

Dieser Artikel stellt hauptsächlich die Redis-Interviewfragen und verteilten Cluster vor. Er hat einen gewissen Referenzwert. Jetzt können Freunde in Not darauf verweisen 1. Welche Vorteile bietet die Verwendung von Redis?
(1) Es ist schnell, weil die Daten im Speicher gespeichert werden, ähnlich wie bei HashMap. Der Vorteil von HashMap besteht darin, dass die zeitliche Komplexität von Suche und Betrieb O(1) ist.  (2) Es unterstützt Rich-Datentypen, Unterstützt String, Liste, Set, Sortierte Menge, Hash
(2) Es unterstützt Rich-Datentypen, Unterstützt String, Liste, Set, Sortierte Menge, Hash
Besondere Empfehlung:
2020 Redis-Interviewfragen (aktuell)
2. Was sind die Vorteile von Redis im Vergleich zu Memcached?(1) Alle Werte in Memcached sind einfache Zeichenfolgen. Als Ersatz unterstützt Redis umfangreichere Datentypen. (2) Redis ist viel schneller als Memcached.
(3) Redis kann seine Daten beibehalten Daten
(1) Der Master führt am besten keine Persistenzarbeiten durch, wie z. B. RDB-Speicher-Snapshots und AOF-Protokolldateien
(2) Wenn die Daten wichtig sind, aktiviert ein Slave AOF-Sicherungsdaten und die Richtlinie ist auf eine Synchronisierung einmal pro Sekunde eingestellt
(3) Für die Geschwindigkeit der Master-Slave-Replikation und die Stabilität der Verbindung sind Master und Slave am besten geeignet Im selben LAN
4. Es gibt 20 Millionen Daten in MySQL, aber nur 200.000 Daten werden in Redis gespeichert Der Speicherdatensatz ist auf eine bestimmte Größe angewachsen. Zu gegebener Zeit wird eine Dateneliminierungsstrategie implementiert. redis bietet 6 Dateneliminierungsstrategien:
voltile-lru: Wählen Sie die zuletzt verwendeten Daten aus dem Datensatz (server.db[i].expires) mit einer für die Eliminierung festgelegten Ablaufzeit aus
volatile-ttl: Wählen Sie die Daten aus, die demnächst ablaufen, aus dem Datensatz (server.db[i].expires) mit einer für die Löschung festgelegten Ablaufzeit
volatile-random: Wählen Sie zufällig Daten zur Eliminierung aus dem Datensatz (server.db[i].expires) mit festgelegter Ablaufzeit aus
allkeys-lru: Aus dem Datensatz (server.db[i ] .dict) und entfernen Sie die zuletzt verwendeten Daten
allkeys-random: Wählen Sie Daten willkürlich aus dem Datensatz (server.db[i].dict) aus, um
no-enviction ( Räumung): Räumung von Daten verbieten
1). Speichermethode
Memecache speichert alle Daten im Speicher. Nach einem Stromausfall bleiben die Daten hängen.
Redis wird teilweise auf der Festplatte gespeichert, was die Datenpersistenz gewährleistet.
2), Datenunterstützungstypen
Memcaches Unterstützung für Datentypen ist relativ einfach.
Redis verfügt über komplexe Datentypen.
3). Es werden verschiedene zugrunde liegende Modelle verwendet
Die zugrunde liegenden Implementierungsmethoden und Anwendungsprotokolle für die Kommunikation mit Clients sind unterschiedlich.
Redis hat den VM-Mechanismus direkt selbst erstellt, denn wenn das allgemeine System Systemfunktionen aufruft, verschwendet es eine gewisse Zeit zum Verschieben und Anfordern.
4), Wertgröße
Redis kann maximal 1 GB erreichen, während Memcache nur 1 MB beträgt
1) Der Master schreibt Speicher-Snapshots und der Speicherbefehl plant die rdbSave-Funktion, die die Arbeit des Haupt-Threads blockiert, was sehr große Auswirkungen auf die Leistung hat Der Dienst wird zeitweise angehalten, daher ist Master die beste Lösung. Schreiben Sie keine Speicher-Snapshots.
2). Wenn die AOF-Datei nicht neu geschrieben wird, hat diese Persistenzmethode nur minimale Auswirkungen auf die Leistung, aber die AOF-Datei wird weiter wachsen beeinflussen die Wiederherstellung der Master-Neustartgeschwindigkeit. Es ist am besten, keine Persistenzarbeiten auf dem Master durchzuführen, einschließlich Speicher-Snapshots und AOF-Protokolldateien. Aktivieren Sie insbesondere keine Speicher-Snapshots für die Persistenz. Wenn die Daten kritisch sind, sollte ein Slave AOF-Sicherungsdaten aktivieren einmal pro Sekunde zu synchronisieren.
