

Detaillierte Interpretation des Node-Timer-Wissens
Dieser Artikel stellt hauptsächlich die relevanten Kenntnisse des Node-Timers vor. Er ist sehr gut und hat Referenzwert.
JavaScript wird in einem einzelnen Thread ausgeführt, und asynchrone Vorgänge sind besonders wichtig .
Solange Sie Funktionen außerhalb der Engine verwenden, müssen Sie mit der Außenseite interagieren und so asynchrone Vorgänge bilden. Da es so viele asynchrone Vorgänge gibt, muss JavaScript viel asynchrone Syntax bereitstellen. Es ist so, als ob manche Menschen immer getroffen werden und ihre Fähigkeit, Schlägen zu widerstehen, stärker werden muss, sonst sind sie am Ende.
Die asynchrone Syntax von Node ist komplizierter als die eines Browsers, da sie mit dem Kernel kommunizieren kann und dafür eine spezielle Bibliothek libuv erstellt werden muss. Diese Bibliothek ist für die Ausführungszeit verschiedener Rückruffunktionen verantwortlich. Schließlich müssen asynchrone Aufgaben schließlich zum Hauptthread zurückkehren und einzeln zur Ausführung in die Warteschlange gestellt werden.

Um asynchrone Aufgaben zu koordinieren, stellt Node tatsächlich vier Timer bereit, sodass Aufgaben zu bestimmten Zeiten ausgeführt werden können.
setTimeout()
setInterval()
setImmediate()
process.nextTick()
Die ersten beiden sind Sprachstandards und die letzten beiden gelten nur für Node. Sie sind auf ähnliche Weise geschrieben und haben ähnliche Funktionen, daher ist es nicht einfach, sie zu unterscheiden.
Können Sie mir das Ergebnis der Ausführung des folgenden Codes mitteilen?
// test.js setTimeout(() => console.log(1)); setImmediate(() => console.log(2)); process.nextTick(() => console.log(3)); Promise.resolve().then(() => console.log(4)); (() => console.log(5))();
Die Laufergebnisse sind wie folgt.
$ node test.js
Wenn Sie es sofort verstehen, müssen Sie möglicherweise nicht mehr lesen. In diesem Artikel wird ausführlich erläutert, wie Node mit verschiedenen Timern umgeht, oder allgemeiner, wie die libuv-Bibliothek asynchrone Aufgaben anordnet, die im Hauptthread ausgeführt werden sollen.
1. Synchrone Aufgaben und asynchrone Aufgaben
Erstens werden synchrone Aufgaben immer früher ausgeführt als asynchrone Aufgaben.
Im vorherigen Codeteil ist nur die letzte Zeile eine Synchronisierungsaufgabe, daher wird sie am frühesten ausgeführt.
(() => console.log(5))();
2. Aktueller Zyklus und sekundärer Zyklus
Asynchrone Aufgaben können in zwei Typen unterteilt werden.
Asynchrone Aufgaben in diesem Zyklus hinzufügen
Asynchrone Aufgaben im zweiten Zyklus hinzufügen
Die sogenannte „Schleife“ bezieht sich auf die Ereignisschleife. Auf diese Weise verarbeitet die JavaScript-Engine asynchrone Aufgaben, was später ausführlich erläutert wird. Verstehen Sie hier nur, dass dieser Zyklus früher als der zweite Zyklus ausgeführt werden muss.
Knoten legt fest, dass die Rückruffunktionen von process.nextTick und Promise an diesen Zyklus angehängt werden, dh sobald die Synchronisierungsaufgaben abgeschlossen sind, werden sie ausgeführt. Die Rückruffunktionen setTimeout, setInterval und setImmediate werden im zweiten Zyklus hinzugefügt.
Das bedeutet, dass die dritte und vierte Zeile des Codes am Anfang des Artikels früher ausgeführt werden müssen als die erste und zweite Zeile.
// 下面两行,次轮循环执行 setTimeout(() => console.log(1)); setImmediate(() => console.log(2)); // 下面两行,本轮循环执行 process.nextTick(() => console.log(3)); Promise.resolve().then(() => console.log(4));
3. process.nextTick()
Es wird in diesem Zyklus ausgeführt und Es ist die schnellste Ausführung unter allen asynchronen Aufgaben.

