

So erhalten Sie Tag-Inhalte mit JS
Dieses Mal zeige ich Ihnen, wie Sie JS zum Abrufen von Tag-Inhalten verwenden und welche Vorsichtsmaßnahmen für die Verwendung von JS zum Abrufen von Tag-Inhalten gelten. Das Folgende ist ein praktischer Fall, schauen wir uns das an.
Bei unserer täglichen JS-Programmierung müssen wir häufig den Inhalt von Tags abrufen und diese bearbeiten. Es gibt viele Details, die wir leicht übersehen. Jetzt werde ich es anhand der Methoden, die ich normalerweise verwende, kurz zusammenfassen. Sollten Fehler vorhanden sein, korrigieren Sie diese bitte.
Die HTML-Struktur ist wie folgt:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <p id="box"> <p>这有个 第一个p</p> <p>这有个第二个p</p> <span>这是个 span</span> <br> <a href="#">这有个a标签</a> </p> </body> </html>
Diese Methode kann den gesamten Inhalt im Tag abrufen, einschließlich Tags, Leerzeichen, Text, Zeilenumbrüche usw.
Methode 1, innerHTML
<script>
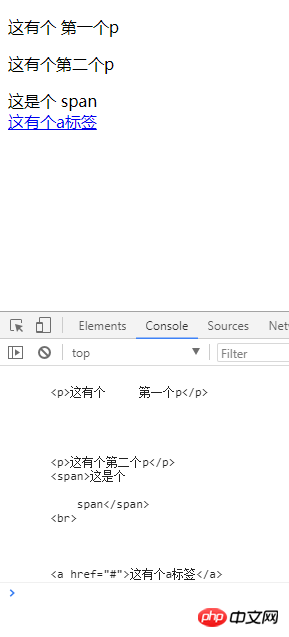
var box = document.getElementById('box');// 获取标签的内容
var box1 = box.innerHTML;
console.log(box1);</script>JS-Code und Renderings lauten wie folgt:
innerHTML ruft den Inhalt im Tag ab
Wenn Sie den Inhalt des Tags löschen möchten, innerHTML = "" das ist es
Wenn Sie den Inhalt des Tags festlegen möchten, füllen Sie das Tag und den Inhalt aus Sie möchten festlegen“; beim Festlegen des Inhalts werden alle Originalinhalte überschrieben.
Ich glaube, dass Sie die Methode beherrschen, nachdem Sie den Fall in diesem Artikel gelesen haben. Weitere spannende Informationen finden Sie in anderen verwandten Artikeln auf der chinesischen PHP-Website!
Empfohlene Lektüre:
So verwenden Sie den Filter global
Detaillierte Erläuterung der Anwendungsfälle der JS-Framework-Bibliothek
Das obige ist der detaillierte Inhalt vonSo erhalten Sie Tag-Inhalte mit JS. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So ändern Sie den Microsoft Edge-Browser so, dass er mit 360-Navigation geöffnet wird - So ändern Sie die Öffnung mit 360-Navigation
Mar 04, 2024 pm 01:50 PM
So ändern Sie den Microsoft Edge-Browser so, dass er mit 360-Navigation geöffnet wird - So ändern Sie die Öffnung mit 360-Navigation
Mar 04, 2024 pm 01:50 PM
Wie ändere ich die Seite, die den Microsoft Edge-Browser öffnet, auf 360-Navigation? Es ist eigentlich sehr einfach, deshalb werde ich Ihnen jetzt die Methode vorstellen, die Seite zu ändern, die den Microsoft Edge-Browser auf 360-Navigation öffnet Schau mal. Ich hoffe, ich kann allen helfen. Öffnen Sie den Microsoft Edge-Browser. Wir sehen eine Seite wie die folgende. Klicken Sie auf das Dreipunktsymbol in der oberen rechten Ecke. Klicken Sie auf „Einstellungen“. Klicken Sie in der linken Spalte der Einstellungsseite auf „Beim Start“. Klicken Sie auf die drei im Bild in der rechten Spalte angezeigten Punkte (klicken Sie nicht auf „Neuen Tab öffnen“), klicken Sie dann auf Bearbeiten und ändern Sie die URL in „0“ (oder andere bedeutungslose Zahlen). Klicken Sie anschließend auf „Speichern“. Wählen Sie als Nächstes „
 So suchen Sie auf allen Registerkarten in Chrome und Edge nach Text
Feb 19, 2024 am 11:30 AM
So suchen Sie auf allen Registerkarten in Chrome und Edge nach Text
Feb 19, 2024 am 11:30 AM
Dieses Tutorial zeigt Ihnen, wie Sie bestimmte Texte oder Phrasen auf allen geöffneten Tabs in Chrome oder Edge unter Windows finden. Gibt es eine Möglichkeit, eine Textsuche auf allen geöffneten Tabs in Chrome durchzuführen? Ja, Sie können eine kostenlose externe Weberweiterung in Chrome verwenden, um Textsuchen auf allen geöffneten Tabs durchzuführen, ohne die Tabs manuell wechseln zu müssen. Einige Erweiterungen wie TabSearch und Strg-FPlus können Ihnen dabei helfen, dies einfach zu erreichen. Wie durchsucht man Text auf allen Registerkarten in Google Chrome? Strg-FPlus ist eine kostenlose Erweiterung, die es Benutzern erleichtert, auf allen Registerkarten ihres Browserfensters nach einem bestimmten Wort, einer bestimmten Phrase oder einem bestimmten Text zu suchen. Diese Erweiterung
