

In diesem Artikel wird ausführlich erläutert, wie Python3 + Dlib Gesichtserkennung und Emotionsanalyse mithilfe spezifischer Codes und Schritte implementiert. Freunde in Not können sich darauf beziehen.
1. Einführung
Was ich tun möchte, ist eine Ausdrucks-(Emotions-)Analyse basierend auf Gesichtserkennung. Ich habe gesehen, dass es im Internet viele Open-Source-Bibliotheken gibt, was die Entwicklung sehr erleichtert. Für die Gesichtserkennung und Feature-Kalibrierung habe ich mich für die derzeit häufiger genutzte dlib-Bibliothek entschieden. Die Verwendung von Python verkürzt auch den Entwicklungszyklus.
Die Einführung zu dlib auf der offiziellen Website lautet: Dlib enthält eine breite Palette von Algorithmen für maschinelles Lernen. Alle sind hochmodular, schnell ausführbar und über eine saubere und moderne C++-API äußerst einfach zu verwenden. Es wird in einer Vielzahl von Anwendungen eingesetzt, darunter Robotik, eingebettete Geräte, Mobiltelefone und große Hochleistungscomputerumgebungen.
Obwohl die Anwendungen relativ hochwertig sind, ist es durchaus interessant, eine kleine Software zur Stimmungsanalyse auf Ihrem PC zu erstellen.
Gestalten Sie die Identifikationsmethode nach Ihren eigenen Vorstellungen und Vorstellungen. Keras, das derzeit ebenfalls sehr beliebt ist, scheint Veränderungen der Mundform als Indikator für die emotionale Analyse zu nutzen.
Meine Idee ist, das Öffnungsverhältnis des Mundes, den Öffnungsgrad der Augen und den Neigungswinkel der Augenbrauen als drei Indikatoren für die Emotionsanalyse zu verwenden. Allerdings ist meine Berechnungsmethode aufgrund der großen Unterschiede im Aussehen der Menschen und der unterschiedlichen Gesichtszüge auch relativ einfach. Daher ist die Erkennungseffizienz nicht sehr hoch.
Erkennungsregeln:
1. Je größer der Anteil des Abstands zwischen der Mundöffnung und der Breite des Gesichtserkennungsrahmens ist, desto aufgeregter ist die Emotion. Das kann sehr glücklich sein, oder es kann extrem wütend sein.
2. Die Augenbrauen werden angehoben, je kleiner das Verhältnis zwischen den Merkmalspunkten 17-21 oder 22-26 und der Oberkante des Gesichtserkennungsrahmens ist. die Überraschung und Glück ausdrücken können. Der Neigungswinkel der Augenbrauen ist normalerweise höher. Wenn Sie wütend sind, werden Ihre Augenbrauen stärker nach unten gedrückt.
3. Schielen Sie die Augen zusammen, wenn Sie herzlich lachen, und sie werden ihre Augen weiten, wenn sie wütend oder überrascht sind.
Systemmängel: Es kann subtile Veränderungen im Ausdruck nicht erfassen und die Emotionen von Menschen wie Glück, Wut, Überraschung und Natürlichkeit nur grob beurteilen.
Systemvorteile: einfacher Aufbau und einfache Bedienung.
Anwendungsfelder: Lächeln einfangen, die Schönheit des Augenblicks einfangen, Autismus bei Kindern lindern und interaktive Spieleentwicklung.
Aufgrund der Komplexität menschlicher Emotionen können diese Ausdrücke die inneren emotionalen Schwankungen einer Person nicht vollständig darstellen. Um die Genauigkeit der Beurteilung zu verbessern, sind umfassende Auswertungen wie Herzfrequenzerkennung und Sprachverarbeitung erforderlich.
2. Einrichtung der Entwicklungsumgebung:
1. Installieren Sie VS2015, da die neueste Version von dlib-19.10 diese Version von vscode erfordert
2. Installation opencv (Installation im WHL-Modus):
Laden Sie die erforderliche Version der WHL-Datei von Pythonlibs herunter, z. B. (opencv_python?3.3.0+contrib?cp36?cp36m?win_amd64.whl)
und verwenden Sie dann die lokale Pip-Installation. Achten Sie auf den Speicherort der Datei (z. B. C: downloadxxx.whl)
3. Installieren Sie dlib (Installation im WHL-Modus):
Laden Sie hier verschiedene Versionen der WHL-Dateien von dlib herunter. Öffnen Sie dann cmd im Stammverzeichnis und installieren Sie es direkt.
Aber um zu lernen, verschiedene Python-Beispielprogramme in dlib zu verwenden, müssen Sie noch ein dlib-komprimiertes Paket herunterladen.
