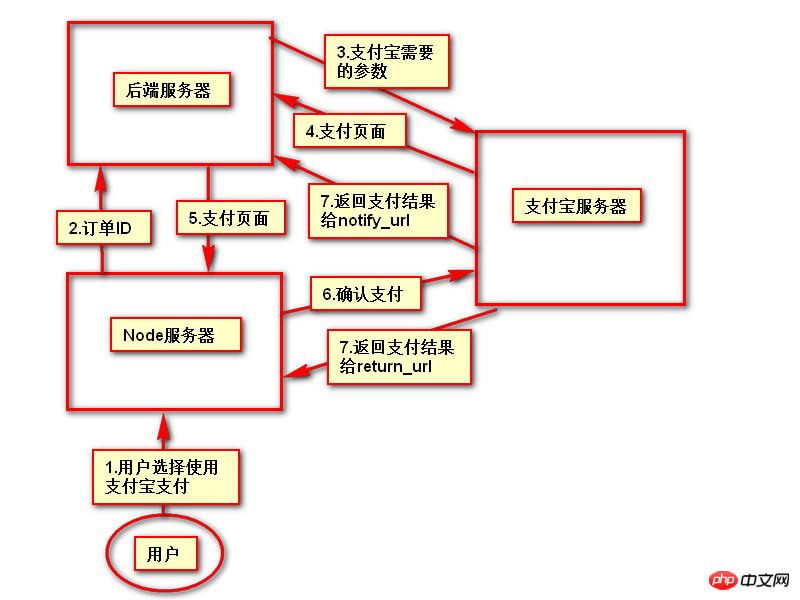 <br/>这种方式也很好,而且,步骤4中后端获取到支付页面,也可以不传给Node端,自己显示出来。这样,整个流程就更加简单。
<br/>这种方式也很好,而且,步骤4中后端获取到支付页面,也可以不传给Node端,自己显示出来。这样,整个流程就更加简单。return_url和notify_url
Node端详解
request发起请求
// 通过orderId向后端请求获取支付宝支付参数alidata var alipayUrl = 'https://mapi.alipay.com/gateway.do?'+ alidata; request.get({url: alipayUrl},function(error, response, body){ res.send(response.body); });
request.get({url: alipayUrl},function(error, response, body){
var str = response2.body;
str = str.replace(/gb2312/, "utf-8");
res.setHeader('content-type', 'text/html;charset=utf-8');
res.send(str);
});表单提交请求
Node端
// node端 // 通过orderId向后端请求获取支付宝支付参数alidata function getArg(str,arg) { var reg = new RegExp('(^|&)' + arg + '=([^&]*)(&|$)', 'i'); var r = str.match(reg); if (r != null) { return unescape(r[2]); } return null; } var alipayParam = { _input_charset: getArg(alidata,'_input_charset'), body: getArg(alidata,'body'), it_b_pay: getArg(alidata, 'it_b_pay'), notify_url: getArg(alidata, 'notify_url'), out_trade_no: getArg(alidata, 'out_trade_no'), partner: getArg(alidata, 'partner'), payment_type: getArg(alidata, 'payment_type'), return_url: getArg(alidata, 'return_url'), seller_id: getArg(alidata, 'seller_id'), service: getArg(alidata, 'service'), show_url: getArg(alidata, 'show_url'), subject: getArg(alidata, 'subject'), total_fee: getArg(alidata, 'total_fee'), sign_type: getArg(alidata, 'sign_type'), sign: getArg(alidata, 'sign'), app_pay: getArg(alidata, 'app_pay') }; res.render('artist/alipay',{ // 其他参数 alipayParam: alipayParam });html
<!--alipay.html-->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>支付宝支付</title> </head> <body>
<form id="ali-form" action="https://mapi.alipay.com/gateway.do" method="get">
<input type="hidden" name="_input_charset" value="<%= alipayParam._input_charset%>">
<input type="hidden" name="body" value="<%= alipayParam.body%>">