3) Der Master ruft BGREWRITEAOF auf, um die AOF-Datei neu zu schreiben. AOF belegt beim Neuschreiben eine große Menge an CPU- und Speicherressourcen, was zu einer übermäßigen Dienstlast und einer kurzfristigen Dienstunterbrechung führt.
4). Leistungsprobleme der Redis-Master-Slave-Replikation und die Stabilität der Verbindung, wenn sich Slave und Master im selben LAN befinden
Redis eignet sich am besten für alle Daten-In-Memory-Szenarien. Obwohl Redis auch Persistenzfunktionen bietet, handelt es sich tatsächlich eher um eine festplattengestützte Funktion, die ganz anders ist Aufgrund der Persistenz im herkömmlichen Sinne haben Sie möglicherweise Fragen. Es scheint, dass Redis eher eine erweiterte Version von Memcached ist. Wenn Sie also einfach den Unterschied zwischen Redis verwenden und Memcached erhalten die meisten von ihnen das gleiche Ergebnis:
1 Redis unterstützt nicht nur einfache Daten vom Typ k/v, sondern bietet auch die Speicherung von Datenstrukturen wie Liste, Satz, Zset Hash.
2. Redis unterstützt die Datensicherung, also die Datensicherung im Master-Slave-Modus.
3. Redis unterstützt Datenpersistenz, wodurch Daten im Speicher auf der Festplatte verbleiben und bei einem Neustart erneut geladen werden können.
(1), Sitzungscache
(2), Full Page Cache (FPC)
Zusätzlich zu den grundlegenden Sitzungstokens bietet Redis auch eine sehr einfache FPC-Plattform. Zurück zum Konsistenzproblem: Selbst wenn die Redis-Instanz neu gestartet wird, werden Benutzer aufgrund der Festplattenpersistenz keinen Rückgang der Seitenladegeschwindigkeit feststellen. Dies ist eine große Verbesserung, ähnlich wie bei PHP Local FPC.
Am Beispiel von Magento bietet Magento ein Plugin zur Verwendung von Redis als Backend für den Ganzseiten-Cache.
Darüber hinaus verfügt Pantheon für WordPress-Benutzer über ein sehr gutes Plug-in wp-redis, mit dem Sie die von Ihnen durchsuchten Seiten so schnell wie möglich laden können.
(3), Warteschlange
Einer der großen Vorteile von Redis im Bereich der Speicher-Engines besteht darin, dass es Listen- und Set-Operationen bereitstellt, wodurch Redis als gute Nachricht verwendet werden kann Warteschlangenplattform. Die von Redis als Warteschlange verwendeten Vorgänge ähneln den Push/Pop-Vorgängen der Liste in lokalen Programmiersprachen (wie Python).
Wenn Sie in Google schnell nach „Redis-Warteschlangen“ suchen, werden Sie sofort eine große Anzahl von Open-Source-Projekten finden. Der Zweck dieser Projekte besteht darin, mit Redis sehr gute Back-End-Tools zu erstellen, um verschiedene Warteschlangen zu erfüllen Bedürfnisse. Celery verfügt beispielsweise über ein Backend, das Redis als Broker verwendet. Sie können es hier anzeigen.
(4), Rangliste/Zähler
Redis implementiert den Vorgang des Erhöhens oder Verringerns von Zahlen im Speicher sehr gut. Sets und sortierte Sets machen es uns auch sehr einfach, diese Operationen durchzuführen. Redis stellt lediglich diese beiden Datenstrukturen bereit. Wir möchten also die Top-10-Benutzer aus der sortierten Menge erhalten – nennen wir sie „user_scores“, und wir müssen es einfach so machen:
Dies setzt natürlich voraus, dass Sie in aufsteigender Reihenfolge sortieren auf die Punktzahlen Ihrer Benutzer. Wenn Sie den Benutzer und die Punktzahl des Benutzers zurückgeben möchten, müssen Sie dies wie folgt ausführen:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games ist ein gutes Beispiel, das in Ruby implementiert wurde Rangliste Es verwendet Redis zum Speichern von Daten. Sie können es hier sehen.
