

Dieser Artikel stellt hauptsächlich Beispiele für die Verwendung von Python zur Verarbeitung von MS Word vor. Jetzt kann ich ihn mit Ihnen teilen.
Verwenden von Python-Tools zum Lesen und Schreiben von MS Word-Dateien (docx- und doc-Dateien), hauptsächlich unter Verwendung des Pakets python-docx. In diesem Artikel werden einige häufig verwendete Vorgänge beschrieben und ein Beispiel vervollständigt, um Ihnen den schnellen Einstieg zu erleichtern.
Installation
pyhton muss das python-docx-Paket verwenden, um docx-Dateien zu verarbeiten Das pip-Tool wird in Python im Ordner „Scripts“ unter dem Pfad
pip install python-docx
installiert. Natürlich können Sie auch easy_install oder manuelle Installation
<🎜 wählen >Dateiinhalt schreiben
Hier geben wir direkt ein Beispiel und extrahieren nützliche Inhalte entsprechend Ihren eigenen Bedürfnissen#coding=utf-8 from docx import Document from docx.shared import Pt from docx.shared import Inches from docx.oxml.ns import qn #打开文档 document = Document() #加入不同等级的标题 document.add_heading(u'MS WORD写入测试',0) document.add_heading(u'一级标题',1) document.add_heading(u'二级标题',2) #添加文本 paragraph = document.add_paragraph(u'我们在做文本测试!') #设置字号 run = paragraph.add_run(u'设置字号、') run.font.size = Pt(24) #设置字体 run = paragraph.add_run('Set Font,') run.font.name = 'Consolas' #设置中文字体 run = paragraph.add_run(u'设置中文字体、') run.font.name=u'宋体' r = run._element r.rPr.rFonts.set(qn('w:eastAsia'), u'宋体') #设置斜体 run = paragraph.add_run(u'斜体、') run.italic = True #设置粗体 run = paragraph.add_run(u'粗体').bold = True #增加引用 document.add_paragraph('Intense quote', style='Intense Quote') #增加无序列表 document.add_paragraph( u'无序列表元素1', style='List Bullet' ) document.add_paragraph( u'无序列表元素2', style='List Bullet' ) #增加有序列表 document.add_paragraph( u'有序列表元素1', style='List Number' ) document.add_paragraph( u'有序列表元素2', style='List Number' ) #增加图像(此处用到图像image.bmp,请自行添加脚本所在目录中) document.add_picture('image.bmp', width=Inches(1.25)) #增加表格 table = document.add_table(rows=1, cols=3) hdr_cells = table.rows[0].cells hdr_cells[0].text = 'Name' hdr_cells[1].text = 'Id' hdr_cells[2].text = 'Desc' #再增加3行表格元素 for i in xrange(3): row_cells = table.add_row().cells row_cells[0].text = 'test'+str(i) row_cells[1].text = str(i) row_cells[2].text = 'desc'+str(i) #增加分页 document.add_page_break() #保存文件 document.save(u'测试.docx')
Der von diesem Code generierte Dokumentstil ist wie folgt

Dateiinhalt lesen
#coding=utf-8 from docx import Document #打开文档 document = Document(u'测试.docx') #读取每段资料 l = [ paragraph.text.encode('gb2312') for paragraph in document.paragraphs]; #输出并观察结果,也可以通过其他手段处理文本即可 for i in l: print i #读取表格材料,并输出结果 tables = [table for table in document.tables]; for table in tables: for row in table.rows: for cell in row.cells: print cell.text.encode('gb2312'),'\t', print print '\n'
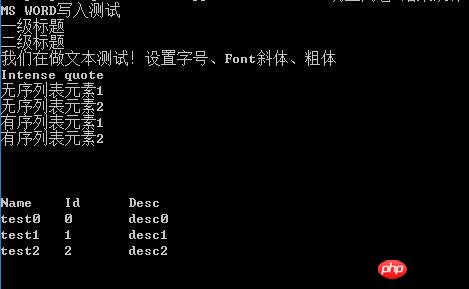
Hinweis: Hier verwenden wir zum Lesen die GB2312-Codierung, hauptsächlich um das Lesen und Sicherstellen sicherzustellen schreibe Chinesisch richtig. Im Allgemeinen wird die UTF-8-Kodierung verwendet. Darüber hinaus kann es bei der Verarbeitung von docx-Dateien zu Problemen kommen. Wenn eine große Anzahl von doc-Dateien vorhanden ist, empfiehlt es sich, die doc-Dateien zunächst stapelweise in docx-Dateien zu konvertieren 🎜>Verwandte Empfehlungen:
Das obige ist der detaillierte Inhalt vonBeispiele für die Verwendung von Python zur Verarbeitung von MS Word. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Python-Entwicklungstools
Python-Entwicklungstools
 Python in ausführbare Datei gepackt
Python in ausführbare Datei gepackt
 So ändern Sie die Hintergrundfarbe eines Wortes in Weiß
So ändern Sie die Hintergrundfarbe eines Wortes in Weiß
 So löschen Sie die letzte leere Seite in Word
So löschen Sie die letzte leere Seite in Word
 was Python kann
was Python kann
 Warum kann ich die letzte leere Seite in Word nicht löschen?
Warum kann ich die letzte leere Seite in Word nicht löschen?
 Eine einzelne Word-Seite ändert die Papierausrichtung
Eine einzelne Word-Seite ändert die Papierausrichtung
 So verwenden Sie das Format in Python
So verwenden Sie das Format in Python








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



