
In diesem Artikel wird hauptsächlich die Implementierungsmethode für die automatische Erfassung von Cookies und die automatische Aktualisierung abgelaufener Cookies durch Webcrawler vorgestellt.
Dieser Artikel implementiert die automatische Erfassung von Cookies und die automatische Aktualisierung von Cookies, wenn Abgelaufen.
Um viele Informationen auf sozialen Netzwerken zu erhalten, müssen Sie sich anmelden. Nehmen Sie Weibo als Beispiel. Ohne Anmeldung können Sie nur die zehn besten Weibo-Beiträge von Big Vs sehen. Um eingeloggt zu bleiben, sind Cookies erforderlich. Nehmen Sie als Beispiel die Anmeldung bei www.weibo.cn:
Eingabe in Chrome: http://login.weibo.cn/login/
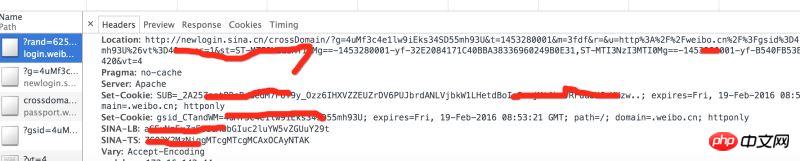
Analysesteuerung Wenn die Header-Anfrage von der Station zurückgegeben wird, werden mehrere Sätze von Cookies angezeigt, die von weibo.cn zurückgegeben werden.
Implementierungsschritte:
1. Verwenden Sie Selen, um sich automatisch anzumelden, um Cookies zu erhalten und sie in einer Datei zu speichern >2. Lesen Sie das Cookie, vergleichen Sie die Gültigkeitsdauer des Cookies und führen Sie Schritt 1 erneut aus.
3 Füllen Sie das Cookie aus, um den Anmeldestatus beizubehalten.
1. Cookies online abrufen
Verwenden Sie Selenium + PhantomJS, um die Browseranmeldung zu simulieren und Cookies zu erhalten.
Normalerweise gibt es mehrere Cookies und die Cookies werden einzeln gespeichert .weibo-Suffixdatei.
def get_cookie_from_network():
from selenium import webdriver
url_login = 'http://login.weibo.cn/login/'
driver = webdriver.PhantomJS()
driver.get(url_login)
driver.find_element_by_xpath('//input[@type="text"]').send_keys('your_weibo_accout') # 改成你的微博账号
driver.find_element_by_xpath('//input[@type="password"]').send_keys('your_weibo_password') # 改成你的微博密码
driver.find_element_by_xpath('//input[@type="submit"]').click() # 点击登录
# 获得 cookie信息
cookie_list = driver.get_cookies()
print cookie_list
cookie_dict = {}
for cookie in cookie_list:
#写入文件
f = open(cookie['name']+'.weibo','w')
pickle.dump(cookie, f)
f.close()
if cookie.has_key('name') and cookie.has_key('value'):
cookie_dict[cookie['name']] = cookie['value']
return cookie_dict2, Cookies aus Dateien abrufen
Durchsuchen Sie Dateien mit der Endung .weibo, also Cookie-Dateien, aus dem aktuellen Verzeichnis. Verwenden Sie pickle, um es in ein Diktat zu entpacken, den Ablaufwert mit der aktuellen Zeit zu vergleichen und leer zurückzugeben, wenn es abläuft
def get_cookie_from_cache():
cookie_dict = {}
for parent, dirnames, filenames in os.walk('./'):
for filename in filenames:
if filename.endswith('.weibo'):
print filename
with open(self.dir_temp + filename, 'r') as f:
d = pickle.load(f)
if d.has_key('name') and d.has_key('value') and d.has_key('expiry'):
expiry_date = int(d['expiry'])
if expiry_date > (int)(time.time()):
cookie_dict[d['name']] = d['value']
else:
return {}
return cookie_dict3, wenn das zwischengespeicherte Cookie abläuft, holen Sie sich das Cookie erneut vom Netzwerk
def get_cookie(): cookie_dict = get_cookie_from_cache() if not cookie_dict: cookie_dict = get_cookie_from_network() return cookie_dict
4, Verwenden Sie Cookies, um andere Weibo-Homepages anzufordern
def get_weibo_list(self, user_id):
import requests
from bs4 import BeautifulSoup as bs
cookdic = get_cookie()
url = 'http://weibo.cn/stocknews88'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36'}
timeout = 5
r = requests.get(url, headers=headers, cookies=cookdic,timeout=timeout)
soup = bs(r.text, 'lxml')
...
# 用BeautifulSoup 解析网页
...Das Obige habe ich für alle zusammengestellt. Ich hoffe, dass es in Zukunft für alle hilfreich sein wird.
Verwandte Artikel:
So durchlaufen Sie ein zweidimensionales Array mit v-for in vueDaten von v-for in Vue-Gruppeninstanzvue2.0-berechnete Instanz zur Berechnung des akkumulierten Werts nach der ListenschleifeDas obige ist der detaillierte Inhalt vonAutomatische Erfassung und Ablauf von Cookies durch Webcrawler (ausführliche Anleitung). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Plätzchen
Plätzchen
 So lösen Sie das Problem, dass document.cookie nicht abgerufen werden kann
So lösen Sie das Problem, dass document.cookie nicht abgerufen werden kann
 Das heißt, die Verknüpfung kann nicht gelöscht werden
Das heißt, die Verknüpfung kann nicht gelöscht werden
 Was bedeutet es, alle Cookies zu blockieren?
Was bedeutet es, alle Cookies zu blockieren?
 So lösen Sie das Problem, dass die IE-Verknüpfung nicht gelöscht werden kann
So lösen Sie das Problem, dass die IE-Verknüpfung nicht gelöscht werden kann
 So legen Sie Kopf- und Fußzeilen in Word fest
So legen Sie Kopf- und Fußzeilen in Word fest
 So installieren Sie ein SSL-Zertifikat
So installieren Sie ein SSL-Zertifikat
 Die Druckerinstallation ist fehlgeschlagen
Die Druckerinstallation ist fehlgeschlagen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