(5), Veröffentlichen/Abonnieren
Zuletzt (aber sicherlich nicht zuletzt) ist die Veröffentlichungs-/Abonnementfunktion von Redis. Es gibt tatsächlich viele Anwendungsfälle für Publish/Subscribe. Ich habe gesehen, wie Leute es in sozialen Netzwerkverbindungen, als Auslöser für Veröffentlichungs-/Abonnement-basierte Skripte und sogar zum Aufbau von Chat-Systemen mithilfe der Veröffentlichungs-/Abonnement-Funktionalität von Redis verwenden! (Nein, das stimmt, Sie können es nachschauen).
Von allen von Redis bereitgestellten Funktionen ist diese meiner Meinung nach diejenige, die den Leuten am wenigsten gefällt, obwohl sie den Benutzern diese Multifunktion bietet.
Hohe Verfügbarkeit (Hohe Verfügbarkeit) bedeutet, dass es keine Auswirkungen auf das Unternehmen und die Benutzer hat, wenn ein Server seine Dienste einstellt . . Der Grund für das Stoppen des Dienstes kann auf unvorhersehbare Ursachen wie Netzwerkkarten, Router, Computerräume, übermäßige CPU-Auslastung, Speicherüberlauf, Naturkatastrophen usw. zurückzuführen sein. In vielen Fällen wird es auch als Einzelpunktproblem bezeichnet.
(1) Es gibt zwei Hauptmethoden zur Lösung von Einzelpunktproblemen:
Aktive und Backup-Methoden
Dies ist normalerweise ein Host und eine oder mehrere Backup-Maschinen. Der untere Host stellt Dienste für die Außenwelt bereit und synchronisiert Daten mit der Standby-Maschine. Wenn die Host-Maschine ausfällt, beginnt die Standby-Maschine sofort mit der Bereitstellung.
Keepalived wird häufig in Redis HA verwendet, wodurch der Host und die Backup-Maschinen der Außenwelt dieselbe virtuelle IP bereitstellen können. Der Client führt Datenoperationen über die virtuelle IP aus Nach einer Ausfallzeit wandert der VIP automatisch zur Backup-Maschine an Bord.
Der Vorteil besteht darin, dass es keine Auswirkungen auf den Kunden hat und dennoch über VIP funktioniert.
Die Mängel liegen auch auf der Hand. Meistens wird die Backup-Maschine nicht genutzt und verschwendet.
Master-Slave-Methode
Diese Methode verwendet einen Master und mehrere Slaves und synchronisiert Daten zwischen Mastern und Slaves. Wenn der Master ausfällt, wird über den Wahlalgorithmus (Paxos, Raft) ein neuer Master aus dem Slave gewählt, der weiterhin Dienste für die Außenwelt bereitstellt. Nachdem sich der Master erholt hat, tritt er als Slave wieder bei.
Ein weiterer Zweck von Master-Slave besteht darin, Lesen und Schreiben zu trennen. Dies ist eine allgemeine Lösung, wenn der Lese- und Schreibdruck einer einzelnen Maschine zu hoch ist. Seine Host-Rolle ermöglicht nur Schreibvorgänge oder eine geringe Lesemenge und verlagert redundante Leseanforderungen über einen Lastausgleichsalgorithmus auf einen oder mehrere Slave-Server.
Der Nachteil besteht darin, dass sich nach dem Ausfall des Hosts, obwohl der Slave zum neuen Master gewählt wird, die der Außenwelt bereitgestellte IP-Dienstadresse geändert hat, was bedeutet, dass dies Auswirkungen auf den Client hat. Die Lösung dieser Situation erfordert einige zusätzliche Arbeit. Wenn sich die Hostadresse ändert, wird der Client rechtzeitig benachrichtigt. Nachdem der Client die neue Adresse erhalten hat, sendet er weiterhin neue Anfragen.
(2) Datensynchronisation
Ob Master-Slave oder Master-Slave, es handelt sich um das Problem der Datensynchronisation. Dies ist ebenfalls in zwei Situationen unterteilt:
Synchronisationsmethode: Wenn der Host den Client empfängt, werden die Daten nach dem endseitigen Schreibvorgang synchron mit dem Slave-Computer synchronisiert. Wenn der Slave-Computer ebenfalls erfolgreich schreibt, gibt der Host den Erfolg an den Client zurück, was auch als starke Datenkonsistenz bezeichnet wird . Offensichtlich wird die Leistung dieser Methode stark beeinträchtigt. Wenn es viele Slave-Maschinen gibt, ist es nicht notwendig, jede einzelne zu synchronisieren. Nachdem der Master eine bestimmte Slave-Maschine synchronisiert hat, synchronisiert die Slave-Maschine dann die Datenverteilung an andere Slaves Maschinen, wodurch die Leistungsteilung der Host-Maschine verbessert wird. Diese Konfiguration wird in Redis mit einem Master und einem Slave unterstützt. Gleichzeitig fungiert dieser Salve als Master für andere Slaves.
