
 Web-Frontend
js-Tutorial
So implementieren Sie den Baidu-Index-Crawler mithilfe der Bilderkennungstechnologie Puppeteer
Web-Frontend
js-Tutorial
So implementieren Sie den Baidu-Index-Crawler mithilfe der Bilderkennungstechnologie Puppeteer
So implementieren Sie den Baidu-Index-Crawler mithilfe der Bilderkennungstechnologie Puppeteer
In diesem Artikel wird hauptsächlich das Beispiel der Node Puppeteer-Bilderkennung zur Implementierung des Baidu-Index-Crawlers vorgestellt. Der Herausgeber findet es recht gut, daher werde ich es jetzt mit Ihnen teilen und als Referenz verwenden. Folgen wir dem Herausgeber und werfen wir einen Blick darauf
Ich habe zuvor einen aufschlussreichen Artikel gelesen, in dem die Front-End-Anti-Crawler-Techniken verschiedener großer Hersteller vorgestellt wurden, aber wie in diesem Artikel gesagt wurde, gibt es keine 100%ige Anti- Crawler-Methode: In diesem Artikel wird eine einfache Methode zum Umgehen aller dieser Front-End-Anti-Crawler-Methoden vorgestellt.
Der folgende Code verwendet Baidu Index als Beispiel. Der Code wurde in eine Baidu Index-Crawler-Knotenbibliothek gepackt: https://github.com/Coffcer/baidu-index-spider
Hinweis: Bitte missbrauchen Sie Crawler nicht, um anderen Ärger zu bereiten
Anti-Crawler-Strategie von Baidu Index
Beachten Sie die Benutzeroberfläche von Baidu Index Bei den Indexdaten handelt es sich um ein Trenddiagramm. Wenn die Maus über einen bestimmten Tag fährt, werden zwei Anfragen ausgelöst und die Ergebnisse im schwebenden Feld angezeigt:
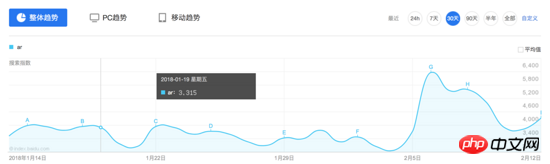
Im Anschluss an das Allgemeine Idee, schauen wir uns zunächst den Inhalt dieser Anfrage an:
Anfrage 1:
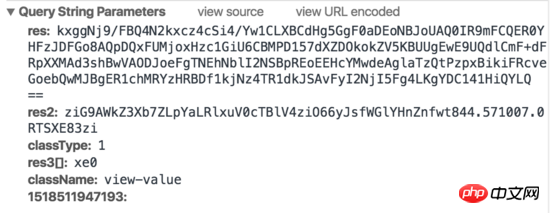
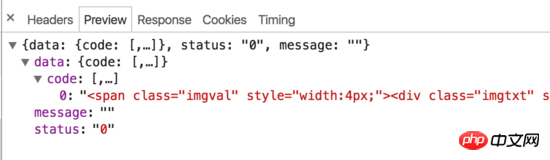
Anfrage 2:

Es kann festgestellt werden, dass Baidu Index tatsächlich bestimmte Anti-Crawler-Strategien im Frontend implementiert hat. Wenn die Maus über das Diagramm bewegt wird, werden zwei Anfragen ausgelöst, eine Anfrage gibt ein Stück HTML zurück und eine Anfrage gibt ein generiertes Bild zurück. Der HTML-Code enthält keine tatsächlichen Werte, sondern zeigt die entsprechenden Zeichen auf dem Bild an, indem Breite und Rand links festgelegt werden. Darüber hinaus enthalten die Anforderungsparameter Parameter wie res und res1, die wir nicht simulieren können, sodass es schwierig ist, die Baidu-Indexdaten mit herkömmlichen simulierten Anforderungen oder HTML-Crawling-Methoden zu crawlen.
