
 Backend-Entwicklung
Python-Tutorial
Beispiel für die Verwendung von Python zur Ausgabe von PDF in TXT
Backend-Entwicklung
Python-Tutorial
Beispiel für die Verwendung von Python zur Ausgabe von PDF in TXT
Beispiel für die Verwendung von Python zur Ausgabe von PDF in TXT

Das Folgende ist ein Beispiel für die Verwendung von Python zur Ausgabe von PDF-Dateien in TXT. Es hat einen guten Referenzwert und ich hoffe, dass es für alle hilfreich ist. Lass uns einen Blick darauf werfen
Ein Klassenkamerad hat mich vor einer Woche danach gefragt. Da ich schon einmal am Huawei-Wettbewerb teilgenommen habe, habe ich mir den Wettbewerb angesehen und herausgefunden, dass ich das pdfminer-Paket verwenden muss. Also habe ich es installiert und der Installationsprozess war sehr einfach:
sudo pip install pdfminer;
Es gab keine Fehler in der Mitte. Wie man es nennt, ich habe die PDFMiner-Bibliothek nicht sehr gut studiert, also habe ich Baidu gestartet ...
Offizielle Dokumentation: http://www .unixuser .org/~euske/python/pdfminer/index.html
Komplett in Python geschrieben. (Gilt für Version 2.4 oder neuer)
PDF-Dokumente analysieren, analysieren und konvertieren.
Unterstützung der PDF-1.7-Spezifikation. (Fast)
CJK-Sprache und vertikale Schreibskriptunterstützung.
Unterstützung für verschiedene Schriftarten (Type1, TrueType, Type3 und CID).
Basisverschlüsselung (RC4)-Unterstützung.
PDF- und HTML-Konvertierung.
Extraktion der Gliederung (TOC).
Tag-Inhaltsextraktion.
Erstellen Sie das ursprüngliche Layout neu, indem Sie Textblöcke gruppieren.
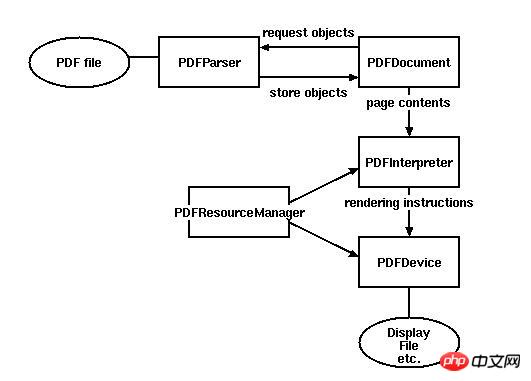
Einige Grundklassen
PDFParser: Daten aus einer Datei abrufen
PDFDocument: Die erhaltenen Daten speichern, und PDFParser ist interlated
PDFPageInterpreter verarbeitet den Seiteninhalt
PDFDevice übersetzt ihn in das von Ihnen benötigte Format
PDFResourceManager wird zum Speichern gemeinsamer Ressourcen wie Schriftarten oder Bilder verwendet.
Einfache Implementierung
Test.pdf lesen und als Output.txt ausgeben:
# -*- coding: utf-8 -*-
from pdfminer.pdfparser import PDFParser
from pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
from pdfminer.layout import *
from pdfminer.converter import PDFPageAggregator
import os
fp = open('test.pdf', 'rb')
#来创建一个pdf文档分析器
parser = PDFParser(fp)
#创建一个PDF文档对象存储文档结构
document = PDFDocument(parser)
# 检查文件是否允许文本提取
if not document.is_extractable:
raise PDFTextExtractionNotAllowed
else:
# 创建一个PDF资源管理器对象来存储共赏资源
rsrcmgr=PDFResourceManager()
# 设定参数进行分析
laparams=LAParams()
# 创建一个PDF设备对象
# device=PDFDevice(rsrcmgr)
device=PDFPageAggregator(rsrcmgr,laparams=laparams)
# 创建一个PDF解释器对象
interpreter=PDFPageInterpreter(rsrcmgr,device)
# 处理每一页
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
# 接受该页面的LTPage对象
layout=device.get_result()
for x in layout:
if(isinstance(x,LTTextBoxHorizontal)):
with open('output.txt','a') as f:
f.write(x.get_text().encode('utf-8')+'\n')Verwandte Empfehlungen:
Python-Methode zum Konvertieren von PDF in Bilder
Das obige ist der detaillierte Inhalt vonBeispiel für die Verwendung von Python zur Ausgabe von PDF in TXT. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Minio-Objektspeicherung: Hochleistungs-Bereitstellung im Rahmen von CentOS System Minio ist ein hochleistungsfähiges, verteiltes Objektspeichersystem, das auf der GO-Sprache entwickelt wurde und mit Amazons3 kompatibel ist. Es unterstützt eine Vielzahl von Kundensprachen, darunter Java, Python, JavaScript und Go. In diesem Artikel wird kurz die Installation und Kompatibilität von Minio zu CentOS -Systemen vorgestellt. CentOS -Versionskompatibilitätsminio wurde in mehreren CentOS -Versionen verifiziert, einschließlich, aber nicht beschränkt auf: CentOS7.9: Bietet einen vollständigen Installationshandbuch für die Clusterkonfiguration, die Umgebungsvorbereitung, die Einstellungen von Konfigurationsdateien, eine Festplattenpartitionierung und Mini
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
 So wählen Sie die Pytorch -Version auf CentOS aus
Apr 14, 2025 pm 06:51 PM
So wählen Sie die Pytorch -Version auf CentOS aus
Apr 14, 2025 pm 06:51 PM
Bei der Installation von PyTorch am CentOS -System müssen Sie die entsprechende Version sorgfältig auswählen und die folgenden Schlüsselfaktoren berücksichtigen: 1. Kompatibilität der Systemumgebung: Betriebssystem: Es wird empfohlen, CentOS7 oder höher zu verwenden. CUDA und CUDNN: Pytorch -Version und CUDA -Version sind eng miteinander verbunden. Beispielsweise erfordert Pytorch1.9.0 CUDA11.1, während Pytorch2.0.1 CUDA11.3 erfordert. Die Cudnn -Version muss auch mit der CUDA -Version übereinstimmen. Bestimmen Sie vor der Auswahl der Pytorch -Version unbedingt, dass kompatible CUDA- und CUDNN -Versionen installiert wurden. Python -Version: Pytorch Official Branch
 So aktualisieren Sie Pytorch auf die neueste Version von CentOS
Apr 14, 2025 pm 06:15 PM
So aktualisieren Sie Pytorch auf die neueste Version von CentOS
Apr 14, 2025 pm 06:15 PM
Das Aktualisieren von PyTorch auf der neuesten Version von CentOS kann die folgenden Schritte ausführen: Methode 1: Aktualisieren von PIP mit PIP: Stellen Sie zunächst sicher, dass Ihr PIP die neueste Version ist, da ältere Versionen von PIP möglicherweise nicht in der Lage sind, die neueste Version von PyTorch ordnungsgemäß zu installieren. Pipinstall-upgradePip Die alte Version von Pytorch (falls installiert): PipuninstallTorChTorChVisionTorChaudio-Installation Neueste