Asynchroner Modus: Nach dem Empfang des Schreibvorgangs gibt der Host direkt den Erfolg zurück und synchronisiert die Daten dann asynchron mit dem Slave im Hintergrund. Diese Art der Synchronisierungsleistung ist besser, kann jedoch die Integrität der Daten nicht garantieren. Wenn beispielsweise der Host während des asynchronen Synchronisierungsprozesses plötzlich abstürzt, wird diese Methode auch als schwache Datenkonsistenz bezeichnet.
Die Master-Slave-Synchronisierung von Redis verwendet eine asynchrone Methode, sodass das Risiko besteht, dass eine kleine Datenmenge verloren geht. Es gibt auch einen Sonderfall schwacher Konsistenz, der als Eventualkonsistenz bezeichnet wird. Weitere Informationen finden Sie im CAP-Prinzip und im Konsistenzmodell.
(3) Lösungsauswahl
Die Keepalived-Lösung ist einfach zu konfigurieren und weist geringe Arbeitskosten auf. Sie wird empfohlen, wenn die Datenmenge gering und der Druck gering ist. Wenn die Datenmenge relativ groß ist und Sie nicht zu viele Maschinen verschwenden möchten und nach der Ausfallzeit auch einige benutzerdefinierte Maßnahmen ergreifen möchten, z. B. Alarmierung, Protokollierung, Datenmigration usw., wird die Verwendung empfohlen die Master-Slave-Methode, da sie der Master-Slave-Methode entspricht. Normalerweise gibt es auch ein Verwaltungs- und Überwachungszentrum.
Ausfallbenachrichtigungen können in die Client-Komponente integriert oder separat getrennt werden. Redis offizieller Sentinel unterstützt automatisches Failover, Benachrichtigung usw. Weitere Informationen finden Sie unter Kostengünstiges und hochverfügbares Lösungsdesign (4).
Logikdiagramm: 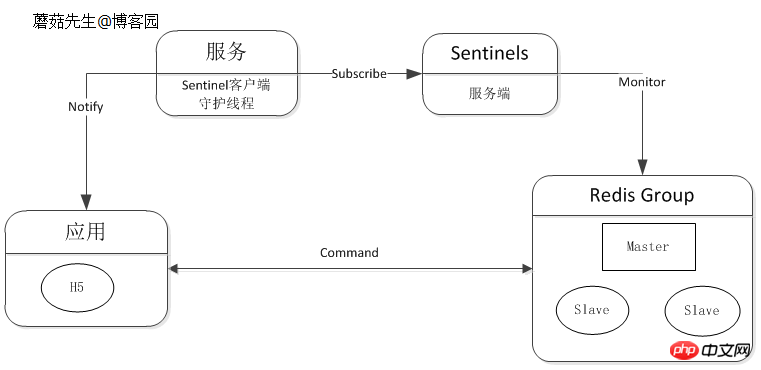
Verteilt (verteilt) bedeutet, dass das Geschäftsvolumen und das Datenvolumen zunehmen können beliebig Erhöhen oder verringern Sie die Anzahl der Server, um das Problem zu lösen.
Cluster-Ära
Stellen Sie mindestens zwei Redis-Server bereit, um einen kleinen Cluster zu bilden, mit zwei Hauptzwecken:
Hohe Verfügbarkeit: Nachdem der Host aufgelegt hat, macht ein automatisches Failover den Front-End-Dienst zugänglich Benutzer Keine Auswirkungen.
Lese- und Schreibtrennung: Verlagern Sie den Lesedruck vom Host auf den Slave.
Auf der Client-Komponente kann ein Lastausgleich erreicht werden, und je nach Betriebsbedingungen verschiedener Server können unterschiedliche Anteile des Leseanforderungsdrucks aufgeteilt werden.
Logikdiagramm: 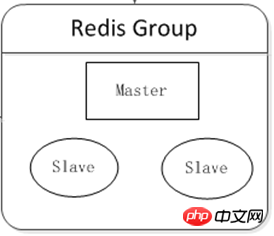
Wenn die Menge der zwischengespeicherten Daten weiter zunimmt, reicht der Speicher einer einzelnen Maschine nicht aus. und die Daten müssen in verschiedene Teile aufgeteilt und auf mehrere Server verteilt werden.