<input type="hidden" name="it_b_pay" value="<%= alipayParam.it_b_pay%>">
<input type="hidden" name="notify_url" value="<%= alipayParam.notify_url%>">
<input type="hidden" name="out_trade_no" value="<%= alipayParam.out_trade_no%>">
<input type="hidden" name="partner" value="<%= alipayParam.partner%>">
<input type="hidden" name="payment_type" value="<%= alipayParam.payment_type%>">
<input type="hidden" name="return_url" value="<%= alipayParam.return_url%>">
<input type="hidden" name="seller_id" value="<%= alipayParam.seller_id%>">
<input type="hidden" name="service" value="<%= alipayParam.service%>">
<input type="hidden" name="show_url" value="<%= alipayParam.show_url%>">
<input type="hidden" name="subject" value="<%= alipayParam.subject%>">
<input type="hidden" name="total_fee" value="<%= alipayParam.total_fee%>">
<input type="hidden" name="sign_type" value="<%= alipayParam.sign_type%>">
<input type="hidden" name="sign" value="<%= alipayParam.sign%>">
<input type="hidden" name="app_pay" value="<%= alipayParam.app_pay%>">
</form> <% include ../bootstrap.html %> <script type="text/javascript" src="<%= dist %>/js/business-modules/artist/alipay.js?v=2016052401"></script>
</body>
</html>
js
// alipay.js seajs.use(['zepto'],function($){
var index = {
init:function(){
var self = this;
this.bindEvent();
},
bindEvent:function(){
var self = this;
$('#ali-form').submit();
}
}
index.init();
});小结
 <br/>选择支付宝支付后,成功跳转到了支付宝支付页面,nice!看来这种方案很靠谱。
<br/>选择支付宝支付后,成功跳转到了支付宝支付页面,nice!看来这种方案很靠谱。错误排查
 <br/>值得点赞的是,支付宝给的错误代码很明确,一看就懂。上面这个错误,签名不对。因为我给alipayParam私自加了个app_pay属性,没有经过签名。
<br/>值得点赞的是,支付宝给的错误代码很明确,一看就懂。上面这个错误,签名不对。因为我给alipayParam私自加了个app_pay属性,没有经过签名。微信屏蔽支付宝
问题描述

完美解决办法
Node端
res.render('artist/alipay',{ alipayParam: alipayParam, param: urlencode(alidata) });html
<input type="hidden" id="param" value="<%= param%>"> <iframe id="payFrame" name="mainIframe" src="" frameborder="0" scrolling="auto" ></iframe>
