
 Backend-Entwicklung
Python-Tutorial
Pytorch + Visdom behandelt einfache Klassifizierungsprobleme
Backend-Entwicklung
Python-Tutorial
Pytorch + Visdom behandelt einfache Klassifizierungsprobleme
Pytorch + Visdom behandelt einfache Klassifizierungsprobleme

Dieser Artikel stellt hauptsächlich vor, wie Pytorch + Visdom mit einfachen Klassifizierungsproblemen umgeht. Er hat einen gewissen Referenzwert. Jetzt können Freunde in Not darauf verweisen.
Umgebung 🎜>
System: Win 10Grafikkarte: GTX965M
CPU: i7-6700HQ
Python 3.61
Pytorch 0.3
Paketreferenz
import torch from torch.autograd import Variable import torch.nn.functional as F import numpy as np import visdom import time from torch import nn,optim
Datenaufbereitung
use_gpu = True ones = np.ones((500,2)) x1 = torch.normal(6*torch.from_numpy(ones),2) y1 = torch.zeros(500) x2 = torch.normal(6*torch.from_numpy(ones*[-1,1]),2) y2 = y1 +1 x3 = torch.normal(-6*torch.from_numpy(ones),2) y3 = y1 +2 x4 = torch.normal(6*torch.from_numpy(ones*[1,-1]),2) y4 = y1 +3 x = torch.cat((x1, x2, x3 ,x4), 0).float() y = torch.cat((y1, y2, y3, y4), ).long()
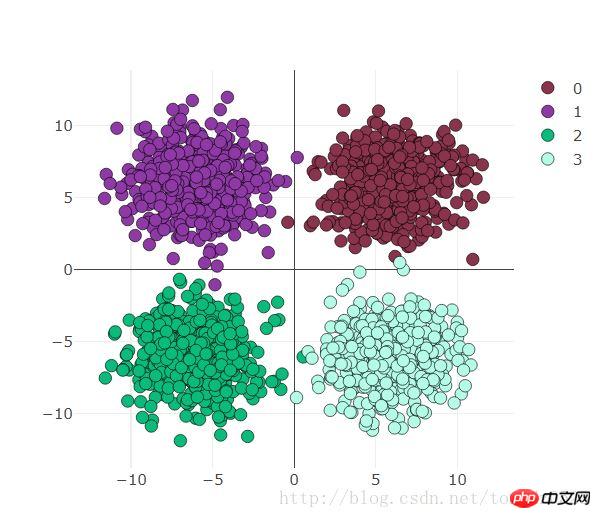
Visdom-Visualisierungsvorbereitung
Erstellen Sie zunächst die Fenster, die beobachtet werden müssenviz = visdom.Visdom()
colors = np.random.randint(0,255,(4,3)) #颜色随机
#线图用来观察loss 和 accuracy
line = viz.line(X=np.arange(1,10,1), Y=np.arange(1,10,1))
#散点图用来观察分类变化
scatter = viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]),)
#text 窗口用来显示loss 、accuracy 、时间
text = viz.text("FOR TEST")
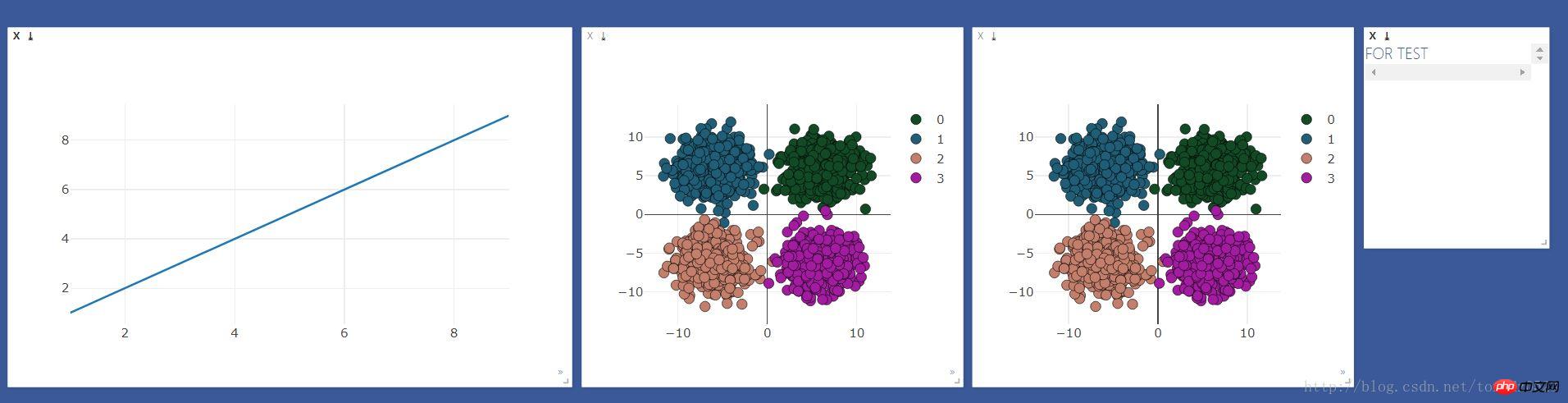
#散点图做对比
viz.scatter(
X=x,
Y=y+1,
opts=dict(
markercolor = colors,
marksize = 5,
legend=["0","1","2","3"]
),
) 
Logistische Regressionsverarbeitung
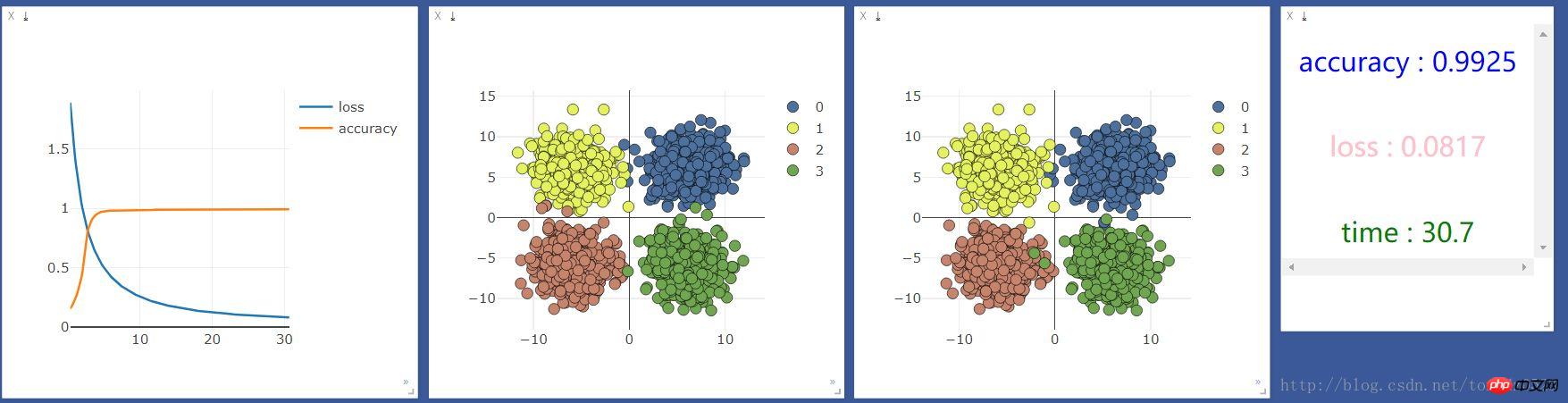
Eingabe 2, Ausgabe 4logstic = nn.Sequential( nn.Linear(2,4) )
if use_gpu:
gpu_status = torch.cuda.is_available()
if gpu_status:
logstic = logstic.cuda()
# net = net.cuda()
print("###############使用gpu##############")
else : print("###############使用cpu##############")
else:
gpu_status = False
print("###############使用cpu##############")loss_f = nn.CrossEntropyLoss() optimizer_l = optim.SGD(logstic.parameters(), lr=0.001)
start_time = time.time()
time_point, loss_point, accuracy_point = [], [], []
for t in range(2000):
if gpu_status:
train_x = Variable(x).cuda()
train_y = Variable(y).cuda()
else:
train_x = Variable(x)
train_y = Variable(y)
# out = net(train_x)
out_l = logstic(train_x)
loss = loss_f(out_l,train_y)
optimizer_l.zero_grad()
loss.backward()
optimizer_l.step()if t % 10 == 0:
prediction = torch.max(F.softmax(out_l, 1), 1)[1]
pred_y = prediction.data
accuracy = sum(pred_y ==train_y.data)/float(2000.0)
loss_point.append(loss.data[0])
accuracy_point.append(accuracy)
time_point.append(time.time()-start_time)
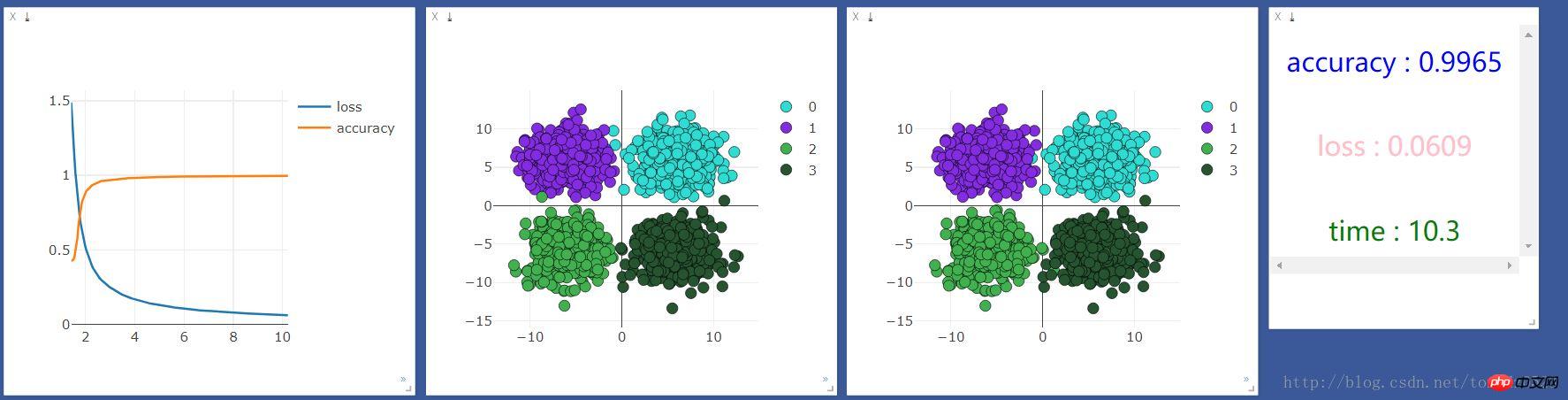
print("[{}/{}] | accuracy : {:.3f} | loss : {:.3f} | time : {:.2f} ".format(t + 1, 2000, accuracy, loss.data[0],
time.time() - start_time))
viz.line(X=np.column_stack((np.array(time_point),np.array(time_point))),
Y=np.column_stack((np.array(loss_point),np.array(accuracy_point))),
win=line,
opts=dict(legend=["loss", "accuracy"]))
#这里的数据如果用gpu跑会出错,要把数据换成cpu的数据 .cpu()即可
viz.scatter(X=train_x.cpu().data, Y=pred_y.cpu()+1, win=scatter,name="add",
opts=dict(markercolor=colors,legend=["0", "1", "2", "3"]))
viz.text("<h3 align='center' style='color:blue'>accuracy : {}</h3><br><h3 align='center' style='color:pink'>"
"loss : {:.4f}</h3><br><h3 align ='center' style='color:green'>time : {:.1f}</h3>"
.format(accuracy,loss.data[0],time.time()-start_time),win =text)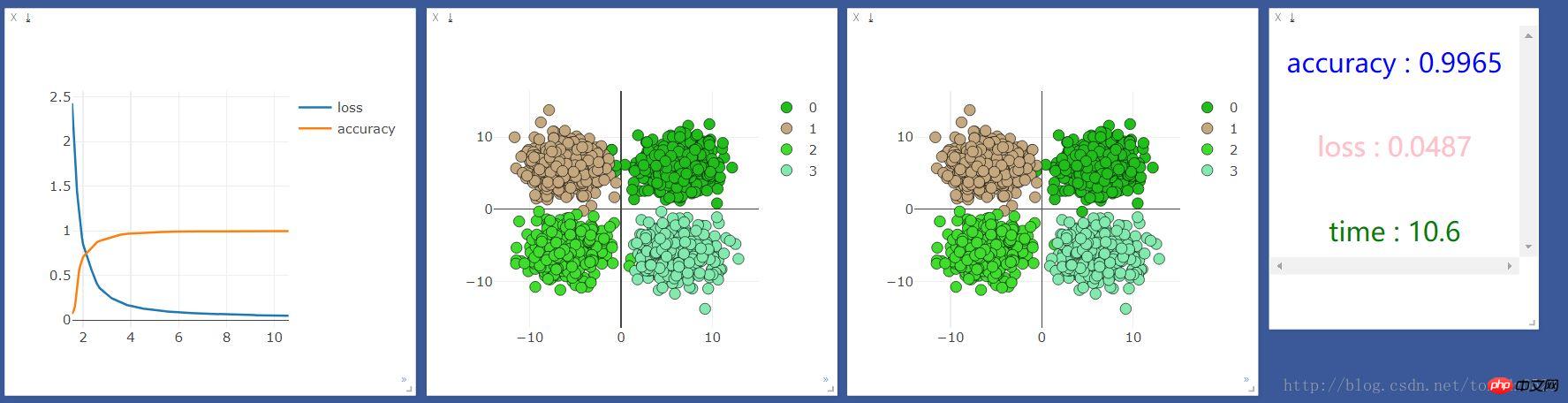
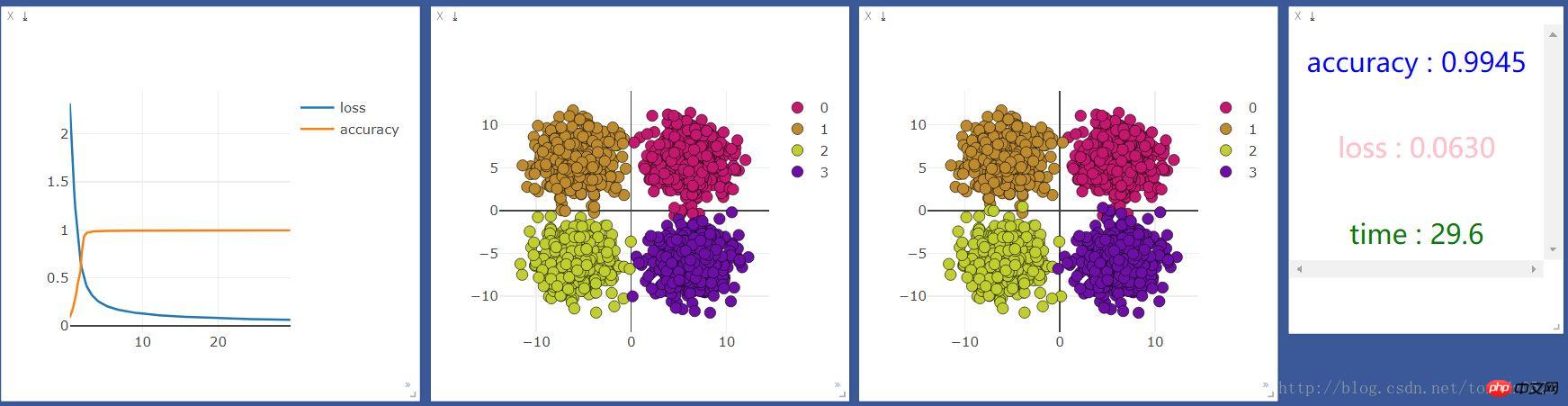

