
 Java
javaLernprogramm
Eine kurze Diskussion über den Entwicklungsprozess der verteilten Java-Anwendungsarchitektur
Java
javaLernprogramm
Eine kurze Diskussion über den Entwicklungsprozess der verteilten Java-Anwendungsarchitektur
Eine kurze Diskussion über den Entwicklungsprozess der verteilten Java-Anwendungsarchitektur

1. Die Entwicklungsgeschichte der verteilten Architektur
1946 wurde an der University of Pennsylvania in den Vereinigten Staaten der erste elektronische Computer geboren. ENICAC, dieser Computer ist relativ schwer und seine Rechengeschwindigkeit ist nicht hoch, aber er stellt den Beginn des Computerzeitalters dar und ist von grundlegender Bedeutung für die zukünftige Entwicklung des Internets.
Der Aufbau eines Computers besteht aus fünf Teilen: Eingabegerät, Ausgabegerät, Speicher. Es gibt ein von Neumann-Modell, das ein sehr anschaulicher Objektcomputer ist Die Zusammensetzung wurde beschrieben, aber der Computer verfügt auch über einen Datenfluss, einen Befehlsfluss und einen Kontrollfluss, um Berechnungen durchzuführen und normal zu funktionieren. Wie im Bild gezeigt:
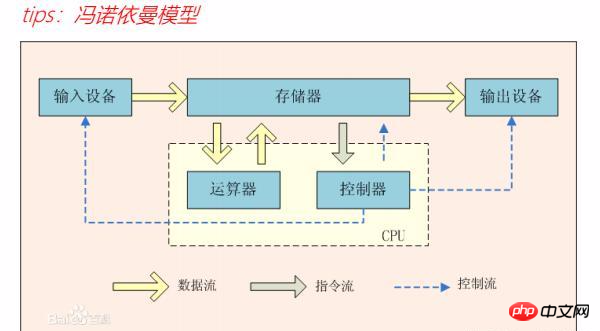
Nach ENIAC traten elektronische Computer in die Ära der Großrechner ein, die 1946 von IBM dominiert wurde Großrechner Die Maschine SYSTEM/360 wurde geboren, die es IBM in den 1950er und 1960er Jahren ermöglichte, die gesamte Großrechnerindustrie zu dominieren. Im Zeitalter der Großrechner entwickelte sich die Computerarchitektur in zwei Richtungen: CISC (von Mikroprozessoren ausgeführter Computersprachenbefehlssatz) und CPU Die Architekturen reichen von kostengünstigen Personal-PCs bis hin zu teuren kleinen UNIX-Servern mit RISC-Anordnung (Reduced Instruction Set Computer).
Das Aufkommen von Großrechnern mit ihrer Rechenleistung und Verarbeitungsleistung sowie ihrer hohen Stabilität und Sicherheit hat die Entwicklung des Computerbereichs lange Zeit vorangetrieben. Zentralisierte Computersysteme haben jedoch einige Probleme mit sich gebracht und sind zunehmend nicht in der Lage, die Bedürfnisse der Benutzer zu erfüllen:
1. Große Hosts sind sehr teuer und können sich normale kleine Unternehmen nicht leisten.
2. Mainframes sind komplexer und die Kosten für die Ausbildung von Talenten sind relativ hoch.
3. Ein einzelnes Problem, wie z. B. ein Mainframe-Ausfall, führt dazu, dass das gesamte System ausfällt und nicht betriebsbereit ist, was zu enormen Verlusten für das Unternehmen führt.
4. Mit der Weiterentwicklung der Technologie wird die Leistung persönlicher PCs immer höher und die Kosten immer niedriger.
Alibaba startete 2009 eine Kampagne zur Eliminierung von „IOE“
IOE bezieht sich auf die Minicomputer von IBM, die Datenbanken von Oracle und die High-End-Speichergeräte von EMC. Die Umstellung auf De-IOE im Jahr 2009 dauerte an, bis der letzte IBM-Minicomputer von Alipay im Jahr 2003 offline war.