js
var iframe = document.getElementById('payFrame'); var param = $('#param').val(); iframe.src='https://mapi.alipay.com/gateway.do?'+param;
报错
官方解决办法
html
<!--alipay.html--> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>支付宝支付</title> </head> <body> <form id="ali-form" action="https://mapi.alipay.com/gateway.do" method="get"> <input type="hidden" name="_input_charset" value="<%= alipayParam._input_charset%>"> <input type="hidden" name="body" value="<%= alipayParam.body%>"> <input type="hidden" name="it_b_pay" value="<%= alipayParam.it_b_pay%>"> <input type="hidden" name="notify_url" value="<%= alipayParam.notify_url%>"> <input type="hidden" name="out_trade_no" value="<%= alipayParam.out_trade_no%>"> <input type="hidden" name="partner" value="<%= alipayParam.partner%>"> <input type="hidden" name="payment_type" value="<%= alipayParam.payment_type%>"> <input type="hidden" name="return_url" value="<%= alipayParam.return_url%>"> <input type="hidden" name="seller_id" value="<%= alipayParam.seller_id%>"> <input type="hidden" name="service" value="<%= alipayParam.service%>"> <input type="hidden" name="show_url" value="<%= alipayParam.show_url%>"> <input type="hidden" name="subject" value="<%= alipayParam.subject%>"> <input type="hidden" name="total_fee" value="<%= alipayParam.total_fee%>"> <input type="hidden" name="sign_type" value="<%= alipayParam.sign_type%>"> <input type="hidden" name="sign" value="<%= alipayParam.sign%>"> <p class="wrapper buy-wrapper" style="max-width:90%"> <a href="javascript:void(0);" class="J-btn-submit btn mj-submit btn-strong btn-larger btn-block">确认支付</a> </p> </form> <input type="hidden" id="param" value="<%= param%>"> <% include ../bootstrap.html %> <script type="text/javascript" src="<%= dist %>/js/business-modules/artist/ap.js"></script> <script> var btn = document.querySelector(".J-btn-submit"); btn.addEventListener("click", function (e) { e.preventDefault(); e.stopPropagation(); e.stopImmediatePropagation(); var queryParam = ''; Array.prototype.slice.call(document.querySelectorAll("input[type=hidden]")).forEach(function (ele) { queryParam += ele.name + "=" + encodeURIComponent(ele.value) + '&'; }); var gotoUrl = document.querySelector("#ali-form").getAttribute('action') + '?' + queryParam; _AP.pay(gotoUrl); return false; }, false); btn.click(); </script> </body> </html>
后记
Lesezeichen
25. Hohe Parallelität, großer Datenverkehr
<br/>
26. Der Unterschied zwischen MySQL und NoSQL
NoSQL oder relationale Datenbank
27. Backend-Struktur-Servitisierung
Übersicht
Datenmodell:
Datenklassifizierung
Halbstrukturierte Daten
Strukturierte Daten
Unstrukturierte Daten
Halbstrukturierte Daten
储存方式
化解为结构化数据
用XML格式来组织并保存到CLOB字段中
28. 单链表翻转
单链表反转总结篇
1 定义
class ListNode {
int val;
ListNode next;
ListNode(int x) {
val = x;
next = null;
}
}2 方法1:就地反转法
2.1 思路
2.2 解释
1初始状态
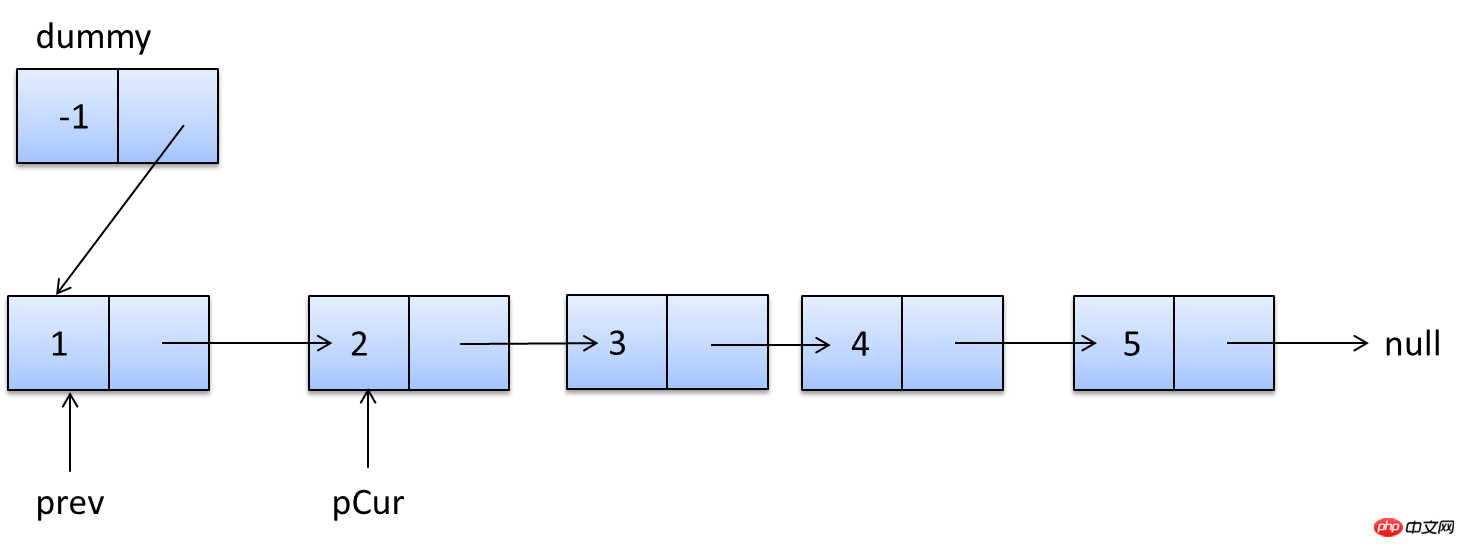
2 过程
1 prev.next = pCur.next;
2 pCur.next = dummy.next;
3 dummy.next = pCur;
4 pCur = prev.next;
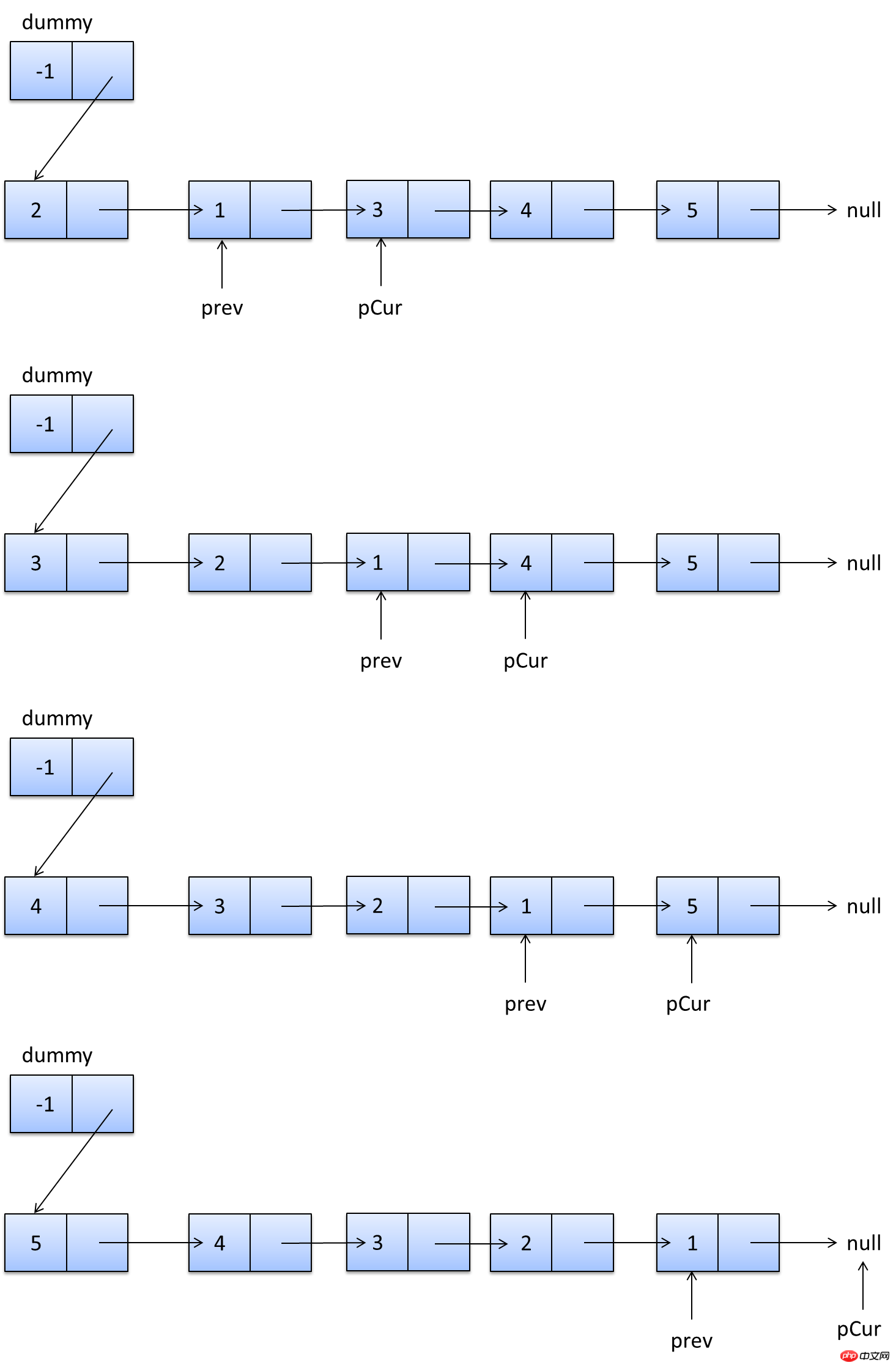
3 循环条件
pCur is not null
2.3 代码
1 // 1.就地反转法
2 public ListNode reverseList1(ListNode head) {
3 if (head == null)
4 return head;
5 ListNode dummy = new ListNode(-1);
6 dummy.next = head;
7 ListNode prev = dummy.next;
8 ListNode pCur = prev.next;
9 while (pCur != null) {
10 prev.next = pCur.next;
11 pCur.next = dummy.next;
12 dummy.next = pCur;
13 pCur = prev.next;
14 }
15 return dummy.next;
16 }2.4 总结
3 方法2:新建链表,头节点插入法
3.1 思路
3.2 解释
1 初始状态
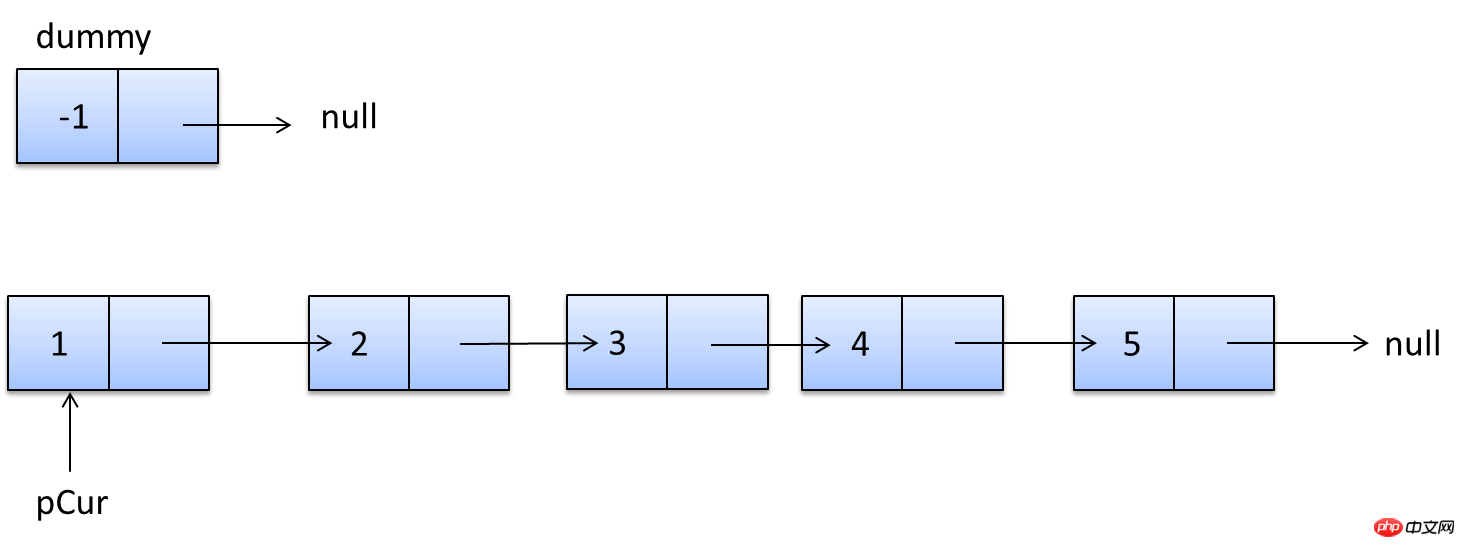
2 过程
1 pNex = pCur.next
2 pCur.next = dummy.next
3 dummy.next = pCur
4 pCur = pNex
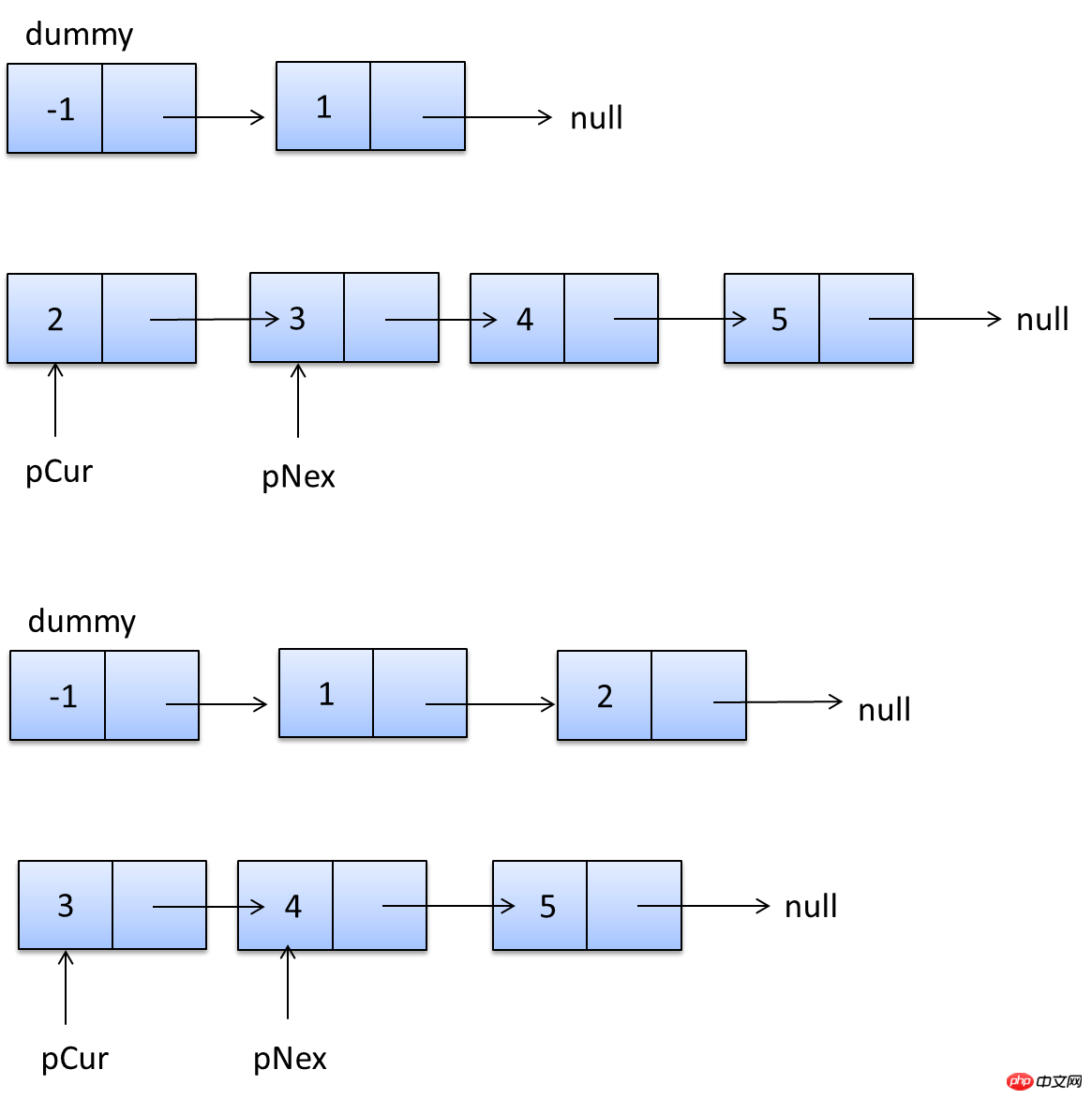
3 循环条件
pCur is not null
3.3 代码
1 // 2.新建链表,头节点插入法
2 public ListNode reverseList2(ListNode head) {