Nachdem der Knoten alle Synchronisierungsaufgaben ausgeführt hat, führt er die Aufgabenwarteschlange von process.nextTick aus. Die folgende Codezeile ist also die zweite Ausgabe.
process.nextTick(() => console.log(3));
Wenn Sie möchten, dass eine asynchrone Aufgabe so schnell wie möglich ausgeführt wird, verwenden Sie grundsätzlich „process.nextTick“.
4. Mikrotasks
Gemäß den Sprachspezifikationen wird die Callback-Funktion des Promise-Objekts in die „Mikrotask“ eingetragen asynchrone Aufgabe (microtask) Warteschlange. Die
-Mikrotask-Warteschlange wird hinten an die process.nextTick-Warteschlange angehängt und gehört ebenfalls zu diesem Zyklus. Daher gibt der folgende Code immer zuerst 3 und dann 4 aus.
process.nextTick(() => console.log(3)); Promise.resolve().then(() => console.log(4)); // 3 // 4

Beachten Sie, dass die nächste Warteschlange erst ausgeführt wird, nachdem die vorherige Warteschlange vollständig geleert wurde.
process.nextTick(() => console.log(1)); Promise.resolve().then(() => console.log(2)); process.nextTick(() => console.log(3)); Promise.resolve().then(() => console.log(4)); // 1 // 3 // 2 // 4
Im obigen Code werden alle Rückruffunktionen von process.nextTick früher als Promise ausgeführt.
An diesem Punkt ist die Ausführungssequenz dieses Zyklus abgeschlossen.
同步任务 process.nextTick() 微任务
Das Konzept der Ereignisschleife
Im Folgenden wird mit der Einführung der Ausführungssequenz des zweiten Zyklus begonnen, was ein Verständnis erfordert Ereignisschleife ist (Ereignisschleife).
Die offizielle Dokumentation von Node stellt es so vor.
„Wenn Node.js startet, initialisiert es die Ereignisschleife, verarbeitet das bereitgestellte Eingabeskript, das asynchrone API-Aufrufe durchführen, Timer planen oder Process.nextTick() aufrufen kann, und beginnt dann mit der Verarbeitung der Ereignisschleife.“
Diese Passage ist sehr wichtig und muss sorgfältig gelesen werden. Es drückt drei Bedeutungsebenen aus.
Zuallererst denken einige Leute, dass es zusätzlich zum Hauptthread einen separaten Event-Loop-Thread gibt. Das ist nicht der Fall, es gibt nur einen Hauptthread und die Ereignisschleife wird im Hauptthread abgeschlossen.
其次,Node 开始执行脚本时,会先进行事件循环的初始化,但是这时事件循环还没有开始,会先完成下面的事情。
同步任务
发出异步请求
规划定时器生效的时间
执行process.nextTick()等等
最后,上面这些事情都干完了,事件循环就正式开始了。
六、事件循环的六个阶段
事件循环会无限次地执行,一轮又一轮。只有异步任务的回调函数队列清空了,才会停止执行。
每一轮的事件循环,分成六个阶段。这些阶段会依次执行。
timers
I/O callbacks
idle, prepare
poll
check
close callbacks
每个阶段都有一个先进先出的回调函数队列。只有一个阶段的回调函数队列清空了,该执行的回调函数都执行了,事件循环才会进入下一个阶段。
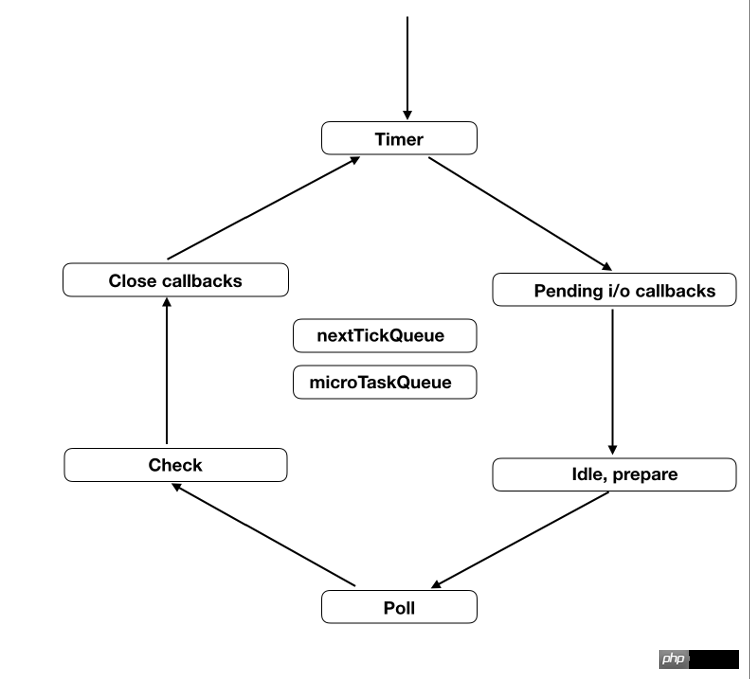
下面简单介绍一下每个阶段的含义,详细介绍可以看官方文档,也可以参考 libuv 的源码解读。
(1)timers
这个是定时器阶段,处理setTimeout()和setInterval()的回调函数。进入这个阶段后,主线程会检查一下当前时间,是否满足定时器的条件。如果满足就执行回调函数,否则就离开这个阶段。
(2)I/O callbacks
除了以下操作的回调函数,其他的回调函数都在这个阶段执行。
setTimeout()和setInterval()的回调函数
setImmediate()的回调函数
用于关闭请求的回调函数,比如socket.on('close', ...)