Warum zu IOE gehen?
Alibaba nutzte in der Vergangenheit Oracle für seine Datenbank und nutzte Minicomputer und High-End-Speichergeräte, um eine leistungsstarke Datenverarbeitung und -speicherung bereitzustellen Dienstleistungen. Da das Geschäftsvolumen des Unternehmens zunimmt und die Anzahl der Benutzer weiter zunimmt, stößt die traditionelle Oracle-Datenbank mit zentraler Architektur auf Engpässe bei der Erweiterung. Im Vergleich zu herkömmlichen Oracle- und DB2-Systemen besteht der Nachteil darin, dass die Skalierbarkeit hauptsächlich nach oben und nicht nach oben gerichtet ist. Dies wird früher oder später zu Engpässen führen.
1. Gemeinsame Konzepte der verteilten Architektur
Cluster
Das kleine Restaurant war ein Koch, der Gemüse schnitt und wusch, Zutaten zubereitete und alle Gerichte gekocht. Als später mehr Kunden da waren, war ein Koch in der Küche zu beschäftigt, also wurde ein anderer Koch eingestellt. Beide Köche konnten die gleichen Gerichte kochen.
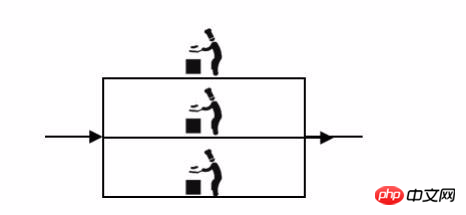
Verteilt
Damit sich der Koch auf das Kochen und die Zubereitung konzentrieren kann Gerichte perfekt, ich habe auch einen Beilagenkoch engagiert, der für das Schneiden des Gemüses, die Zubereitung des Gemüses und die Zubereitung der Zutaten verantwortlich ist. Selbst ein Beilagenkoch ist zu beschäftigt Der Küchenchef bereitet diese beiden Beilagen zu. Die Beziehung zwischen Lehrern und Lehrern ist ein Cluster. Daher kann es in einer verteilten Architektur Cluster geben, aber Cluster bedeuten nicht verteilt.
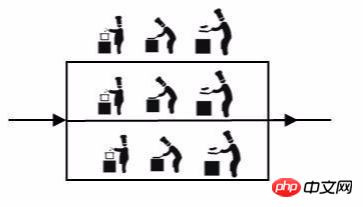
Knoten
Ein Knoten bezieht sich auf ein einzelnes Programm, das unabhängig einen Satz Logik gemäß einem verteilten Protokoll vervollständigen kann. In einem bestimmten Projekt stellt ein Knoten einen Prozess auf dem Betriebssystem dar.
Replikationsmechanismus
Replikation bezieht sich auf die Bereitstellung von Redundanz für Daten oder Dienste in einem verteilten System.
Datenkopie bezieht sich auf das Beibehalten derselben Daten auf verschiedenen Knoten. Wenn Daten auf einem bestimmten Knoten verloren gehen, können die Daten aus der Kopie gelesen werden. Datenkopien sind in verteilten Systemen die einzige Möglichkeit, die zu Datenverlust führen kann.
Das Dienstreplikat stellt eine Hochverfügbarkeitslösung für mehrere Knoten dar, um denselben Dienst über eine Master-Slave-Beziehung bereitzustellen.
Middleware
Middleware ist zusätzlich zu den vom Betriebssystem bereitgestellten Diensten und gehört nicht zur Anwendung. Sie befindet sich zwischen der Anwendungs- und Systemebene für Entwickler. Eine Art Software, die Kommunikation, Eingabe und Ausgabe bequem abwickelt und es den Benutzern ermöglicht, sich um diesen Teil ihrer Anwendung zu kümmern.
