
Dieses Mal werde ich Ihnen eine detaillierte Erklärung der Schritte für die Knotensimulation der Anmeldung und Erfassung basierend auf dem Puppenspieler geben Praktischer Fall, werfen wir einen Blick darauf.
Über HeatmapIn der Website-Analysebranche kann die Website-Heatmap das Betriebsverhalten des Benutzers auf der Website gut widerspiegeln. Detaillierte Analyse Benutzer Präferenzen, gezielte Optimierung der Website, ein Beispiel einer Heatmap (von ptengine)
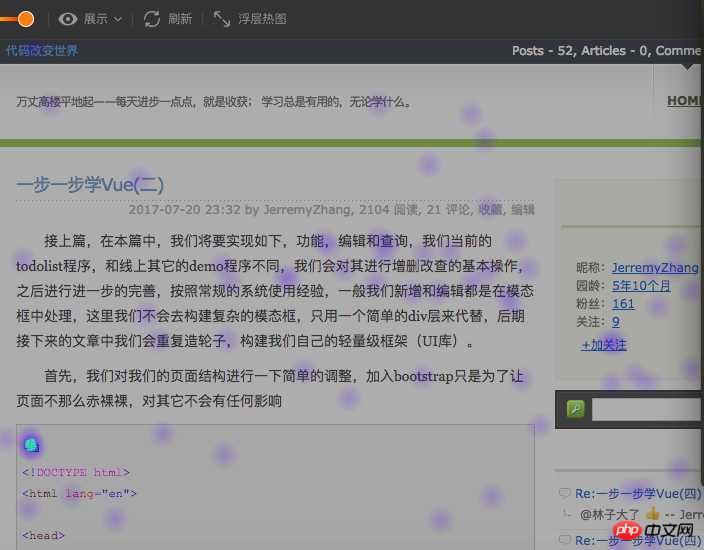 Auf dem Bild oben können Sie deutlich erkennen, wo der Fokus des Benutzers liegt. Nun, das tun wir Achten Sie nicht auf die Funktion der Heatmap im Produkt. In diesem Artikel wird eine einfache Analyse und Zusammenfassung der Implementierung der Heatmap erstellt.
Auf dem Bild oben können Sie deutlich erkennen, wo der Fokus des Benutzers liegt. Nun, das tun wir Achten Sie nicht auf die Funktion der Heatmap im Produkt. In diesem Artikel wird eine einfache Analyse und Zusammenfassung der Implementierung der Heatmap erstellt.
Mainstream-Implementierungsmethoden für Heatmaps
Im Allgemeinen sind die folgenden Schritte erforderlich, um die Heatmap-Anzeige zu implementieren:1 . Erhalten Sie die Website-Seite 2. Erhalten Sie verarbeitete Benutzerdaten 3. Zeichnen Sie eine Heatmap
Dieser Artikel konzentriert sich hauptsächlich auf Stufe 1, um die gängige Implementierungsmethode zum Abrufen von Website-Seiten in einer Heatmap detailliert vorzustellen
4. Verwenden Sie iframe, um die Benutzerwebsite direkt einzubetten
5. Erfassen Sie die Benutzerseite, speichern Sie sie lokal und betten Sie lokale Ressourcen über iframe ein (die sogenannten lokalen Ressourcen gelten als Seite des Analysetools)
Es gibt jeweils zwei Vor- und Nachteile
Die erste Möglichkeit besteht darin, sie direkt in die Benutzerwebsite einzubetten. Dies unterliegt beispielsweise bestimmten Einschränkungen, wenn die Benutzerwebsite keine Iframe-Verschachtelung zulässt Um Iframe-Hijacking zu verhindern (setzen Sie meta vom Iframe des Analysetools geladen werden. Die Verwendung ist nicht unbedingt so komfortabel, da nicht alle Benutzer, die die Website erkennen und analysieren, die Website verwalten können.