3 ListNode dummy = new ListNode(-1);
4 ListNode pCur = head;
5 while (pCur != null) {
6 ListNode pNex = pCur.next;
7 pCur.next = dummy.next;
8 dummy.next = pCur;
9 pCur = pNex;
10 }
11 return dummy.next;
12 }<br/>29. 最擅长的php
30. 索引
MySQL索引优化
一、索引类型
CREATE TABLE index_table (
id BIGINT NOT NULL auto_increment COMMENT '主键',
NAME VARCHAR (10) COMMENT '姓名',
age INT COMMENT '年龄',
phoneNum CHAR (11) COMMENT '手机号',
PRIMARY KEY (id) ) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8;
下图是Col2为索引列,记录与B树结构的对应图,仅供参考:
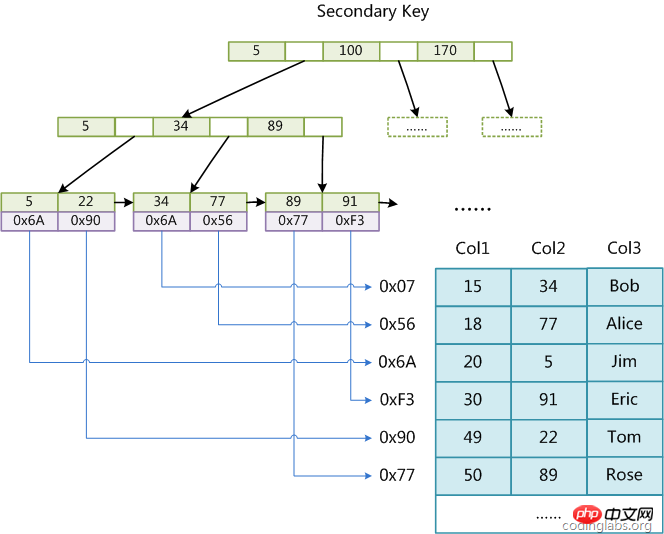
1、普通索引
------直接创建索引 create index index_name on index_table(name);
2、唯一索引
---------直接创建唯一索引 create UNIQUE index index_phoneNum on index_table(phoneNum);
3、主键
4、多列索引
-------直接创建组合索引 create index index_union on index_table(name,age,phoneNum);
二、索引优化
1、选择索引列
SELECT age----不使用索引 FROM index_union WHERE NAME = 'xiaoming'---考虑使用索引 AND phoneNum = '18668247687';---考虑使用索引
2、最左前缀原则
3、like的使用
4、不能使用索引说明
5、order by
1 select test_index where id = 3 order by id desc;1 select test_index where id = 3 order by name desc;31. Einkaufszentrumsstruktur
1 Gründe für E-Commerce-Fälle
大型门户一般是新闻类信息,可以使用CDN,静态化等方式优化, 开心网等交互性比较多,可能会引入更多的NOSQL,分布式缓存,使用高性能的通信框架等. E-Commerce-Websites weisen die Merkmale der beiden oben genannten Kategorien auf, 比如产品详情可以采用CDN,静态化,交互性高的需要采用NOSQL等技术. Daher nutzen wir E-Commerce-Websites als Fallbeispiel für die Analyse. 2 E-Commerce-Website-Anforderungen
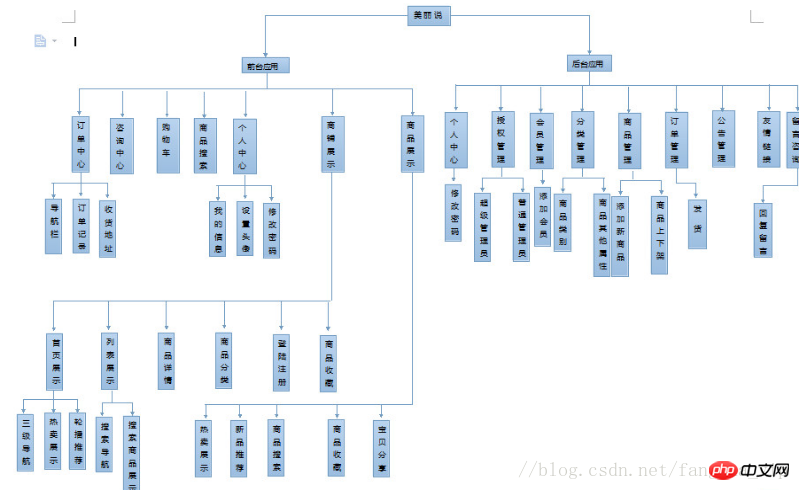
推荐大家使用需求功能矩阵,进行需求描述

. Zumindest sieht es unten so aus.

一般都会采用集群的方式,进行高可用设计  (2) Verwenden Sie den Datenbank-Aktiv- und Sicherungsmodus, um Datensicherung und hohe Verfügbarkeit zu erreichen
(2) Verwenden Sie den Datenbank-Aktiv- und Sicherungsmodus, um Datensicherung und hohe Verfügbarkeit zu erreichen Anzahl der registrierten Benutzer – durchschnittliches tägliches UV-Volumen – tägliches PV-Volumen – tägliches Parallelitätsvolumen