Der Entwicklungsprozess der Architektur
Eine ausgereifte, groß angelegte Website-Systemarchitektur ist nicht von Anfang an perfekt konzipiert und verfügt auch nicht von Anfang an über hohe Leistung, hohe Verfügbarkeit, Sicherheit und andere Funktionen , aber mit zunehmender Benutzerzahl wird die Erweiterung der Geschäftsfunktionen schrittweise verbessert und weiterentwickelt. In diesem Entwicklungsprozess werden sich Entwicklungsmodelle, technische Architektur usw. stark verändern.
Angenommen, das System verfügt über die folgenden Funktionen:
Benutzermodul: Benutzerregistrierung und -verwaltung
Produktmodul : Produkte anzeigen und verwalten
Transaktionsmodul: Transaktionen und Zahlungsabwicklung erstellen
Phase 1: Single Application Architecture
Zu Beginn des Systems werden sowohl die Anwendung als auch die Datenbank auf einem Server platziert.

Phase 2: Trennung von Anwendungsserver und Datenbankserver
Da die Anzahl der Benutzer der Website steigt, steigt der Datenverkehr, Anwendungsserver und Datenbank trennen Server Durch den Einsatz von Maschinen kann die Systemleistung gesteigert, die Zugriffseffizienz verbessert sowie die Auslastungskapazität und die Notfallwiederherstellungsfähigkeiten einer einzelnen Maschine verbessert werden.
Phase 3: Anwendungsserver-Cluster – Anwendungsserver-Auslastungsalarm
Wenn die Anzahl der Besuche und der Datenverkehr zunimmt und die Datenbank keine Engpässe aufweist, wird der Anwendungsserver-Cluster zum Auslagern verwendet Anforderungen zu erfüllen und die Programmleistung zu verbessern. Bestehende Probleme: Wer leitet die Anfrage des Benutzers weiter und wie wird die Sitzung verwaltet?
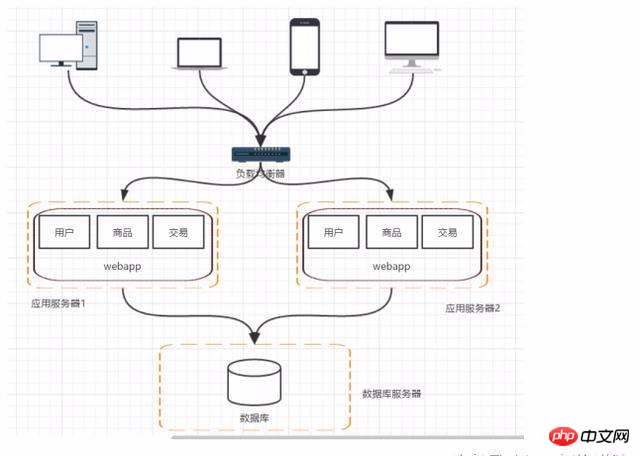
Phase 4: Datenbankdruck steigt – Lese- und Schreibtrennung der Datenbank