(3)idle, prepare
该阶段只供 libuv 内部调用,这里可以忽略。
(4)Poll
这个阶段是轮询时间,用于等待还未返回的 I/O 事件,比如服务器的回应、用户移动鼠标等等。
这个阶段的时间会比较长。如果没有其他异步任务要处理(比如到期的定时器),会一直停留在这个阶段,等待 I/O 请求返回结果。
(5)check
该阶段执行setImmediate()的回调函数。
(6)close callbacks
该阶段执行关闭请求的回调函数,比如socket.on('close', ...)。
七、事件循环的示例
下面是来自官方文档的一个示例。
const fs = require('fs');
const timeoutScheduled = Date.now();
// 异步任务一:100ms 后执行的定时器
setTimeout(() => {
const delay = Date.now() - timeoutScheduled;
console.log(`${delay}ms`);
}, 100);
// 异步任务二:至少需要 200ms 的文件读取
fs.readFile('test.js', () => {
const startCallback = Date.now();
while (Date.now() - startCallback < 200) {
// 什么也不做
}
});上面代码有两个异步任务,一个是 100ms 后执行的定时器,一个是至少需要 200ms 的文件读取。请问运行结果是什么?
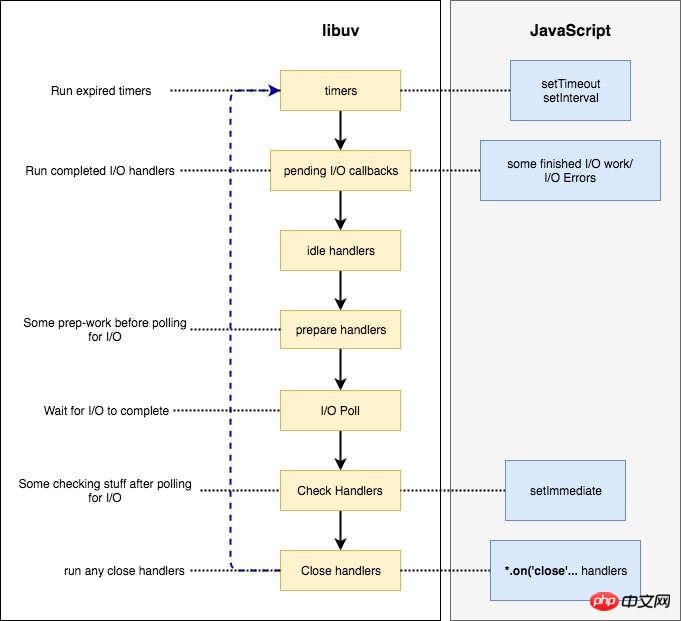
脚本进入第一轮事件循环以后,没有到期的定时器,也没有已经可以执行的 I/O 回调函数,所以会进入 Poll 阶段,等待内核返回文件读取的结果。由于读取小文件一般不会超过 100ms,所以在定时器到期之前,Poll 阶段就会得到结果,因此就会继续往下执行。
第二轮事件循环,依然没有到期的定时器,但是已经有了可以执行的 I/O 回调函数,所以会进入 I/O callbacks 阶段,执行fs.readFile的回调函数。这个回调函数需要 200ms,也就是说,在它执行到一半的时候,100ms 的定时器就会到期。但是,必须等到这个回调函数执行完,才会离开这个阶段。
第三轮事件循环,已经有了到期的定时器,所以会在 timers 阶段执行定时器。最后输出结果大概是200多毫秒。
八、setTimeout 和 setImmediate
由于setTimeout在 timers 阶段执行,而setImmediate在 check 阶段执行。所以,setTimeout会早于setImmediate完成。
setTimeout(() => console.log(1)); setImmediate(() => console.log(2));
上面代码应该先输出1,再输出2,但是实际执行的时候,结果却是不确定,有时还会先输出2,再输出1。
这是因为setTimeout的第二个参数默认为0。但是实际上,Node 做不到0毫秒,最少也需要1毫秒,根据官方文档,第二个参数的取值范围在1毫秒到2147483647毫秒之间。也就是说,setTimeout(f, 0)等同于setTimeout(f, 1)。
实际执行的时候,进入事件循环以后,有可能到了1毫秒,也可能还没到1毫秒,取决于系统当时的状况。如果没到1毫秒,那么 timers 阶段就会跳过,进入 check 阶段,先执行setImmediate的回调函数。
但是,下面的代码一定是先输出2,再输出1。
const fs = require('fs');
fs.readFile('test.js', () => {
setTimeout(() => console.log(1));
setImmediate(() => console.log(2));