Ein Webserver unterstützt 300 gleichzeitige Berechnungen pro Sekunde. Normalerweise werden 10 Server benötigt (ungefähr gleich); [Tomcat-Standardkonfiguration ist 150]
系统CPU一般维持在70%左右的水平,高峰期达到90%的水平,是不浪费资源,并比较稳定的Nach der obigen Einschätzung gibt es mehrere Probleme:
Eine große Anzahl von Servern muss bereitgestellt werden, und Berechnungen in Spitzenzeiten erfordern möglicherweise die Bereitstellung von 30 Webservern. Darüber hinaus werden diese dreißig Server nur bei Flash-Sales und Veranstaltungen genutzt, was eine Menge Verschwendung darstellt.
Geschäftsaufteilung
6.1 Geschäftsaufteilung
, unterteilt in Produkt-Subsystem, Einkaufs-Subsystem, Zahlungs-Subsystem, Bewertungs-Subsystem, Kundendienst-Subsystem und Schnittstellen-Subsystem (Verbindung mit externen Systemen wie Einkauf, Verkauf, Inventar, SMS usw.). 根据业务属性进行垂直切分根据业务子系统进行等级定义业务拆分作用等级定义作用Architekturdiagramm nach der Aufteilung:  Referenzbereitstellungsplan 2:
Referenzbereitstellungsplan 2: 
Bereitstellen der Anwendungen nach der Geschäftsaufteilung separat, und die Anwendungen kommunizieren direkt über RPC aus der Ferne 分布式部署:集群部署:负载均衡: Architekturdiagramm nach der Clusterbereitstellung: 
6.3 Mehrstufiger Cache
一般可分为两类本地缓存和分布式缓存. In diesem Fall wird die Cache-Methode der zweiten Ebene zum Entwerfen des Caches verwendet. Der Cache der ersten Ebene ist ein lokaler Cache und der Cache der zweiten Ebene ist ein verteilter Cache. (Es gibt auch Seiten-Caching, Fragment-Caching usw., bei denen es sich um feinkörnigere Unterteilungen handelt) 一级缓存,缓存数据字典,和常用热点数据等基本不可变/有规则变化的信息,二级缓存缓存需要的所有缓存. Wenn der Cache der ersten Ebene abläuft oder nicht verfügbar ist, wird auf die Daten im Cache der zweiten Ebene zugegriffen. Wenn kein Second-Level-Cache vorhanden ist, wird auf die Datenbank zugegriffen. 
Nach der unabhängigen Bereitstellung treten zwangsläufig Probleme bei der Sitzungsverwaltung auf .