Wenn Lesen und Schreiben getrennt sind, können zukünftige Anfragen und Abfrageanfragen von Reading ausgehen Daten in der Bibliothek und Schreibdaten können an die Hauptbibliothek gesendet werden, dies bringt jedoch mehrere Probleme mit sich:
1. Datensynchronisation zwischen Master- und Slave-Datenbanken: Sie können die mit MySQL gelieferte Master-Slave-Methode verwenden um eine Master-Slave-Replikation zu erreichen
2. Auswahl der entsprechenden Datenquelle: Verwenden Sie Datenbank-Middleware von Drittanbietern, zum Beispiel: mycat
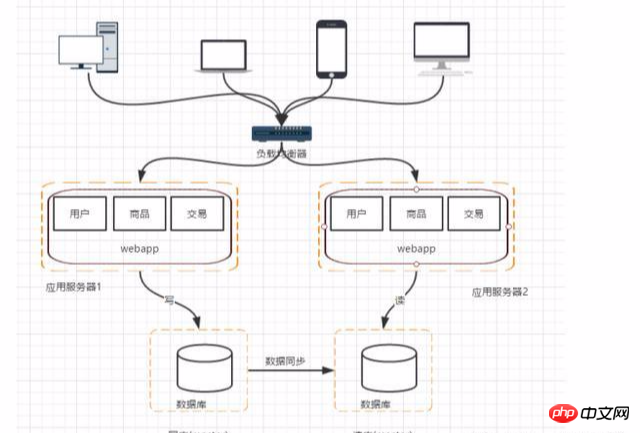
Stufe 5: Verwenden Sie Suchmaschinen, um den Druck beim Lesen von Datenbanken zu verringern
Wenn Datenbanken zum Lesen von Datenbanken verwendet werden, ist die Leistung von Fuzzy-Abfragen häufig nicht sehr gut, insbesondere bei großen Internetunternehmen, die suchen möchten für Module Der Kern besteht darin, dass Sie Suchmaschinen verwenden können, obwohl dies die Abfragegeschwindigkeit erheblich verbessern kann, es jedoch auch einige Probleme wie die Indexerstellung verursacht.
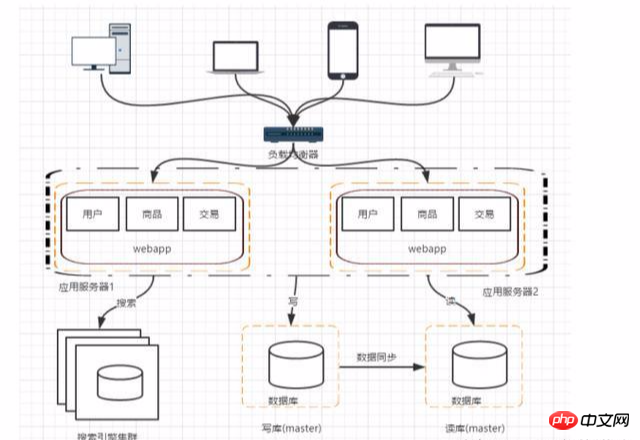
Stufe 6: Einführung eines Caching-Mechanismus, um den Druck auf die Datenbank zu verringern
Für einige heiße Daten können Redis und Memcache als Cache auf Anwendungsebene verwendet werden ; zusätzlich In einigen Szenarien kann Mongodb verwendet werden, um relationale Datenbanken für die Speicherung zu ersetzen.
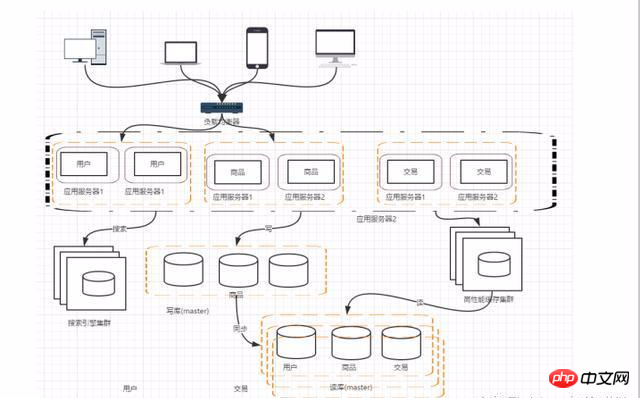
Phase 7: Horizontale/vertikale Aufteilung der Datenbank
Vertikale Aufteilung: Verschiedene Geschäftsdaten in der Datenbank in verschiedene in der Datenbank aufteilen.
Horizontale Aufteilung: Teilen Sie die Daten in derselben Tabelle in zwei oder mehr Datenbanken auf. Der Grund für die horizontale Aufteilung ist, dass einige Unternehmen mit großen Datenmengen den Engpass einer einzelnen Datenbank erreicht haben. Sie können die Tabelle in mehrere Datenbanken aufteilen.

