

Das zugrunde liegende Implementierungsprinzip des MySQL-Index

Die Datenstruktur und die Algorithmusprinzipien hinter MySQL-Indizes
1. Indexdefinition: Index (Index) soll MySQL helfen effizient sein Holen Sie sich die Datenstruktur der Daten. Essenz: Der Index ist eine Datenstruktur.
2. B-Baum
M-Ordnung B-Baum erfüllt die folgenden Bedingungen: 1. Jeder Knoten kann höchstens m Teilbäume haben.
2. Der Wurzelknoten hat nur mindestens 2 Knoten (oder im Extremfall hat ein Baum nur einen Wurzelknoten, ein einzelliger Organismus ist eine Wurzel, ein Blatt und ein Baum).3. Nicht-Wurzel- und Nicht-Blattknoten haben mindestens Ceil (m/2) Teilbäume (Ceil bedeutet Aufrunden, wie zum Beispiel ein B-Baum 5. Ordnung, jeder Knoten hat mindestens 3 Teilbäume, d. h. es gibt mindestens 3 Gabeln).
4. Die Informationen in Nicht-Blattknoten umfassen [n,A0,K1,A1,K2,A2,…,Kn,An], wobei n die Anzahl der im Knoten gespeicherten Schlüsselwörter darstellt und K das Schlüsselwort ist Und Ki
B-Tree-Funktionen:
1. Der Schlüsselwortsatz ist im gesamten Baum verteilt; ein Nicht-Blattknoten; 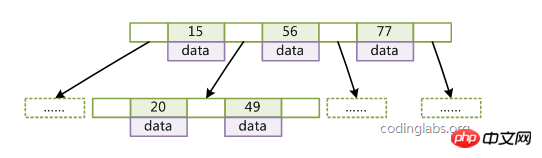 5. Die Schlüssel in einem Knoten sind von links nach rechts nicht abnehmend angeordnet;
5. Die Schlüssel in einem Knoten sind von links nach rechts nicht abnehmend angeordnet;
Der Pseudocode des Suchalgorithmus auf B-Tree lautet wie folgt:
 Der Unterschied zwischen B+Tree und B-Tree ist:
Der Unterschied zwischen B+Tree und B-Tree ist:
Alle Schlüsselwörter werden gespeichert auf Blattknoten; 3. Jeder Blattknoten enthält einen Zeiger auf den benachbarten Blattknoten. und enthält nur das größte (oder kleinste) Schlüsselwort in seinem Unterbaum (Wurzelknoten);
 4. Leistungsanalyse des B/B+-Baumindex
4. Leistungsanalyse des B/B+-Baumindex
Basis : Verwenden Sie die Anzahl der Festplatten-E/As, um die Qualität der Indexstruktur zu bewerten
Hauptspeicher und Festplattenaustauschdaten in Seiteneinheiten. Stellen Sie die Größe eines Knotens auf eine Seite ein, sodass jeder Knoten nur eine E/A benötigt . Voll beladen.
Gemäß der Definition des B-Baums ist ersichtlich, dass für einen Abruf auf maximal h Knoten zugegriffen werden muss
Asymptotische Komplexität: O(h)=O(logdN)
dmax=floor (pagesize/(keysize+datasize+pointsize) )
Einmal im B-Tree-Abruf erfordert höchstens h-1 I/O (Wurzelknoten-residenter Speicher) Die Knoten im B+Tree enthalten keine Datenfelder, daher der Out-Grad Je größer d, desto kleiner ist h, desto geringer ist die Anzahl der E/A und desto höher ist die Effizienz. Daher eignet sich B+Tree besser für externe Speicherindizes.
5. MySQL-Indeximplementierung
1. Das Datenfeld des Blattknotens speichert die Adresse > MyISAM main Es gibt keinen strukturellen Unterschied zwischen dem Index und dem Hilfsindex, außer dass der Schlüssel des Primärindex eindeutig sein muss, während der Schlüssel des Hilfsindex wiederholt werden kann.
2 InnoDB selbst ist die Indexdatei, und der Blattknoten enthält die vollständigen Datensätze. Dieser Index wird als Clustered-Index bezeichnet.
Da die Datendateien von InnoDB selbst nach Primärschlüssel aggregiert werden, erfordert InnoDB, dass die Tabelle einen Primärschlüssel haben muss (MyISAM benötigt diesen nicht, wenn er nicht explizit angegeben wird, wählt das MySQL-System automatisch eine Spalte aus, die den eindeutig identifizieren kann). Wenn eine solche Spalte nicht vorhanden ist, generiert MySQL automatisch ein implizites Feld als Primärschlüssel für die InnoDB-Tabelle.
Das Hilfsindexdatenfeld von InnoDB speichert den Wert des Primärschlüssels des entsprechenden Datensatzes anstelle der Adresse.
Die Hilfsindexsuche muss den Index zweimal abrufen: Rufen Sie zuerst den Hilfsindex ab, um den Primärschlüssel zu erhalten Verwenden Sie dann den Primärschlüssel, um den Datensatz im Primärindex abzurufen Der Datensatz wird nacheinander in die Seite eingefügt. Fahren Sie mit dem Einfügen in eine neue Seite fort.
Wenn die Schreibvorgänge nicht in der richtigen Reihenfolge sind, muss InnoDB häufig Seitenaufteilungen durchführen, um Platz für neue Zeilen zu reservieren. Durch die Seitenaufteilung werden große Datenmengen verschoben; bei einer Einfügung müssen mindestens drei Seiten statt einer geändert werden. Wenn Seiten häufig geteilt werden, werden die Seiten spärlich und unregelmäßig gefüllt, sodass die Daten schließlich fragmentiert werden.
Das Verständnis der Indeximplementierungsmethoden verschiedener Speicher-Engines ist für die korrekte Verwendung und Optimierung von Indizes sehr hilfreich
2. Warum ein Auto-Inkrement-Feld als Primärschlüssel wählen?
3. Warum wird nicht empfohlen, einen Index für Felder zu erstellen, die häufig aktualisiert werden?
4. Warum eine stark differenzierte Spalte als Index wählen? Die Unterscheidungsformel lautet count(distinct col)/count(*)
Verwenden Sie den abdeckenden Index so weit wie möglich
7. Optimieren Sie die LIMIT-Paging-Abfrage.
SELECT * FROM table where condition LIMIT offset , rows ;
Der Implementierungsmechanismus der obigen SQL-Anweisung ist:
1. Offset+Zeilenzeilendatensätze aus der Tabelle „Tabelle“ lesen.
2. Verwerfen Sie die vorherigen versetzten Zeilendatensätze und geben Sie die Zeilendatensätze der nachfolgenden Zeilen als Endergebnis zurück.
Abgedeckter Index:
select a.id, sid, parent_s_id from cashpool_account_relationship a join (select id from cashpool_account_relationship LIMIT 1000000,10)b on a.id = b.id; select id, sid, parent_s_id from cashpool_account_relationship where id >=(select id from cashpool_account_relationship LIMIT 1000000,1) LIMIT 10;
8. Unterstützt InnoDB einen Hash-Index? --Ma in einer Tabelle. 2. Die Blattknoten des InnoDB-Primärschlüsselindex enthalten vollständige Datensätze. Ist die Primärschlüsselindexdatei größer als die Datendatei? --Xu Caihou
1). In der Innodb-Engine enthalten die Blattknoten im Primärschlüsselindex Datensatzdaten, und die Primärschlüsselindexdatei ist die Datendatei.2). Die in der Tabellentabelle gezählten data_length-Daten sind die Primärschlüsselindexgröße und index_length ist die gezählte Größe aller Hilfsindizes (Sekundärindizes) in dieser Tabelle.
Das obige ist der detaillierte Inhalt vonDas zugrunde liegende Implementierungsprinzip des MySQL-Index. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Mehrere Situationen, in denen ein MySQL-Index fehlschlägt
Feb 21, 2024 pm 04:23 PM
Mehrere Situationen, in denen ein MySQL-Index fehlschlägt
Feb 21, 2024 pm 04:23 PM
Häufige Situationen: 1. Verwenden Sie Funktionen oder Operationen; 3. Verwenden Sie ungleich (!= oder <>); Wert; 7. Niedrige Indexselektivität; 8. Prinzip des zusammengesetzten Indexes; 9. Optimierer-Entscheidung;
 Unter welchen Umständen schlägt der MySQL-Index fehl?
Aug 09, 2023 pm 03:38 PM
Unter welchen Umständen schlägt der MySQL-Index fehl?
Aug 09, 2023 pm 03:38 PM
MySQL-Indizes schlagen fehl, wenn Abfragen ohne Verwendung von Indexspalten, nicht übereinstimmenden Datentypen, falscher Verwendung von Präfixindizes, Verwendung von Funktionen oder Ausdrücken für Abfragen, falscher Reihenfolge von Indexspalten, häufigen Datenaktualisierungen und zu vielen oder zu wenigen Indizes erfolgen. 1. Verwenden Sie keine Indexspalten für Abfragen. 2. Bei der Gestaltung der Tabellenstruktur sollten Sie darauf achten, dass die Indexspalten übereinstimmen 3. Bei unsachgemäßer Verwendung des Präfixindex können Sie den Präfixindex verwenden.
 Wann könnte ein vollständiger Tabellen -Scan schneller sein als einen Index in MySQL?
Apr 09, 2025 am 12:05 AM
Wann könnte ein vollständiger Tabellen -Scan schneller sein als einen Index in MySQL?
Apr 09, 2025 am 12:05 AM
Die volle Tabellenscannung kann in MySQL schneller sein als die Verwendung von Indizes. Zu den spezifischen Fällen gehören: 1) das Datenvolumen ist gering; 2) Wenn die Abfrage eine große Datenmenge zurückgibt; 3) wenn die Indexspalte nicht sehr selektiv ist; 4) Wenn die komplexe Abfrage. Durch Analyse von Abfrageplänen, Optimierung von Indizes, Vermeidung von Überindex und regelmäßiger Wartung von Tabellen können Sie in praktischen Anwendungen die besten Auswahlmöglichkeiten treffen.
 Was sind die Klassifizierungen von MySQL-Indizes?
Apr 22, 2024 pm 07:12 PM
Was sind die Klassifizierungen von MySQL-Indizes?
Apr 22, 2024 pm 07:12 PM
MySQL-Indizes werden in die folgenden Typen unterteilt: 1. Gewöhnlicher Index: Übereinstimmung mit Wert, Bereich oder Präfix; 2. Eindeutiger Index: Stellt sicher, dass der Wert eindeutig ist. 3. Primärschlüsselindex: Eindeutiger Index der Primärschlüsselspalte Schlüsselindex: zeigt auf den Primärschlüssel einer anderen Tabelle; 5. Volltextindex: Suche nach gleicher Übereinstimmung; 8. Zusammengesetzter Index: Suche basierend auf mehreren Säulen.
 MySQL-Index-Linkspräfix-Matching-Regeln
Feb 24, 2024 am 10:42 AM
MySQL-Index-Linkspräfix-Matching-Regeln
Feb 24, 2024 am 10:42 AM
Prinzip des MySQL-Index ganz links: Prinzip und Codebeispiele In MySQL ist die Indizierung eines der wichtigsten Mittel zur Verbesserung der Abfrageeffizienz. Unter diesen ist das Indexprinzip ganz links ein wichtiges Prinzip, das wir befolgen müssen, wenn wir Indizes zur Optimierung von Abfragen verwenden. In diesem Artikel wird das Prinzip des MySQL-Index ganz links vorgestellt und einige spezifische Codebeispiele gegeben. 1. Das Prinzip des Index-Prinzips ganz links Das Prinzip des Index ganz links bedeutet, dass in einem Index, wenn die Abfragebedingung aus mehreren Spalten besteht, nur die Spalte ganz links im Index abgefragt werden kann, um die Abfragebedingungen vollständig zu erfüllen.
 Erklären Sie verschiedene Arten von MySQL-Indizes (B-Tree, Hash, Volltext, räumlich).
Apr 02, 2025 pm 07:05 PM
Erklären Sie verschiedene Arten von MySQL-Indizes (B-Tree, Hash, Volltext, räumlich).
Apr 02, 2025 pm 07:05 PM
MySQL unterstützt vier Indextypen: B-Tree, Hash, Volltext und räumlich. 1.B-Tree-Index ist für die gleichwertige Suche, eine Bereichsabfrage und die Sortierung geeignet. 2. Hash -Index ist für gleichwertige Suche geeignet, unterstützt jedoch keine Abfrage und Sortierung von Bereichs. 3. Die Volltextindex wird für die Volltext-Suche verwendet und ist für die Verarbeitung großer Mengen an Textdaten geeignet. 4. Der räumliche Index wird für die Abfrage für Geospatial -Daten verwendet und ist für GIS -Anwendungen geeignet.
 Wie kann man MySQL-Indizes rational nutzen und die Datenbankleistung optimieren? Designprotokolle, die Technikstudenten kennen müssen!
Sep 10, 2023 pm 03:16 PM
Wie kann man MySQL-Indizes rational nutzen und die Datenbankleistung optimieren? Designprotokolle, die Technikstudenten kennen müssen!
Sep 10, 2023 pm 03:16 PM
Wie kann man MySQL-Indizes rational nutzen und die Datenbankleistung optimieren? Designprotokolle, die Technikstudenten kennen müssen! Einleitung: Im heutigen Internetzeitalter wächst die Datenmenge weiter und die Optimierung der Datenbankleistung ist zu einem sehr wichtigen Thema geworden. Als eine der beliebtesten relationalen Datenbanken ist die rationelle Nutzung von Indizes durch MySQL von entscheidender Bedeutung für die Verbesserung der Datenbankleistung. In diesem Artikel erfahren Sie, wie Sie MySQL-Indizes rational nutzen, die Datenbankleistung optimieren und einige Designregeln für Technikstudenten bereitstellen. 1. Warum Indizes verwenden? Ein Index ist eine Datenstruktur, die verwendet
 Strategien zur Leistungsoptimierung für die Datenaktualisierung und Indexpflege von PHP- und MySQL-Indizes und deren Auswirkungen auf die Leistung
Oct 15, 2023 pm 12:15 PM
Strategien zur Leistungsoptimierung für die Datenaktualisierung und Indexpflege von PHP- und MySQL-Indizes und deren Auswirkungen auf die Leistung
Oct 15, 2023 pm 12:15 PM
Strategien zur Leistungsoptimierung für die Datenaktualisierung und Indexpflege von PHP- und MySQL-Indizes und deren Auswirkungen auf die Leistung. Zusammenfassung: In der Entwicklung von PHP und MySQL sind Indizes ein wichtiges Werkzeug zur Optimierung der Datenbankabfrageleistung. In diesem Artikel werden die Grundprinzipien und die Verwendung von Indizes vorgestellt und die Auswirkungen von Indizes auf die Leistung bei der Datenaktualisierung und -wartung untersucht. Gleichzeitig bietet dieser Artikel auch einige Strategien zur Leistungsoptimierung und spezifische Codebeispiele, um Entwicklern zu helfen, Indizes besser zu verstehen und anzuwenden. Grundprinzipien und Verwendung von Indizes In MySQL ist ein Index eine spezielle Zahl