Besuchen Sie zum Herunterladen direkt die offizielle Website von dlib: http://dlib.net/ml.html
Whl-Dateien verschiedener Versionen von dlib: https://pypi.python .org/simple/dlib/4. Wenn Sie die Gesichtsmodell-Feature-Kalibrierung verwenden möchten, benötigen Sie auch einen Gesichtsform-Prädiktor. Dies kann mit Ihren eigenen Fotos trainiert werden, oder Sie können den dlib-Autor verwenden Ein gut trainierter Prädiktor:
Zum Herunterladen klicken: http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2
3. Implementierungsideen
Verwenden Sie zunächst dlib für die Gesichtserkennung:)
Instanziieren Sie dann einen Shape_Predictor Objekt, verwenden Sie den dlib-Autor, um den Gesichtsmerkmalsdetektor zu trainieren und die Merkmalspunkte des Gesichts zu kalibrieren.import cv2
import dlib
from skimage import io
# 使用特征提取器get_frontal_face_detector
detector = dlib.get_frontal_face_detector()
# dlib的68点模型,使用作者训练好的特征预测器
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# 图片所在路径
img = io.imread("2.jpg")
# 生成dlib的图像窗口
win = dlib.image_window()
win.clear_overlay()
win.set_image(img)
# 特征提取器的实例化
dets = detector(img, 1)
print("人脸数:", len(dets))
for k, d in enumerate(dets):
print("第", k+1, "个人脸d的坐标:",
"left:", d.left(),
"right:", d.right(),
"top:", d.top(),
"bottom:", d.bottom())
width = d.right() - d.left()
heigth = d.bottom() - d.top()
print('人脸面积为:',(width*heigth))Verwenden Sie beim Kalibrieren die Kreismethode von opencv, um den Koordinaten der Feature-Punkte ein Wasserzeichen hinzuzufügen. Der Inhalt ist die Seriennummer und Position der Feature-Punkte.
Zu diesem Zeitpunkt wurden die Informationen von 68 Merkmalspunkten erhalten. Als Nächstes muss eine umfassende Berechnung basierend auf den Koordinateninformationen dieser 68 Merkmalspunkte als Beurteilungsindikator für jeden Ausdruck durchgeführt werden . # 利用预测器预测
shape = predictor(img, d)
# 标出68个点的位置
for i in range(68):
cv2.circle(img, (shape.part(i).x, shape.part(i).y), 4, (0, 255, 0), -1, 8)
cv2.putText(img, str(i), (shape.part(i).x, shape.part(i).y), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 255, 255))
# 显示一下处理的图片,然后销毁窗口
cv2.imshow('face', img)
cv2.waitKey(0) Berechnen Sie anhand der oben genannten Beurteilungsindikatoren zunächst das Öffnungsverhältnis des Mundes aufgrund der Entfernung der Person von der Kamera und der Größe des Gesichtserkennungsrahmens ist unterschiedlich, daher wird das Verhältnis als Beurteilungsindex gewählt.
Berechnen Sie anhand der oben genannten Beurteilungsindikatoren zunächst das Öffnungsverhältnis des Mundes aufgrund der Entfernung der Person von der Kamera und der Größe des Gesichtserkennungsrahmens ist unterschiedlich, daher wird das Verhältnis als Beurteilungsindex gewählt.
Analysieren Sie mehrere Fotos von glücklichen Gesichtern, bevor Sie einen Standardwert für den Indikator auswählen. Berechnen Sie das durchschnittliche Mundöffnungsverhältnis, wenn Sie glücklich sind.
Das Folgende ist eine Datenverarbeitungsmethode zum Abfangen menschlicher Augenbrauen, die an den fünf Merkmalspunkten auf der linken Augenbraue durchgeführt wird, um eine lineare Funktionsgerade anzupassen. Die Steigung der angepassten geraden Linie wird ungefähr verwendet stellen den Neigungsgrad der Augenbrauen dar.