Fügen Sie eine neuronale Ebene hinzu:
net = nn.Sequential( nn.Linear(2, 10), nn.ReLU(), #激活函数 nn.Linear(10, 4) )
Ein Beispiel für den Aufbau eines einfachen neuronalen Netzwerks zur Implementierung von Regression und Klassifizierung auf PyTorch
Detaillierte Erläuterung des PyTorch Batch-Trainings und des Optimierungsvergleichs
Das obige ist der detaillierte Inhalt vonPytorch + Visdom behandelt einfache Klassifizierungsprobleme. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 iFlytek: Die Fähigkeiten des Ascend 910B von Huawei sind grundsätzlich mit denen des A100 von Nvidia vergleichbar, und sie arbeiten zusammen, um eine neue Basis für die allgemeine künstliche Intelligenz meines Landes zu schaffen
Oct 22, 2023 pm 06:13 PM
iFlytek: Die Fähigkeiten des Ascend 910B von Huawei sind grundsätzlich mit denen des A100 von Nvidia vergleichbar, und sie arbeiten zusammen, um eine neue Basis für die allgemeine künstliche Intelligenz meines Landes zu schaffen
Oct 22, 2023 pm 06:13 PM
Diese Website berichtete am 22. Oktober, dass iFlytek im dritten Quartal dieses Jahres einen Nettogewinn von 25,79 Millionen Yuan erzielte, was einem Rückgang von 81,86 % gegenüber dem Vorjahr entspricht; der Nettogewinn in den ersten drei Quartalen betrug 99,36 Millionen Yuan Rückgang um 76,36 % gegenüber dem Vorjahr. Jiang Tao, Vizepräsident von iFlytek, gab bei der Leistungsbesprechung im dritten Quartal bekannt, dass iFlytek Anfang 2023 ein spezielles Forschungsprojekt mit Huawei Shengteng gestartet und gemeinsam mit Huawei eine leistungsstarke Betreiberbibliothek entwickelt hat, um gemeinsam eine neue Basis für Chinas allgemeine künstliche Intelligenz zu schaffen Intelligenz, die den Einsatz inländischer Großmodelle ermöglicht. Die Architektur basiert auf unabhängig innovativer Soft- und Hardware. Er wies darauf