

Crawlen von NetEase Cloud-Musikrezensionen
# coding=gbk
import requests
import json
c='网易云爬虫实战一'
print(c)
music_url = 'https://music.163.com/#/song?id=28815250'
id = music_url.split('=')[1]
# print(id)
url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_%s?csrf_token=7e19029fe28aa3e09cfe87e89d2e4eeb' %(id)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Referer': 'https://music.163.com/song?id=%s' %(id),
'Origin': 'https://music.163.com',
}
formdata = {
'params': 'AoF/ZXuccqvtaCMCPHecFGVPfrbtDj4JFPJsaZ3tYn9J+r0NcnKPhZdVECDz/jM+1CpA+ByvAO2J9d44B/MG97WhjmxWkfo4Tm++AfyBgK11NnSbKsuQ5bxJR6yE0MyFhU8sPq7wb9DiUPFKs2ulw0GxwU/il1NS/eLrq+bbYikK/cyne90S/yGs6ldxpbcNd1yQTuOL176aBZXTJEcGkfbxY+mLKCwScAcCK1s3STo=',
'encSecKey': '365b4c31a9c7e2ddc002e9c42942281d7e450e5048b57992146633181efe83c1e26acbc8d84b988d746370d788b6ae087547bace402565cca3ad59ccccf7566b07d364aa1d5b2bbe8ccf2bc33e0f03182206e29c66ae4ad6c18cb032d23f1793420ceda05e796401f170dbdb825c20356d27f07870598b2798f8d344807ad6f2',
}
response = requests.post(url, headers = headers, data = formdata)
messages = json.loads(response.text)
data_list=[]
data={}
for message in messages['hotComments']:
data['nickname']=message['user']['nickname']
data['content']=message['content']
data_list.append(data)
data={}
#print(data_list)
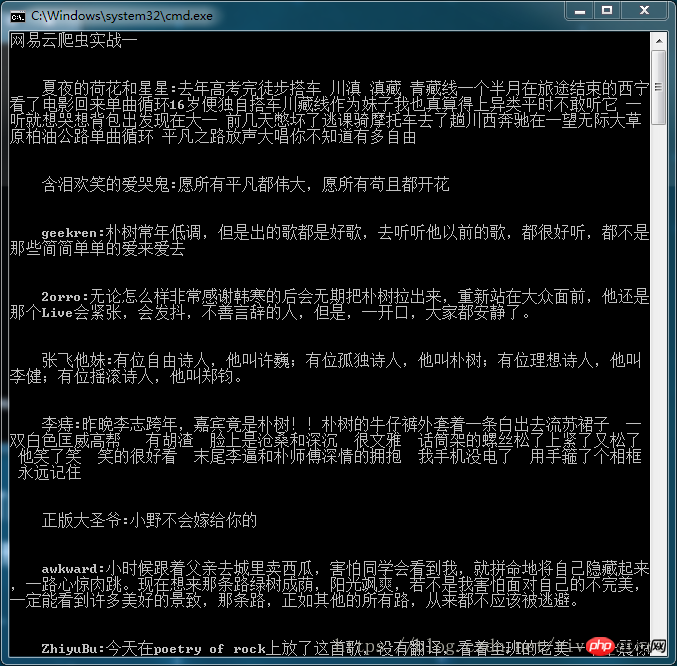
for i in data_list:
c = ' '+i['nickname']+':'+i['content']
print('\n\n'+c.replace('\n',''))
Zusammenfassung:
1. Das „#“ im ersten line programming=gbk“ bedeutet, dass Textzeichenfolgen im Texteditor eingegeben werden können.
2. Die Funktion split() in „id = music_url.split('=')[1]“ bedeutet, Elemente zu gruppieren, in diesem Beispiel ist es „https://music.163“. .com /#/song?id=“, „28815250“
3. Der vom Anforderungsmodul erhaltene HTML-Text muss in Python konvertiert werden, das mit dem JSON lesbar ist. Loads()-Methodentext, andernfalls wird ein Fehler gemeldet. Dies ist im Jupiter-Notebook nicht der Fall.
4. Die Funktion replace() kann Elemente aus der Zeichenfolge entfernen. In diesem Beispiel wird das Newline-Zeichen leer.
Das endgültige Anzeigeergebnis ist wie folgt:
Dieser Artikel stellt den relevanten Inhalt der NetEase Cloud-Musikrezension vor Crawling, bitte folgen Sie der chinesischen PHP-Website.