 Wie richte ich die Cheat Engine auf Chinesisch ein? Cheat Engine-Einstellung chinesische Methode
Mar 13, 2024 pm 04:49 PM
Wie richte ich die Cheat Engine auf Chinesisch ein? Cheat Engine-Einstellung chinesische Methode
Mar 13, 2024 pm 04:49 PM
CheatEngine ist ein Spieleeditor, der den Speicher des Spiels bearbeiten und ändern kann. Die Standardsprache ist jedoch nicht Chinesisch, was für viele Freunde unpraktisch ist. Wie stellt man Chinesisch in CheatEngine ein? Heute gibt Ihnen der Herausgeber eine detaillierte Einführung in die Einrichtung von Chinesisch in CheatEngine. Ich hoffe, es kann Ihnen helfen. Einstellungsmethode eins: 1. Doppelklicken Sie, um die Software zu öffnen, und klicken Sie oben links auf „Bearbeiten“. 2. Klicken Sie dann in der Optionsliste unten auf „Einstellungen“. 3. Klicken Sie in der geöffneten Fensteroberfläche in der linken Spalte auf „Sprachen“.
 Wie füge ich Tags auf Douyin hinzu, um Traffic anzulocken? Zu welchen Tags auf der Plattform lässt sich am einfachsten Traffic anziehen?
Mar 22, 2024 am 10:28 AM
Wie füge ich Tags auf Douyin hinzu, um Traffic anzulocken? Zu welchen Tags auf der Plattform lässt sich am einfachsten Traffic anziehen?
Mar 22, 2024 am 10:28 AM
Als beliebte soziale Plattform für Kurzvideos verfügt Douyin über eine riesige Nutzerbasis. Für Douyin-Ersteller ist die Verwendung von Tags zur Gewinnung von Traffic eine wirksame Möglichkeit, die Bekanntheit von Inhalten zu erhöhen und Aufmerksamkeit zu erregen. Wie nutzt Douyin also Tags, um Traffic anzulocken? Dieser Artikel beantwortet diese Frage ausführlich für Sie und stellt verwandte Techniken vor. 1. Wie füge ich Tags auf Douyin hinzu, um Traffic anzulocken? Achten Sie beim Posten eines Videos darauf, Tags auszuwählen, die für den Inhalt relevant sind. Diese Tags sollten das Thema und die Schlüsselwörter Ihres Videos abdecken, damit Benutzer Ihr Video mithilfe von Tags leichter finden können. Die Nutzung beliebter Hashtags ist eine effektive Möglichkeit, die Bekanntheit Ihres Videos zu erhöhen. Recherchieren Sie aktuelle beliebte Tags und Trends und integrieren Sie diese in Ihre Videobeschreibungen und Tags. Diese beliebten Tags sind in der Regel besser sichtbar und können die Aufmerksamkeit von mehr Zuschauern auf sich ziehen. 3. Etikett
 Wo wird die Download-Schaltfläche in Microsoft Edge festgelegt? – So richten Sie die Download-Schaltfläche in Microsoft Edge ein
Mar 06, 2024 am 11:49 AM
Wo wird die Download-Schaltfläche in Microsoft Edge festgelegt? – So richten Sie die Download-Schaltfläche in Microsoft Edge ein
Mar 06, 2024 am 11:49 AM
Wissen Sie, wo Sie die Download-Schaltfläche für die Anzeige in Microsoft Edge festlegen müssen? Im Folgenden erfahren Sie, wie Sie die Download-Schaltfläche für die Anzeige in Microsoft Edge festlegen Darüber! Schritt 1: Öffnen Sie zunächst den Microsoft Edge-Browser und klicken Sie auf das [...]-Logo in der oberen rechten Ecke, wie in der Abbildung unten gezeigt. Schritt 2: Klicken Sie dann im Popup-Menü auf [Einstellungen], wie in der Abbildung unten gezeigt. Schritt 3: Klicken Sie dann auf der linken Seite der Benutzeroberfläche auf [Darstellung], wie in der Abbildung unten gezeigt. Schritt 4: Klicken Sie abschließend auf die Schaltfläche auf der rechten Seite von [Download-Schaltfläche anzeigen] und sie wechselt von Grau zu Blau, wie in der Abbildung unten gezeigt. Oben zeigt Ihnen der Editor, wie Sie die Download-Schaltfläche in Microsoft Edge einrichten.
