

Analyse häufig verwendeter Tags in HTML (mit Code)

Der Inhalt dieses Artikels befasst sich mit der Analyse häufig verwendeter Tags in HTML (mit Code). Ich hoffe, dass er für Freunde hilfreich ist.
1.1 Klassifizierung von Tags
1.1.1 Klassifizierung nach Betreff:
1. Tags mit Betreff: Zum Beispiel data
2. Tags ohne Betreff: wie zum Beispiel
Zeilenumbruch-Tags
, um zu bestimmen, ob eine Tabelle benötigt wird Was den Körper betrifft, können Sie darüber nachdenken, ob das Tag Daten kapseln muss. Wenn es Daten kapseln muss, muss das Tag einen Körper haben. Wenn es keine Daten kapseln muss, gibt es keinen muss einen Körper haben .
2.1.2 Klassifizierung nach Zeile :
1. Wenn der Inhalt eines Etiketts eine unabhängige Zeile belegen muss, nennen wir es ein Blocketikett. Zum Beispiel:Titel-Tag
2. Wenn ein Tag keine separate Zeile belegen muss, nennen wir es ein Inline-Tag. Zum Beispiel: Font-Tag2.2 Text-Tag:
Tag-Name
|
Tag-Beschreibung | Gemeinsame Attribute | ||||||||||||||||||||||||
| h1~h6 | Titel-Tag, Alle Titel sind fett gedruckt, 1 bedeutet Titel der Ebene 1, die größten Wörter, Titel der Ebene 6 ist der kleinste td> | Das -Attribut befindet sich im Start-Tag align:Titelausrichtung festlegen Mitte: Mitte, rechts: rechtsbündig, links: linksbündig | ||||||||||||||||||||||||
| Std | Zeichnen Sie eine horizontale Linie | width: Zeilenlänge Größe:Dicke Farbe: Farbe | ||||||||||||||||||||||||
| b | Fett die Schriftart, die die gleiche Funktion wie das starke Tag hat | |||||||||||||||||||||||||
| i | Stellen Sie die Schriftart auf Kursiv ein | |||||||||||||||||||||||||
| br | Zeilenumbruch | |||||||||||||||||||||||||
| Schriftart | Schriftart (in HTML5 veraltet) | Farbe: Farbe Größe: Größe Gesicht: der Name der angegebenen Schriftart | ||||||||||||||||||||||||
| p | Absatz, jedes p-Tag ist ein Absatz, es gibt keinen Einzug in der ersten Zeile. Es gibt Lücken zwischen den Absätzen | Wenn Sie einrücken möchten, verwenden Sie Leerzeichen in halber Breite können auch Leerzeichen in voller Breite sein title:Wenn die Maus nach oben bewegt wird, erscheint eine Textaufforderung Informationen werden angezeigt |
2.3 块标签与内联标签:
1.div:块标签,需要独立占一行。
2.span:内联标签,不需要独立占一行。
案例文字素材
World Wide Web Consortium
万维网联盟创建于1994年代码演示
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Title</title>
<style type="text/css"></style>
<script type="text/javascript"></script>
</head>
<body>
<div style="background-color: red">World Wide Web Consortium</div>
万维网联盟创建于1994年
<span style="background-color: aqua">World Wide Web Consortium</span>
万维网联盟创建于1994年
</body>
</html>
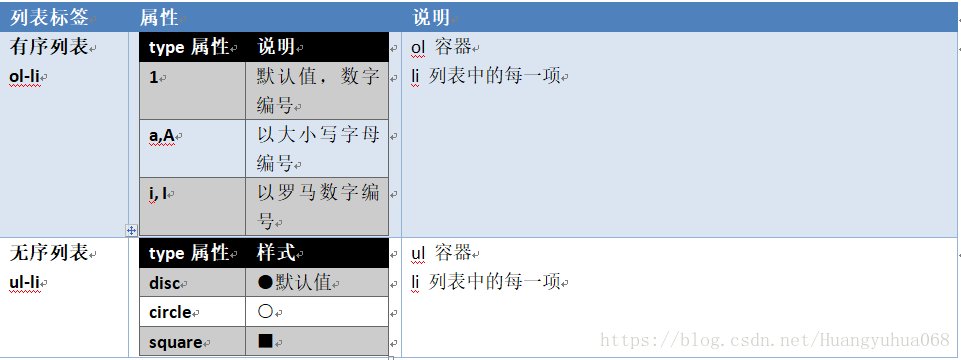
2.4 列表标签:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style type="text/css"></style>
<script type="text/javascript"></script>
</head>
<body>
今天早上吃什么?
<ol style="color: black" type="A">
<li>
油条
</li>
<li>
豆浆
</li>
<li>
稀饭
</li>
</ol>
明天早上吃什么?
<ul style="color: black" type="disc">
<li>面</li>
<li>糯米鸡</li>
</ul>
</body>
</html>
2.5 实体字符
2.5.1 为什么需要使用到实体字符:
在HTML页面中,有些字符是有着特殊含义的字符,如果需要在网页上显示这种特殊的字符,那么就需要使用到该特殊字符对应的实体字符。比如:< 小于号 > 大于号
2.5.2 实体字符列表:
注释:实体名称对大小写敏感!
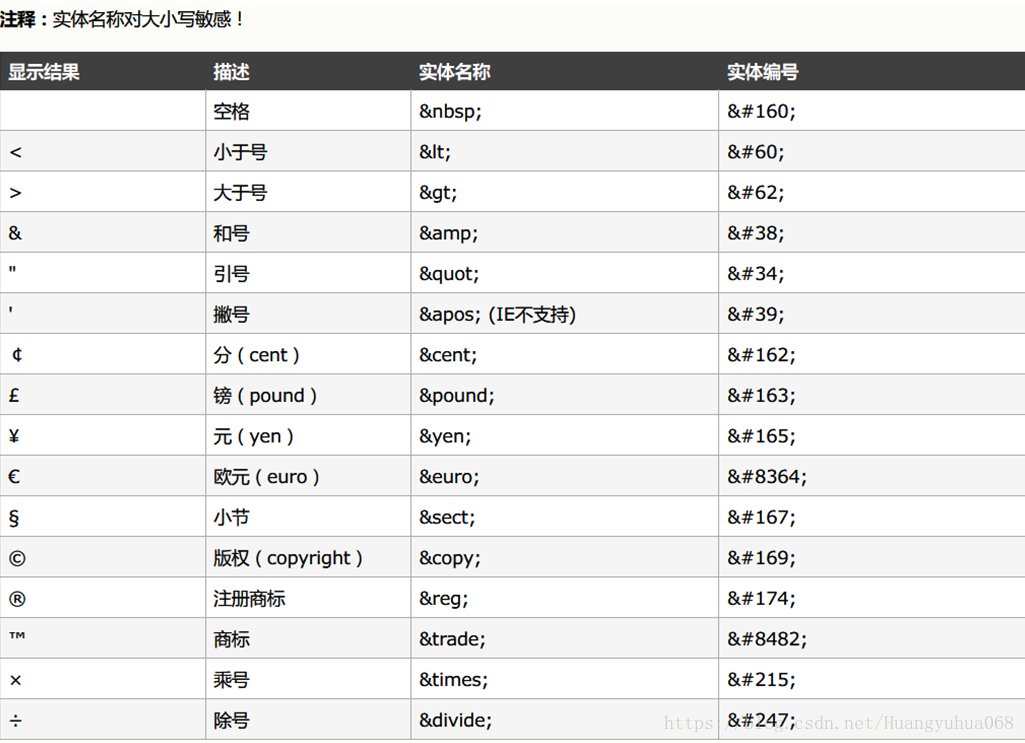
2.5.3 常用的实体字符:
| 特殊的字符 | 对应的实体字符 |
| < | < |
| > | > |
| 空格 | |
| ¥ |
¥ |
| © 版本所有 | © |
| ® | ® |
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style type="text/css"></style>
<script type="text/javascript"></script>
</head>
<body>
<h1>标签是标题标签<br/>
百度(纳斯达克:BIDU),全球最大的中文搜索引擎、最大的中文网站。
1999年底,身在美国硅谷的李彦宏看到了中国互联网及中文搜索引擎服务的巨大发展潜力,
抱着技术改变世界的梦想,他毅然辞掉硅谷的高薪工作,携搜索引擎专利技术,于 2000年1月1日在中关村创建了百度公司。<br/>
青岛啤酒:¥16元一瓶。<br/>
《java从入门到放弃》:© XXX版权所有<br/>
本次活动解释权归XXX公司所有:®XXX有限公司
</body>
</html>
2.6 图像标签(img)
2.6.1 标签的作用:
在网页中显示图片。
2.6.2 常用的属性:
| 属性名 | 作用 |
| src | source图片文件地址,注:不能使用客户端本地地址,如:c:/aaa.jpg |
| width | 图片宽度,如果只指定宽和高,另一个参数会等比例缩放 |
| height | 图片高度 |
| alt | 如果图片丢失,图片显示的文字 |
| title | 如果鼠标移到图片上,显示提示文字信息 |
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style type="text/css"></style>
<script type="text/javascript"></script>
</head>
<body>
<img src="img/11.jpg" height="500" width="200" title="这个是一辆豪车" />
</body>
</html>相关推荐:
html标签之meta标签_html/css_WEB-ITnose
Das obige ist der detaillierte Inhalt vonAnalyse häufig verwendeter Tags in HTML (mit Code). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 So extrahieren Sie HTML-Tag-Inhalte mithilfe regulärer Ausdrücke in der Go-Sprache
Jul 14, 2023 pm 01:18 PM
So extrahieren Sie HTML-Tag-Inhalte mithilfe regulärer Ausdrücke in der Go-Sprache
Jul 14, 2023 pm 01:18 PM
So verwenden Sie reguläre Ausdrücke zum Extrahieren von HTML-Tag-Inhalten in der Go-Sprache. Einführung: Reguläre Ausdrücke sind ein leistungsstarkes Tool zum Textabgleich und werden auch häufig in der Go-Sprache verwendet. Im Szenario der Verarbeitung von HTML-Tags können uns reguläre Ausdrücke dabei helfen, den erforderlichen Inhalt schnell zu extrahieren. In diesem Artikel wird erläutert, wie reguläre Ausdrücke zum Extrahieren des Inhalts von HTML-Tags in der Go-Sprache verwendet werden, und es werden relevante Codebeispiele aufgeführt. 1. Verwandte Pakete einführen Zuerst müssen wir verwandte Pakete importieren: regexp und fmt. regexp-Paket bietet
 So entfernen Sie HTML-Tags mithilfe regulärer Python-Ausdrücke
Jun 22, 2023 am 08:44 AM
So entfernen Sie HTML-Tags mithilfe regulärer Python-Ausdrücke
Jun 22, 2023 am 08:44 AM
HTML (HyperTextMarkupLanguage) ist eine Standardsprache zum Erstellen von Webseiten. Sie verwendet Tags und Attribute, um verschiedene Elemente auf der Seite zu beschreiben, wie z. B. Text, Bilder, Tabellen, Links usw. Bei der Verarbeitung von HTML-Text ist es jedoch schwierig, den Textinhalt schnell für die anschließende Verarbeitung zu extrahieren. Zu diesem Zeitpunkt können wir reguläre Ausdrücke in Python verwenden, um HTML-Tags zu entfernen und so schnell einfachen Text zu extrahieren. In Python reguläre Tabellen
 Wie entferne ich HTML-Tags aus einer Zeichenfolge in PHP?
Mar 23, 2024 pm 09:03 PM
Wie entferne ich HTML-Tags aus einer Zeichenfolge in PHP?
Mar 23, 2024 pm 09:03 PM
PHP ist eine häufig verwendete serverseitige Skriptsprache, die häufig in der Website-Entwicklung und der Back-End-Anwendungsentwicklung eingesetzt wird. Bei der Entwicklung einer Website oder Anwendung kommt es häufig vor, dass Sie HTML-Tags in Zeichenfolgen verarbeiten müssen. In diesem Artikel wird erläutert, wie Sie mithilfe von PHP HTML-Tags aus Zeichenfolgen entfernen, und es werden spezifische Codebeispiele bereitgestellt. Warum müssen Sie HTML-Tags entfernen? Bei der Verarbeitung von Benutzereingaben oder aus einer Datenbank abgerufenem Text werden häufig HTML-Tags einbezogen. Manchmal möchten wir diese HTML-Tags entfernen, wenn wir Text anzeigen
 So maskieren Sie HTML-Tags in PHP
Feb 24, 2021 pm 06:00 PM
So maskieren Sie HTML-Tags in PHP
Feb 24, 2021 pm 06:00 PM
In PHP können Sie die Funktion htmlentities() verwenden, um HTML zu maskieren, wodurch Zeichen in HTML-Entitäten umgewandelt werden können. Die Syntax lautet „htmlentities(string,flags,character-set,double_encode)“. Sie können auch die Funktion html_entity_decode() in PHP verwenden, um HTML zu entescapen und HTML-Entitäten in Zeichen umzuwandeln.
 Wie entferne ich HTML-Tags aus einer bestimmten Zeichenfolge in Java?
Aug 29, 2023 pm 06:05 PM
Wie entferne ich HTML-Tags aus einer bestimmten Zeichenfolge in Java?
Aug 29, 2023 pm 06:05 PM
String ist eine letzte Klasse in Java, sie ist unveränderlich, was bedeutet, dass wir das Objekt selbst nicht ändern können, aber wir können die Referenz des Objekts ändern. HTML-Tags können mit der Methode replaceAll() der String-Klasse aus einer bestimmten Zeichenfolge entfernt werden. Mithilfe regulärer Ausdrücke können wir HTML-Tags aus einer bestimmten Zeichenfolge entfernen. Nachdem die HTML-Tags aus der Zeichenfolge entfernt wurden, wird eine Zeichenfolge als normaler Text zurückgegeben. Syntax publicStringreplaceAll(Stringregex,Stringreplacement) Beispiel publicclassRemoveHTMLTagsTest{&nbs
 Wie verwende ich HTML-Tags in HTML-Tabellen?
Sep 08, 2023 pm 06:13 PM
Wie verwende ich HTML-Tags in HTML-Tabellen?
Sep 08, 2023 pm 06:13 PM
Wir können problemlos HTML-Tags in die Tabelle einfügen. HTML-Tags sollten innerhalb von <td>-Tags platziert werden. Fügen Sie beispielsweise Absatz-<p>…</p>-Tags oder andere verfügbare Tags innerhalb des <td>-Tags hinzu. Syntax Im Folgenden finden Sie die Syntax für die Verwendung von HTML-Tags in HTML-Tabellen. <td><p>Absatz des Kontexts</p><td>Beispiel 1 Ein Beispiel für die Verwendung von HTML-Tags in einer HTML-Tabelle finden Sie unten. <!DOCTYPEhtml><html><head&g
 Was ist ein Beispiel für ein Start -Tag in HTML?
Apr 06, 2025 am 12:04 AM
Was ist ein Beispiel für ein Start -Tag in HTML?
Apr 06, 2025 am 12:04 AM
AnexampleofaTartingTaginHtmlis, die, die starttagsaresesinginhtmlastheyinitiateElements, definetheirtypes, andarecrucialForstructuringwebpages und -konstruktionsthedoms.
 PHP-Methode für reguläre Ausdrücke zur Überprüfung grundlegender HTML-Tags
Jun 24, 2023 am 08:07 AM
PHP-Methode für reguläre Ausdrücke zur Überprüfung grundlegender HTML-Tags
Jun 24, 2023 am 08:07 AM
PHP ist eine effiziente Webentwicklungssprache, die reguläre Ausdrucksfunktionen unterstützt und die Gültigkeit von Eingabedaten schnell überprüfen kann. In der Webentwicklung ist HTML eine gängige Auszeichnungssprache und die Validierung von HTML-Tags ist eine sehr wichtige Methode zur Validierung von Webformularen. In diesem Artikel werden grundlegende Methoden zur Überprüfung von HTML-Tags und die Verwendung regulärer PHP-Ausdrücke zur Überprüfung vorgestellt. 1. Grundstruktur von HTML-Tags HTML-Tags bestehen aus Elementnamen und Attributen, die von spitzen Klammern umgeben sind. Zu den gängigen Tags gehören p, a, div