hin, dass die aktuellen Fähigkeiten des Huawei Ascend 910B grundsätzlich mit dem A100 von Nvidia vergleichbar seien. Auf dem bevorstehenden iFlytek 1024 Global Developer Festival werden iFlytek und Huawei weitere gemeinsame Ankündigungen zur Rechenleistungsbasis für künstliche Intelligenz machen. Er erwähnte auch,
 Die perfekte Kombination aus PyCharm und PyTorch: detaillierte Installations- und Konfigurationsschritte
Feb 21, 2024 pm 12:00 PM
Die perfekte Kombination aus PyCharm und PyTorch: detaillierte Installations- und Konfigurationsschritte
Feb 21, 2024 pm 12:00 PM
PyCharm ist eine leistungsstarke integrierte Entwicklungsumgebung (IDE) und PyTorch ist ein beliebtes Open-Source-Framework im Bereich Deep Learning. Im Bereich maschinelles Lernen und Deep Learning kann die Verwendung von PyCharm und PyTorch für die Entwicklung die Entwicklungseffizienz und Codequalität erheblich verbessern. In diesem Artikel wird detailliert beschrieben, wie PyTorch in PyCharm installiert und konfiguriert wird, und es werden spezifische Codebeispiele angehängt, um den Lesern zu helfen, die leistungsstarken Funktionen dieser beiden besser zu nutzen. Schritt 1: Installieren Sie PyCharm und Python
 Einführung in fünf Stichprobenmethoden bei Aufgaben zur Generierung natürlicher Sprache und bei der Implementierung von Pytorch-Code
Feb 20, 2024 am 08:50 AM
Einführung in fünf Stichprobenmethoden bei Aufgaben zur Generierung natürlicher Sprache und bei der Implementierung von Pytorch-Code
Feb 20, 2024 am 08:50 AM
Bei Aufgaben zur Generierung natürlicher Sprache ist die Stichprobenmethode eine Technik, um eine Textausgabe aus einem generativen Modell zu erhalten. In diesem Artikel werden fünf gängige Methoden erläutert und mit PyTorch implementiert. 