

Tatsächlich können Sie den Index als ein spezielles Verzeichnis verstehen. Der folgende Artikel führt Sie hauptsächlich in die Prinzipien der SQL Server-Indizierung ein Ihr Studium bzw. Die Arbeit hat einen gewissen Referenz- und Lernwert. Freunde, die es brauchen, folgen bitte dem Herausgeber, um gemeinsam zu lernen
Vorwort
In diesem Artikel habe ich meine vorherigen Notizen zusammengestellt und den Index als Einstiegspunkt für die Diskussion relevanter Datenbankkenntnisse verwendet (und ihn geändert, um ihn für die Menschen leichter verständlich zu machen). Freunde, die neu bei SQL Server sind, können einfach die folgende blaue Schriftart lesen, die einfach und nützlich ist, um Zeit zu sparen. Wenn Sie ein Freund mit einer guten Datenbankbasis sind, können Sie alles lesen und gerne diskutieren .
Das Konzept des Index
Der Zweck des Index: Unsere Datenabfrage- und Verarbeitungsgeschwindigkeit ist zum Standard für die Messung des Erfolgs oder Misserfolgs von Anwendungssystemen geworden. und Indizes werden verwendet, um die Datenverarbeitungsgeschwindigkeit zu beschleunigen. Dies ist häufig die am häufigsten verwendete Optimierungsmethode.
Was ist ein Index: Der Index in der Datenbank ähnelt dem Inhaltsverzeichnis eines Buches. Mithilfe des Inhaltsverzeichnisses in einem Buch können Sie schnell die gewünschten Informationen finden, ohne das gesamte Buch lesen zu müssen. In einer Datenbank verwenden Datenbankprogramme Indizes, um Daten in einer Tabelle abzurufen, ohne die gesamte Tabelle scannen zu müssen. Das Inhaltsverzeichnis im Buch ist eine Liste von Wörtern und die Seitenzahlen, auf denen sich jedes Wort befindet, und der Index in der Datenbank ist eine Liste von Werten in der Tabelle und dem Speicherort jedes Werts.
Vor- und Nachteile von Indizes: Der größte Teil des Overheads der Abfrageausführung ist E/A. Eines der Hauptziele der Verwendung von Indizes zur Verbesserung der Leistung besteht darin, vollständige Tabellenscans zu vermeiden, da für vollständige Tabellenscans das Lesen aller Daten erforderlich ist Wenn es einen Index gibt, der auf den Datenwert zeigt, muss die Abfrage die Festplatte nur ein paar Mal lesen. Daher kann die sinnvolle Verwendung von Indizes die Datenabfrage beschleunigen. Allerdings verbessern Indizes nicht immer die Systemleistung. Indizierte Tabellen erfordern mehr Speicherplatz in der Datenbank. Die Ausführung derselben Befehle zum Hinzufügen und Löschen von Daten dauert länger und die zum Verwalten des Index erforderliche Verarbeitungszeit ist länger. Daher müssen wir Indizes rational verwenden und sie rechtzeitig aktualisieren, um suboptimale Indizes zu entfernen.
Der Index ist in Clustered-Index und Nicht-Clustered-Index unterteilt
Die Daten der Tabelle werden auf der Datenseite gespeichert (die PageType-Markierung der Datenseite ist 1). Eine Seite von SqlServer ist 8 KB groß . Wenn die Seite voll ist, wird eine Seite mit Speicherplatz geöffnet. Wenn die Tabelle einen Clustered-Index hat, werden die physischen Daten einzeln in aufsteigender/absteigender Reihenfolge entsprechend der Größe des Clustered-Index-Felds auf der Seite gespeichert. Wenn das Clustered-Index-Feld aktualisiert wird oder Daten in der Mitte eingefügt/gelöscht werden, werden die Tabellendaten verschoben (was einen gewissen Einfluss auf die Leistung hat), da die aufsteigende/absteigende Sortierung beibehalten werden muss.
Beachten Sie, dass der Primärschlüssel standardmäßig nur ein Clustered-Index ist. Er kann auch als Nicht-Clustered-Index oder als Clustered-Index für einen Nicht-Primärschlüssel festgelegt werden Schlüsselfelder. Die gesamte Tabelle kann nur einen Clustered-Index haben.
Ein ausgezeichnetes Clustered-Index-Feld enthält im Allgemeinen die folgenden 4 Merkmale:
(A) ist immer am Ende Erhöhen Sie die Anzahl der Datensätze und reduzieren Sie Paging und Indexfragmentierung.