});上面代码会先进入 I/O callbacks 阶段,然后是 check 阶段,最后才是 timers 阶段。因此,setImmediate才会早于setTimeout执行。
上面是我整理给大家的,希望今后会对大家有帮助。
相关文章:
Das obige ist der detaillierte Inhalt vonDetaillierte Interpretation des Node-Timer-Wissens. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
52

 So verwenden Sie Express für den Datei-Upload im Knotenprojekt
Mar 28, 2023 pm 07:28 PM
So verwenden Sie Express für den Datei-Upload im Knotenprojekt
Mar 28, 2023 pm 07:28 PM
Wie gehe ich mit dem Datei-Upload um? Der folgende Artikel stellt Ihnen vor, wie Sie Express zum Hochladen von Dateien im Knotenprojekt verwenden. Ich hoffe, er ist hilfreich für Sie!
 So löschen Sie einen Knoten in NVM
Dec 29, 2022 am 10:07 AM
So löschen Sie einen Knoten in NVM
Dec 29, 2022 am 10:07 AM
So löschen Sie einen Knoten mit nvm: 1. Laden Sie „nvm-setup.zip“ herunter und installieren Sie es auf dem Laufwerk C. 2. Konfigurieren Sie Umgebungsvariablen und überprüfen Sie die Versionsnummer mit dem Befehl „nvm -v“. install“-Befehl Knoten installieren; 4. Löschen Sie den installierten Knoten über den Befehl „nvm uninstall“.
 Eine ausführliche Analyse des Prozessmanagement-Tools „pm2' von Node
Apr 03, 2023 pm 06:02 PM
Eine ausführliche Analyse des Prozessmanagement-Tools „pm2' von Node
Apr 03, 2023 pm 06:02 PM
In diesem Artikel stellen wir Ihnen das Prozessmanagement-Tool „pm2“ von Node vor und sprechen darüber, warum PM2 benötigt wird und wie Sie PM2 installieren und verwenden. Ich hoffe, dass es für alle hilfreich ist!
 PI -Knotenunterricht: Was ist ein PI -Knoten? Wie installiere und richte ich einen PI -Knoten ein?
Mar 05, 2025 pm 05:57 PM
PI -Knotenunterricht: Was ist ein PI -Knoten? Wie installiere und richte ich einen PI -Knoten ein?