1. GreedyDecoding Bei der Greedy-Decodierung sagt das generative Modell die Wörter der Ausgabesequenz basierend auf der Eingabesequenz Zeit Schritt für Zeit voraus. In jedem Zeitschritt berechnet das Modell die bedingte Wahrscheinlichkeitsverteilung jedes Wortes und wählt dann das Wort mit der höchsten bedingten Wahrscheinlichkeit als Ausgabe des aktuellen Zeitschritts aus. Dieses Wort wird zur Eingabe für den nächsten Zeitschritt und der Generierungsprozess wird fortgesetzt, bis eine Abschlussbedingung erfüllt ist, beispielsweise eine Sequenz mit einer bestimmten Länge oder eine spezielle Endmarkierung. Das Merkmal von GreedyDecoding besteht darin, dass die aktuelle bedingte Wahrscheinlichkeit jedes Mal die beste ist
 Implementierung eines Rauschentfernungs-Diffusionsmodells mit PyTorch
Jan 14, 2024 pm 10:33 PM
Implementierung eines Rauschentfernungs-Diffusionsmodells mit PyTorch
Jan 14, 2024 pm 10:33 PM
Bevor wir das Funktionsprinzip des Denoising Diffusion Probabilistic Model (DDPM) im Detail verstehen, wollen wir zunächst einige Aspekte der Entwicklung generativer künstlicher Intelligenz verstehen, die auch zu den Grundlagenforschungen von DDPM gehört. VAEVAE verwendet einen Encoder, einen probabilistischen latenten Raum und einen Decoder. Während des Trainings sagt der Encoder den Mittelwert und die Varianz jedes Bildes voraus und tastet diese Werte aus einer Gaußschen Verteilung ab. Das Ergebnis der Abtastung wird an den Decoder weitergeleitet, der das Eingabebild in eine dem Ausgabebild ähnliche Form umwandelt. Zur Berechnung des Verlusts wird die KL-Divergenz verwendet. Ein wesentlicher Vorteil von VAE ist die Fähigkeit, vielfältige Bilder zu erzeugen. In der Abtastphase kann man direkt aus der Gaußschen Verteilung Stichproben ziehen und über den Decoder neue Bilder erzeugen. GAN hat in nur einem Jahr große Fortschritte bei Variational Autoencodern (VAEs) gemacht.