Daten können auf der Clientseite fragmentiert werden. Weitere Informationen zum Datenfragmentierungsalgorithmus finden Sie unter C# Consistent Hash Detaillierte Erklärung und C# Virtual Bucket Fragmentation.
Logikdiagramm: 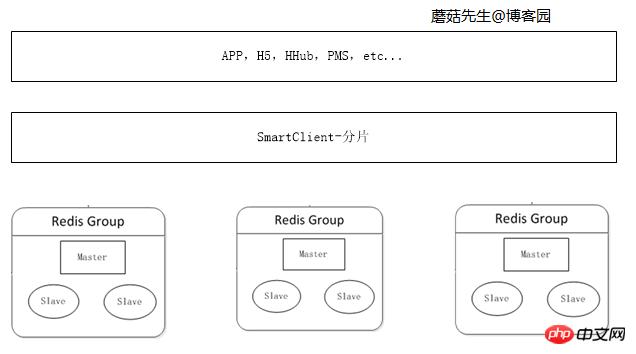
Zeitalter verteilter Cluster in großem Maßstab
Wenn die Datenmenge weiter zunimmt, können Anwendungen entsprechend dem Unternehmen eine entsprechende verteilte Verteilung beantragen in verschiedenen Szenarien Cluster. Der wichtigste Teil davon ist die Cache-Verwaltung, und der wichtigste Teil ist das Hinzufügen von Proxy-Diensten. Die Anwendung greift über einen Proxy zum Lesen und Schreiben auf den echten Redis-Server zu. Dies hat folgende Vorteile:
Es wird vermieden, dass immer mehr Clients direkt auf den Redis-Server zugreifen, was schwierig zu verwalten ist und Risiken mit sich bringt.
Entsprechende Sicherheitsmaßnahmen können auf der Proxy-Ebene implementiert werden, wie z. B. Strombegrenzung, Autorisierung und Sharding.
Vermeiden Sie immer mehr Logikcodes auf der Clientseite, die nicht nur aufgeblasen, sondern auch mühsam zu aktualisieren sind.
Die Proxy-Schicht ist zustandslos und kann Knoten beliebig erweitern. Für den Client ist der Zugriff auf den Proxy dasselbe wie der Zugriff auf eigenständiges Redis.
Derzeit verwendet das Host-Unternehmen zwei Lösungen: Client-Komponente und Proxy, da die Verwendung eines Proxys bestimmte Leistungen beeinträchtigt. Zu den entsprechenden Lösungen für die Proxy-Implementierung gehören Twemproxy von Twitter und Codis von Wandoujia.
Logikdiagramm: 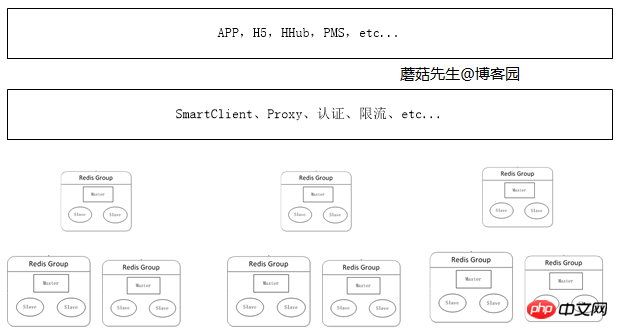
Auf den verteilten Cache folgt der Cloud-Service-Cache, der die Details vollständig vor dem Benutzer schützt. Jede Anwendung kann ihre eigene Größe und ihren eigenen Verkehrsplan beantragen, wie zum Beispiel den Taobao OCS-Cloud-Service Cache.
Die erforderlichen Implementierungskomponenten für den verteilten Cache sind:
Ein Cache-Überwachungs-, Migrations- und Verwaltungszentrum.
Eine benutzerdefinierte Client-Komponente, SmartClient im Bild oben.
Ein zustandsloser Proxy-Dienst.
N Server.
Verwandte Lernempfehlungen: Redis-Video-Tutorial
Verwandte Lernempfehlungen: MySQL-Video-Tutorial
Das obige ist der detaillierte Inhalt vonRedis-Interviewfragen und verteilte Cluster. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was wird verteilt?
Was wird verteilt?
 Der Unterschied zwischen verteilten und Microservices
Der Unterschied zwischen verteilten und Microservices
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?









![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