Stufe 8: Aufteilung der Anträge
Mit der Geschäftsentwicklung gibt es immer mehr Unternehmen und der Druck auf Anträge nimmt zu. Auch der Umfang des Projekts wird immer größer. Zu diesem Zeitpunkt können Sie erwägen, die Anwendung aufzuteilen und unsere Benutzer, Produkte und Transaktionen gemäß dem Domänenmodell in Subsysteme aufzuteilen.
Nach der Aufteilung auf diese Weise können einige identische Codes vorhanden sein, z. B. Benutzervorgänge und Produkttransaktionsabfragen, die alle zu Benutzerabfragen und zugriffsbezogenen Problemen führen jeder Systembetrieb. Dieselben Codes und Module müssen abstrahiert werden. Dies erleichtert die Wartung und Verwaltung.
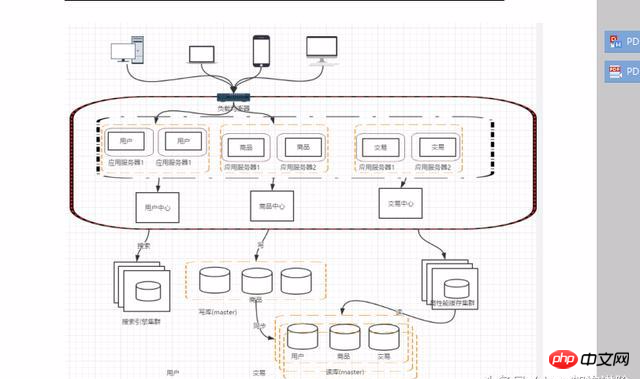
Nachdem der Dienst aufgeteilt wurde, kann die Kommunikation zwischen Diensten über RPC-Technologie erfolgen. Typische davon sind: Webservice, Hession, http, RMI usw.
Das obige ist der detaillierte Inhalt vonEine kurze Diskussion über den Entwicklungsprozess der verteilten Java-Anwendungsarchitektur. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
In diesem Artikel haben wir die am häufigsten gestellten Fragen zu Java Spring-Interviews mit ihren detaillierten Antworten zusammengestellt. Damit Sie das Interview knacken können.
 Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Java 8 führt die Stream -API ein und bietet eine leistungsstarke und ausdrucksstarke Möglichkeit, Datensammlungen zu verarbeiten. Eine häufige Frage bei der Verwendung von Stream lautet jedoch: Wie kann man von einem Foreach -Betrieb brechen oder zurückkehren? Herkömmliche Schleifen ermöglichen eine frühzeitige Unterbrechung oder Rückkehr, aber die Stream's foreach -Methode unterstützt diese Methode nicht direkt. In diesem Artikel werden die Gründe erläutert und alternative Methoden zur Implementierung vorzeitiger Beendigung in Strahlverarbeitungssystemen erforscht. Weitere Lektüre: Java Stream API -Verbesserungen Stream foreach verstehen Die Foreach -Methode ist ein Terminalbetrieb, der einen Vorgang für jedes Element im Stream ausführt. Seine Designabsicht ist
 Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Anleitung zum TimeStamp to Date in Java. Hier diskutieren wir auch die Einführung und wie man Zeitstempel in Java in ein Datum konvertiert, zusammen mit Beispielen.
 Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Java ist eine beliebte Programmiersprache, die sowohl von Anfängern als auch von erfahrenen Entwicklern erlernt werden kann. Dieses Tutorial beginnt mit grundlegenden Konzepten und geht dann weiter zu fortgeschrittenen Themen. Nach der Installation des Java Development Kit können Sie das Programmieren üben, indem Sie ein einfaches „Hello, World!“-Programm erstellen. Nachdem Sie den Code verstanden haben, verwenden Sie die Eingabeaufforderung, um das Programm zu kompilieren und auszuführen. Auf der Konsole wird „Hello, World!“ ausgegeben. Mit dem Erlernen von Java beginnt Ihre Programmierreise, und wenn Sie Ihre Kenntnisse vertiefen, können Sie komplexere Anwendungen erstellen.