# 眉毛
brow_sum = 0 # 高度之和
frown_sum = 0 # 两边眉毛距离之和
for j in range(17,21):
brow_sum+= (shape.part(j).y - d.top()) + (shape.part(j+5).y- d.top())
frown_sum+= shape.part(j+5).x - shape.part(j).x
line_brow_x.append(shape.part(j).x)
line_brow_y.append(shape.part(j).y)
self.excel_brow_hight.append(round((brow_sum/10)/self.face_width,3))
self.excel_brow_width.append(round((frown_sum/5)/self.face_width,3))
brow_hight[0]+= (brow_sum/10)/self.face_width # 眉毛高度占比
brow_width[0]+= (frown_sum/5)/self.face_width # 眉毛距离占比
tempx = np.array(line_brow_x)
tempy = np.array(line_brow_y)
z1 = np.polyfit(tempx, tempy, 1) # 拟合成一次直线
self.brow_k = -round(z1[0], 3) # 拟合出曲线的斜率和实际眉毛的倾斜方向是相反的我计算了25个人脸的开心表情的嘴巴张开比例、嘴巴宽度、眼睛张开程度、眉毛倾斜程度,导入excel表格生成折线图:

通过折线图能很明显的看出什么参数可以使用,什么参数的可信度不高,什么参数在那个范围内可以作为一个指标。
同样的方法,计算人愤怒、惊讶、自然时的数据折线图。
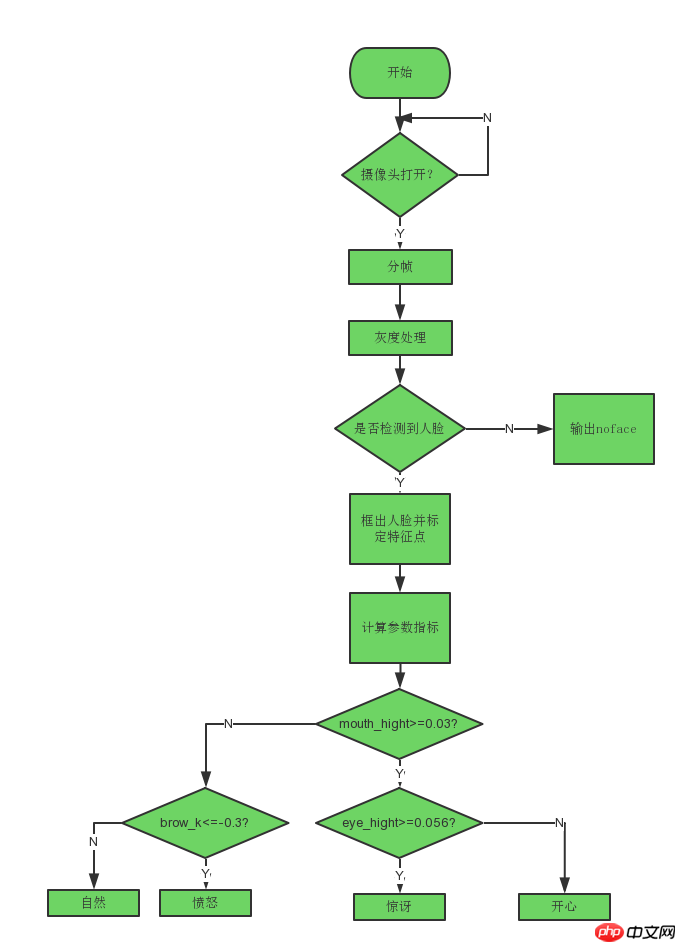
通过对多个不同表情数据的分析,得出每个指标的参考值,可以写出简单的表情分类标准:
# 分情况讨论
# 张嘴,可能是开心或者惊讶
if round(mouth_higth >= 0.03):
if eye_hight >= 0.056:
cv2.putText(im_rd, "amazing", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
else:
cv2.putText(im_rd, "happy", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
# 没有张嘴,可能是正常和生气
else:
if self.brow_k <= -0.3:
cv2.putText(im_rd, "angry", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)
else:
cv2.putText(im_rd, "nature", (d.left(), d.bottom() + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.8,
(0, 0, 255), 2, 4)五、实际运行效果:

识别之后:

Das obige ist der detaillierte Inhalt vonPython3+dlib implementiert Gesichtserkennung und Emotionsanalyse. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Einführung in den Öffnungsort von Windows 10
Einführung in den Öffnungsort von Windows 10
 Was sind die DDoS-Angriffstools?
Was sind die DDoS-Angriffstools?
 Was soll ich tun, wenn iS nicht starten kann?
Was soll ich tun, wenn iS nicht starten kann?
 Was sind die gängigen Testtechniken?
Was sind die gängigen Testtechniken?
 MySQL-Ausnahmelösung
MySQL-Ausnahmelösung
 Was ist der Unterschied zwischen Blockieren und Löschen bei WeChat?
Was ist der Unterschied zwischen Blockieren und Löschen bei WeChat?
 So lernen Sie die Python-Programmierung von Grund auf
So lernen Sie die Python-Programmierung von Grund auf
 Auf welcher Plattform kann ich Ripple-Coins kaufen?
Auf welcher Plattform kann ich Ripple-Coins kaufen?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



