
 Backend-Entwicklung
Python-Tutorial
Tutorial zur Erkennung von Python-Verifizierungscodes: Graustufenverarbeitung, Binarisierung, Rauschunterdrückung und Tesserocr-Erkennung
Backend-Entwicklung
Python-Tutorial
Tutorial zur Erkennung von Python-Verifizierungscodes: Graustufenverarbeitung, Binarisierung, Rauschunterdrückung und Tesserocr-Erkennung
Tutorial zur Erkennung von Python-Verifizierungscodes: Graustufenverarbeitung, Binarisierung, Rauschunterdrückung und Tesserocr-Erkennung

Dieser Artikel stellt hauptsächlich das Tutorial zur Graustufenverarbeitung, Binärisierung, Rauschunterdrückung und Tesserocr-Erkennung zur Erkennung von Python-Verifizierungscodes vor. Jetzt kann ich es mit Ihnen teilen.
Vorwort
Ein unvermeidbares Problem beim Schreiben von Crawlern ist der Verifizierungscode. Es gibt mittlerweile etwa 4 Arten von Verifizierungscodes:
Bildklasse
Schiebeklasse
Klickklasse
Sprachtyp
Werfen wir heute einen Blick auf den Bildtyp? Die meisten dieser Verifizierungscodes sind eine Kombination aus Zahlen und Buchstaben, und in China werden auch chinesische Schriftzeichen verwendet. Auf dieser Basis werden Rauschen, Interferenzlinien, Verformung, Überlappung, unterschiedliche Schriftfarben und andere Methoden hinzugefügt, um die Erkennungsschwierigkeit zu erhöhen.
Entsprechend kann die Erkennung von Verifizierungscodes grob in die folgenden Schritte unterteilt werden:
Graustufenverarbeitung
Kontrast erhöhen (optional)
Binarisierung
Rauschunterdrückung
Neigungskorrektur-Segmentierungszeichen
Trainingsbibliothek einrichten
Anerkennung
Aufgrund ihres experimentellen Charakters werden die verwendeten Verifizierungscodes verwendet In diesem Artikel werden alle von Programmen generiert, anstatt echte Website-Bestätigungscodes stapelweise herunterzuladen. Dies hat den Vorteil, dass es eine große Anzahl von Datensätzen mit klaren Ergebnissen geben kann.
Wenn Sie Daten in einer realen Umgebung abrufen müssen, können Sie verschiedene Plattformen mit großem Code verwenden, um einen Datensatz für das Training zu erstellen.
Um den Verifizierungscode zu generieren, verwende ich die Claptcha-Bibliothek (lokaler Download). Natürlich ist auch die Captcha-Bibliothek (lokaler Download) eine gute Wahl.
Um den einfachsten rein digitalen, störungsfreien Verifizierungscode zu generieren, müssen Sie zunächst einige Änderungen an _drawLine in Zeile 285 von claptcha.py vornehmen. Ich lasse diese Funktion direkt None zurückgeben und dann Beginnen Sie mit der Generierung des Bestätigungscodes. Code:
from claptcha import Claptcha
c = Claptcha("8069","/usr/share/fonts/truetype/freefont/FreeMono.ttf")
t,_ = c.write('1.png')Sie müssen hier auf den Schriftartenpfad von Ubuntu achten, Sie können auch andere Schriftarten online zur Verwendung herunterladen. Der Bestätigungscode wird wie folgt generiert:
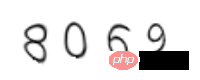
Es ist ersichtlich, dass der Bestätigungscode deformiert ist. Für diese Art des einfachsten Bestätigungscodes können Sie ihn direkt mit dem Open-Source-Code tesserocr von Google identifizieren.
Erste Installation:
apt-get install tesseract-ocr libtesseract-dev libleptonica-dev pip install tesserocr
Dann Erkennung starten:
from PIL import Image import tesserocr p1 = Image.open('1.png') tesserocr.image_to_text(p1) '8069\n\n'
Es ist ersichtlich, dass für diesen einfachen Verifizierungscode die Erkennungsrate bereits sehr hoch ist, ohne dass grundsätzlich etwas unternommen wird . Hoch. Interessierte Freunde können weitere Daten zum Testen verwenden, ich werde hier jedoch nicht auf Details eingehen.
Fügen Sie als Nächstes Rauschen zum Hintergrund des Bestätigungscodes hinzu, um Folgendes anzuzeigen:
c = Claptcha("8069","/usr/share/fonts/truetype/freefont/FreeMono.ttf",noise=0.4)
t,_ = c.write('2.png')Generieren Sie den Bestätigungscode wie folgt:

Erkennung:
p2 = Image.open('2.png') tesserocr.image_to_text(p2) '8069\n\n'
Die Wirkung ist okay. Als nächstes generieren Sie eine alphanumerische Kombination:
c2 = Claptcha("A4oO0zZ2","/usr/share/fonts/truetype/freefont/FreeMono.ttf")
t,_ = c2.write('3.png')Generieren Sie den Bestätigungscode wie folgt:
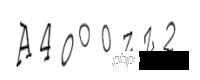
Der dritte ist der Kleinbuchstabe o, der vierte ist der Großbuchstabe O, der fünfte ist die Zahl 0, der sechste ist der Kleinbuchstabe z, der siebte ist der Großbuchstabe Z und der letzte ist die Nummer 2. Stimmt es, dass die menschlichen Augen bereits niedergekniet sind? Aber jetzt unterscheiden allgemeine Verifizierungscodes nicht strikt zwischen Groß- und Kleinbuchstaben. Mal sehen, wie die automatische Erkennung aussieht:
p3 = Image.open('3.png') tesserocr.image_to_text(p3) 'AMOOZW\n\n'
Natürlich ein Computer, der sogar knien kann mit dem menschlichen Auge ist nutzlos. In einigen Fällen, in denen die Interferenz gering und die Verformung nicht schwerwiegend ist, ist die Verwendung von tesserocr jedoch sehr einfach und bequem. Stellen Sie dann Zeile 285 der geänderten _drawLine von claptcha.py wieder her, um zu sehen, ob Interferenzlinien hinzugefügt werden.

p4 = Image.open('4.png') tesserocr.image_to_text(p4) ''
Es kann überhaupt nicht erkannt werden, nachdem eine Interferenzlinie hinzugefügt wurde. Gibt es also eine Möglichkeit, die Interferenzlinie zu entfernen? ?
Obwohl das Bild schwarzweiß aussieht, muss es dennoch in Graustufen verarbeitet werden. Andernfalls erhalten Sie mit der Funktion „load()“ ein RGB-Tupel eines bestimmten Pixels anstelle eines einzelnen Werts . Die Verarbeitung ist wie folgt:
def binarizing(img,threshold):
"""传入image对象进行灰度、二值处理"""
img = img.convert("L") # 转灰度
pixdata = img.load()
w, h = img.size
# 遍历所有像素,大于阈值的为黑色
for y in range(h):
for x in range(w):
if pixdata[x, y] < threshold:
pixdata[x, y] = 0
else:
pixdata[x, y] = 255
return imgDas verarbeitete Bild ist wie folgt:

Sie können die Verarbeitung sehen. Anschließend wurde das Bild stark geschärft. Als nächstes habe ich versucht, die Interferenzlinien mithilfe der gängigen 4-Nachbarschafts- und 8-Nachbarschafts-Algorithmen zu entfernen. Der sogenannte X-Nachbarschaftsalgorithmus kann sich auf die Neun-Quadrat-Raster-Eingabemethode auf Mobiltelefonen beziehen. Die Taste 5 dient zur Beurteilung des Pixels nach oben, unten, links und rechts, und die Nachbarschaft 8 dient zur Beurteilung umlaufende 8 Pixel. Wenn die Anzahl von 255 unter diesen 4 oder 8 Punkten einen bestimmten Schwellenwert überschreitet, wird dieser Punkt als Rauschen beurteilt. Der Schwellenwert kann entsprechend der tatsächlichen Situation geändert werden.
def depoint(img):
"""传入二值化后的图片进行降噪"""
pixdata = img.load()
w,h = img.size
for y in range(1,h-1):
for x in range(1,w-1):
count = 0
if pixdata[x,y-1] > 245:#上
count = count + 1
if pixdata[x,y+1] > 245:#下
count = count + 1
if pixdata[x-1,y] > 245:#左
count = count + 1
if pixdata[x+1,y] > 245:#右
count = count + 1
if pixdata[x-1,y-1] > 245:#左上
count = count + 1
if pixdata[x-1,y+1] > 245:#左下
count = count + 1
if pixdata[x+1,y-1] > 245:#右上
count = count + 1
if pixdata[x+1,y+1] > 245:#右下
count = count + 1
if count > 4:
pixdata[x,y] = 255
return imgDas verarbeitete Bild sieht wie folgt aus:

好像……根本没卵用啊?!确实是这样的,因为示例中的图片干扰线的宽度和数字是一样的。对于干扰线和数据像素不同的,比如Captcha生成的验证码:

从左到右依次是原图、二值化、去除干扰线的情况,总体降噪的效果还是比较明显的。另外降噪可以多次执行,比如我对上面的降噪后结果再进行依次降噪,可以得到下面的效果:

再进行识别得到了结果:
p7 = Image.open('7.png') tesserocr.image_to_text(p7) '8069 ,,\n\n'
另外,从图片来看,实际数据颜色明显和噪点干扰线不同,根据这一点可以直接把噪点全部去除,这里就不展开说了。
第一篇文章,先记录如何将图片进行灰度处理、二值化、降噪,并结合tesserocr来识别简单的验证码,剩下的部分在下一篇文章中和大家一起分享。
相关推荐:
Das obige ist der detaillierte Inhalt vonTutorial zur Erkennung von Python-Verifizierungscodes: Graustufenverarbeitung, Binarisierung, Rauschunterdrückung und Tesserocr-Erkennung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, hochrangige skalierbare Python-Datenbank Hadidb (HadIDB) ist eine leichte Datenbank in Python mit einem hohen Maß an Skalierbarkeit. Installieren Sie HadIDB mithilfe der PIP -Installation: PipinstallHadIDB -Benutzerverwaltung erstellen Benutzer: createUser (), um einen neuen Benutzer zu erstellen. Die Authentication () -Methode authentifiziert die Identität des Benutzers. fromHadidb.operationImportUseruser_obj = user ("admin", "admin") user_obj.
 Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
MySQL kann ohne Netzwerkverbindungen für die grundlegende Datenspeicherung und -verwaltung ausgeführt werden. Für die Interaktion mit anderen Systemen, Remotezugriff oder Verwendung erweiterte Funktionen wie Replikation und Clustering ist jedoch eine Netzwerkverbindung erforderlich. Darüber hinaus sind Sicherheitsmaßnahmen (wie Firewalls), Leistungsoptimierung (Wählen Sie die richtige Netzwerkverbindung) und die Datensicherung für die Verbindung zum Internet von entscheidender Bedeutung.
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Kann sich MySQL Workbench mit Mariadb verbinden?
Apr 08, 2025 pm 02:33 PM
Kann sich MySQL Workbench mit Mariadb verbinden?
Apr 08, 2025 pm 02:33 PM
MySQL Workbench kann eine Verbindung zu MariADB herstellen, vorausgesetzt, die Konfiguration ist korrekt. Wählen Sie zuerst "Mariadb" als Anschlusstyp. Stellen Sie in der Verbindungskonfiguration Host, Port, Benutzer, Kennwort und Datenbank korrekt ein. Überprüfen Sie beim Testen der Verbindung, ob der Mariadb -Dienst gestartet wird, ob der Benutzername und das Passwort korrekt sind, ob die Portnummer korrekt ist, ob die Firewall Verbindungen zulässt und ob die Datenbank vorhanden ist. Verwenden Sie in fortschrittlicher Verwendung die Verbindungspooling -Technologie, um die Leistung zu optimieren. Zu den häufigen Fehlern gehören unzureichende Berechtigungen, Probleme mit Netzwerkverbindung usw. Bei Debugging -Fehlern, sorgfältige Analyse von Fehlerinformationen und verwenden Sie Debugging -Tools. Optimierung der Netzwerkkonfiguration kann die Leistung verbessern
 Benötigt MySQL einen Server?
Apr 08, 2025 pm 02:12 PM
Benötigt MySQL einen Server?
Apr 08, 2025 pm 02:12 PM
Für Produktionsumgebungen ist in der Regel ein Server erforderlich, um MySQL auszuführen, aus Gründen, einschließlich Leistung, Zuverlässigkeit, Sicherheit und Skalierbarkeit. Server haben normalerweise leistungsstärkere Hardware, redundante Konfigurationen und strengere Sicherheitsmaßnahmen. Bei kleinen Anwendungen mit niedriger Last kann MySQL auf lokalen Maschinen ausgeführt werden, aber Ressourcenverbrauch, Sicherheitsrisiken und Wartungskosten müssen sorgfältig berücksichtigt werden. Für eine größere Zuverlässigkeit und Sicherheit sollte MySQL auf Cloud oder anderen Servern bereitgestellt werden. Die Auswahl der entsprechenden Serverkonfiguration erfordert eine Bewertung basierend auf Anwendungslast und Datenvolumen.