 Tutorial zur Installation von PyCharm mit PyTorch
Feb 24, 2024 am 10:09 AM
Tutorial zur Installation von PyCharm mit PyTorch
Feb 24, 2024 am 10:09 AM
Als leistungsstarkes Deep-Learning-Framework wird PyTorch häufig in verschiedenen maschinellen Lernprojekten eingesetzt. Als leistungsstarke integrierte Python-Entwicklungsumgebung kann PyCharm auch bei der Umsetzung von Deep-Learning-Aufgaben eine gute Unterstützung bieten. In diesem Artikel wird die Installation von PyTorch in PyCharm ausführlich vorgestellt und spezifische Codebeispiele bereitgestellt, um den Lesern den schnellen Einstieg in die Verwendung von PyTorch für Deep-Learning-Aufgaben zu erleichtern. Schritt 1: Installieren Sie PyCharm. Zuerst müssen wir sicherstellen, dass wir es haben
 Deep Learning mit PHP und PyTorch
Jun 19, 2023 pm 02:43 PM
Deep Learning mit PHP und PyTorch
Jun 19, 2023 pm 02:43 PM
Deep Learning ist ein wichtiger Zweig im Bereich der künstlichen Intelligenz und hat in den letzten Jahren immer mehr Aufmerksamkeit erhalten. Um Deep-Learning-Forschung und -Anwendungen durchführen zu können, ist es oft notwendig, einige Deep-Learning-Frameworks zu verwenden, um dies zu erreichen. In diesem Artikel stellen wir vor, wie man PHP und PyTorch für Deep Learning verwendet. 1. Was ist PyTorch? PyTorch ist ein von Facebook entwickeltes Open-Source-Framework für maschinelles Lernen. Es kann uns helfen, schnell Deep-Learning-Modelle zu erstellen und zu trainieren. PyTorc
 so schnell! Erkennen Sie Videosprache in nur wenigen Minuten mit weniger als 10 Codezeilen in Text
Feb 27, 2024 pm 01:55 PM
so schnell! Erkennen Sie Videosprache in nur wenigen Minuten mit weniger als 10 Codezeilen in Text
Feb 27, 2024 pm 01:55 PM
Hallo zusammen, ich bin Kite. Die Notwendigkeit, Audio- und Videodateien in Textinhalte umzuwandeln, war vor zwei Jahren schwierig, aber jetzt kann dies problemlos in nur wenigen Minuten gelöst werden. Es heißt, dass einige Unternehmen, um Trainingsdaten zu erhalten, Videos auf Kurzvideoplattformen wie Douyin und Kuaishou vollständig gecrawlt haben, dann den Ton aus den Videos extrahiert und sie in Textform umgewandelt haben, um sie als Trainingskorpus für Big-Data-Modelle zu verwenden . Wenn Sie eine Video- oder Audiodatei in Text konvertieren müssen, können Sie diese heute verfügbare Open-Source-Lösung ausprobieren. Sie können beispielsweise nach bestimmten Zeitpunkten suchen, zu denen Dialoge in Film- und Fernsehsendungen erscheinen. Kommen wir ohne weitere Umschweife zum Punkt. Whisper ist OpenAIs Open-Source-Whisper. Es ist natürlich in Python geschrieben und erfordert nur ein paar einfache Installationspakete.
 So installieren Sie Pytorch in PyCharm
Dec 08, 2023 pm 03:05 PM
So installieren Sie Pytorch in PyCharm
Dec 08, 2023 pm 03:05 PM
Installationsschritte: 1. Öffnen Sie PyCharm und erstellen Sie ein neues Python-Projekt. 2. Klicken Sie in der unteren Statusleiste von PyCharm auf das „Terminal“-Symbol, um das Terminalfenster zu öffnen. 3. Verwenden Sie im Terminalfenster den Befehl pip, um PyTorch zu installieren Je nach System und Anforderungen können Sie verschiedene Installationsmethoden auswählen. 4. Nach Abschluss der Installation können Sie Code in PyCharm schreiben und die PyTorch-Bibliothek importieren, um ihn zu verwenden.