Verwandte Empfehlungen:
Einfache PHP+MySQL-Paging-Klasse
Zwei Baumarray-Konstruktoren ohne Rekursion
HTML in Excel konvertieren und Druck- und Downloadfunktionen realisieren
Das obige ist der detaillierte Inhalt vonCrawlen von NetEase Cloud-Musikrezensionen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1205
24
52
1205
24

 Metadaten-Scraping mit der New York Times API
Sep 02, 2023 pm 10:13 PM
Metadaten-Scraping mit der New York Times API
Sep 02, 2023 pm 10:13 PM
Einleitung Letzte Woche habe ich eine Einleitung über das Scrapen von Webseiten zum Sammeln von Metadaten geschrieben und erwähnt, dass es unmöglich sei, die Website der New York Times zu scrapen. Die Paywall der New York Times blockiert Ihre Versuche, grundlegende Metadaten zu sammeln. Aber es gibt eine Möglichkeit, dieses Problem mithilfe der New York Times API zu lösen. Vor kurzem habe ich mit dem Aufbau einer Community-Website auf der Yii-Plattform begonnen, die ich in einem zukünftigen Tutorial veröffentlichen werde. Ich möchte in der Lage sein, problemlos Links hinzuzufügen, die für den Inhalt der Website relevant sind. Während Benutzer URLs problemlos in Formulare einfügen können, ist die Bereitstellung von Titel- und Quelleninformationen zeitaufwändig. Deshalb werde ich im heutigen Tutorial den Scraping-Code, den ich kürzlich geschrieben habe, erweitern, um die New York Times-API zum Sammeln von Schlagzeilen zu nutzen, wenn ich einen Link zur New York Times hinzufüge. Denken Sie daran, ich bin involviert
 Wie kann ich Daten durch Aufrufen der API-Schnittstelle in einem PHP-Projekt crawlen und verarbeiten?
Sep 05, 2023 am 08:41 AM
Wie kann ich Daten durch Aufrufen der API-Schnittstelle in einem PHP-Projekt crawlen und verarbeiten?
Sep 05, 2023 am 08:41 AM
Wie kann ich Daten durch Aufrufen der API-Schnittstelle in einem PHP-Projekt crawlen und verarbeiten? 1. Einführung In PHP-Projekten müssen wir häufig Daten von anderen Websites crawlen und diese Daten verarbeiten. Viele Websites bieten API-Schnittstellen, und wir können Daten durch Aufrufen dieser Schnittstellen abrufen. In diesem Artikel wird erläutert, wie Sie mit PHP die API-Schnittstelle zum Crawlen und Verarbeiten von Daten aufrufen. 2. Ermitteln Sie die URL und die Parameter der API-Schnittstelle. Bevor Sie beginnen, müssen Sie die URL der Ziel-API-Schnittstelle und die erforderlichen Parameter ermitteln.
 Zusammenfassung der Vue-Entwicklungserfahrungen: Tipps zur Optimierung von SEO und Suchmaschinen-Crawling
Nov 22, 2023 am 10:56 AM
Zusammenfassung der Vue-Entwicklungserfahrungen: Tipps zur Optimierung von SEO und Suchmaschinen-Crawling
Nov 22, 2023 am 10:56 AM
Zusammenfassung der Vue-Entwicklungserfahrungen: Tipps zur Optimierung von SEO und Suchmaschinen-Crawling Mit der rasanten Entwicklung des Internets ist Website-SEO (SearchEngineOptimization, Suchmaschinenoptimierung) immer wichtiger geworden. Für mit Vue entwickelte Websites ist die Optimierung für SEO und Suchmaschinen-Crawling von entscheidender Bedeutung. In diesem Artikel werden einige Erfahrungen in der Vue-Entwicklung zusammengefasst und einige Tipps zur Optimierung von SEO und Suchmaschinen-Crawling gegeben. Verwendung der Prerendering-Technologie Vue
 Wie kann man mit Scrapy Douban-Bücher und deren Bewertungen und Kommentare crawlen?
Jun 22, 2023 am 10:21 AM
Wie kann man mit Scrapy Douban-Bücher und deren Bewertungen und Kommentare crawlen?
Jun 22, 2023 am 10:21 AM
Mit der Entwicklung des Internets verlassen sich die Menschen zunehmend auf das Internet, um Informationen zu erhalten. Für Buchliebhaber ist Douban Books zu einer unverzichtbaren Plattform geworden. Darüber hinaus bietet Douban Books eine Fülle von Buchbewertungen und Rezensionen, die es den Lesern ermöglichen, ein Buch umfassender zu verstehen. Das manuelle Abrufen dieser Informationen ist jedoch gleichbedeutend mit der Suche nach der Nadel im Heuhaufen. Zu diesem Zeitpunkt können wir das Scrapy-Tool zum Crawlen von Daten verwenden. Scrapy ist ein auf Python basierendes Open-Source-Webcrawler-Framework, das uns effizient helfen kann
 Scrapy in Aktion: Baidu-Nachrichtendaten crawlen
Jun 23, 2023 am 08:50 AM
Scrapy in Aktion: Baidu-Nachrichtendaten crawlen
Jun 23, 2023 am 08:50 AM
Scrapy in Aktion: Crawlen von Baidu-Nachrichtendaten Mit der Entwicklung des Internets hat sich die Hauptmethode für die Informationsbeschaffung von traditionellen Medien auf das Internet verlagert, und die Menschen verlassen sich zunehmend auf das Internet, um Nachrichteninformationen zu erhalten. Für Forscher oder Analysten werden große Datenmengen für Analysen und Recherchen benötigt. Daher wird in diesem Artikel erläutert, wie Sie mit Scrapy Baidu-Nachrichtendaten crawlen. Scrapy ist ein Open-Source-Python-Crawler-Framework, das Website-Daten schnell und effizient crawlen kann. Scrapy bietet leistungsstarke Funktionen zum Parsen und Crawlen von Webseiten
 Wie verwende ich die PHP-Goutte-Klassenbibliothek für Web-Crawling und Datenextraktion?
Aug 09, 2023 pm 02:16 PM
Wie verwende ich die PHP-Goutte-Klassenbibliothek für Web-Crawling und Datenextraktion?
Aug 09, 2023 pm 02:16 PM
Wie verwende ich die PHPGoutte-Klassenbibliothek für Web-Crawling und Datenextraktion? Überblick: Im täglichen Entwicklungsprozess müssen wir häufig verschiedene Daten aus dem Internet abrufen, z. B. Filmrankings, Wettervorhersagen usw. Web-Crawling ist eine der gebräuchlichsten Methoden, um diese Daten zu erhalten. In der PHP-Entwicklung können wir die Goutte-Klassenbibliothek verwenden, um Web-Crawling- und Datenextraktionsfunktionen zu implementieren. In diesem Artikel wird erläutert, wie Sie mit der PHPGoutte-Klassenbibliothek Webseiten crawlen, Daten extrahieren und Codebeispiele anhängen. Was ist Gicht?
 Scrapy in Aktion: Daten zu Douban-Filmen durchsuchen und Beliebtheitsrankings bewerten
Jun 22, 2023 pm 01:49 PM
Scrapy in Aktion: Daten zu Douban-Filmen durchsuchen und Beliebtheitsrankings bewerten
Jun 22, 2023 pm 01:49 PM
Scrapy ist ein Open-Source-Python-Framework zum schnellen und effizienten Scrapen von Daten. In diesem Artikel verwenden wir Scrapy, um die Daten zu crawlen und die Beliebtheit von Douban-Filmen zu bewerten. Vorbereitung Zuerst müssen wir Scrapy installieren. Sie können Scrapy installieren, indem Sie den folgenden Befehl in die Befehlszeile eingeben: pipinstallscrapy Als nächstes erstellen wir ein Scrapy-Projekt. Geben Sie in der Befehlszeile den folgenden Befehl ein: scrapystartproject
 Wie kann ich mit Scrapy Kugou Music-Songs crawlen?
Jun 22, 2023 pm 10:59 PM
Wie kann ich mit Scrapy Kugou Music-Songs crawlen?
Jun 22, 2023 pm 10:59 PM
Mit der Entwicklung des Internets nimmt die Informationsmenge im Internet zu und die Menschen müssen Informationen von verschiedenen Websites crawlen, um verschiedene Analysen und Mining durchzuführen. Scrapy ist ein voll funktionsfähiges Python-Crawler-Framework, das Website-Daten automatisch crawlen und in strukturierter Form ausgeben kann. Kugou Music ist eine der beliebtesten Online-Musikplattformen. Im Folgenden werde ich vorstellen, wie man Scrapy zum Crawlen der Songinformationen von Kugou Music verwendet. 1. Installieren Sie ScrapyScrapy ist ein Framework, das auf der Python-Sprache basiert