Mar 05, 2025 pm 05:57 PM
Detaillierte Erläuterungs- und Installationshandbuch für Pinetwork -Knoten In diesem Artikel wird das Pinetwork -Ökosystem im Detail vorgestellt - PI -Knoten, eine Schlüsselrolle im Pinetwork -Ökosystem und vollständige Schritte für die Installation und Konfiguration. Nach dem Start des Pinetwork -Blockchain -Testnetzes sind PI -Knoten zu einem wichtigen Bestandteil vieler Pioniere geworden, die aktiv an den Tests teilnehmen und sich auf die bevorstehende Hauptnetzwerkveröffentlichung vorbereiten. Wenn Sie Pinetwork noch nicht kennen, wenden Sie sich bitte an was Picoin ist? Was ist der Preis für die Auflistung? PI -Nutzung, Bergbau und Sicherheitsanalyse. Was ist Pinetwork? Das Pinetwork -Projekt begann 2019 und besitzt seine exklusive Kryptowährung PI -Münze. Das Projekt zielt darauf ab, eine zu erstellen, an der jeder teilnehmen kann
 So stellen Sie einen Timer für Ihre iPhone-Kamera ein
Apr 14, 2023 am 10:43 AM
So stellen Sie einen Timer für Ihre iPhone-Kamera ein
Apr 14, 2023 am 10:43 AM
Wie lange können Sie einen Timer für Ihre iPhone-Kamera einstellen? Wenn Sie in der Kamera-App des iPhones auf die Timer-Optionen zugreifen, haben Sie die Möglichkeit, zwischen zwei Modi zu wählen: 3 Sekunden (3s) und 10 Sekunden (10s). Mit der ersten Option können Sie ein schnelles Selfie mit der Vorder- oder Rückkamera machen, während Sie Ihr iPhone halten. Die zweite Option ist in Szenen nützlich, in denen Sie Ihr iPhone aus einiger Entfernung auf einem Stativ montieren können, um Gruppenfotos oder Selfies anzuklicken. So stellen Sie einen Timer für eine iPhone-Kamera ein Das Einstellen eines Timers für eine iPhone-Kamera ist zwar ein recht einfacher Vorgang, die Vorgehensweise variiert jedoch je nach verwendetem iPhone-Modell.
 Was tun, wenn npm node gyp ausfällt?
Dec 29, 2022 pm 02:42 PM
Was tun, wenn npm node gyp ausfällt?
Dec 29, 2022 pm 02:42 PM
npm node gyp schlägt fehl, weil „node-gyp.js“ nicht mit der Version von „Node.js“ übereinstimmt. Die Lösung ist: 1. Löschen Sie den Knotencache über „npm cache clean -f“ 2. Über „npm install -“ g n“ Installieren Sie das n-Modul. 3. Installieren Sie die Version „node v12.21.0“ über den Befehl „n v12.21.0“.
 Tokenbasierte Authentifizierung mit Angular und Node
Sep 01, 2023 pm 02:01 PM
Tokenbasierte Authentifizierung mit Angular und Node
Sep 01, 2023 pm 02:01 PM
Die Authentifizierung ist einer der wichtigsten Teile jeder Webanwendung. In diesem Tutorial werden tokenbasierte Authentifizierungssysteme und ihre Unterschiede zu herkömmlichen Anmeldesystemen erläutert. Am Ende dieses Tutorials sehen Sie eine voll funktionsfähige Demo, die in Angular und Node.js geschrieben wurde. Traditionelle Authentifizierungssysteme Bevor wir zu tokenbasierten Authentifizierungssystemen übergehen, werfen wir einen Blick auf traditionelle Authentifizierungssysteme. Der Benutzer gibt seinen Benutzernamen und sein Passwort im Anmeldeformular ein und klickt auf „Anmelden“. Nachdem Sie die Anfrage gestellt haben, authentifizieren Sie den Benutzer im Backend, indem Sie die Datenbank abfragen. Wenn die Anfrage gültig ist, wird eine Sitzung mit den aus der Datenbank erhaltenen Benutzerinformationen erstellt und die Sitzungsinformationen werden im Antwortheader zurückgegeben, sodass die Sitzungs-ID im Browser gespeichert wird. Bietet Zugriff auf Anwendungen, die unterliegen
 Was ist ein Single-Sign-On-System? Wie implementiert man es mit NodeJS?
Feb 24, 2023 pm 07:33 PM
Was ist ein Single-Sign-On-System? Wie implementiert man es mit NodeJS?
Feb 24, 2023 pm 07:33 PM
Was ist ein Single-Sign-On-System? Wie implementiert man es mit NodeJS? Im folgenden Artikel erfahren Sie, wie Sie mit Node ein Single-Sign-On-System implementieren. Ich hoffe, dass er Ihnen weiterhilft!