Crawler-Ideen
Wie kann man Baidus Anti-Crawler-Methode durchbrechen? Es ist eigentlich ganz einfach, ignorieren Sie einfach, wie es Crawler bekämpft. Wir müssen lediglich Benutzervorgänge simulieren, einen Screenshot der erforderlichen Werte erstellen und eine Bilderkennung durchführen. Die Schritte sind ungefähr:
Anmeldung simulieren
Indexseite öffnen
Maus bewegen bis zum angegebenen Datum
Warten Sie, bis die Anforderung beendet ist, und fangen Sie den numerischen Teil des Bildes ab
Bilderkennung, um den Wert zu erhalten
Schleifen Sie die Schritte 3 bis 5 ab und ermitteln Sie den Wert, der jedem Datum entspricht.
Mit dieser Methode können wir theoretisch den Inhalt jeder Website crawlen Implementieren Sie den Crawler Schritt für Schritt. Die folgende Bibliothek ist angekommen:
Puppenspieler Browser-Bedienung simulieren
node-tesseract Tesseract-Paket, wird für die Bilderkennung verwendet
jimpBildzuschnitt
Installieren Sie Puppeteer und simulieren Sie Benutzervorgänge
Puppeteer ist ein vom Google Chrome-Team entwickeltes Chrome-Automatisierungstool, das zur Steuerung von Chrome-Ausführungsbefehlen verwendet wird. Sie können Benutzervorgänge simulieren, automatisierte Tests, Crawler usw. durchführen. Die Verwendung ist sehr einfach. Es gibt viele Einführungs-Tutorials im Internet. Nach dem Lesen dieses Artikels können Sie wahrscheinlich wissen, wie man es verwendet.
API-Dokumentation: https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md
Installation:
npm install --save puppeteer
Puppeteer lädt Chromium automatisch herunter um sicherzustellen, dass es ordnungsgemäß funktioniert. Inländische Netzwerke können Chromium jedoch möglicherweise nicht erfolgreich herunterladen. Wenn der Download fehlschlägt, können Sie es mit cnpm installieren oder die Download-Adresse auf den Taobao-Spiegel ändern und es dann installieren:
npm config set PUPPETEER_DOWNLOAD_HOST=https://npm.taobao.org/mirrors npm install --save puppeteer
Das ist auch möglich Überspringen Sie Chromium während der Installation. Laden Sie es herunter und führen Sie es aus, indem Sie den nativen Chrome-Pfad über den Code angeben:
// npm
npm install --save puppeteer --ignore-scripts
// node
puppeteer.launch({ executablePath: '/path/to/Chrome' });Implementierung
Um das Layout sauber zu halten, werden nur die Hauptteile aufgelistet unten, und der Code beinhaltet stattdessen den Selektorteil All used... Den vollständigen Code finden Sie im Github-Repository oben im Artikel.
Öffnen Sie die Baidu-Indexseite und simulieren Sie die Anmeldung
Hier werden Benutzervorgänge, Klicks und Eingaben Schritt für Schritt simuliert. Die Handhabung des Anmeldebestätigungscodes ist nicht erforderlich. Wenn Sie sich lokal bei Baidu angemeldet haben, benötigen Sie im Allgemeinen keinen Bestätigungscode.
// 启动浏览器,
// headless参数如果设置为true,Puppeteer将在后台操作你Chromium,换言之你将看不到浏览器的操作过程
// 设为false则相反,会在你电脑上打开浏览器,显示浏览器每一操作。
const browser = await puppeteer.launch({headless:false});
const page = await browser.newPage();
// 打开百度指数
await page.goto(BAIDU_INDEX_URL);
// 模拟登陆
await page.click('...');
await page.waitForSelecto('...');
// 输入百度账号密码然后登录
await page.type('...','username');
await page.type('...','password');
await page.click('...');
await page.waitForNavigation();
console.log(':white_check_mark: 登录成功');Simulieren Sie die Bewegung der Maus, um die erforderlichen Daten zu erhalten
Sie müssen auf der Seite zum Trenddiagrammbereich scrollen, dann die Maus auf ein bestimmtes Datum bewegen und warten bis die Anfrage beendet ist. Der Tooltip zeigt den Wert an und erstellt dann einen Screenshot, um das Bild zu speichern.
// 获取chart第一天的坐标
const position = await page.evaluate(() => {
const $image = document.querySelector('...');
const $area = document.querySelector('...');
const areaRect = $area.getBoundingClientRect();
const imageRect = $image.getBoundingClientRect();
// 滚动到图表可视化区域
window.scrollBy(0, areaRect.top);
return { x: imageRect.x, y: 200 };
});
// 移动鼠标,触发tooltip
await page.mouse.move(position.x, position.y);
await page.waitForSelector('...');
// 获取tooltip信息
const tooltipInfo = await page.evaluate(() => {
const $tooltip = document.querySelector('...');
const $title = $tooltip.querySelector('...');
const $value = $tooltip.querySelector('...');
const valueRect = $value.getBoundingClientRect();
const padding = 5;
return {
title: $title.textContent.split(' ')[0],
x: valueRect.x - padding,
y: valueRect.y,
width: valueRect.width + padding * 2,
height: valueRect.height
}
});Screenshot
Berechnen Sie die Koordinaten des Werts, machen Sie einen Screenshot und schneiden Sie das Bild mit jimp zu.
await page.screenshot({ path: imgPath });
// 对图片进行裁剪,只保留数字部分
const img = await jimp.read(imgPath);
await img.crop(tooltipInfo.x, tooltipInfo.y, tooltipInfo.width, tooltipInfo.height);
// 将图片放大一些,识别准确率会有提升
await img.scale(5);
await img.write(imgPath);Bilderkennung
Hier verwenden wir Tesseract für die Bilderkennung. Tesseracts ist ein Open-Source-OCR-Tool von Google, das zur Texterkennung in Bildern verwendet wird und die Genauigkeit verbessern kann durch Training. Auf Github gibt es bereits ein einfaches Knotenpaket: node-tesseract. Sie müssen zuerst Tesseract installieren und es auf Umgebungsvariablen festlegen.
Tesseract.process(imgPath, (err, val) => {
if (err || val == null) {
console.error(':x: 识别失败:' + imgPath);
return;
}
console.log(val);实际上未经训练的Tesseracts识别起来会有少数几个错误,比如把9开头的数字识别成`3,这里需要通过训练去提升Tesseracts的准确率,如果识别过程出现的问题都是一样的,也可以简单通过正则去修复这些问题。
封装
实现了以上几点后,只需组合起来就可以封装成一个百度指数爬虫node库。当然还有许多优化的方法,比如批量爬取,指定天数爬取等,只要在这个基础上实现都不难了。
const recognition = require('./src/recognition');
const Spider = require('./src/spider');
module.exports = {
async run (word, options, puppeteerOptions = { headless: true }) {
const spider = new Spider({
imgDir,
...options
}, puppeteerOptions);
// 抓取数据
await spider.run(word);
// 读取抓取到的截图,做图像识别
const wordDir = path.resolve(imgDir, word);
const imgNames = fs.readdirSync(wordDir);
const result = [];
imgNames = imgNames.filter(item => path.extname(item) === '.png');
for (let i = 0; i < imgNames.length; i++) {
const imgPath = path.resolve(wordDir, imgNames[i]);
const val = await recognition.run(imgPath);
result.push(val);
}
return result;
}
}反爬虫
最后,如何抵挡这种爬虫呢,个人认为通过判断鼠标移动轨迹可能是一种方法。当然前端没有100%的反爬虫手段,我们能做的只是给爬虫增加一点难度。
上面是我整理给大家的,希望今后会对大家有帮助。
相关文章:
在Node.js中使用cheerio制作简单的网页爬虫(详细教程)
在React中使用Native如何实现自定义下拉刷新上拉加载的列表
Das obige ist der detaillierte Inhalt vonSo implementieren Sie den Baidu-Index-Crawler mithilfe der Bilderkennungstechnologie Puppeteer. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So verwenden Sie Express für den Datei-Upload im Knotenprojekt
Mar 28, 2023 pm 07:28 PM
So verwenden Sie Express für den Datei-Upload im Knotenprojekt
Mar 28, 2023 pm 07:28 PM
Wie gehe ich mit dem Datei-Upload um? Der folgende Artikel stellt Ihnen vor, wie Sie Express zum Hochladen von Dateien im Knotenprojekt verwenden. Ich hoffe, er ist hilfreich für Sie!
 Java-Entwicklung: So implementieren Sie die Bilderkennung und -verarbeitung
Sep 21, 2023 am 08:39 AM
Java-Entwicklung: So implementieren Sie die Bilderkennung und -verarbeitung
Sep 21, 2023 am 08:39 AM
Java-Entwicklung: Ein praktischer Leitfaden zur Bilderkennung und -verarbeitung Zusammenfassung: Mit der rasanten Entwicklung von Computer Vision und künstlicher Intelligenz spielen Bilderkennung und -verarbeitung in verschiedenen Bereichen eine wichtige Rolle. In diesem Artikel wird erläutert, wie die Java-Sprache zum Implementieren der Bilderkennung und -verarbeitung verwendet wird, und es werden spezifische Codebeispiele bereitgestellt. 1. Grundprinzipien der Bilderkennung Unter Bilderkennung versteht man den Einsatz von Computertechnologie zur Analyse und zum Verständnis von Bildern, um Objekte, Merkmale oder Inhalte im Bild zu identifizieren. Bevor wir die Bilderkennung durchführen, müssen wir einige grundlegende Bildverarbeitungstechniken verstehen, wie in der Abbildung dargestellt
 Eine ausführliche Analyse des Prozessmanagement-Tools „pm2' von Node
Apr 03, 2023 pm 06:02 PM
Eine ausführliche Analyse des Prozessmanagement-Tools „pm2' von Node
Apr 03, 2023 pm 06:02 PM
In diesem Artikel stellen wir Ihnen das Prozessmanagement-Tool „pm2“ von Node vor und sprechen darüber, warum PM2 benötigt wird und wie Sie PM2 installieren und verwenden. Ich hoffe, dass es für alle hilfreich ist!
 PI -Knotenunterricht: Was ist ein PI -Knoten? Wie installiere und richte ich einen PI -Knoten ein?
Mar 05, 2025 pm 05:57 PM
PI -Knotenunterricht: Was ist ein PI -Knoten? Wie installiere und richte ich einen PI -Knoten ein?
Mar 05, 2025 pm 05:57 PM
Detaillierte Erläuterungs- und Installationshandbuch für Pinetwork -Knoten In diesem Artikel wird das Pinetwork -Ökosystem im Detail vorgestellt - PI -Knoten, eine Schlüsselrolle im Pinetwork -Ökosystem und vollständige Schritte für die Installation und Konfiguration. Nach dem Start des Pinetwork -Blockchain -Testnetzes sind PI -Knoten zu einem wichtigen Bestandteil vieler Pioniere geworden, die aktiv an den Tests teilnehmen und sich auf die bevorstehende Hauptnetzwerkveröffentlichung vorbereiten. Wenn Sie Pinetwork noch nicht kennen, wenden Sie sich bitte an was Picoin ist? Was ist der Preis für die Auflistung? PI -Nutzung, Bergbau und Sicherheitsanalyse. Was ist Pinetwork? Das Pinetwork -Projekt begann 2019 und besitzt seine exklusive Kryptowährung PI -Münze. Das Projekt zielt darauf ab, eine zu erstellen, an der jeder teilnehmen kann
 Bringen Sie Ihnen bei, wie Sie mithilfe der Python-Programmierung das Andocken der Baidu-Bilderkennungsschnittstelle und die Bilderkennungsfunktion realisieren.
Aug 25, 2023 pm 03:10 PM
Bringen Sie Ihnen bei, wie Sie mithilfe der Python-Programmierung das Andocken der Baidu-Bilderkennungsschnittstelle und die Bilderkennungsfunktion realisieren.
Aug 25, 2023 pm 03:10 PM
Bringen Sie Ihnen bei, die Python-Programmierung zu verwenden, um das Andocken der Bilderkennungsschnittstelle von Baidu zu implementieren und die Bilderkennungsfunktion zu realisieren. Im Bereich Computer Vision ist die Bilderkennungstechnologie eine sehr wichtige Technologie. Baidu bietet eine leistungsstarke Bilderkennungsschnittstelle, über die wir Bildklassifizierung, Beschriftung, Gesichtserkennung und andere Funktionen problemlos implementieren können. In diesem Artikel erfahren Sie, wie Sie mithilfe der Programmiersprache Python die Bilderkennungsfunktion realisieren, indem Sie eine Verbindung zur Baidu-Bilderkennungsschnittstelle herstellen. Zuerst müssen wir eine Anwendung auf der Baidu Developer Platform erstellen und herunterladen
 So verwenden Sie reguläre Python-Ausdrücke zur Bilderkennung
Jun 23, 2023 am 10:36 AM
So verwenden Sie reguläre Python-Ausdrücke zur Bilderkennung
Jun 23, 2023 am 10:36 AM
In der Informatik war die Bilderkennung schon immer ein wichtiges Gebiet. Mithilfe der Bilderkennung können wir den Computer den Bildinhalt erkennen, analysieren und verarbeiten lassen. Python ist eine sehr beliebte Programmiersprache, die in vielen Bereichen eingesetzt werden kann, einschließlich der Bilderkennung. In diesem Artikel wird erläutert, wie Sie reguläre Python-Ausdrücke zur Bilderkennung verwenden. Reguläre Ausdrücke sind ein Tool zum Vergleichen von Textmustern, mit dem Text gefunden wird, der einem bestimmten Muster entspricht. Python verfügt über ein integriertes „re“-Modul für reguläre Ausdrücke
 So führen Sie Bildverarbeitung und -erkennung in Python durch
Oct 20, 2023 pm 12:10 PM
So führen Sie Bildverarbeitung und -erkennung in Python durch
Oct 20, 2023 pm 12:10 PM
So führen Sie Bildverarbeitung und -erkennung in Python durch Zusammenfassung: Moderne Technologie hat Bildverarbeitung und -erkennung in vielen Bereichen zu einem wichtigen Werkzeug gemacht. Python ist eine einfach zu erlernende und zu verwendende Programmiersprache mit umfangreichen Bildverarbeitungs- und Erkennungsbibliotheken. In diesem Artikel wird die Verwendung von Python für die Bildverarbeitung und -erkennung vorgestellt und spezifische Codebeispiele bereitgestellt. Bildverarbeitung: Bei der Bildverarbeitung werden verschiedene Vorgänge und Transformationen an Bildern durchgeführt, um die Bildqualität zu verbessern, Informationen aus Bildern zu extrahieren usw. PIL-Bibliothek in Python (Pi
 Implementierung eines hochgradig gleichzeitigen Bilderkennungssystems mit Go und Goroutinen
Jul 22, 2023 am 10:58 AM
Implementierung eines hochgradig gleichzeitigen Bilderkennungssystems mit Go und Goroutinen
Jul 22, 2023 am 10:58 AM
Verwendung von Go und Goroutinen zur Implementierung eines hochgradig gleichzeitigen Bilderkennungssystems Einführung: In der heutigen digitalen Welt ist die Bilderkennung zu einer wichtigen Technologie geworden. Durch Bilderkennung können wir Informationen wie Objekte, Gesichter, Szenen usw. in Bildern in digitale Daten umwandeln. Bei der Erkennung umfangreicher Bilddaten wird die Geschwindigkeit jedoch häufig zu einer Herausforderung. Um dieses Problem zu lösen, wird in diesem Artikel erläutert, wie die Go-Sprache und Goroutinen verwendet werden, um ein Bilderkennungssystem mit hoher Parallelität zu implementieren. Hintergrund: Go-Sprache