 Was ist die Uhr hinter dem TikTok-Label? Wie markiere ich ein Douyin-Konto?
Mar 24, 2024 pm 03:46 PM
Was ist die Uhr hinter dem TikTok-Label? Wie markiere ich ein Douyin-Konto?
Mar 24, 2024 pm 03:46 PM
Wenn wir Douyin-Werke durchsuchen, sehen wir oft ein Uhrsymbol hinter dem Tag. Was genau ist diese Uhr also? Dieser Artikel konzentriert sich auf die Diskussion „Was ist die Uhr hinter dem Douyin-Label“ und hofft, Ihnen nützliche Hinweise für die Verwendung von Douyin zu geben. 1. Was ist die Uhr hinter dem Douyin-Label? Douyin wird einige heiße Themenherausforderungen starten. Wenn Benutzer teilnehmen, sehen sie nach dem Tag ein Uhrsymbol, was bedeutet, dass die Arbeit an der Themenherausforderung teilnimmt, und zeigt die verbleibende Zeit der Herausforderung an. Bei einigen zeitkritischen Inhalten wie Feiertagen, besonderen Ereignissen usw. fügt Douyin nach dem Etikett ein Uhrensymbol hinzu, um Benutzer an die Gültigkeitsdauer des Inhalts zu erinnern. 3. Beliebte Tags: Wenn ein Tag beliebt wird, fügt Douyin hinter dem Tag ein Uhrsymbol ein, um anzuzeigen, dass der Tag beliebt ist
 Einfaches JavaScript-Tutorial: So erhalten Sie den HTTP-Statuscode
Jan 05, 2024 pm 06:08 PM
Einfaches JavaScript-Tutorial: So erhalten Sie den HTTP-Statuscode
Jan 05, 2024 pm 06:08 PM
JavaScript-Tutorial: So erhalten Sie HTTP-Statuscode. Es sind spezifische Codebeispiele erforderlich. Vorwort: Bei der Webentwicklung ist häufig die Dateninteraktion mit dem Server erforderlich. Bei der Kommunikation mit dem Server müssen wir häufig den zurückgegebenen HTTP-Statuscode abrufen, um festzustellen, ob der Vorgang erfolgreich ist, und die entsprechende Verarbeitung basierend auf verschiedenen Statuscodes durchführen. In diesem Artikel erfahren Sie, wie Sie mit JavaScript HTTP-Statuscodes abrufen und einige praktische Codebeispiele bereitstellen. Verwenden von XMLHttpRequest
 Ein genauerer Blick auf das Videoelement in HTML
Feb 24, 2024 pm 08:18 PM
Ein genauerer Blick auf das Videoelement in HTML
Feb 24, 2024 pm 08:18 PM
Ausführliche Erklärung des Video-Tags in HTML Der Video-Tag in HTML5 ist ein Tag, der zum Abspielen von Videos auf Webseiten verwendet wird. Es kann Videos in verschiedenen Formaten rendern, z. B. MP4, WebM, Ogg und mehr. In diesem Artikel stellen wir die Verwendung von Video-Tags im Detail vor und stellen spezifische Codebeispiele bereit. Grundstruktur Das Folgende ist die Grundstruktur des Video-Tags:
