
 Datenbank
MySQL-Tutorial
Detaillierte Erläuterung des MySQL-Master-Slave-Synchronisationsprinzips, der Konfiguration und der Verzögerung
Datenbank
MySQL-Tutorial
Detaillierte Erläuterung des MySQL-Master-Slave-Synchronisationsprinzips, der Konfiguration und der Verzögerung
Detaillierte Erläuterung des MySQL-Master-Slave-Synchronisationsprinzips, der Konfiguration und der Verzögerung
In diesem Artikel werden das Master-Slave-Synchronisationsprinzip, die Master-Slave-Synchronisationskonfiguration und die Master-Slave-Synchronisationsverzögerung von MySQL vorgestellt Wird auch als Master-Slave-Replikation bezeichnet und dient zum Einrichten einer Datenbankumgebung, die genau mit der Hauptdatenbank identisch ist. Durch die Master-Slave-Synchronisierung können Daten von einem Datenbankserver auf andere Server kopiert werden, um sicherzustellen, dass die Daten in der Master-Datenbank und den Daten in der Slave-Datenbank konsistent sind.
Der Cluster ist ein gemeinsam genutzter Speicher, bei dem es sich bei der Master-Slave-Replikation um keine gemeinsame Nutzung handelt -Sharing.
Prinzip der Master-Slave-Synchronisation
-
Es gibt drei Hauptmethoden zur Implementierung der Master-Slave-Replikation nach mysql5.6:
1. Asynchrone Replikation
3. Halbsynchrone Replikation
- Master-Slave-Synchronisationsschema
 1 ) der Master-Datenbank werden im Binärprotokoll geschrieben.
1 ) der Master-Datenbank werden im Binärprotokoll geschrieben.
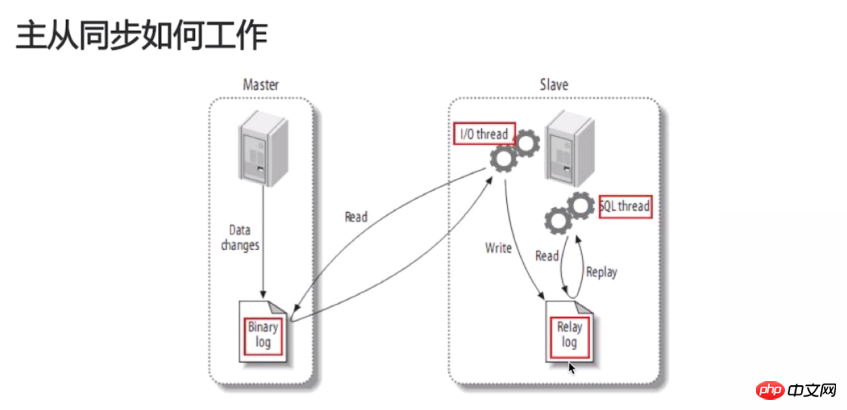
2. Die Slave-Bibliothek erstellt einen E/A-Thread, der eine Verbindung zur Hauptbibliothek herstellt und die Hauptbibliothek auffordert, die Aktualisierungsdatensätze im zu senden Binlog an die Slave-Bibliothek. Die Hauptbibliothek erstellt ein Binlog. Der Dump-Thread sendet den Inhalt des Binlogs an die Slave-Bibliothek. Der E/A-Thread der Slave-Bibliothek liest die vom Ausgabethread der Hauptbibliothek gesendeten Aktualisierungen diese Aktualisierungen der lokalen Relay-Protokolldatei.
Von Die Bibliothek erstellt einen SQL-Thread. Dieser Thread liest die in das Relay-Protokoll geschriebenen Aktualisierungsereignisse aus dem Bibliotheks-E/A-Thread.
Implementierung der Master-Slave-Synchronisation (asynchrone Replikation, Datenbanken auf verschiedenen Servern)
1. Konfigurieren Sie die Hauptdatenbank zum Öffnen des Binärprotokolls
vim /etc/my.cnf 在[mysqld]下添加 server-id=1(用来标识不同的数据库)log-bin=master-bin(打开bin-log并配置文件名为master-bin)log-bin-index=master-bin.index(区分不同的log-bin文件)
Starten Sie die Datenbank neu: systemctl restart mariadb. service
2. Konfigurieren Sie die Slave-Datenbank zum Öffnen von Relay-Log
Starten Sie die Datenbank neu: systemctl restart mariadb.service
3 Datenbanken
In der Hauptdatenbank: Erstellen Sie eine Benutzerreplikation, die für jeden Slave-Server erforderlich ist. Ein Kontoname und ein Passwort für die Master-Datenbank, um eine Verbindung zum Master-Server herzustellen
vim /etc/my.cnf 在[mysqld]下添加 server-id=2relay-log=slave-relay-bin(打开relay-log并配置文件名为slave-relay-bin) relay-log-index=slave-relay-bin.index
CREATE USER 'repl'@'114.116.77.213' IDENTIFIED BY '12312';GRANT REPLICATION SLAVE ON *.* TO 'repl'@'114.116.77.213' IDENTIFIED BY '12312';
Überprüfen
Erstellen Sie eine Datenbank in der Master-Datenbank und zeigen Sie dann die Rolle der Master-Slave-Synchronisierung in der Slave-Datenbank an
1 Führen Sie eine Hot-Sicherung der Daten durch Backup-Datenbank: Nachdem der Hauptdatenbankserver ausgefallen ist, können Sie zur Slave-Datenbank wechseln, um weiterzuarbeiten und Datenverluste zu vermeiden.
2. Durch die Lese- und Schreibtrennung kann die Datenbank eine größere Parallelität unterstützen .
Hinweise zur Master-Slave-Synchronisation
Die Master-Bibliothek kann Daten lesen und schreiben, während die Slave-Bibliothek nur Daten lesen kann, da der Slave Wenn die Bibliothek Daten schreibt, ändert sich die Position, aber die Position der Hauptbibliothek ändert sich nicht.- Wann Die Binärprotokolldatei der Hauptbibliothek speichert viele Daten. Wenn die Position sehr groß ist, wird eine neue Binärprotokolldatei aufgeteilt und die Position auf 0 gesetzt >mysql der Master-Slave-Bibliothek Die Versionen können unterschiedlich sein, aber die MySQL-Version der Slave-Bibliothek ist höher als die Version der Hauptbibliothek. Andernfalls werden die Anweisungen der Hauptbibliothek möglicherweise nicht ausgeführt, wenn sie die Slave-Bibliothek erreichen . Da MySQL abwärtskompatibel ist, heißt es, dass die Anweisungen der niedrigeren Version in der höheren Version unterstützt werden, einige Anweisungen der höheren Version jedoch nicht in der niedrigeren Version
Interviewbezogen
(Wenn Sie Fragen zu Datenbank-Master-Slave-Problemen stellen, müssen Sie die folgenden Fragen stellen): -
Was sind die Vorteile von Master-Slave?
- Kennen Sie das Latenzproblem beim Lesen aus der Datenbank? Wie kann man es lösen?
- Was soll ich tun, wenn der Master-Server abstürzt, nachdem er Master und Slave war?
- Der Grund für die Verzögerung der Master-Slave-Synchronisation
- Der Grund für die Verzögerung der Master-Slave-Synchronisation
- Problem mit der Verzögerung der Master-Slave-Synchronisation
-
1. Gründe für die Verzögerung der Master-Slave-Synchronisation
Wir wissen, dass ein Server geöffnet ist. Es werden N-Links bereitgestellt, über die der Client eine Verbindung herstellen kann, sodass große gleichzeitige Aktualisierungsvorgänge stattfinden, es jedoch nur einen Thread gibt, der das Binlog vom Server liest. Wenn eine bestimmte SQL erforderlich ist Die Ausführung auf dem Slave-Server dauert länger oder aufgrund einiger Sperren der Tabelle für jedes SQL führt dies zu einem großen SQL-Rückstand auf dem Master-Server und wird nicht mit dem Slave-Server synchronisiert. Dies führt zu einer Master-Slave-Inkonsistenz, also einer Master-Slave-Verzögerung. 2. Lösung für die Master-Slave-Synchronisationsverzögerung Tatsächlich gibt es keine Komplettlösung für die Master-Slave-Synchronisationsverzögerung, da das gesamte SQL auf dem Slave-Server ausgeführt werden muss Wenn der Hauptserver weiterhin Aktualisierungsvorgänge ausführt und kontinuierlich schreibt, ist die Wahrscheinlichkeit einer Verschlimmerung der Verzögerung größer, sobald eine Verzögerung auftritt. Natürlich können wir einige Abhilfemaßnahmen ergreifen.
a. Wir wissen, dass der Master-Server höhere Sicherheitsanforderungen hat als der Slave-Server, z. B. sync_binlog=1, innodb_flush_log_at_trx_commit = 1 usw., aber der Slave Für eine so hohe Datensicherheit können Sie sync_binlog auf 0 setzen oder binlog deaktivieren. Innodb_flushlog und innodb_flush_log_at_trx_commit können auch auf 0 gesetzt werden, um die Ausführungseffizienz von SQL zu verbessern. Die andere besteht darin, ein besseres Hardwaregerät als die Hauptbibliothek als Slave zu verwenden.
b. Das heißt, ein Slave-Server wird als Backup verwendet, ohne Abfragen bereitzustellen. Wenn seine Last reduziert wird, ist die Effizienz der Ausführung des SQL im Relay-Protokoll natürlich höher.
c. Der Zweck des Hinzufügens von Slave-Servern besteht darin, den Lesedruck zu verteilen und dadurch die Serverlast zu reduzieren.
Verwandte Empfehlungen:
Analyse und Lösungen des MYSQL-Master-Slave-Synchronisationsverzögerungsprinzips
MYSQL-Master-Slave-Synchronisationsverzögerungsprinzip
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung des MySQL-Master-Slave-Synchronisationsprinzips, der Konfiguration und der Verzögerung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Wie verändern Sie eine Tabelle in MySQL mit der Änderungstabelleanweisung?
Mar 19, 2025 pm 03:51 PM
Wie verändern Sie eine Tabelle in MySQL mit der Änderungstabelleanweisung?
Mar 19, 2025 pm 03:51 PM
In dem Artikel werden mithilfe der Änderungstabelle von MySQL Tabellen, einschließlich Hinzufügen/Löschen von Spalten, Umbenennung von Tabellen/Spalten und Ändern der Spaltendatentypen, erläutert.
 Erläutern Sie InnoDB Volltext-Suchfunktionen.
Apr 02, 2025 pm 06:09 PM
Erläutern Sie InnoDB Volltext-Suchfunktionen.
Apr 02, 2025 pm 06:09 PM
Die Volltext-Suchfunktionen von InnoDB sind sehr leistungsfähig, was die Effizienz der Datenbankabfrage und die Fähigkeit, große Mengen von Textdaten zu verarbeiten, erheblich verbessern kann. 1) InnoDB implementiert die Volltext-Suche durch invertierte Indexierung und unterstützt grundlegende und erweiterte Suchabfragen. 2) Verwenden Sie die Übereinstimmung und gegen Schlüsselwörter, um den Booleschen Modus und die Phrasesuche zu unterstützen. 3) Die Optimierungsmethoden umfassen die Verwendung der Word -Segmentierungstechnologie, die regelmäßige Wiederaufbauung von Indizes und die Anpassung der Cache -Größe, um die Leistung und Genauigkeit zu verbessern.
 Wie konfiguriere ich die SSL/TLS -Verschlüsselung für MySQL -Verbindungen?
Mar 18, 2025 pm 12:01 PM
Wie konfiguriere ich die SSL/TLS -Verschlüsselung für MySQL -Verbindungen?
Mar 18, 2025 pm 12:01 PM
In Artikel werden die Konfiguration der SSL/TLS -Verschlüsselung für MySQL, einschließlich der Erzeugung und Überprüfung von Zertifikaten, erläutert. Das Hauptproblem ist die Verwendung der Sicherheitsauswirkungen von selbstsignierten Zertifikaten. [Charakterzahl: 159]
 Was sind einige beliebte MySQL -GUI -Tools (z. B. MySQL Workbench, PhpMyAdmin)?
Mar 21, 2025 pm 06:28 PM
Was sind einige beliebte MySQL -GUI -Tools (z. B. MySQL Workbench, PhpMyAdmin)?
Mar 21, 2025 pm 06:28 PM
In Artikel werden beliebte MySQL -GUI -Tools wie MySQL Workbench und PhpMyAdmin beschrieben, die ihre Funktionen und ihre Eignung für Anfänger und fortgeschrittene Benutzer vergleichen. [159 Charaktere]
 Wie behandeln Sie große Datensätze in MySQL?
Mar 21, 2025 pm 12:15 PM
Wie behandeln Sie große Datensätze in MySQL?
Mar 21, 2025 pm 12:15 PM
In Artikel werden Strategien zum Umgang mit großen Datensätzen in MySQL erörtert, einschließlich Partitionierung, Sharding, Indexierung und Abfrageoptimierung.
 Wie lassen Sie eine Tabelle in MySQL mit der Drop -Tabelle -Anweisung fallen?
Mar 19, 2025 pm 03:52 PM
Wie lassen Sie eine Tabelle in MySQL mit der Drop -Tabelle -Anweisung fallen?
Mar 19, 2025 pm 03:52 PM
In dem Artikel werden in MySQL die Ablagerung von Tabellen mithilfe der Drop -Tabellenerklärung erörtert, wobei Vorsichtsmaßnahmen und Risiken betont werden. Es wird hervorgehoben, dass die Aktion ohne Backups, die Detaillierung von Wiederherstellungsmethoden und potenzielle Produktionsumfeldgefahren irreversibel ist.
 Erklären Sie verschiedene Arten von MySQL-Indizes (B-Tree, Hash, Volltext, räumlich).
Apr 02, 2025 pm 07:05 PM
Erklären Sie verschiedene Arten von MySQL-Indizes (B-Tree, Hash, Volltext, räumlich).
Apr 02, 2025 pm 07:05 PM
MySQL unterstützt vier Indextypen: B-Tree, Hash, Volltext und räumlich. 1.B-Tree-Index ist für die gleichwertige Suche, eine Bereichsabfrage und die Sortierung geeignet. 2. Hash -Index ist für gleichwertige Suche geeignet, unterstützt jedoch keine Abfrage und Sortierung von Bereichs. 3. Die Volltextindex wird für die Volltext-Suche verwendet und ist für die Verarbeitung großer Mengen an Textdaten geeignet. 4. Der räumliche Index wird für die Abfrage für Geospatial -Daten verwendet und ist für GIS -Anwendungen geeignet.
 Wie erstellen Sie Indizes für JSON -Spalten?
Mar 21, 2025 pm 12:13 PM
Wie erstellen Sie Indizes für JSON -Spalten?
Mar 21, 2025 pm 12:13 PM
In dem Artikel werden in verschiedenen Datenbanken wie PostgreSQL, MySQL und MongoDB Indizes für JSON -Spalten in verschiedenen Datenbanken erstellt, um die Abfrageleistung zu verbessern. Es erläutert die Syntax und die Vorteile der Indizierung spezifischer JSON -Pfade und listet unterstützte Datenbanksysteme auf.