(B) Nicht geändert
Datenbewegung reduzieren.
(C). Eindeutigkeit
Einzigartigkeit ist das idealste Merkmal eines jeden Index, das die Position des Indexschlüsselwerts in der Sortierung verdeutlichen kann.
Noch wichtiger: Wenn der Indexschlüssel eindeutig ist, kann er in jedem Datensatz korrekt auf die Quelldatenzeilen-RID verweisen. Wenn der Schlüsselwert des gruppierten Index nicht eindeutig ist, muss SqlServer intern eine eindeutige Spaltenkombination als gruppierten Schlüssel generieren, um die Eindeutigkeit des „Schlüsselwerts“ sicherzustellen. Wenn der Schlüsselwert des nicht gruppierten Index nicht eindeutig ist, wird eine RID-Spalte ( Clustered-Index-Schlüssel oder Heap-Tabelle) werden hinzugefügt, um die Eindeutigkeit des „Schlüsselwerts“ sicherzustellen.
Denken (kann übersprungen werden): Der Index-„Schlüsselwert“ ist auch in Nicht-Blattknoten garantiert eindeutig. Der Grund sollte darin bestehen, die Position des Indexdatensatzes im Nicht-Blattknoten zu klären. Blattknoten. Beispielsweise gibt es ein nicht gruppiertes Indexfeld Name2. Es gibt viele Datensätze mit Name2='a' in der Tabelle, was dazu führt, dass Name2='a' zu diesem Zeitpunkt mehrere Indexdatensätze (Knoten) hat Wenn Sie Name2='a'-Datensatz einfügen, können Sie anhand der RID des Nicht-Blattknotens und der RID des neuen Datensatzes schnell bestimmen, welcher Indexdatensatz (Knoten) eingefügt werden soll , Sie müssen alle durchlaufen Name2=' Nur die Blattknoten von a' können die Position bestimmen. Wenn wir außerdem * aus Tabelle1 auswählen, wobei Name2<='a' ist, werden die zurückgegebenen Daten nach dem nicht gruppierten Index Name2 und der RID sortiert. Es ist leicht zu verstehen, dass die zurückgegebenen Daten hier nach der Reihenfolge der Indexspeicherung sortiert sind . Dies ist das Ergebnis der Verwendung des Name2-Index in dieser SQL-Abfrage. Wenn der Datenbankabfrageplan aufgrund des Problems „kritischer Punkt“ das direkte Scannen von Tabellendaten auswählt, werden die zurückgegebenen Daten standardmäßig nach der Reihenfolge der Tabellendaten sortiert.
Für die Eindeutigkeit des „Schlüsselwerts“ wird bei gruppierten Indizes die Eindeutigkeitsspalte nur dann erhöht, wenn der Indexwert dupliziert wird. Wenn bei nicht gruppierten Indizes die Eindeutigkeit beim Erstellen des Index nicht definiert wurde, wird die RID in allen Datensätzen erhöht. Auch wenn der Indexwert eindeutig ist, wird die RID nur auf Blattebene erhöht , die zum Suchen von Quelldatenzeilen verwendet wird, d. h. als Suchvorgang.
(D). Kleine Feldlänge
Je kleiner die Länge des Clustered-Index-Schlüssels ist, desto mehr Indexdatensätze können auf einer Indexseite untergebracht werden, wodurch die Tiefe der Index-B-Baumstruktur verringert wird. Beispielsweise verfügt eine Tabelle mit Millionen von Datensätzen über einen int-Clusterindex und erfordert möglicherweise nur eine B-Baumstruktur mit drei Ebenen. Wenn der Clustered-Index für eine breitere Spalte definiert ist (die Spalte „uniqueidentifier“ erfordert beispielsweise 16 Bytes), erhöht sich die Tiefe des Index auf 4 Ebenen. Jede Clustered-Index-Suche erfordert 4 E/A-Vorgänge (um genau zu sein 4 logische Lesevorgänge) anstelle von nur 3 E/A-Vorgängen.