 Java -Programm, um das Kapselvolumen zu finden
Feb 07, 2025 am 11:37 AM
Java -Programm, um das Kapselvolumen zu finden
Feb 07, 2025 am 11:37 AM
Kapseln sind dreidimensionale geometrische Figuren, die aus einem Zylinder und einer Hemisphäre an beiden Enden bestehen. Das Volumen der Kapsel kann berechnet werden, indem das Volumen des Zylinders und das Volumen der Hemisphäre an beiden Enden hinzugefügt werden. In diesem Tutorial wird erörtert, wie das Volumen einer bestimmten Kapsel in Java mit verschiedenen Methoden berechnet wird. Kapselvolumenformel Die Formel für das Kapselvolumen lautet wie folgt: Kapselvolumen = zylindrisches Volumenvolumen Zwei Hemisphäre Volumen In, R: Der Radius der Hemisphäre. H: Die Höhe des Zylinders (ohne die Hemisphäre). Beispiel 1 eingeben Radius = 5 Einheiten Höhe = 10 Einheiten Ausgabe Volumen = 1570,8 Kubikeinheiten erklären Berechnen Sie das Volumen mithilfe der Formel: Volumen = π × R2 × H (4
 Wie führe ich Ihre erste Spring -Boot -Anwendung in der Spring Tool Suite aus?
Feb 07, 2025 pm 12:11 PM
Wie führe ich Ihre erste Spring -Boot -Anwendung in der Spring Tool Suite aus?
Feb 07, 2025 pm 12:11 PM
Spring Boot vereinfacht die Schaffung robuster, skalierbarer und produktionsbereiteter Java-Anwendungen, wodurch die Java-Entwicklung revolutioniert wird. Der Ansatz "Übereinkommen über Konfiguration", der dem Feder -Ökosystem inhärent ist, minimiert das manuelle Setup, Allo
 Java leicht gemacht: Ein Leitfaden für Anfänger zur Programmierleistung
Oct 11, 2024 pm 06:30 PM
Java leicht gemacht: Ein Leitfaden für Anfänger zur Programmierleistung
Oct 11, 2024 pm 06:30 PM
Java leicht gemacht: Ein Leitfaden für Anfänger zur leistungsstarken Programmierung Java ist eine leistungsstarke Programmiersprache, die in allen Bereichen von mobilen Anwendungen bis hin zu Systemen auf Unternehmensebene verwendet wird. Für Anfänger ist die Syntax von Java einfach und leicht zu verstehen, was es zu einer idealen Wahl zum Erlernen des Programmierens macht. Grundlegende Syntax Java verwendet ein klassenbasiertes objektorientiertes Programmierparadigma. Klassen sind Vorlagen, die zusammengehörige Daten und Verhaltensweisen organisieren. Hier ist ein einfaches Java-Klassenbeispiel: publicclassPerson{privateStringname;privateintage;
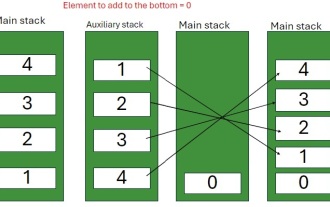 Java -Programm zum Einfügen eines Elements am unteren Rand eines Stapels
Feb 07, 2025 am 11:59 AM
Java -Programm zum Einfügen eines Elements am unteren Rand eines Stapels
Feb 07, 2025 am 11:59 AM
Ein Stapel ist eine Datenstruktur, die dem LIFO -Prinzip (zuletzt, zuerst heraus) folgt. Mit anderen Worten, das letzte Element, das wir einem Stapel hinzufügen, ist das erste, das entfernt wird. Wenn wir einem Stapel Elemente hinzufügen (oder drücken), werden sie oben platziert. vor allem der