Die zweite Methode besteht darin, die Website-Seite direkt auf dem lokalen Server zu erfassen und dann die auf dem lokalen Server erfasste Seite zu durchsuchen. In diesem Fall ist die Seite bereits angekommen und wir können tun, was wir wollen . Umgehen wir zunächst das Problem, dass X-FRAME-OPTIONS gleich ist, müssen wir nur das Problem der JS-Steuerung lösen. Für die erfassten Seiten können wir es durch spezielle Korrespondenz (z. B. Entfernen des entsprechenden JS-Steuerelements oder Hinzufügen) lösen Diese Methode weist jedoch auch viele Mängel auf: 1. Sie kann keine Spa-Seiten crawlen, keine Seiten crawlen, für die eine if(window.top !== window.self){ window.top.location = window.location;} Benutzeranmeldung
Hier werden wir einige Optimierungen basierend auf Puppenspielern vornehmen, um das Crawlen der aufgetretenen Probleme zu verbessern Das Crawlen von Website-Seiten optimiert hauptsächlich die folgenden zwei Seiten:
1.spa-Seite
Die Spa-Seite gilt auf der aktuellen Seite als Mainstream, aber sie ist immer für seine nicht benutzerfreundlichen Indexierungs
-Engines bekannt. Der übliche Seitencrawler ist eigentlich ein einfacher Crawler, und der Prozess beinhaltet normalerweise das Initiieren einer http-Get-Anfrage an die Website des Benutzers (sollte sein). Website-Server des Benutzers). Diese Crawling-Methode selbst weist Probleme auf. Erstens muss der Benutzerserver viele Einschränkungen für Nicht-Browser-Agenten haben, und zweitens muss die Anforderung umgangen werden Der über js im Browser gerenderte Teil kann nicht abgerufen werden (natürlich wird die js-Ausführung dieses Problem bis zu einem gewissen Grad ausgleichen). Zu diesem Zeitpunkt wird nur die Vorlage in der Heatmap abgerufen. Der Anzeigeeffekt ist sehr unfreundlich.Wenn es in diesem Fall auf Basis von Puppeteer erfolgt, wird der Prozess zu
Puppeteer startet den Browser, um die Benutzer-Website zu öffnen--> gibt das gerenderte Ergebnis zurück . Verwenden Sie einfach Pseudocode, um es wie folgt zu implementieren:const puppeteer = require('puppeteer');
async getHtml = (url) =>{
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
return await page.content();
}Seiten, die eine Anmeldung erfordern
Es gibt tatsächlich viele Situationen für Seiten, die eine Anmeldung erfordern:
需要登录才可以查看页面,如果没有登录,则跳转到login页面(各种管理系统)
对于这种类型的页面我们需要做的就是模拟登录,所谓模拟登录就是让浏览器去登录,这里需要用户提供对应网站的用户名和密码,然后我们走如下的流程:
访问用户网站-->用户网站检测到未登录跳转到login-->puppeteer控制浏览器自动登录后跳转到真正需要抓取的页面,可用如下伪代码来说明:
const puppeteer = require("puppeteer");
async autoLogin =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.waitForNavigation();
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,需要保证redirect 跳转到请求的页面
await page.waitForNavigation();
return await page.content();
}登录与否都可以查看页面,只是登录后看到内容会所有不同 (各种电商或者portal页面)
这种情况处理会比较简单一些,可以简单的认为是如下步骤:
通过puppeteer启动浏览器打开请求页面-->点击登录按钮-->输入用户名和密码登录 -->重新加载页面
基本代码如下图:
const puppeteer = require("puppeteer");
async autoLoginV2 =(url)=>{
const browser = await puppeteer.launch();
const page =await browser.newPage();
await page.goto(url);
await page.click('#btn_show_login');
//登录
await page.type('#username',"用户提供的用户名");
await page.type('#password','用户提供的密码');
await page.click('#btn_login');
//页面登录成功后,是否需要reload 根据实际情况来确定
await page.reload();
return await page.content();
}总结
明天总结吧,今天下班了。
补充(还昨天的债):基于puppeteer虽然可以很友好的抓取页面内容,但是也存在这很多的局限
1.抓取的内容为渲染后的原始html,即资源路径(css、image、javascript)等都是相对路径,保存到本地后无法正常显示,需要特殊处理(js不需要特殊处理,甚至可以移除,因为渲染的结构已经完成)
2.通过puppeteer抓取页面性能会比直接http get 性能会差一些,因为多了渲染的过程
3.同样无法保证页面的完整性,只是很大的提高了完整的概率,虽然通过page对象提供的各种wait 方法能够解决这个问题,但是网站不同,处理方式就会不同,无法复用。
相信看了本文案例你已经掌握了方法,更多精彩请关注php中文网其它相关文章!
推荐阅读:
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der Schritte zum Crawlen der Anmeldung bei der Knotensimulation basierend auf Puppenspieler. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Methode zum Öffnen der Bereichsberechtigung
Methode zum Öffnen der Bereichsberechtigung
 Was soll ich tun, wenn der IE-Browser einen Skriptfehler auslöst?
Was soll ich tun, wenn der IE-Browser einen Skriptfehler auslöst?
 So überprüfen Sie tote Links auf Ihrer Website
So überprüfen Sie tote Links auf Ihrer Website
 Einführung in die Implementierungsmethoden für Java-Spezialeffekte
Einführung in die Implementierungsmethoden für Java-Spezialeffekte
 Der Win10-Bluetooth-Schalter fehlt
Der Win10-Bluetooth-Schalter fehlt
 Einführung in Screenshot-Tastenkombinationen in Win8
Einführung in Screenshot-Tastenkombinationen in Win8
 So kaufen Sie echte Ripple-Münzen
So kaufen Sie echte Ripple-Münzen
 WeChat-Zahlungsabzugssequenz
WeChat-Zahlungsabzugssequenz








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