. E-Commerce-Websites werden im Allgemeinen mithilfe verteilter Sitzungen implementiert. 一般可采用Session同步,Cookies,分布式Session方式Ein weiterer Schritt kann darin bestehen, ein vollständiges Single-Sign-On- oder Kontoverwaltungssystem basierend auf verteilten Sitzungen einzurichten.  Prozessbeschreibung:
Prozessbeschreibung: .
高可用,高性能一般采用冗余的方式进行系统设计一般有两种方式读写分离和分库分表读写分离:一般解决读比例远大于写比例的场景,可采用一主一备,一主多备或多主多备方式。
. Beispielsweise kann das Mitgliedschaftssubsystem in diesem Fall als öffentlicher Dienst extrahiert werden. 将多个子系统公用的功能/模块,进行抽取,作为公用服务使用
(1) Nachdem der Benutzer eine Bestellung aufgegeben hat, schreiben Sie diese in die Nachrichtenwarteschlange und senden Sie sie dann direkt an den Client zurück.
消息队列可以解决子系统/模块之间的耦合,实现异步,高可用,高性能的系统建议可以研究下Rabbit MQ。6.8 其他架构(技术)
应用集群,多级缓存,单点登录,数据库集群,服务化,消息队列外。还有CDN,反向代理,分布式文件系统,大数据处理等系统。7 架构总结

32. app
34. AB
前沿
--PV(访问量):Page View, 即页面浏览量或点击量,用户每次刷新即被计算一次。 --UV(独立访客):Unique Visitor,访问您网站的一台电脑客户端为一个访客。00:00-24:00内相同的客户端只会被计算一次。 --IP(独立IP):指独立IP数。00:00-24:00内相同IP地址之被计算一次。
安装
ab的基本参数
-c 并发的请求数 -n 要执行的请求总数 -k 启用keep-alive功能(开启的话,请求会快一些) -H 一个使用冒号分隔的head报文头的附加信息 -t 执行这次测试所用的时间
ab基本语法
ab -c 5 -n 60 -H "Referer: http://baidu.com" -H "Connection: close" http://blog.csdn.net /XXXXXX/article/details/XXXXXXX
ab -c 100 -n 100 -H "User-Agent: Mozilla/5.0 (Windows NT 6.1; rv:3 8.0) Gecko/20100101 Firefox/38.0" -e "E:\ab.csv" http://blog.csdn.net/uxxxxx/artic le/details/xxxx
ab执行结果分析

总结
linux 下ab压力测试
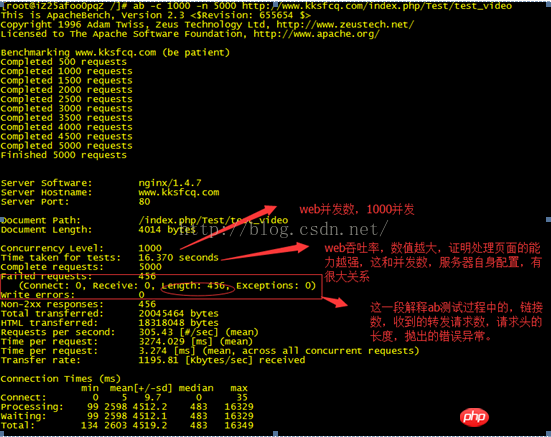
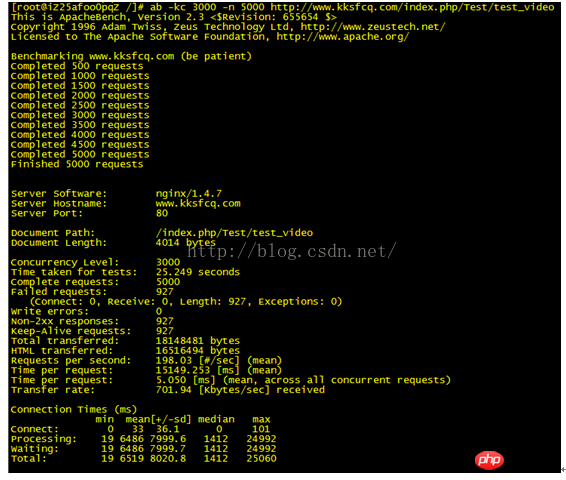 <br/>
<br/>35. Langsame Abfrage
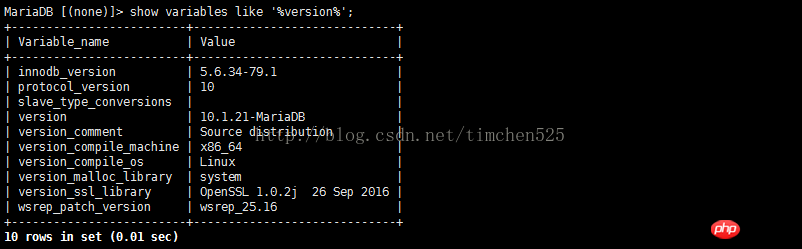 <br/>
<br/> <br/>
<br/> <br/>
<br/> <br/>
<br/>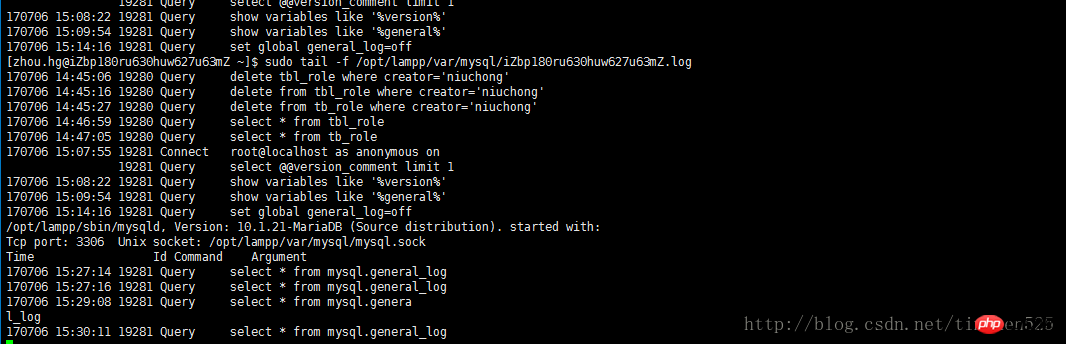 <br/>
<br/>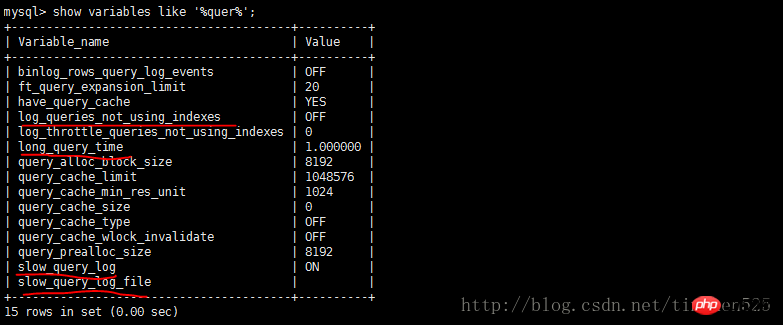 <br/>
<br/> <br/>
<br/> <br/>
<br/>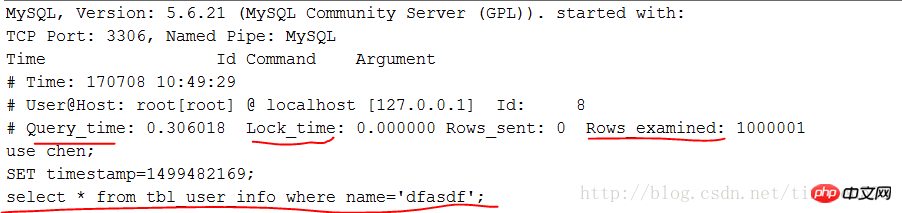 <br/>
<br/>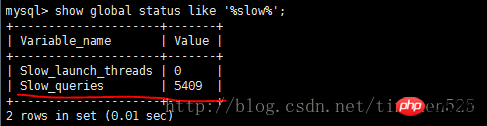 <br/>
<br/> <br/>Die oben genannten Parameter haben folgende Bedeutung:
<br/>Die oben genannten Parameter haben folgende Bedeutung: Open-Source-Framework (TP, CI, Laravel, Yii) Nachdruck um 13:36:47
37. 命名空间
PHP命名空间 namespace 及导入 use 的用法
<?php
echo 111;
//由于namespace前有代码而报错
namespace Teacher;
class Person{
function __construct(){
echo 'Please study!';
}
}<?php
namespace Newer;
require_once './1.php';
new Person();
//报错,找不到Person;
new \Person();
//输出 I am tow!;
<?php
namespace New;
require_once './2.php';
new Person();
//报错,(当前空间)找不到
Person; new \Person();
//报错,(公共空间)找不到
Person; new \Two\Person();
//输出 I am tow!;
namespace School\Parents;
class Man{
function __construct(){
echo 'Listen to teachers!<br/>';
}
}
namespace School\Teacher;
class Person{
function __construct(){
echo 'Please study!<br/>';
}
}
namespace School\Student;
class Person{
function __construct(){
echo 'I want to play!<br/>';
}
}
new Person();
//输出I want to play!
new \School\Teacher\Person();
//输出Please study!
new Teacher\Person();
//报错 ----------
use School\Teacher;
new Teacher\Person();
//输出Please study! ----------
use School\Teacher as Tc;
new Tc\Person();
//输出Please study! ----------
use \School\Teacher\Person;
new Person();
//报错 ----------
use \School\Parent\Man;
new Man();
//报错
 So öffnen Sie eine PHP-Datei
So öffnen Sie eine PHP-Datei
 So entfernen Sie die ersten paar Elemente eines Arrays in PHP
So entfernen Sie die ersten paar Elemente eines Arrays in PHP
 Was tun, wenn die PHP-Deserialisierung fehlschlägt?
Was tun, wenn die PHP-Deserialisierung fehlschlägt?
 So verbinden Sie PHP mit der MSSQL-Datenbank
So verbinden Sie PHP mit der MSSQL-Datenbank
 So verbinden Sie PHP mit der MSSQL-Datenbank
So verbinden Sie PHP mit der MSSQL-Datenbank
 So laden Sie HTML hoch
So laden Sie HTML hoch
 So lösen Sie verstümmelte Zeichen in PHP
So lösen Sie verstümmelte Zeichen in PHP
 So öffnen Sie PHP-Dateien auf einem Mobiltelefon
So öffnen Sie PHP-Dateien auf einem Mobiltelefon








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