In ähnlicher Weise enthält der nicht gruppierte Index den Schlüsselwert des gruppierten Index. Je kleiner die Schlüssellänge des gruppierten Index ist, desto kleiner kann eine Indexseite sein.
wird auch in Seiten gespeichert (Seiten, die mit PageType 2 markiert sind, werden Indexseiten genannt). Zum Beispiel hat Tabelle T einen nicht gruppierten Index Index_A erstellt. Wenn Tabelle T 100 Datenelemente enthält, enthält Index_A auch 100 Datenelemente (genauer gesagt 100 Blattknotendaten und den Index). ist eine B-Baumstruktur. Wenn die Höhe des Baums größer als 0 ist, gibt es Stammknotenseiten- oder Zwischenknotenseitendaten, und die Indexdaten überschreiten 100. Wenn Tabelle T auch einen nicht gruppierten Index hat Index_B, dann hat Index_B auch mindestens 100 Daten, sodass der Index mehr erstellt wird. Je mehr, desto höher sind die Kosten.
Das Aktualisieren von Indexfeldern, das Einfügen eines Datenelements und das Löschen eines Datenelements führen zur Indexwartung und haben gewisse Auswirkungen auf die Leistung. Die Auswirkungen auf die Leistung sind in verschiedenen Situationen unterschiedlich. Wenn Sie beispielsweise einen Clustered-Index haben, befinden sich die eingefügten Daten alle am Ende, was fast nie zu einer Datenverschiebung führt. Wenn sich die eingefügten Daten in der Mitte befinden, führt dies im Allgemeinen zu einer Datenverschiebung und kann dazu führen Wenn die eingefügte mittlere Seite über genügend Platz für die eingefügten Daten verfügt und die Position am Ende der Seite liegt, führt dies nicht zu einer Datenverschiebung.
Es wird gesagt, dass der Index von SqlServer eine B-Baumstruktur ist (es wird angenommen, dass Sie haben ein gewisses Verständnis für die B-Baum-Struktur. Wie sieht sie also genau aus? Sie können SQL-Anweisungen verwenden, um ihre logische Darstellung anzuzeigen.
Neue Abfrageausführungssyntax: DBCC IND(Test,OrderBo,-1) – Die OrderBo-Tabelle der Testbibliothek enthält 10.000 Daten und verfügt über ein Clustered-Index-ID-Primärschlüsselfeld
(Sie können genauso gut selbst eine Tabelle mit einem Clustered-Index-Feld erstellen, 10.000 Tabellendaten einfügen und dann diese Syntax ausführen, um sie anzuzeigen. Sie werden viel gewinnen. Es ist besser, sie zu sehen, als sie hundertmal zu hören.)
Ausführungsergebnisse ::
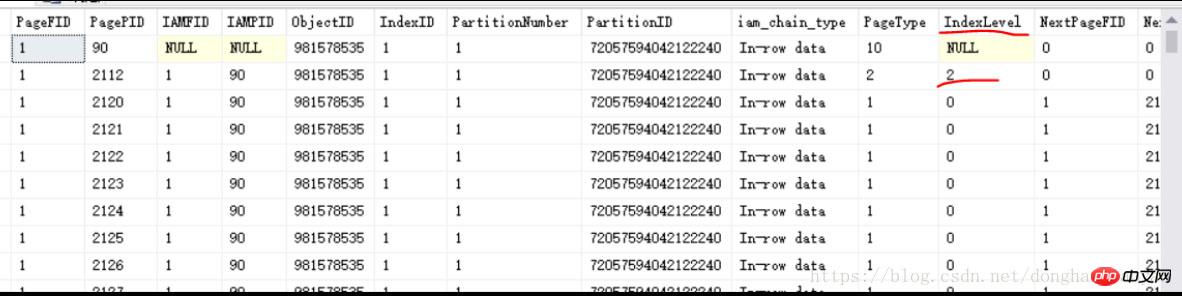
Wie im Bild oben gezeigt, sehen Sie eine Indexseite 2112 mit IndexLevel=2 (hier ist der Wurzelknoten des B-Baums, und der größte IndexLevel ist der Wurzelknoten, und darunter befindet sich eine Unterebene, eine Unterebene ... es gibt nur eine Stammseite als Zugriffseinstiegspunkt des B-Baums. Baumstruktur), was angibt, dass es eine Indexseite mit IndexLevel=1 und eine Blattseite mit IndexLevel=0 geben muss. Da es sich um einen Clustered-Index handelt, ist die Blattseite bei IndexLevel=0 die Datenseite, auf der physische Daten einzeln gespeichert werden. Wie Sie in der Abbildung oben sehen können, ist der PageType der Zeile mit IndexLevel=0 gleich 1, was die Datenseite darstellt. Wenn im obigen Kapitel über den Clustered-Index gesprochen wird, wird auch PageType=1 erwähnt ist ein nicht gruppierter Index, die Blattseite mit IndexLevel=0, PageType ist gleich 2, was immer noch eine Indexseite ist.
Ähnlich verwenden wir den SQL-Befehl DBCC PAGE, um einen Blick darauf zu werfen
-- DBCC TRACEON(3604,-1) DBCC PAGE(Test,1,2112,3) --根节点2112,可以查出它的两个子节点2280和2448,然后对这两个子节点再作DBCC PAGE查询 DBCC PAGE(Test,1,2280,3) DBCC PAGE(Test,1,2448,3)

Wie oben gezeigt, hat Seite 2112 mit IndexLevel=2 zwei untergeordnete Knoten 2280 und 2448 mit IndexLevel=1. Es gibt untergeordnete Knoten, die für einen anderen Indexschlüsselwert verantwortlich sind Bereich (d. h. im Feld „Id(key)“ in der obigen Abbildung ist der Wert in der ersten Zeile Null, was den Minimalwert oder den Maximalwert in umgekehrter Reihenfolge bedeutet). Ist eine solche hierarchische Beziehung eine B-Baumstruktur, wobei IndexLevel tatsächlich die Höhe in der B-Baumstruktur ist?
Wenn SqlServer nach einem bestimmten Datensatz im Index sucht, findet er die Blattknoten vom Wurzelknoten abwärts, da alle Datenadressen Blattknoten haben. Dies ist tatsächlich eines der Merkmale des B+-Baums ( Das Merkmal von B-Tree besteht darin, dass der gesuchte Wert direkt zurückgegeben werden kann, wenn er in einem Nicht-Blattknoten gefunden wird. Offensichtlich führt SqlServer dies nicht aus. Um dies zu überprüfen, können Sie die Statistik io aktivieren auf Statistiken, und wählen Sie dann aus, um die Anzahl der logischen Lesevorgänge anzuzeigen.
Da der Blattknoten definitiv gefunden wird, muss der Index, der Spalten enthält, nur an den Blattknoten aufgezeichnet werden, das heißt, Nicht-Blattknoten zeichnen keine enthaltenden Spalten auf „Index, der Spalten enthält“.
Die Eigenschaften des B+-Baums (Blattknoten sind in allen Datenadressen vorhanden) sind auch für die Intervallabfrage zwischen Wert1 und Wert2 förderlich, solange Sie Wert1 und Wert2 (an den Blattknoten) finden Aneinanderreihen. Das Ergebnis war.
Die SqlServer-Indexstruktur ähnelt eher einem B+-Baum und letztendlich einer Hybridversion eines B-Baums und eines B+-Baums. Die Datenstruktur wird von Menschen bestimmt und ist es nicht unbedingt ein reiner B-Baum oder ein reiner B+-Baum.
Apropos Indizes: Hier ist ein weiterer „Index mit Spalten“, der seit SqlServer2005 hinzugefügt wurde. Funktional, sehr praktisch.
Wenn Sie beispielsweise Daten in einem großen Bericht abfragen, verwendet die Where-Bedingung das Indexfeld Name2, aber das auszuwählende Feld ist Name1. Zu diesem Zeitpunkt können Sie „Index“ verwenden Inklusive Spalte“, um Name1 in das Indexfeld „Name2“ aufzunehmen, wird die Abfrageleistung erheblich verbessert.
Syntax: Erstellen Sie [UNIQUE] Nonclustered/Clustered Index IndexName On dbo.Table1(Name2) Include(Name1);
Analysieren Sie als Nächstes, warum der Index enthält Spalten können die Leistung erheblich verbessern. Verwenden Sie weiterhin den Befehl DBCC PAGE, um einen nicht gruppierten Index mit Indexdaten anzuzeigen, die Spalten enthalten:

Wie aus der obigen Abbildung ersichtlich ist, ist die enthaltende Spalte Name1 wird auch im Index in den Daten gespeichert. Wenn die Datenbank daher das Indexfeld Name2 verwendet, um eine bestimmte zu durchsuchende Zeile zu finden, kann sie den Wert von Name1 direkt zurückgeben, ohne ihn auf der Datenseite basierend auf der RID suchen zu müssen (das Bild oben zeigt die [HEAP-RID ( Schlüssel)] Spalte) Um den Wert zu erhalten, wird die Lesezeichensuche reduziert. Es spielt natürlich keine Rolle, wenn die Abfrage nur ein Datenelement und nur eine Lesezeichensuche zurückgibt. Wenn die von der Abfrage zurückgegebenen Daten groß sind, müssen Sie zur Datenseite gehen, um die Daten zu finden und sie abzurufen Datensätze bedeuten 1.000 Lesezeichensuchen. Sie können sich vorstellen, dass der Leistungsverbrauch zu diesem Zeitpunkt sehr groß ist.
Wenn die Tabelle über einen Clustered-Index (z. B. Id) verfügt, ähnelt dies bei einer Lesezeichensuche der Ausführung einer Auswahl von Name1 aus Tabelle1, wobei Id=1 ist und für die Suche der Clustered-Index-Schlüssel Id verwendet wird (Die Suchmethode ist die Index-ID-B-Tree-Struktursuche), und wenn die Tabelle keinen Clustered-Index hat, wird sie basierend auf dem Datenzeilenzeiger durchsucht (bestehend aus „Dateinummer 2 Byte: Seitennummer 4 Byte: Steckplatznummer 2 Byte“. "). Clustered-Indexschlüssel und Zeilenzeiger werden im Allgemeinen als RID-Zeiger (Row ID) bezeichnet. Von hier aus können wir denken: Wenn Ihre Tabelle kein gutes Clustered-Index-Feld hat, wird empfohlen, das selbstwachsende ID-Feld als Primärschlüssel des Clustered-Index zu verwenden (redundante ID-Felder sind ebenfalls akzeptabel). Dies steht im Einklang mit dem Selbstwachstum und wird nicht geändert. Die Einzigartigkeit und die geringe Länge machen es zu einer guten Wahl für Clustered-Indizes.
Selbst erhöhende ID ist in den meisten Fällen anwendbar. In besonderen Fällen hängt es von den spezifischen Bedürfnissen ab. Es gibt auch einen Fehler, der bei der selbsterhöhenden ID berücksichtigt werden muss. Beim gleichzeitigen Einfügen von Datensätzen mit einer großen Datenmenge in die Tabelle ist es denkbar, dass jeder Thread bis zur letzten Seite einfügen muss und es zu Konkurrenz und Warten kommt. Um diese Situation zu lösen, können Sie Felder vom Typ UniqueIdentifier (16 Bytes, ich empfehle die Verwendung nicht) oder Hash-Partitionierung (d. h. eine Tabelle wird in mehrere Tabellen unterteilt, es ist normal, Datenbanken und Tabellen bei der Big-Data-Verarbeitung zu unterteilen) verwenden. , usw. Ich empfehle jedoch, zunächst die Einfügeeffizienz zu optimieren (die Einfügeleistung selbst ist sehr schnell) und zu testen, ob die Anzahl gleichzeitiger Einfügungen pro Sekunde der Produktionsumgebung entspricht, um die einfache, stabile und effiziente Methode der selbsterhöhenden ID beizubehalten.
Selbst erhöhende ID bedeutet nicht unbedingt, die von der Datenbank bereitgestellte selbst erhöhende ID zu verwenden. Sie können auch Ihren eigenen Algorithmus schreiben, um eine ID zu generieren, die in gleichzeitigen Situationen eindeutig ist (die Die allgemeine Länge ist derzeit bitint, 8-Byte-Shaping). Diese Situation eignet sich für das Szenario, in dem das ID-Feld während der Master-Slave-Replikation in einer verteilten Datenbank nicht fehlerfrei sein darf (im allgemeinen Modus der Master-Slave-Replikation, Die ID der Master-Datenbank erhöht sich entsprechend der Master-Datenbank, und die ID der Slave-Datenbank wächst auch entsprechend der Slave-Bibliothek selbst. Wenn die Master-Slave-Replikation aufgrund von Deadlocks und anderen Gründen nicht synchron ist, wird die ID des Slaves erhöht (Die Bibliothek stimmt nicht mit der ID der Master-Bibliothek überein.) Wenn es sich bei der sich selbst erhöhenden ID um einen redundanten Primärschlüssel handelt, hat dies keine Auswirkung, wenn die Master-Slave-Datenbank-ID nicht mit der Nummer übereinstimmt.
Darüber hinaus sagt uns die letzte Spalte [Zeilengröße] im obigen Bild auch: Die Größe der Indexspalte oder der den Index enthaltenden Spalte sollte nicht zu lang sein, Andernfalls kann eine Seite nicht mehrere Datensätze aufnehmen. Dadurch erhöht sich die Anzahl der Indexseiten erheblich und der von den Indexdaten belegte Platz nimmt ebenfalls erheblich zu.
Das obige ist der detaillierte Inhalt vonDer Editor führt Sie durch eine detaillierte Analyse der Prinzipien von SQL Server-Indizes. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



